- ¿Qué es la función softmax?
- Fórmula del softmax
- Explicación de los símbolos de la fórmula softmax
- Calcular el Softmax
- Función softmax vs Función Sigmoide
- Cálculo de la función softmax frente a la función sigmoide
- Función softmax vs Función Argmax
- Cálculo de la función softmax frente a la función argmax
- Aplicaciones de la función softmax
- Función softmax en redes neuronales
- Ejemplo de cálculo de Softmax en una red neuronal
- Función softmax en el aprendizaje por refuerzo
- Ejemplo de cálculo de Softmax en el aprendizaje por refuerzo
- Explicación de los símbolos de la fórmula softmax del aprendizaje por refuerzo
- Historia del softmax
¿Qué es la función softmax?
La función softmax es una función que convierte un vector de K valores reales en un vector de K valores reales que suman 1. Los valores de entrada pueden ser positivos, negativos, cero o mayores que uno, pero el softmax los transforma en valores entre 0 y 1, de forma que puedan ser interpretados como probabilidades. Si una de las entradas es pequeña o negativa, el softmax la convierte en una probabilidad pequeña, y si una entrada es grande, entonces la convierte en una probabilidad grande, pero siempre permanecerá entre 0 y 1.
La función softmax se llama a veces función softargmax, o regresión logística multiclase. Esto se debe a que la softmax es una generalización de la regresión logística que puede utilizarse para la clasificación multiclase, y su fórmula es muy similar a la función sigmoidea que se utiliza para la regresión logística. La función softmax se puede utilizar en un clasificador sólo cuando las clases son mutuamente excluyentes.
Muchas redes neuronales multicapa terminan en una penúltima capa que emite puntuaciones de valor real que no están convenientemente escaladas y que pueden ser difíciles de trabajar. Aquí el softmax es muy útil porque convierte las puntuaciones en una distribución de probabilidad normalizada, que puede mostrarse a un usuario o utilizarse como entrada para otros sistemas. Por esta razón es habitual añadir una función softmax como capa final de la red neuronal.
Fórmula del softmax
La fórmula del softmax es la siguiente:
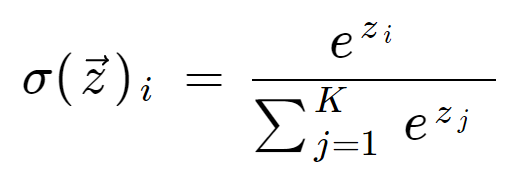
Definición matemática de la función softmax
donde todos los valores zi son los elementos del vector de entrada y pueden tomar cualquier valor real. El término de la parte inferior de la fórmula es el término de normalización que asegura que todos los valores de salida de la función sumarán 1, constituyendo así una distribución de probabilidad válida.
Explicación de los símbolos de la fórmula softmax
| El vector de entrada a la función softmax, formado por (z0, … zK) | |
| Todos los valores zi son los elementos del vector de entrada a la función softmax, y pueden tomar cualquier valor real, positivo, cero o negativo. Por ejemplo, una red neuronal podría tener como salida un vector como (-0,62, 8,12, 2,53), que no es una distribución de probabilidad válida, por lo que el softmax sería necesario. | |
 |
La función exponencial estándar se aplica a cada elemento del vector de entrada. Esto da un valor positivo por encima de 0, que será muy pequeño si la entrada era negativa, y muy grande si la entrada era grande. Sin embargo, todavía no se fija en el rango (0, 1) que es lo que se requiere de una probabilidad. |
 |
El término en la parte inferior de la fórmula es el término de normalización. Asegura que todos los valores de salida de la función sumarán 1 y cada uno estará en el rango (0, 1), constituyendo así una distribución de probabilidad válida. |
| El número de clases en el clasificador multiclase. |
Calcular el Softmax
Imagina que tenemos una matriz de tres valores reales. Estos valores podrían ser típicamente la salida de un modelo de aprendizaje automático como una red neuronal. Queremos convertir los valores en una distribución de probabilidad.

