- Qu’est-ce que la fonction softmax ?
- Formule softmax
- Symboles de la formule softmax expliqués
- Calcul du Softmax
- Fonction softmax vs fonction sigmoïde
- Calcul de la fonction softmax par rapport à la fonction sigmoïde
- Fonction softmax vs fonction argmax
- Calcul de la fonction softmax par rapport à la fonction argmax
- Applications de la fonction softmax
- Fonction softmax dans les réseaux neuronaux
- Exemple de calcul de la softmax dans un réseau neuronal
- Fonction softmax dans l’apprentissage par renforcement
- Exemple de calcul de la Softmax dans l’apprentissage par renforcement
- Les symboles de la formule softmax de l’apprentissage par renforcement expliqués
- Histoire de la softmax
Qu’est-ce que la fonction softmax ?
La fonction softmax est une fonction qui transforme un vecteur de K valeurs réelles en un vecteur de K valeurs réelles dont la somme est égale à 1. Les valeurs d’entrée peuvent être positives, négatives, nulles ou supérieures à 1, mais la softmax les transforme en valeurs comprises entre 0 et 1, afin qu’elles puissent être interprétées comme des probabilités. Si une des entrées est petite ou négative, la softmax la transforme en une petite probabilité, et si une entrée est grande, alors elle la transforme en une grande probabilité, mais elle restera toujours entre 0 et 1.
La fonction softmax est parfois appelée fonction softargmax, ou régression logistique multi-classes. C’est parce que la softmax est une généralisation de la régression logistique qui peut être utilisée pour la classification multi-classes, et sa formule est très similaire à la fonction sigmoïde qui est utilisée pour la régression logistique. La fonction softmax ne peut être utilisée dans un classificateur que lorsque les classes sont mutuellement exclusives.
De nombreux réseaux neuronaux multicouches se terminent par une avant-dernière couche qui sort des scores à valeur réelle qui ne sont pas commodément mis à l’échelle et avec lesquels il peut être difficile de travailler. Ici, le softmax est très utile car il convertit les scores en une distribution de probabilité normalisée, qui peut être affichée à un utilisateur ou utilisée comme entrée pour d’autres systèmes. Pour cette raison, il est habituel d’annexer une fonction softmax comme couche finale du réseau neuronal.
Formule softmax
La formule softmax est la suivante:
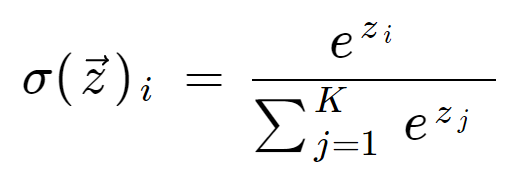
Définition mathématique de la fonction softmax
où toutes les valeurs zi sont les éléments du vecteur d’entrée et peuvent prendre n’importe quelle valeur réelle. Le terme au bas de la formule est le terme de normalisation qui garantit que toutes les valeurs de sortie de la fonction feront la somme de 1, constituant ainsi une distribution de probabilité valide.
Symboles de la formule softmax expliqués
| Le vecteur d’entrée de la fonction softmax, composé de (z0, …. zK) | |
| Toutes les valeurs zi sont les éléments du vecteur d’entrée de la fonction softmax, et elles peuvent prendre n’importe quelle valeur réelle, positive, nulle ou négative. Par exemple, un réseau neuronal aurait pu sortir un vecteur tel que (-0,62, 8,12, 2,53), qui n’est pas une distribution de probabilité valide, d’où la nécessité de la fonction softmax. | |
 |
La fonction exponentielle standard est appliquée à chaque élément du vecteur d’entrée. Cela donne une valeur positive supérieure à 0, qui sera très petite si l’entrée était négative, et très grande si l’entrée était grande. Cependant, elle n’est toujours pas fixée dans l’intervalle (0, 1), ce qui est ce qui est requis d’une probabilité. |
 |
Le terme en bas de la formule est le terme de normalisation. Il garantit que toutes les valeurs de sortie de la fonction feront la somme de 1 et seront chacune dans l’intervalle (0, 1), constituant ainsi une distribution de probabilité valide. |
| Le nombre de classes dans le classificateur multi-classes. |
Calcul du Softmax
Imaginez que nous avons un tableau de trois valeurs réelles. Ces valeurs pourraient typiquement être la sortie d’un modèle d’apprentissage automatique tel qu’un réseau neuronal. Nous voulons convertir les valeurs en une distribution de probabilité.

