- Ce este funcția Softmax?
- Formula softmax
- Explicarea simbolurilor formulei softmax
- Calcularea Softmax
- Funcția softmax vs. funcția sigmoidă
- Calcularea funcției softmax vs. funcția sigmoidă
- Funcția softmax vs. funcția argmax
- Calculul funcției softmax vs. funcția argmax
- Aplicații ale funcției softmax
- Funcția softmax în rețelele neuronale
- Exemplu de calcul al Softmax într-o rețea neuronală
- Funcția softmax în învățarea prin întărire
- Exemplu de calcul al funcției Softmax în învățarea prin întărire
- Formula softmax de învățare prin întărire Simboluri explicate
- Istoria softmax
Ce este funcția Softmax?
Funcția Softmax este o funcție care transformă un vector de K valori reale într-un vector de K valori reale care însumează 1. Valorile de intrare pot fi pozitive, negative, zero sau mai mari decât unu, dar Softmax le transformă în valori cuprinse între 0 și 1, astfel încât acestea să poată fi interpretate ca probabilități. Dacă una dintre intrări este mică sau negativă, softmax o transformă într-o probabilitate mică, iar dacă o intrare este mare, atunci o transformă într-o probabilitate mare, dar aceasta va rămâne întotdeauna între 0 și 1.
Funcția softmax este uneori numită funcția softargmax sau regresie logistică multiclasă. Acest lucru se datorează faptului că softmax este o generalizare a regresiei logistice care poate fi utilizată pentru clasificarea multiclasă, iar formula sa este foarte asemănătoare cu funcția sigmoidă care este utilizată pentru regresia logistică. Funcția softmax poate fi utilizată într-un clasificator numai atunci când clasele se exclud reciproc.
Multe rețele neuronale multistraturi se termină într-un penultim strat care emite scoruri cu valori reale care nu sunt scalate convenabil și care pot fi dificil de utilizat. În acest caz, softmax este foarte util, deoarece convertește scorurile într-o distribuție de probabilitate normalizată, care poate fi afișată unui utilizator sau utilizată ca intrare pentru alte sisteme. Din acest motiv, se obișnuiește să se adauge o funcție softmax ca strat final al rețelei neuronale.
Formula softmax
Formula softmax este următoarea:
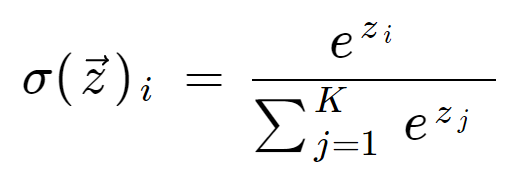
Definiția matematică a funcției softmax
unde toate valorile zi sunt elementele vectorului de intrare și pot lua orice valoare reală. Termenul din partea de jos a formulei este termenul de normalizare care asigură că toate valorile de ieșire ale funcției vor însuma 1, constituind astfel o distribuție de probabilitate validă.
Explicarea simbolurilor formulei softmax
| Vectorialul de intrare al funcției softmax, alcătuit din (z0, …. zK) | |
| Toate valorile zi sunt elementele vectorului de intrare al funcției softmax, iar acestea pot lua orice valoare reală, pozitivă, zero sau negativă. De exemplu, o rețea neuronală ar fi putut emite la ieșire un vector precum (-0,62, 8,12, 2,53), care nu este o distribuție de probabilitate validă, motiv pentru care ar fi necesară funcția softmax. | |
 |
Funcția exponențială standard se aplică fiecărui element al vectorului de intrare. Astfel se obține o valoare pozitivă peste 0, care va fi foarte mică dacă valoarea de intrare a fost negativă și foarte mare dacă valoarea de intrare a fost mare. Cu toate acestea, încă nu este fixată în intervalul (0, 1), ceea ce este necesar pentru o probabilitate. |
 |
Termenul din partea de jos a formulei este termenul de normalizare. Acesta asigură că toate valorile de ieșire ale funcției vor avea suma 1 și că fiecare dintre ele se va afla în intervalul (0, 1), constituind astfel o distribuție de probabilitate validă. |
| Numărul de clase în clasificatorul multiclasă. |
Calcularea Softmax
Imaginați-vă că avem o matrice de trei valori reale. Aceste valori ar putea fi, de obicei, ieșirea unui model de învățare automată, cum ar fi o rețea neuronală. Dorim să convertim valorile într-o distribuție de probabilitate.