Primero podemos calcular la exponencial de cada elemento de la matriz de entrada. Este es el término en la mitad superior de la ecuación softmax.
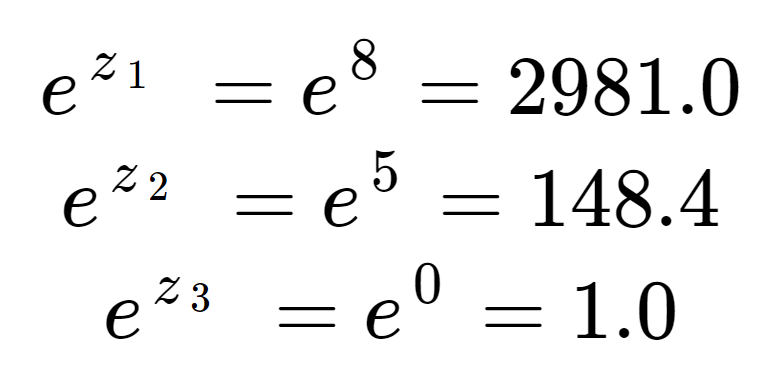
Estos valores aún no se ven como probabilidades. Nótese que en los elementos de entrada, aunque 8 es sólo un poco más grande que 5, 2981 es mucho más grande que 148 debido al efecto de la exponencial. Podemos obtener el término de normalización, la mitad inferior de la ecuación softmax, sumando los tres términos exponenciales:

Vemos que el término de normalización ha sido dominado por z1.
Finalmente, dividiendo por el término de normalización, obtenemos la salida softmax para cada uno de los tres elementos. Obsérvese que no hay un único valor de salida porque el softmax transforma un array en un array de la misma longitud, en este caso 3.
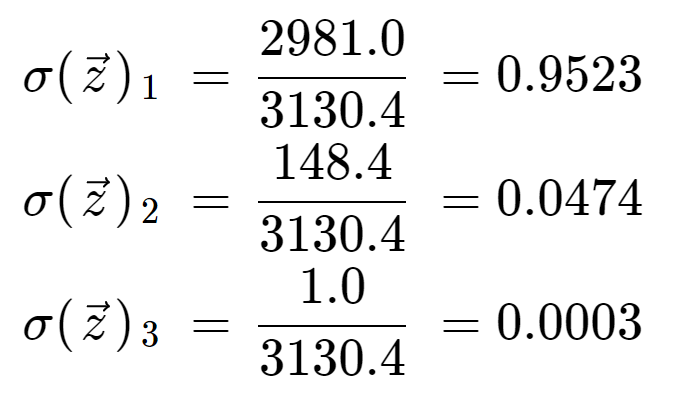
Es informativo comprobar que tenemos tres valores de salida que son todos probabilidades válidas, es decir, están entre 0 y 1, y suman 1.
Nótese también que debido a la operación exponencial, el primer elemento, el 8, ha dominado la función softmax y ha exprimido el 5 y el 0 en valores de probabilidad muy bajos.
Si utilizas la función softmax en un modelo de aprendizaje automático, debes tener cuidado antes de interpretarla como una probabilidad real, ya que tiene una tendencia a producir valores muy cercanos a 0 o 1. Si una red neuronal tuviera puntuaciones de salida de , como en este ejemplo, entonces la función softmax habría asignado un 95% de probabilidad a la primera clase, cuando en realidad podría haber habido más incertidumbre en las predicciones de la red neuronal. Esto podría dar la impresión de que la predicción de la red neuronal tenía una alta confianza cuando ese no era el caso.
Función softmax vs Función Sigmoide
Como se mencionó anteriormente, la función softmax y la función sigmoide son similares. La softmax opera sobre un vector mientras que la sigmoide toma un escalar.

De hecho, la función sigmoide es un caso especial de la función softmax para un clasificador con sólo dos clases de entrada. Podemos demostrarlo si fijamos el vector de entrada y calculamos el primer elemento de salida con la fórmula habitual de softmax:

Dividiendo la parte superior e inferior por ex, obtenemos:

Esto demuestra que la función sigmoide se hace equivalente a la función softmax cuando tenemos dos clases. No es necesario calcular el segundo componente del vector explícitamente porque cuando hay dos probabilidades, deben sumar 1. Por lo tanto, si estamos desarrollando un clasificador de dos clases con regresión logística, podemos utilizar la función sigmoide y no necesitamos trabajar con vectores. Pero si tenemos más de dos clases mutuamente excluyentes se debe utilizar la softmax.
Si hay más de dos clases y no son mutuamente excluyentes (un clasificador multietiqueta), entonces el clasificador se puede dividir en múltiples clasificadores binarios, cada uno utilizando su propia función sigmoide.
Cálculo de la función softmax frente a la función sigmoide
Si tomamos un vector de entrada , podemos ponerlo tanto en la función softmax como en la sigmoide. Como la sigmoide toma un valor escalar, ponemos sólo el primer elemento en la función sigmoide.

La función sigmoide da el mismo valor que la softmax para el primer elemento, siempre que el segundo elemento de entrada sea 0. Como la sigmoide nos da una probabilidad, y las dos probabilidades deben sumar 1, no es necesario calcular explícitamente un valor para el segundo elemento.
Función softmax vs Función Argmax
La función softmax fue desarrollada como una alternativa suavizada y diferenciable a la función argmax. Por ello, la función softmax se denomina a veces más explícitamente función softargmax. Al igual que la softmax, la función argmax opera sobre un vector y convierte todos los valores en cero excepto el valor máximo, donde devuelve 1.

