- Was ist die Softmax-Funktion?
- Softmax-Formel
- Erläuterung der Symbole der Softmax-Formel
- Berechnung der Softmax
- Softmax-Funktion vs. Sigmoid-Funktion
- Berechnung der Softmax-Funktion gegenüber der Sigmoid-Funktion
- Softmax-Funktion vs. Argmax-Funktion
- Berechnung der Softmax-Funktion gegenüber der Argmax-Funktion
- Anwendungen der Softmax-Funktion
- Softmax-Funktion in neuronalen Netzen
- Beispiel für die Berechnung von Softmax in einem neuronalen Netz
- Softmax-Funktion im Reinforcement Learning
- Beispiel für die Berechnung von Softmax beim Reinforcement Learning
- Reinforcement Learning Softmax Formula Symbols Explained
- Softmax Geschichte
Was ist die Softmax-Funktion?
Die Softmax-Funktion ist eine Funktion, die einen Vektor von K reellen Werten in einen Vektor von K reellen Werten umwandelt, die sich zu 1 summieren. Die Eingabewerte können positiv, negativ, null oder größer als eins sein, aber die Softmax-Funktion wandelt sie in Werte zwischen 0 und 1 um, so dass sie als Wahrscheinlichkeiten interpretiert werden können. Wenn einer der Eingabewerte klein oder negativ ist, wandelt die Softmax-Funktion ihn in eine kleine Wahrscheinlichkeit um, und wenn ein Eingabewert groß ist, wandelt sie ihn in eine große Wahrscheinlichkeit um, aber er bleibt immer zwischen 0 und 1.
Die Softmax-Funktion wird manchmal als Softargmax-Funktion oder logistische Mehrklassenregression bezeichnet. Dies liegt daran, dass die Softmax-Funktion eine Verallgemeinerung der logistischen Regression ist, die für die Klassifizierung mehrerer Klassen verwendet werden kann, und ihre Formel ist der Sigmoid-Funktion sehr ähnlich, die für die logistische Regression verwendet wird. Die Softmax-Funktion kann in einem Klassifikator nur dann verwendet werden, wenn sich die Klassen gegenseitig ausschließen.
Viele mehrschichtige neuronale Netze enden in einer vorletzten Schicht, die reellwertige Werte ausgibt, die nicht bequem skaliert sind und mit denen es schwierig sein kann zu arbeiten. Hier ist Softmax sehr nützlich, weil es die Ergebnisse in eine normalisierte Wahrscheinlichkeitsverteilung umwandelt, die dem Benutzer angezeigt oder als Eingabe für andere Systeme verwendet werden kann. Aus diesem Grund ist es üblich, eine Softmax-Funktion als letzte Schicht des neuronalen Netzes einzufügen.
Softmax-Formel
Die Softmax-Formel lautet wie folgt:
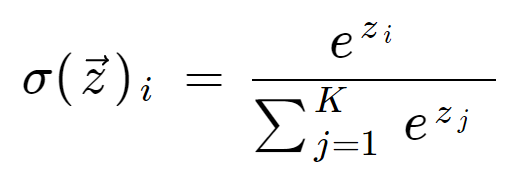
Mathematische Definition der Softmax-Funktion
wobei alle zi-Werte die Elemente des Eingabevektors sind und jeden realen Wert annehmen können. Der Term am Ende der Formel ist der Normalisierungsterm, der sicherstellt, dass alle Ausgangswerte der Funktion die Summe 1 ergeben und somit eine gültige Wahrscheinlichkeitsverteilung darstellen.
Erläuterung der Symbole der Softmax-Formel
| Der Eingangsvektor der Softmax-Funktion, bestehend aus (z0, … zK) | |
| Alle zi-Werte sind die Elemente des Eingabevektors für die Softmax-Funktion, und sie können jeden realen Wert annehmen, positiv, null oder negativ. Ein neuronales Netz könnte beispielsweise einen Vektor wie (-0,62, 8,12, 2,53) ausgeben, was keine gültige Wahrscheinlichkeitsverteilung ist, weshalb die Softmax-Funktion erforderlich wäre. | |
 |
Die Standard-Exponentialfunktion wird auf jedes Element des Eingangsvektors angewendet. Dies ergibt einen positiven Wert über 0, der sehr klein ist, wenn die Eingabe negativ war, und sehr groß, wenn die Eingabe groß war. Der Wert ist jedoch immer noch nicht im Bereich (0, 1) festgelegt, wie es für eine Wahrscheinlichkeit erforderlich ist. |
 |
Der Term am unteren Ende der Formel ist der Normalisierungsterm. Er stellt sicher, dass alle Ausgabewerte der Funktion die Summe 1 ergeben und jeweils im Bereich (0, 1) liegen, so dass sie eine gültige Wahrscheinlichkeitsverteilung darstellen. |
| Die Anzahl der Klassen im Mehrklassen-Klassifikator. |
Berechnung der Softmax
Stellen Sie sich vor, wir haben eine Reihe von drei realen Werten. Diese Werte könnten typischerweise die Ausgabe eines maschinellen Lernmodells sein, z. B. eines neuronalen Netzes. Wir wollen die Werte in eine Wahrscheinlichkeitsverteilung umwandeln.