Primul lucru pe care îl putem face este să calculăm exponențialul fiecărui element al matricei de intrare. Acesta este termenul din jumătatea superioară a ecuației softmax.
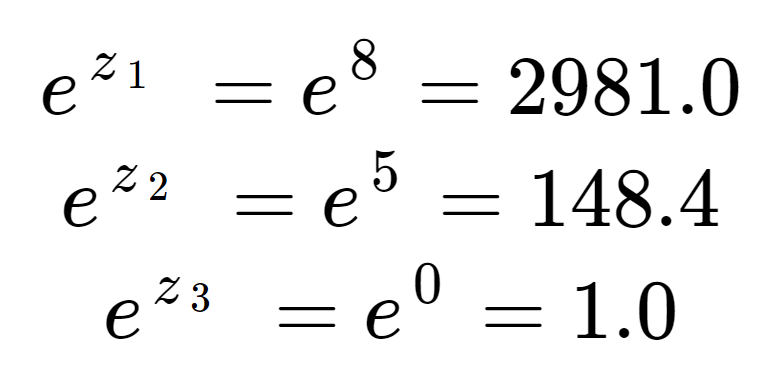
Aceste valori nu arată încă ca niște probabilități. Observați că în elementele de intrare, deși 8 este doar puțin mai mare decât 5, 2981 este mult mai mare decât 148 datorită efectului exponențialului. Putem obține termenul de normalizare, jumătatea inferioară a ecuației softmax, prin însumarea celor trei termeni exponențiali:

Vezi că termenul de normalizare a fost dominat de z1.
În cele din urmă, împărțind cu termenul de normalizare, obținem ieșirea softmax pentru fiecare dintre cele trei elemente. Observați că nu există o singură valoare de ieșire, deoarece softmax transformă un tablou într-un tablou de aceeași lungime, în acest caz 3.
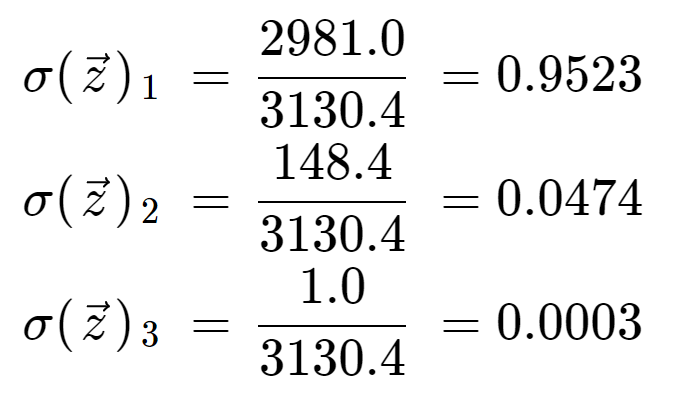
Este informativ să verificăm că avem trei valori de ieșire care sunt toate probabilități valide, adică se situează între 0 și 1, iar suma lor este 1.
Rețineți, de asemenea, că, datorită operației exponențiale, primul element, 8, a dominat funcția softmax și a eliminat 5 și 0 în valori de probabilitate foarte mici.
Dacă folosiți funcția softmax într-un model de învățare automată, ar trebui să fiți atenți înainte de a o interpreta ca o probabilitate reală, deoarece are tendința de a produce valori foarte apropiate de 0 sau 1. Dacă o rețea neuronală a avut scoruri de ieșire de , ca în acest exemplu, atunci funcția softmax ar fi atribuit o probabilitate de 95% pentru prima clasă, când în realitate ar fi putut exista mai multă incertitudine în predicțiile rețelei neuronale. Acest lucru ar putea da impresia că predicția rețelei neuronale a avut o încredere ridicată, când nu era cazul.
Funcția softmax vs. funcția sigmoidă
După cum s-a menționat mai sus, funcția softmax și funcția sigmoidă sunt similare. Funcția softmax operează pe un vector, în timp ce sigmoidul ia un scalar.