Es común entrenar un modelo de aprendizaje automático utilizando la softmax pero cambiar la capa softmax por una capa argmax cuando el modelo se utiliza para la inferencia.
Debemos utilizar la softmax en el entrenamiento porque la softmax es diferenciable y nos permite optimizar una función de coste. Sin embargo, para la inferencia a veces necesitamos un modelo para dar salida a un solo valor predicho en lugar de una probabilidad, en cuyo caso el argmax es más útil.
Cuando hay múltiples valores máximos es común que el argmax devuelva 1/Nmax, es decir una fracción normalizada, de modo que la suma de los elementos de salida sigue siendo 1 como con el softmax. Una definición alternativa es devolver 1 para todos los valores máximos, o sólo para el primer valor.
Cálculo de la función softmax frente a la función argmax
Imaginemos de nuevo el vector de entrada . Calculamos el softmax como antes. El valor más grande es el primer elemento, por lo que la argmax devolverá 1 para el primer elemento y 0 para el resto.

De este ejemplo se desprende que la softmax se comporta como una aproximación «suave» a la argmax: devuelve valores no enteros entre 0 y 1 que pueden interpretarse como probabilidades. Si estamos utilizando un modelo de aprendizaje automático para la inferencia, en lugar de entrenarlo, podríamos querer una salida entera del sistema que represente una decisión dura que tomaremos con la salida del modelo, como tratar un tumor, autenticar a un usuario o asignar un documento a un tema. Los valores argmax son más fáciles de trabajar en este sentido y pueden utilizarse para construir una matriz de confusión y calcular la precisión y el recuerdo de un clasificador.
Aplicaciones de la función softmax
Función softmax en redes neuronales
Un uso de la función softmax sería al final de una red neuronal. Consideremos una red neuronal convolucional que reconoce si una imagen es un gato o un perro. Obsérvese que una imagen debe ser un gato o un perro, y no puede ser ambas cosas, por lo que las dos clases son mutuamente excluyentes. Normalmente, la última capa totalmente conectada de esta red produciría valores como que no están normalizados y no pueden interpretarse como probabilidades. Si añadimos una capa softmax a la red, es posible traducir los números en una distribución de probabilidad. Esto significa que la salida puede ser mostrada a un usuario, por ejemplo, la aplicación está 95% segura de que esto es un gato. También significa que la salida puede ser introducida en otros algoritmos de aprendizaje automático sin necesidad de ser normalizada, ya que se garantiza que se encuentra entre 0 y 1.
Nótese que si la red está clasificando imágenes en perros y gatos, y está configurada para tener sólo dos clases de salida, entonces se ve obligada a categorizar cada imagen como perro o gato, incluso si no es ninguna de ellas. Si necesitamos permitir esta posibilidad, entonces debemos reconfigurar la red neuronal para que tenga una tercera salida para miscelánea.
Ejemplo de cálculo de Softmax en una red neuronal
El softmax es esencial cuando estamos entrenando una red neuronal. Imagina que tenemos una red neuronal convolucional que está aprendiendo a distinguir entre perros y gatos. Establecemos que el gato es la clase 1 y el perro es la clase 2.
En realidad, cuando introducimos una imagen de un gato en nuestra red, la red emitiría el vector . Cuando introducimos una imagen de un perro, queremos una salida .
El procesamiento de imágenes de la red neuronal termina en la última capa totalmente conectada. Esta capa produce dos puntuaciones para el gato y el perro, que no son probabilidades. Es una práctica habitual añadir una capa softmax al final de la red neuronal, que convierte la salida en una distribución de probabilidad.Al comienzo del entrenamiento, los pesos de la red neuronal se configuran aleatoriamente. Así, la imagen del gato pasa y es convertida por las etapas de procesamiento de la imagen en puntuaciones . Pasando a la función softmax podemos obtener las probabilidades iniciales

Claramente esto no es deseable. Una red perfecta en este caso daría como resultado .