D’abord, nous pouvons calculer l’exponentielle de chaque élément du tableau d’entrée. C’est le terme de la moitié supérieure de l’équation du softmax.
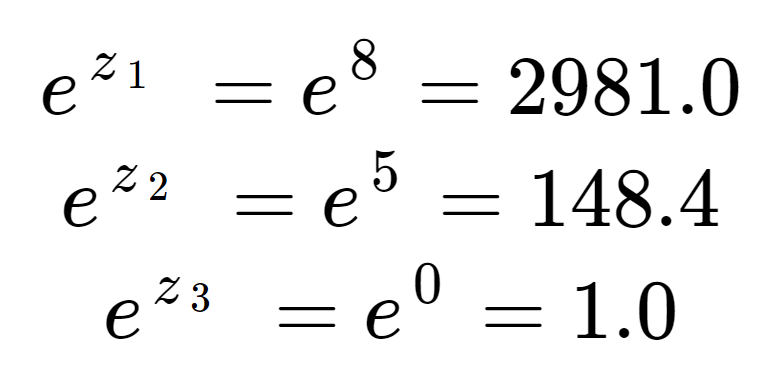
Ces valeurs ne ressemblent pas encore à des probabilités. Notez que dans les éléments d’entrée, bien que 8 soit seulement un peu plus grand que 5, 2981 est beaucoup plus grand que 148 en raison de l’effet de l’exponentielle. Nous pouvons obtenir le terme de normalisation, la moitié inférieure de l’équation du softmax, en additionnant les trois termes exponentiels :

Nous voyons que le terme de normalisation a été dominé par z1.
Enfin, en divisant par le terme de normalisation, nous obtenons la sortie du softmax pour chacun des trois éléments. Notez qu’il n’y a pas une seule valeur de sortie car le softmax transforme un tableau en un tableau de même longueur, en l’occurrence 3.
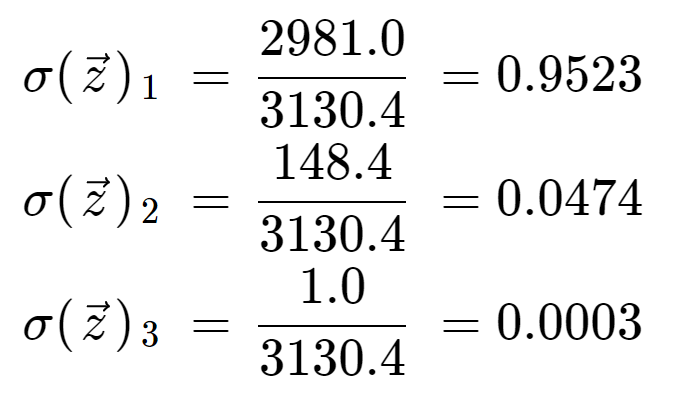
Il est informatif de vérifier que nous avons trois valeurs de sortie qui sont toutes des probabilités valides, c’est-à-dire qu’elles sont comprises entre 0 et 1, et que leur somme est égale à 1.
Notez également qu’en raison de l’opération exponentielle, le premier élément, le 8, a dominé la fonction softmax et a évincé le 5 et le 0 dans des valeurs de probabilité très faibles.
Si vous utilisez la fonction softmax dans un modèle d’apprentissage automatique, vous devez être prudent avant de l’interpréter comme une véritable probabilité, car elle a tendance à produire des valeurs très proches de 0 ou 1. Si un réseau neuronal a obtenu des scores de sortie de , comme dans cet exemple, la fonction softmax aurait attribué une probabilité de 95 % à la première classe, alors qu’en réalité, les prédictions du réseau neuronal auraient pu être plus incertaines. Cela pourrait donner l’impression que la prédiction du réseau neuronal avait une confiance élevée alors que ce n’était pas le cas.
Fonction softmax vs fonction sigmoïde
Comme mentionné ci-dessus, la fonction softmax et la fonction sigmoïde sont similaires. La softmax opère sur un vecteur alors que la sigmoïde prend un scalaire.

