- Hvad er softmax-funktionen?
- Softmax-formel
- Symboler for softmaxformlen forklaret
- Beregning af Softmax
- Softmax-funktion vs. sigmoid-funktion
- Beregning af softmaxfunktion vs. sigmoidfunktion
- Softmax-funktion vs. argmax-funktion
- Beregning af softmax-funktion vs. argmax-funktion
- Anvendelser af softmax-funktionen
- Softmax-funktionen i neurale netværk
- Eksempel på beregning af softmax i et neuralt netværk
- Softmax-funktionen i forstærkningslæring
- Eksempel på beregning af softmax i forstærkende læring
- Reinforcement Learning Softmax Formula Symboler Forklaret
- Softmax historie
Hvad er softmax-funktionen?
Softmax-funktionen er en funktion, der omdanner en vektor med K reelle værdier til en vektor med K reelle værdier, der summerer til 1. Indgangsværdierne kan være positive, negative, nul eller større end 1, men softmax omdanner dem til værdier mellem 0 og 1, så de kan tolkes som sandsynligheder. Hvis en af inputværdierne er lille eller negativ, omdanner softmax den til en lille sandsynlighed, og hvis en inputværdi er stor, omdanner den den til en stor sandsynlighed, men den vil altid forblive mellem 0 og 1.
Den softmax-funktion kaldes undertiden softargmax-funktionen eller logistisk regression med flere klasser. Dette skyldes, at softmax er en generalisering af logistisk regression, der kan bruges til klassifikation med flere klasser, og dens formel ligner meget den sigmoide funktion, som bruges til logistisk regression. Softmax-funktionen kan kun anvendes i en klassifikator, når klasserne er gensidigt udelukkende.
Mange flerlags neurale netværk ender i et næstsidste lag, som udsender realværdi-scoringer, der ikke er praktisk skaleret, og som kan være vanskelige at arbejde med. Her er softmax meget nyttigt, fordi det konverterer scorerne til en normaliseret sandsynlighedsfordeling, som kan vises for en bruger eller bruges som input til andre systemer. Derfor er det almindeligt at tilføje en softmax-funktion som det sidste lag i det neurale netværk.
Softmax-formel
Den softmax-formel er som følger:
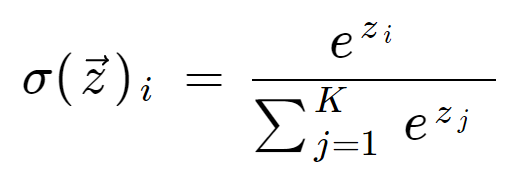
Matematisk definition af softmax-funktionen
hvor alle zi-værdierne er elementerne i inputvektoren og kan antage enhver reel værdi. Udtrykket nederst i formlen er normaliseringstermen, som sikrer, at alle funktionens udgangsværdier summerer til 1 og dermed udgør en gyldig sandsynlighedsfordeling.
Symboler for softmaxformlen forklaret
| Inputvektoren til softmaxfunktionen, der består af (z0, … zK) | ||
| Alle zi-værdierne er elementerne i inputvektoren til softmax-funktionen, og de kan antage en hvilken som helst reel værdi, positiv, nul eller negativ. Et neuralt netværk kunne f.eks. have afgivet en vektor som (-0,62, 8,12, 2,53), hvilket ikke er en gyldig sandsynlighedsfordeling, hvorfor softmax ville være nødvendig. | ||
 |
Den eksponentielle standardfunktion anvendes på hvert element i inputvektoren. Dette giver en positiv værdi over 0, som vil være meget lille, hvis input var negativt, og meget stor, hvis input var stort. Den er dog stadig ikke fast i intervallet (0, 1), hvilket er det, der kræves af en sandsynlighed. | |
 |
Termen nederst i formlen er normaliseringstermen. Det sikrer, at alle funktionens udgangsværdier summerer til 1 og hver især ligger i intervallet (0, 1) og dermed udgør en gyldig sandsynlighedsfordeling. | |
| Antal af klasser i flerklasseklassifikatoren. |
Beregning af Softmax
Forestil dig, at vi har et array af tre reelle værdier. Disse værdier kunne typisk være output fra en maskinlæringsmodel, f.eks. et neuralt netværk. Vi ønsker at konvertere værdierne til en sandsynlighedsfordeling.