Podemos formular una función de pérdida de nuestra red que cuantifica lo lejos que están las probabilidades de salida de la red de los valores deseados. Cuanto más pequeña sea la función de pérdida, más cerca estará el vector de salida de la clase correcta. La función de pérdida más común en este caso es la pérdida de entropía cruzada que en este caso viene a ser:
Debido a que el softmax es una función continuamente diferenciable, es posible calcular la derivada de la función de pérdida con respecto a cada peso de la red, para cada imagen del conjunto de entrenamiento.
Esta propiedad nos permite ajustar los pesos de la red para reducir la función de pérdida y hacer que la salida de la red se acerque a los valores deseados y mejorar la precisión de la red.Después de varias iteraciones de entrenamiento, actualizamos los pesos de la red. Ahora, cuando se introduce la misma imagen de un gato en la red, la capa totalmente conectada da como resultado un vector de puntuación de . Al pasar esto por la función softmax de nuevo, obtenemos las probabilidades de salida:

Este es claramente un resultado mejor y más cercano a la salida deseada de . Recalculando la pérdida de entropía cruzada,

vemos que la pérdida se ha reducido, lo que indica que la red neuronal ha mejorado.
El método de diferenciar la función de pérdida para saber cómo ajustar los pesos de la red no habría sido posible si hubiéramos utilizado la función argmax, porque no es diferenciable. La propiedad de diferenciabilidad hace que la función softmax sea útil para el entrenamiento de redes neuronales.
Función softmax en el aprendizaje por refuerzo
En el aprendizaje por refuerzo, la función softmax también se utiliza cuando un modelo necesita decidir entre tomar la acción que actualmente se sabe que tiene la mayor probabilidad de obtener una recompensa, llamada
explotación, o dar un paso exploratorio, llamado exploración.
Ejemplo de cálculo de Softmax en el aprendizaje por refuerzo
Imagina que estamos entrenando un modelo de aprendizaje por refuerzo para jugar al póker contra un humano. Debemos configurar una temperatura τ, que establece la probabilidad de que el sistema realice acciones exploratorias aleatorias. El sistema tiene actualmente dos opciones: jugar un as o jugar un rey. Por lo que ha aprendido hasta ahora, jugar un as tiene un 80% de probabilidades de ser la estrategia ganadora en la situación actual. Suponiendo que no hay otras jugadas posibles, jugar un rey tiene un 20% de probabilidades de ser la estrategia ganadora. Hemos configurado la temperatura τ a 2.
El sistema de aprendizaje por refuerzo utiliza la función softmax para obtener la probabilidad de jugar un As y un Rey respectivamente. La fórmula softmax modificada que se utiliza en el aprendizaje por refuerzo es la siguiente:

Explicación de los símbolos de la fórmula softmax del aprendizaje por refuerzo
| La probabilidad de que el modelo tome ahora la acción a en el tiempo t. | |
 |
La temperatura del sistema, configurada como hiperparámetro. |
|
La mejor estimación actual de la probabilidad de éxito si tomamos la acción i, a partir de lo que el modelo ha aprendido hasta ahora. |
Poniendo nuestros valores en la ecuación obtenemos:

Esto significa que aunque el modelo está actualmente un 80% seguro de que el As es la estrategia correcta, sólo tiene un 57% de probabilidades de jugar esa carta. Esto se debe a que en el aprendizaje por refuerzo asignamos un valor a la exploración (probar nuevas estrategias) y a la explotación (utilizar estrategias conocidas). Si elegimos aumentar la temperatura, el modelo se vuelve más «impulsivo»: es más probable que dé pasos exploratorios en lugar de jugar siempre la estrategia ganadora.
Historia del softmax
El primer uso conocido de la función softmax es anterior al aprendizaje automático. De hecho, la función softmax está tomada de la física y la mecánica estadística, donde se conoce como la distribución de Boltzmann o la distribución de Gibbs. Fue formulada por el físico y filósofo austriaco Ludwig Boltzmann en 1868.
Boltzmann estaba estudiando la mecánica estadística de los gases en equilibrio térmico. Descubrió que la distribución de Boltzmann podía describir la probabilidad de encontrar un sistema en un determinado estado, dada la energía de ese estado y la temperatura del sistema. Su versión de la fórmula era similar a la utilizada en el aprendizaje por refuerzo. De hecho, el parámetro τ se denomina temperatura en el campo del aprendizaje por refuerzo como homenaje a Boltzmann.
En 1902 el físico y químico estadounidense Josiah Willard Gibbs popularizó la distribución de Boltzmann cuando la utilizó para sentar las bases de la termodinámica y su definición de entropía. También constituye la base de la espectroscopia, es decir, el análisis de los materiales observando la luz que absorben y reflejan.
En 1959 Robert Duncan Luce propuso el uso de la función softmax para el aprendizaje por refuerzo en su libro Individual Choice Behavior: A Theoretical Analysis. Finalmente, en 1989, John S. Bridle sugirió que la función argmax en las redes neuronales de avance debería ser sustituida por la función softmax porque «preserva el orden de los valores de entrada y es una generalización diferenciable de la operación ‘winner-take-all’ de elegir el valor máximo». En los últimos años, al generalizarse el uso de las redes neuronales, el softmax se ha hecho muy conocido gracias a estas propiedades.