En fait, la fonction sigmoïde est un cas particulier de la fonction softmax pour un classificateur avec seulement deux classes d’entrée. Nous pouvons le montrer si nous fixons le vecteur d’entrée à et calculons le premier élément de sortie avec la formule habituelle de la fonction softmax:

En divisant le haut et le bas par ex, nous obtenons:

Cela montre que la fonction sigmoïde devient équivalente à la fonction softmax lorsque nous avons deux classes. Il n’est pas nécessaire de calculer explicitement la deuxième composante vectorielle car lorsqu’il y a deux probabilités, leur somme doit être égale à 1.Ainsi, si nous développons un classificateur à deux classes avec une régression logistique, nous pouvons utiliser la fonction sigmoïde et n’avons pas besoin de travailler avec des vecteurs. Mais si nous avons plus de deux classes mutuellement exclusives, la softmax doit être utilisée.
S’il y a plus de deux classes et qu’elles ne sont pas mutuellement exclusives (un classificateur multi-label), alors le classificateur peut être divisé en plusieurs classificateurs binaires, chacun utilisant sa propre fonction sigmoïde.
Calcul de la fonction softmax par rapport à la fonction sigmoïde
Si nous prenons un vecteur d’entrée , nous pouvons le mettre dans les fonctions softmax et sigmoïde. Comme la sigmoïde prend une valeur scalaire, nous ne mettons que le premier élément dans la fonction sigmoïde.

La fonction sigmoïde donne la même valeur que la softmax pour le premier élément, à condition que le deuxième élément d’entrée soit mis à 0. Puisque la sigmoïde nous donne une probabilité, et que les deux probabilités doivent s’additionner à 1, il n’est pas nécessaire de calculer explicitement une valeur pour le deuxième élément.
Fonction softmax vs fonction argmax
La fonction softmax a été développée comme une alternative lissée et différentiable à la fonction argmax. De ce fait, la fonction softmax est parfois plus explicitement appelée fonction softargmax. Comme la softmax, la fonction argmax opère sur un vecteur et convertit chaque valeur en zéro sauf la valeur maximale, où elle renvoie 1.

Il est courant de former un modèle d’apprentissage automatique en utilisant la softmax mais de remplacer la couche softmax par une couche argmax lorsque le modèle est utilisé pour l’inférence.
Nous devons utiliser la softmax dans la formation parce que la softmax est différentiable et qu’elle nous permet d’optimiser une fonction de coût. Cependant, pour l’inférence, nous avons parfois besoin d’un modèle juste pour sortir une seule valeur prédite plutôt qu’une probabilité, dans ce cas l’argmax est plus utile.
Lorsqu’il y a plusieurs valeurs maximales, il est courant que l’argmax renvoie 1/Nmax, c’est-à-dire une fraction normalisée, de sorte que la somme des éléments de sortie reste 1 comme avec le softmax. Une autre définition consiste à retourner 1 pour toutes les valeurs maximales, ou pour la première valeur seulement.
Calcul de la fonction softmax par rapport à la fonction argmax
Imaginons à nouveau le vecteur d’entrée . Nous calculons la softmax comme précédemment. La plus grande valeur est le premier élément, donc l’argmax retournera 1 pour le premier élément et 0 pour le reste.