Først kan vi beregne eksponentialet for hvert element i input arrayet. Dette er udtrykket i den øverste halvdel af softmax-ligningen.
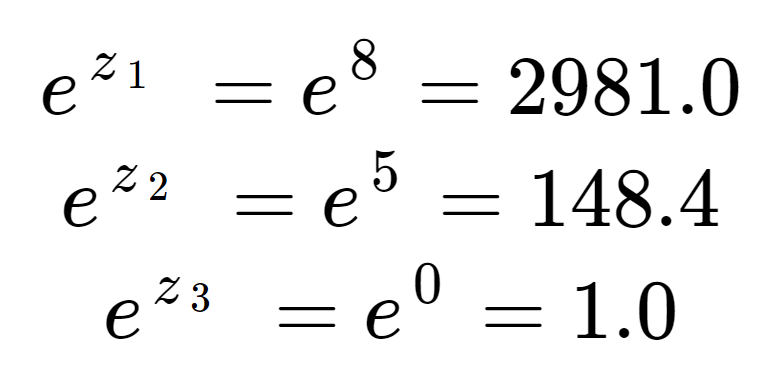
Disse værdier ligner ikke sandsynligheder endnu. Bemærk, at i inputelementerne, selv om 8 kun er lidt større end 5, er 2981 meget større end 148 på grund af eksponentialens virkning. Vi kan få normaliseringstermen, den nederste halvdel af softmax-ligningen, ved at summere alle tre eksponentielle termer:

Vi ser, at normaliseringstermen er blevet domineret af z1.
Til sidst får vi ved at dividere med normaliseringstermen softmax-udgangen for hvert af de tre elementer. Bemærk, at der ikke er en enkelt udgangsværdi, fordi softmax transformerer et array til et array af samme længde, i dette tilfælde 3.
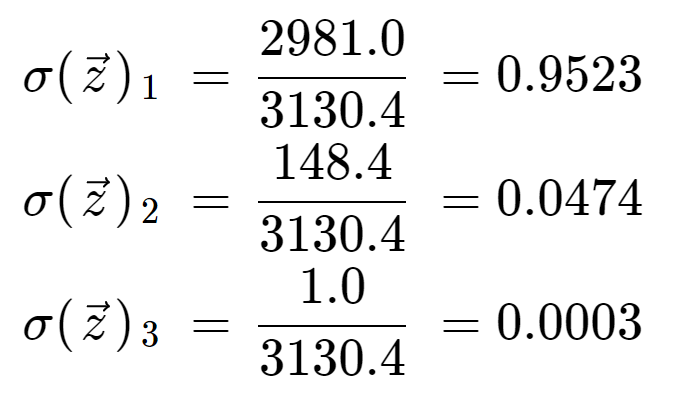
Det er informativt at kontrollere, at vi har tre udgangsværdier, som alle er gyldige sandsynligheder, dvs. at de ligger mellem 0 og 1, og at de summerer til 1.
Bemærk også, at på grund af den eksponentielle operation har det første element, 8, domineret softmax-funktionen og har presset 5 og 0 ud til meget lave sandsynlighedsværdier.
Hvis du bruger softmax-funktionen i en maskinlæringsmodel, skal du være forsigtig, før du fortolker den som en sand sandsynlighed, da den har en tendens til at producere værdier meget tæt på 0 eller 1. Hvis et neuralt netværk havde outputscorer på , som i dette eksempel, ville softmax-funktionen have tildelt 95 % sandsynlighed til den første klasse, når der i virkeligheden kunne have været større usikkerhed i det neurale netværks forudsigelser. Dette kunne give indtryk af, at det neurale netværks forudsigelse havde en høj tillid, når det ikke var tilfældet.
Softmax-funktion vs. sigmoid-funktion
Som nævnt ovenfor ligner softmax-funktionen og sigmoid-funktionen hinanden. Softmax-funktionen opererer på en vektor, mens sigmoid-funktionen tager en skalar.