De fapt, funcția sigmoid este un caz special al funcției softmax pentru un clasificator cu doar două clase de intrare. Putem arăta acest lucru dacă setăm vectorul de intrare să fie și calculăm primul element de ieșire cu formula softmax obișnuită:

Divizând partea de sus și partea de jos cu ex, obținem:

Aceasta arată că funcția sigmoidă devine echivalentă cu funcția softmax atunci când avem două clase. Nu este necesar să calculăm a doua componentă vectorială în mod explicit, deoarece atunci când există două probabilități, acestea trebuie să însumeze 1. Astfel, dacă dezvoltăm un clasificator cu două clase cu regresie logistică, putem utiliza funcția sigmoidă și nu este nevoie să lucrăm cu vectori. Dar dacă avem mai mult de două clase care se exclud reciproc, ar trebui utilizat softmax.
Dacă există mai mult de două clase și acestea nu se exclud reciproc (un clasificator cu mai multe etichete), atunci clasificatorul poate fi împărțit în mai multe clasificatoare binare, fiecare folosind propria funcție sigmoidă.
Calcularea funcției softmax vs. funcția sigmoidă
Dacă luăm un vector de intrare , îl putem introduce atât în funcția softmax, cât și în funcția sigmoidă. Deoarece sigmoidul ia o valoare scalară, punem doar primul element în funcția sigmoid.

Funcția sigmoid dă aceeași valoare ca și softmax pentru primul element, cu condiția ca al doilea element de intrare să fie setat la 0. Deoarece sigmoidul ne oferă o probabilitate, iar cele două probabilități trebuie să însumeze 1, nu este necesar să calculăm în mod explicit o valoare pentru al doilea element.
Funcția softmax vs. funcția argmax
Funcția softmax a fost dezvoltată ca o alternativă netezită și diferențiabilă la funcția argmax. Din acest motiv, funcția softmax este uneori denumită mai explicit funcția softargmax. Ca și funcția softmax, funcția argmax operează pe un vector și convertește fiecare valoare la zero, cu excepția valorii maxime, unde returnează 1.

Se obișnuiește să se antreneze un model de învățare automată folosind softmax, dar să se schimbe stratul softmax cu un strat argmax atunci când modelul este utilizat pentru inferență.
Trebuie să folosim softmax în antrenare deoarece softmax este diferențiabilă și ne permite să optimizăm o funcție de cost. Cu toate acestea, pentru inferență, uneori avem nevoie de un model doar pentru a emite o singură valoare prezisă, mai degrabă decât o probabilitate, caz în care argmax este mai util.
Când există mai multe valori maxime, este obișnuit ca argmax să returneze 1/Nmax, adică o fracție normalizată, astfel încât suma elementelor de ieșire să rămână 1, ca în cazul softmax. O definiție alternativă este de a returna 1 pentru toate valorile maxime, sau doar pentru prima valoare.
Calculul funcției softmax vs. funcția argmax
Să ne imaginăm din nou vectorul de intrare . Calculăm funcția softmax ca și până acum. Cea mai mare valoare este primul element, astfel încât argmax va returna 1 pentru primul element și 0 pentru restul.