Il est clair à partir de cet exemple que la softmax se comporte comme une approximation « douce » de l’argmax : elle retourne des valeurs non entières entre 0 et 1 qui peuvent être interprétées comme des probabilités. Si nous utilisons un modèle d’apprentissage automatique pour l’inférence, plutôt que de l’entraîner, nous pouvons vouloir une sortie entière du système représentant une décision ferme que nous prendrons avec la sortie du modèle, comme le traitement d’une tumeur, l’authentification d’un utilisateur ou l’attribution d’un document à un sujet. Les valeurs argmax sont plus faciles à travailler dans ce sens et peuvent être utilisées pour construire une matrice de confusion et calculer la précision et le rappel d’un classificateur.
Applications de la fonction softmax
Fonction softmax dans les réseaux neuronaux
Une utilisation de la fonction softmax serait à la fin d’un réseau neuronal. Considérons un réseau neuronal convolutif qui reconnaît si une image est un chat ou un chien. Notez qu’une image doit être soit un chat, soit un chien, et ne peut pas être les deux, donc les deux classes sont mutuellement exclusives. Typiquement, la couche finale entièrement connectée de ce réseau produirait des valeurs comme qui ne sont pas normalisées et ne peuvent pas être interprétées comme des probabilités. Si nous ajoutons une couche softmax au réseau, il est possible de traduire les chiffres en une distribution de probabilité. Cela signifie que le résultat peut être affiché à l’utilisateur, par exemple l’application est sûre à 95 % qu’il s’agit d’un chat. Cela signifie également que la sortie peut être introduite dans d’autres algorithmes d’apprentissage automatique sans avoir besoin d’être normalisée, puisqu’elle est garantie entre 0 et 1.
Notez que si le réseau classe les images en chiens et chats, et qu’il est configuré pour n’avoir que deux classes de sortie, alors il est obligé de classer chaque image comme chien ou chat, même si ce n’est ni l’un ni l’autre. Si nous devons permettre cette possibilité, alors nous devons reconfigurer le réseau neuronal pour avoir une troisième sortie pour divers.
Exemple de calcul de la softmax dans un réseau neuronal
La softmax est essentielle lorsque nous formons un réseau neuronal. Imaginons que nous ayons un réseau neuronal convolutif qui apprend à distinguer les chats des chiens. Nous définissons le chat comme étant la classe 1 et le chien comme étant la classe 2.
Idéalement, lorsque nous entrons une image de chat dans notre réseau, le réseau sortirait le vecteur . Lorsque nous entrons une image de chien, nous voulons une sortie .
Le traitement d’image du réseau neuronal se termine à la couche finale entièrement connectée. Cette couche produit deux scores pour le chat et le chien, qui ne sont pas des probabilités. Il est d’usage d’ajouter une couche softmax à la fin du réseau neuronal, qui convertit la sortie en une distribution de probabilités.Au début de la formation, les poids du réseau neuronal sont configurés de manière aléatoire. Ainsi, l’image du chat passe et est convertie par les étapes de traitement d’image en scores . En passant dans la fonction softmax, nous pouvons obtenir les probabilités initiales

Il est clair que ce n’est pas souhaitable. Un réseau parfait dans ce cas sortirait .

Nous pouvons formuler une fonction de perte de notre réseau qui quantifie la distance entre les probabilités de sortie du réseau et les valeurs souhaitées. Plus la fonction de perte est petite, plus le vecteur de sortie est proche de la bonne classe. La fonction de perte la plus courante dans ce cas est la perte d’entropie croisée qui, dans ce cas, revient à :
Parce que la softmax est une fonction continuellement différentiable, il est possible de calculer la dérivée de la fonction de perte par rapport à chaque poids du réseau, pour chaque image de l’ensemble d’apprentissage.
Cette propriété nous permet d’ajuster les poids du réseau afin de réduire la fonction de perte et de rendre la sortie du réseau plus proche des valeurs souhaitées et d’améliorer la précision du réseau.Après plusieurs itérations d’apprentissage, nous mettons à jour les poids du réseau. Après plusieurs itérations d’apprentissage, nous mettons à jour les poids du réseau. Maintenant, lorsque la même image de chat est entrée dans le réseau, la couche entièrement connectée sort un vecteur de score de . En passant à nouveau par la fonction softmax, nous obtenons des probabilités de sortie :