Sigmoid-funktionen er faktisk et specialtilfælde af softmax-funktionen for en klassifikator med kun to indgangsklasser. Det kan vi vise, hvis vi sætter inputvektoren til at være og beregner det første outputelement med den sædvanlige softmax-formel:

Dividerer vi top og bund med ex, får vi:

Det viser, at sigmoidfunktionen bliver ækvivalent med softmax-funktionen, når vi har to klasser. Det er ikke nødvendigt at beregne den anden vektorkomponent eksplicit, for når der er to sandsynligheder, skal de summere til 1. Så hvis vi udvikler en toklassesklassifikator med logistisk regression, kan vi bruge sigmoidfunktionen og behøver ikke at arbejde med vektorer. Men hvis vi har mere end to klasser, der udelukker hinanden, skal softmax bruges.
Hvis der er mere end to klasser, og de ikke udelukker hinanden (en klassifikator med flere etiketter), kan klassifikatoren opdeles i flere binære klassifikatorer, der hver bruger sin egen sigmoidfunktion.
Beregning af softmaxfunktion vs. sigmoidfunktion
Hvis vi tager en inputvektor , kan vi sætte denne ind i både softmax- og sigmoidfunktionen. Da sigmoid-funktionen tager en skalarværdi, sætter vi kun det første element ind i sigmoid-funktionen.

Sigmoid-funktionen giver den samme værdi som softmax-funktionen for det første element, forudsat at det andet indgangselement sættes til 0. Da sigmoidfunktionen giver os en sandsynlighed, og de to sandsynligheder skal summeres til 1, er det ikke nødvendigt eksplicit at beregne en værdi for det andet element.
Softmax-funktion vs. argmax-funktion
Den blødemax-funktion blev udviklet som et udglattet og differentierbart alternativ til argmax-funktionen. På grund af dette kaldes softmax-funktionen nogle gange mere eksplicit for softargmax-funktionen. Ligesom softmax fungerer argmax-funktionen på en vektor og konverterer alle værdier til nul undtagen den maksimale værdi, hvor den returnerer 1.

Det er almindeligt at træne en maskinlæringsmodel ved hjælp af softmax, men skifte softmax-laget ud med et argmax-lag, når modellen bruges til inferens.
Vi skal bruge softmax i træningen, fordi softmax er differentierbar, og den giver os mulighed for at optimere en omkostningsfunktion. Til inferens har vi dog nogle gange brug for en model, der blot skal udstede en enkelt forudsagt værdi i stedet for en sandsynlighed, og i så fald er argmax mere nyttig.
Når der er flere maksimumværdier, er det almindeligt, at argmax returnerer 1/Nmax, dvs. en normaliseret brøkdel, således at summen af udgangselementerne forbliver 1 som med softmax. En alternativ definition er at returnere 1 for alle maksimumværdier eller kun for den første værdi.
Beregning af softmax-funktion vs. argmax-funktion
Lad os igen forestille os inputvektoren . Vi beregner softmax som før. Den største værdi er det første element, så argmax vil returnere 1 for det første element og 0 for resten.