Zunächst können wir das Exponential jedes Elements des Eingabefeldes berechnen. Dies ist der Term in der oberen Hälfte der Softmax-Gleichung.
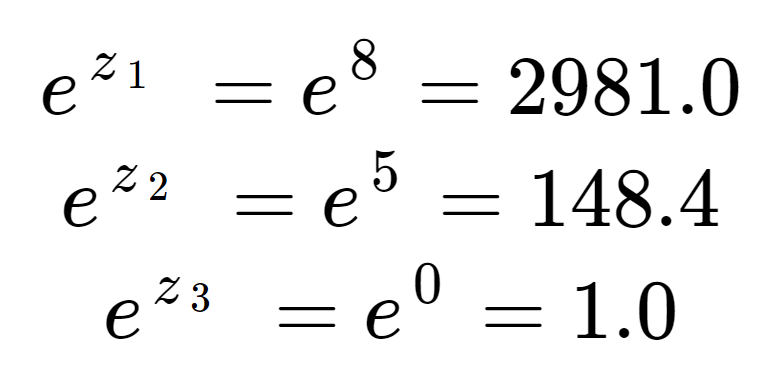
Diese Werte sehen noch nicht wie Wahrscheinlichkeiten aus. Beachten Sie, dass in den Eingabeelementen, obwohl 8 nur ein wenig größer als 5 ist, 2981 aufgrund des Effekts des Exponentials viel größer als 148 ist. Wir können den Normalisierungsterm, die untere Hälfte der Softmax-Gleichung, erhalten, indem wir alle drei Exponentialterme addieren:

Wir sehen, dass der Normalisierungsterm von z1 dominiert wird.
Schließlich erhalten wir durch Division durch den Normalisierungsterm die Softmax-Ausgabe für jedes der drei Elemente. Man beachte, dass es nicht nur einen einzigen Ausgabewert gibt, da Softmax ein Array in ein Array der gleichen Länge, in diesem Fall 3, umwandelt.
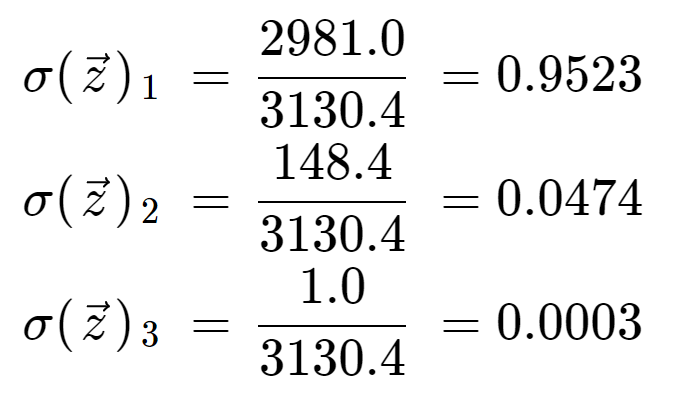
Es ist aufschlussreich zu prüfen, dass wir drei Ausgabewerte haben, die alle gültige Wahrscheinlichkeiten sind, d.h. sie liegen zwischen 0 und 1 und ergeben in der Summe 1.
Beachten Sie auch, dass aufgrund der Exponentialoperation das erste Element, die 8, die Softmax-Funktion dominiert und die 5 und die 0 zu sehr niedrigen Wahrscheinlichkeitswerten verdrängt hat.
Wenn Sie die Softmax-Funktion in einem Modell für maschinelles Lernen verwenden, sollten Sie vorsichtig sein, bevor Sie sie als echte Wahrscheinlichkeit interpretieren, da sie dazu neigt, Werte zu produzieren, die sehr nahe an 0 oder 1 liegen. Wenn ein neuronales Netzwerk wie in diesem Beispiel Ausgabewerte von , hätte die Softmax-Funktion der ersten Klasse eine Wahrscheinlichkeit von 95 % zugewiesen, während in Wirklichkeit mehr Unsicherheit in den Vorhersagen des neuronalen Netzwerks bestanden haben könnte. Dies könnte den Eindruck erwecken, dass die Vorhersage des neuronalen Netzes eine hohe Zuverlässigkeit hat, obwohl dies nicht der Fall ist.
Softmax-Funktion vs. Sigmoid-Funktion
Wie oben erwähnt, sind die Softmax-Funktion und die Sigmoid-Funktion ähnlich. Die Softmax-Funktion arbeitet mit einem Vektor, während die Sigmoid-Funktion einen Skalar annimmt.

In der Tat ist die Sigmoid-Funktion ein Spezialfall der Softmax-Funktion für einen Klassifikator mit nur zwei Eingabeklassen. Wir können dies zeigen, wenn wir den Eingangsvektor auf be setzen und das erste Ausgangselement mit der üblichen Softmax-Formel berechnen:

Teilt man das obere und untere Element durch ex, erhält man:

Das zeigt, dass die Sigmoid-Funktion der Softmax-Funktion entspricht, wenn wir zwei Klassen haben. Es ist nicht notwendig, die zweite Vektorkomponente explizit zu berechnen, denn wenn es zwei Wahrscheinlichkeiten gibt, müssen sie sich zu 1 summieren. Wenn wir also einen Zwei-Klassen-Klassifikator mit logistischer Regression entwickeln, können wir die Sigmoid-Funktion verwenden und müssen nicht mit Vektoren arbeiten. Wenn wir jedoch mehr als zwei sich gegenseitig ausschließende Klassen haben, sollte die Softmax-Funktion verwendet werden.
Wenn es mehr als zwei Klassen gibt und diese sich nicht gegenseitig ausschließen (ein Multi-Label-Klassifikator), dann kann der Klassifikator in mehrere binäre Klassifikatoren aufgeteilt werden, von denen jeder seine eigene Sigmoid-Funktion verwendet.
Berechnung der Softmax-Funktion gegenüber der Sigmoid-Funktion
Wenn wir einen Eingabevektor nehmen, können wir diesen sowohl in die Softmax- als auch in die Sigmoid-Funktion einsetzen. Da die Sigmoid-Funktion einen skalaren Wert annimmt, geben wir nur das erste Element in die Sigmoid-Funktion ein.