C’est clairement un meilleur résultat et plus proche de la sortie souhaitée de . En recalculant la perte d’entropie croisée,

nous constatons que la perte a diminué, ce qui indique que le réseau neuronal s’est amélioré.
La méthode de différenciation de la fonction de perte afin de déterminer comment ajuster les poids du réseau n’aurait pas été possible si nous avions utilisé la fonction argmax, car elle n’est pas différentiable. La propriété de différentiabilité rend la fonction softmax utile pour la formation des réseaux neuronaux.
Fonction softmax dans l’apprentissage par renforcement
Dans l’apprentissage par renforcement, la fonction softmax est également utilisée lorsqu’un modèle doit décider entre prendre l’action actuellement connue pour avoir la plus grande probabilité de récompense, appelée
exploitation, ou prendre une étape exploratoire, appelée exploration.
Exemple de calcul de la Softmax dans l’apprentissage par renforcement
Imaginez que nous formons un modèle d’apprentissage par renforcement pour jouer au poker contre un humain. Nous devons configurer une température τ, qui définit la probabilité que le système prenne des actions exploratoires aléatoires. Le système a actuellement deux options : jouer un As ou jouer un Roi. D’après ce qu’il a appris jusqu’à présent, jouer un As a 80% de chances d’être la stratégie gagnante dans la situation actuelle. En supposant qu’il n’y a pas d’autres jeux possibles, jouer un Roi a 20% de chances d’être la stratégie gagnante. Nous avons configuré la température τ à 2.
Le système d’apprentissage par renforcement utilise la fonction softmax pour obtenir la probabilité de jouer un As et un Roi respectivement. La formule softmax modifiée utilisée dans l’apprentissage par renforcement est la suivante :

Les symboles de la formule softmax de l’apprentissage par renforcement expliqués
| La probabilité que le modèle entreprenne maintenant l’action a au moment t. | |
| L’action que nous envisageons de prendre. Par exemple, jouer un roi ou un as. | |
 |
La température du système, configurée comme un hyperparamètre. |
|
La meilleure estimation actuelle de la probabilité de succès si nous prenons l’action i, à partir de ce que le modèle a appris jusqu’à présent. |
En mettant nos valeurs dans l’équation, nous obtenons :

Cela signifie que même si le modèle est actuellement sûr à 80% que l’As est la bonne stratégie, il n’a que 57% de chances de jouer cette carte. En effet, dans l’apprentissage par renforcement, nous attribuons une valeur à l’exploration (tester de nouvelles stratégies) et à l’exploitation (utiliser des stratégies connues). Si nous choisissons d’augmenter la température, le modèle devient plus » impulsif » : il est plus susceptible de prendre des mesures exploratoires plutôt que de toujours jouer la stratégie gagnante.
Histoire de la softmax
La première utilisation connue de la fonction softmax est antérieure à l’apprentissage automatique. La fonction softmax est en effet empruntée à la physique et à la mécanique statistique, où elle est connue sous le nom de distribution de Boltzmann ou de distribution de Gibbs. Elle a été formulée par le physicien et philosophe autrichien Ludwig Boltzmann en 1868.
Boltzmann étudiait la mécanique statistique des gaz en équilibre thermique. Il a découvert que la distribution de Boltzmann pouvait décrire la probabilité de trouver un système dans un certain état, étant donné l’énergie de cet état, et la température du système. Sa version de la formule était similaire à celle utilisée dans l’apprentissage par renforcement. En effet, le paramètre τ est appelé température dans le domaine de l’apprentissage par renforcement en hommage à Boltzmann.
En 1902, le physicien et chimiste américain Josiah Willard Gibbs a popularisé la distribution de Boltzmann lorsqu’il l’a utilisée pour poser les bases de la thermodynamique et sa définition de l’entropie. Elle constitue également la base de la spectroscopie, c’est-à-dire l’analyse des matériaux en regardant la lumière qu’ils absorbent et réfléchissent.
En 1959, Robert Duncan Luce a proposé l’utilisation de la fonction softmax pour l’apprentissage par renforcement dans son livre Individual Choice Behavior : A Theoretical Analysis. Enfin, en 1989, John S. Bridle a suggéré que l’argmax dans les réseaux neuronaux à anticipation devrait être remplacée par la softmax car elle « préserve l’ordre de classement de ses valeurs d’entrée et constitue une généralisation différentiable de l’opération « winner-take-all » consistant à choisir la valeur maximale ». Ces dernières années, alors que l’utilisation des réseaux neuronaux s’est généralisée, la softmax est devenue bien connue grâce à ces propriétés.