Din acest exemplu reiese clar că funcția softmax se comportă ca o aproximare „soft” a funcției argmax: ea returnează valori neintegrale între 0 și 1 care pot fi interpretate ca probabilități. Dacă folosim un model de învățare automatizată pentru inferență, mai degrabă decât să-l antrenăm, am putea dori o ieșire întreagă de la sistem care să reprezinte o decizie dură pe care o vom lua cu rezultatul modelului, cum ar fi tratarea unei tumori, autentificarea unui utilizator sau atribuirea unui document unui subiect. Valorile argmax sunt mai ușor de lucrat în acest sens și pot fi folosite pentru a construi o matrice de confuzie și pentru a calcula precizia și reamintirea unui clasificator.
Aplicații ale funcției softmax
Funcția softmax în rețelele neuronale
O utilizare a funcției softmax ar fi la sfârșitul unei rețele neuronale. Să considerăm o rețea neuronală convoluțională care recunoaște dacă o imagine este o pisică sau un câine. Rețineți că o imagine trebuie să fie fie o pisică sau un câine și nu poate fi ambele, prin urmare cele două clase se exclud reciproc. În mod normal, stratul final complet conectat al acestei rețele ar produce valori de genul care nu sunt normalizate și nu pot fi interpretate ca probabilități. Dacă adăugăm un strat softmax la rețea, este posibil să traducem cifrele într-o distribuție de probabilități. Acest lucru înseamnă că rezultatul poate fi afișat unui utilizator, de exemplu, aplicația este sigură în proporție de 95% că aceasta este o pisică. De asemenea, înseamnă că rezultatul poate fi introdus în alți algoritmi de învățare automată fără a fi nevoie să fie normalizat, deoarece este garantat să se situeze între 0 și 1.
Rețineți că, dacă rețeaua clasifică imaginile în câini și pisici și este configurată să aibă doar două clase de ieșire, atunci este forțată să clasifice fiecare imagine ca fiind fie câine, fie pisică, chiar dacă nu este niciuna dintre ele. Dacă trebuie să permitem această posibilitate, atunci trebuie să reconfigurăm rețeaua neuronală pentru a avea o a treia ieșire pentru diverse.
Exemplu de calcul al Softmax într-o rețea neuronală
Exemplul Softmax este esențial atunci când antrenăm o rețea neuronală. Imaginați-vă că avem o rețea neuronală convoluțională care învață să distingă între câini și pisici. Am setat pisica ca fiind clasa 1 și câinele ca fiind clasa 2.
În mod normal, atunci când introducem o imagine a unei pisici în rețeaua noastră, rețeaua ar produce vectorul . Atunci când introducem o imagine de câine, dorim o ieșire .
Procesarea imaginilor în rețeaua neuronală se termină la stratul final complet conectat. Acest strat emite două scoruri pentru pisică și câine, care nu sunt probabilități. Este o practică obișnuită să se adauge un strat softmax la sfârșitul rețelei neuronale, care transformă ieșirea într-o distribuție de probabilități.La începutul antrenamentului, ponderile rețelei neuronale sunt configurate aleatoriu. Astfel, imaginea pisicii trece prin și este convertită de etapele de procesare a imaginii în scoruri . Trecând în funcția softmax putem obține probabilitățile inițiale

Evident, acest lucru nu este de dorit. O rețea perfectă în acest caz ar produce .

Potem formula o funcție de pierdere a rețelei noastre care să cuantifice cât de departe sunt probabilitățile de ieșire ale rețelei de valorile dorite. Cu cât funcția de pierdere este mai mică, cu atât vectorul de ieșire este mai apropiat de clasa corectă. Cea mai comună funcție de pierdere în acest caz este pierderea de entropie încrucișată care, în acest caz, ajunge la:
Pentru că softmax este o funcție continuu diferențiabilă, este posibil să se calculeze derivata funcției de pierdere în raport cu fiecare greutate din rețea, pentru fiecare imagine din setul de antrenament.
Această proprietate ne permite să ajustăm ponderile rețelei pentru a reduce funcția de pierdere și pentru a face ca rezultatul rețelei să fie mai aproape de valorile dorite și pentru a îmbunătăți acuratețea rețelei.După mai multe iterații de instruire, actualizăm ponderile rețelei. Acum, atunci când aceeași imagine de pisică este introdusă în rețea, stratul complet conectat emite un vector de scor de . Trecând din nou acest lucru prin funcția softmax, obținem probabilități de ieșire:

Este este în mod clar un rezultat mai bun și mai aproape de rezultatul dorit de . Recalculând pierderea de entropie încrucișată,

vădem că pierderea s-a redus, ceea ce indică faptul că rețeaua neuronală s-a îmbunătățit.
Metoda de diferențiere a funcției de pierdere pentru a stabili cum să ajustăm ponderile rețelei nu ar fi fost posibilă dacă am fi folosit funcția argmax, deoarece aceasta nu este diferențiabilă. Proprietatea diferențiabilității face ca funcția softmax să fie utilă pentru antrenarea rețelelor neuronale.
Funcția softmax în învățarea prin întărire
În învățarea prin întărire, funcția softmax este utilizată și atunci când un model trebuie să decidă între a întreprinde acțiunea despre care se știe în prezent că are cea mai mare probabilitate de recompensă, numită
exploatare, sau a face un pas exploratoriu, numit explorare.
Exemplu de calcul al funcției Softmax în învățarea prin întărire
Imaginați-vă că antrenăm un model de învățare prin întărire pentru a juca poker împotriva unui om. Trebuie să configurăm o temperatură τ, care stabilește cât de probabil este ca sistemul să întreprindă acțiuni aleatorii de explorare. În prezent, sistemul are două opțiuni: să joace un As sau să joace un Rege. Din ceea ce a învățat până în prezent, jucând un As are o probabilitate de 80% să fie strategia câștigătoare în situația actuală. Presupunând că nu există alte jocuri posibile, atunci jucarea unui rege are 20% șanse să fie strategia câștigătoare. Am configurat temperatura τ la 2.
Sistemul de învățare prin întărire utilizează funcția softmax pentru a obține probabilitatea de a juca un As și, respectiv, un Rege. Formula softmax modificată utilizată în învățarea prin întărire este următoarea:

Formula softmax de învățare prin întărire Simboluri explicate
| Probabilitatea ca modelul să întreprindă acum acțiunea a la momentul t. | |
| Acțiunea pe care ne gândim să o întreprindem. De exemplu, să jucăm un Rege sau un As. | |
 |
Temperatura sistemului, configurată ca un hiperparametru. |
|
Cea mai bună estimare actuală a probabilității de succes dacă întreprindem acțiunea i, din ceea ce a învățat modelul până acum. |
Punând valorile noastre în ecuație obținem:

Acest lucru înseamnă că, deși modelul este în prezent 80% sigur că Asul este strategia corectă, este doar 57% probabil să joace această carte. Acest lucru se datorează faptului că, în învățarea prin întărire, atribuim o valoare atât explorării (testarea de noi strategii), cât și exploatării (utilizarea strategiilor cunoscute). Dacă alegem să creștem temperatura, modelul devine mai „impulsiv”: este mai probabil să facă pași de explorare decât să joace întotdeauna strategia câștigătoare.
Istoria softmax
Prima utilizare cunoscută a funcției softmax este anterioară învățării automate. Funcția softmax este, de fapt, împrumutată din fizică și mecanica statistică, unde este cunoscută sub numele de distribuția Boltzmann sau distribuția Gibbs. Ea a fost formulată de fizicianul și filosoful austriac Ludwig Boltzmann în 1868.
Boltzmann studia mecanica statistică a gazelor în echilibru termic. El a descoperit că distribuția Boltzmann poate descrie probabilitatea de a găsi un sistem într-o anumită stare, având în vedere energia acelei stări și temperatura sistemului. Versiunea sa a formulei era similară cu cea utilizată în învățarea prin întărire. Într-adevăr, parametrul τ este numit temperatură în domeniul învățării prin întărire ca un omagiu adus lui Boltzmann.
În 1902, fizicianul și chimistul american Josiah Willard Gibbs a popularizat distribuția Boltzmann când a folosit-o pentru a pune bazele termodinamicii și definiția sa a entropiei. De asemenea, ea stă la baza spectroscopiei, adică a analizei materialelor prin observarea luminii pe care o absorb și o reflectă.
În 1959, Robert Duncan Luce a propus utilizarea funcției softmax pentru învățarea prin întărire în cartea sa Individual Choice Behavior: A Theoretical Analysis. În cele din urmă, în 1989, John S. Bridle a sugerat că funcția argmax din rețelele neuronale feedforward ar trebui să fie înlocuită cu softmax, deoarece „păstrează ordinea de rang a valorilor de intrare și este o generalizare diferențiabilă a operației „winner-take-all” de alegere a valorii maxime”. În ultimii ani, pe măsură ce rețelele neuronale au devenit utilizate pe scară largă, softmax a devenit bine cunoscut datorită acestor proprietăți.
.