Die Sigmoid-Funktion liefert den gleichen Wert wie die Softmax-Funktion für das erste Element, vorausgesetzt, das zweite Eingabeelement wird auf 0 gesetzt. Da die Sigmoidfunktion eine Wahrscheinlichkeit liefert und die beiden Wahrscheinlichkeiten sich zu 1 addieren müssen, ist es nicht notwendig, explizit einen Wert für das zweite Element zu berechnen.
Softmax-Funktion vs. Argmax-Funktion
Die Softmax-Funktion wurde als geglättete und differenzierbare Alternative zur Argmax-Funktion entwickelt. Aus diesem Grund wird die softmax-Funktion manchmal auch explizit als softargmax-Funktion bezeichnet. Wie die softmax-Funktion arbeitet auch die argmax-Funktion mit einem Vektor und wandelt jeden Wert in Null um, mit Ausnahme des Maximalwerts, bei dem sie 1 zurückgibt.

Es ist üblich, ein Modell für maschinelles Lernen mit der softmax-Funktion zu trainieren, aber die softmax-Schicht gegen eine argmax-Schicht auszutauschen, wenn das Modell für Inferenzen verwendet wird.
Wir müssen die softmax-Funktion beim Training verwenden, weil die softmax-Funktion differenzierbar ist und es uns erlaubt, eine Kostenfunktion zu optimieren. In diesem Fall ist argmax nützlicher.
Wenn es mehrere Maximalwerte gibt, ist es üblich, dass argmax 1/Nmax zurückgibt, d.h. einen normalisierten Bruch, so dass die Summe der Ausgabeelemente wie bei softmax 1 bleibt. Eine alternative Definition besteht darin, für alle Maximalwerte oder nur für den ersten Wert 1 zurückzugeben.
Berechnung der Softmax-Funktion gegenüber der Argmax-Funktion
Stellen wir uns wieder den Eingangsvektor vor. Wir berechnen den Softmax wie zuvor. Der größte Wert ist das erste Element, so dass argmax für das erste Element 1 und für den Rest 0 zurückgibt.

Aus diesem Beispiel wird deutlich, dass sich softmax wie eine „weiche“ Annäherung an argmax verhält: Es liefert nicht-ganzzahlige Werte zwischen 0 und 1, die als Wahrscheinlichkeiten interpretiert werden können. Wenn wir ein Modell für maschinelles Lernen nicht trainieren, sondern für Schlussfolgerungen verwenden, möchten wir vielleicht eine ganzzahlige Ausgabe des Systems, die eine harte Entscheidung darstellt, die wir mit der Modellausgabe treffen, z. B. die Behandlung eines Tumors, die Authentifizierung eines Benutzers oder die Zuordnung eines Dokuments zu einem Thema. Die argmax-Werte sind in diesem Sinne einfacher zu handhaben und können verwendet werden, um eine Konfusionsmatrix zu erstellen und die Präzision und den Recall eines Klassifizierers zu berechnen.
Anwendungen der Softmax-Funktion
Softmax-Funktion in neuronalen Netzen
Eine Anwendung der Softmax-Funktion wäre am Ende eines neuronalen Netzes. Betrachten wir ein neuronales Faltungsnetz, das erkennt, ob es sich bei einem Bild um eine Katze oder einen Hund handelt. Beachten Sie, dass ein Bild entweder eine Katze oder ein Hund sein muss und nicht beides sein kann; die beiden Klassen schließen sich also gegenseitig aus. Normalerweise würde die letzte vollständig verknüpfte Schicht dieses Netzes Werte produzieren, die nicht normalisiert sind und nicht als Wahrscheinlichkeiten interpretiert werden können. Wenn wir dem Netz eine Softmax-Schicht hinzufügen, ist es möglich, die Zahlen in eine Wahrscheinlichkeitsverteilung zu übersetzen. Das bedeutet, dass die Ausgabe einem Benutzer angezeigt werden kann, z. B. dass die App zu 95 % sicher ist, dass es sich um eine Katze handelt. Das bedeutet auch, dass die Ausgabe in andere Algorithmen des maschinellen Lernens eingespeist werden kann, ohne dass sie normalisiert werden muss, da sie garantiert zwischen 0 und 1 liegt.
Wenn das Netzwerk Bilder in Hunde und Katzen klassifiziert und so konfiguriert ist, dass es nur zwei Ausgabeklassen hat, dann ist es gezwungen, jedes Bild entweder als Hund oder als Katze zu kategorisieren, auch wenn es keines von beiden ist. Wenn wir diese Möglichkeit berücksichtigen wollen, müssen wir das neuronale Netz so umkonfigurieren, dass es einen dritten Ausgang für „Verschiedenes“ hat.
Beispiel für die Berechnung von Softmax in einem neuronalen Netz
Das Softmax ist wichtig, wenn wir ein neuronales Netz trainieren. Stellen wir uns vor, wir haben ein neuronales Faltungsnetzwerk, das lernt, zwischen Katzen und Hunden zu unterscheiden. Wir setzen die Katze auf Klasse 1 und den Hund auf Klasse 2.
Wenn wir ein Bild einer Katze in unser Netz eingeben, würde das Netz den Vektor ausgeben. Wenn wir ein Hundebild eingeben, wollen wir eine Ausgabe.
Die Bildverarbeitung des neuronalen Netzes endet an der letzten vollständig verbundenen Schicht. Diese Schicht gibt zwei Scores für Katze und Hund aus, die keine Wahrscheinlichkeiten sind. Es ist üblich, am Ende des neuronalen Netzes eine Softmax-Schicht hinzuzufügen, die die Ausgabe in eine Wahrscheinlichkeitsverteilung umwandelt.zu Beginn des Trainings sind die Gewichte des neuronalen Netzes zufällig konfiguriert. Das Katzenbild durchläuft also die Bildverarbeitungsstufen und wird in Scores umgewandelt. Wenn man die Softmax-Funktion einsetzt, erhält man die Anfangswahrscheinlichkeiten