Det fremgår tydeligt af dette eksempel, at softmax opfører sig som en “blød” tilnærmelse til argmax: den returnerer ikke-integrale værdier mellem 0 og 1, der kan fortolkes som sandsynligheder. Hvis vi bruger en maskinlæringsmodel til inferens i stedet for at træne den, ønsker vi måske et heltalsoutput fra systemet, der repræsenterer en hård beslutning, som vi vil træffe med modellens output, f.eks. at behandle en tumor, autentificere en bruger eller tildele et dokument til et emne. Argmax-værdierne er lettere at arbejde med i denne forstand og kan bruges til at opbygge en forvekslingsmatrix og beregne præcisionen og tilbagekaldelsen af en klassifikator.
Anvendelser af softmax-funktionen
Softmax-funktionen i neurale netværk
En anvendelse af softmax-funktionen ville være i slutningen af et neuralt netværk. Lad os overveje et konvolutionelt neuralt netværk, som genkender, om et billede er en kat eller en hund. Bemærk, at et billede skal være enten en kat eller en hund og ikke kan være begge dele, og at de to klasser derfor udelukker hinanden gensidigt. Typisk vil det sidste fuldt forbundne lag af dette netværk producere værdier som f.eks. værdier, der ikke er normaliseret og ikke kan fortolkes som sandsynligheder. Hvis vi tilføjer et softmax-lag til netværket, er det muligt at oversætte tallene til en sandsynlighedsfordeling. Det betyder, at output kan vises for en bruger, f.eks. at appen er 95 % sikker på, at dette er en kat. Det betyder også, at outputtet kan føres ind i andre maskinlæringsalgoritmer uden at skulle normaliseres, da det er garanteret at ligge mellem 0 og 1.
Bemærk, at hvis netværket klassificerer billeder i hunde og katte og er konfigureret til kun at have to outputklasser, så er det tvunget til at kategorisere hvert billede som enten hund eller kat, selv om det hverken er hund eller kat, selv om det er det ene eller det andet. Hvis vi skal tillade denne mulighed, skal vi omkonfigurere det neurale netværk til at have et tredje output for diverse.
Eksempel på beregning af softmax i et neuralt netværk
Den softmax er vigtig, når vi træner et neuralt netværk. Forestil dig, at vi har et konvolutionelt neuralt netværk, der skal lære at skelne mellem katte og hunde. Vi indstiller kat til at være klasse 1 og hund til at være klasse 2.
Ideelt set ville netværket, når vi indtaster et billede af en kat i vores netværk, outputte vektoren . Når vi indtaster et billede af en hund, vil vi have et output .
Den neurale netværks billedbehandling slutter ved det sidste fuldt forbundne lag. Dette lag udsender to scoringer for kat og hund, som ikke er sandsynligheder. Det er almindelig praksis at tilføje et softmax-lag til sidst i det neurale netværk, som omdanner output til en sandsynlighedsfordeling.I starten af træningen er vægtene i det neurale netværk tilfældigt konfigureret. Så kattebilledet går igennem og konverteres af billedbehandlingsfaserne til scoringer . Ved at passere ind i softmax-funktionen kan vi få de indledende sandsynligheder

Det er klart, at dette ikke er ønskeligt. Et perfekt netværk ville i dette tilfælde output .

Vi kan formulere en tabsfunktion for vores netværk, som kvantificerer, hvor langt netværkets output-sandsynligheder er fra de ønskede værdier. Jo mindre tabsfunktionen er, jo tættere er outputvektoren på den korrekte klasse. Den mest almindelige tabsfunktion i dette tilfælde er krydsentropitabet, som i dette tilfælde kommer til:
Da softmax er en kontinuert differentierbar funktion, er det muligt at beregne tabsfunktionens afledning i forhold til hver vægt i netværket, for hvert billede i træningsmængden.
Denne egenskab giver os mulighed for at justere netværkets vægte for at reducere tabsfunktionen og få netværkets output tættere på de ønskede værdier og forbedre netværkets nøjagtighed.Efter flere iterationer af træningen opdaterer vi netværkets vægte. Når det samme kattebillede nu indlæses i netværket, udsender det fuldt forbundne lag en scorevektor på . Ved at sætte dette gennem softmax-funktionen igen får vi udgangssandsynligheder:

Dette er klart et bedre resultat og tættere på det ønskede output på . Ved at genberegne tabet på tværs af entropien,

ser vi, at tabet er blevet mindre, hvilket indikerer, at det neurale netværk er blevet bedre.
Metoden med at differentiere tabsfunktionen for at finde ud af, hvordan vægtene i netværket skal justeres, ville ikke have været mulig, hvis vi havde brugt argmax-funktionen, fordi den ikke er differentierbar. Egenskaben differentiabilitet gør softmax-funktionen nyttig til træning af neurale netværk.
Softmax-funktionen i forstærkningslæring
I forstærkningslæring anvendes softmax-funktionen også, når en model skal beslutte sig mellem at foretage den handling, som man på nuværende tidspunkt ved har den højeste sandsynlighed for en belønning, kaldet
udnyttelse, eller at foretage et udforskende skridt, kaldet udforskning.
Eksempel på beregning af softmax i forstærkende læring
Forestil dig, at vi træner en forstærkende læringsmodel til at spille poker mod et menneske. Vi skal konfigurere en temperatur τ, som fastsætter, hvor sandsynligt det er, at systemet foretager tilfældige udforskende handlinger. Systemet har i øjeblikket to muligheder: at spille et es eller at spille en konge. Ud fra det, det har lært indtil nu, er det 80 % sandsynligt, at det er den vindende strategi i den aktuelle situation at spille et es. Hvis man antager, at der ikke er andre mulige spil, er det 20 % sandsynligt, at det er den vindende strategi at spille en konge. Vi har konfigureret temperaturen τ til 2.
Det forstærkende læringssystem anvender softmax-funktionen til at opnå sandsynligheden for at spille henholdsvis et es og en konge. Den modificerede softmax-formel, der anvendes i reinforcement learning, er som følger:

Reinforcement Learning Softmax Formula Symboler Forklaret
| Sandsynligheden for, at modellen nu vil foretage handling a på tidspunktet t. | |
| Den handling, som vi overvejer at foretage. F.eks. at spille en konge eller et es. | |
 |
Systemets temperatur, der er konfigureret som en hyperparameter. |
|
Det aktuelle bedste skøn over sandsynligheden for succes, hvis vi foretager handling i, ud fra det, modellen har lært indtil nu. |
Sætter vi vores værdier ind i ligningen, får vi:

Det betyder, at selv om modellen i øjeblikket er 80 % sikker på, at esset er den rigtige strategi, er det kun 57 % sandsynligt, at den vil spille det kort. Det skyldes, at vi i forstærkende læring tildeler en værdi til udforskning (afprøvning af nye strategier) såvel som udnyttelse (anvendelse af kendte strategier). Hvis vi vælger at øge temperaturen, bliver modellen mere “impulsiv”: den er mere tilbøjelig til at tage udforskende skridt i stedet for altid at spille den vindende strategi.
Softmax historie
Den første kendte anvendelse af softmax-funktionen går forud for maskinlæring. Softmax-funktionen er faktisk lånt fra fysik og statistisk mekanik, hvor den er kendt som Boltzmann-fordelingen eller Gibbs-fordelingen. Den blev formuleret af den østrigske fysiker og filosof Ludwig Boltzmann i 1868.
Boltzmann studerede den statistiske mekanik for gasser i termisk ligevægt. Han fandt ud af, at Boltzmann-fordelingen kunne beskrive sandsynligheden for at finde et system i en bestemt tilstand, givet denne tilstands energi og systemets temperatur. Hans version af formlen svarede til den, der anvendes i forbindelse med forstærket indlæring. Faktisk kaldes parameteren τ for temperatur inden for reinforcement learning som en hyldest til Boltzmann.
I 1902 gjorde den amerikanske fysiker og kemiker Josiah Willard Gibbs Boltzmann-fordelingen populær, da han brugte den til at lægge grunden til termodynamikken og sin definition af entropi. Den danner også grundlaget for spektroskopi, dvs. analyse af materialer ved at se på det lys, de absorberer og reflekterer.
I 1959 foreslog Robert Duncan Luce brugen af softmax-funktionen til forstærkningsindlæring i sin bog Individual Choice Behavior (adfærd ved individuelle valg): A Theoretical Analysis. Endelig foreslog John S. Bridle i 1989, at argmax i feedforward neurale netværk bør erstattes af softmax, fordi den “bevarer rangordenen af sine inputværdier og er en differentierbar generalisering af ‘winner-take-all’-operationen, hvor man vælger den maksimale værdi”. I de seneste år, efterhånden som neurale netværk er blevet meget udbredt, er softmax blevet velkendt takket være disse egenskaber.