Dies ist natürlich nicht wünschenswert. Ein perfektes Netz würde in diesem Fall .

Wir können eine Verlustfunktion für unser Netz formulieren, die angibt, wie weit die Ausgabewahrscheinlichkeiten des Netzes von den gewünschten Werten entfernt sind. Je kleiner die Verlustfunktion ist, desto näher liegt der Ausgabevektor an der richtigen Klasse. Die gebräuchlichste Verlustfunktion in diesem Fall ist der Cross-Entropie-Verlust, der in diesem Fall beträgt:
Da Softmax eine kontinuierlich differenzierbare Funktion ist, ist es möglich, die Ableitung der Verlustfunktion in Bezug auf jedes Gewicht im Netz für jedes Bild im Trainingssatz zu berechnen.
Diese Eigenschaft ermöglicht es uns, die Gewichte des Netzes anzupassen, um die Verlustfunktion zu verringern und die Netzausgabe näher an die gewünschten Werte heranzuführen und die Genauigkeit des Netzes zu verbessern.Nach mehreren Iterationen des Trainings aktualisieren wir die Gewichte des Netzes. Wenn nun dasselbe Katzenbild in das Netz eingegeben wird, gibt die vollständig verknüpfte Schicht einen Score-Vektor von aus. Wenn wir dies erneut durch die Softmax-Funktion laufen lassen, erhalten wir Ausgabewahrscheinlichkeiten:

Dies ist eindeutig ein besseres Ergebnis und näher an der gewünschten Ausgabe von . Bei der Neuberechnung des Cross-Entropie-Verlustes

sehen wir, dass sich der Verlust verringert hat, was darauf hindeutet, dass sich das neuronale Netz verbessert hat.
Die Methode, die Verlustfunktion zu differenzieren, um festzustellen, wie die Gewichte des Netzes anzupassen sind, wäre nicht möglich gewesen, wenn wir die argmax-Funktion verwendet hätten, da sie nicht differenzierbar ist. Die Eigenschaft der Differenzierbarkeit macht die Softmax-Funktion nützlich für das Training neuronaler Netze.
Softmax-Funktion im Reinforcement Learning
Beim Reinforcement Learning wird die Softmax-Funktion auch verwendet, wenn ein Modell entscheiden muss, ob es die Aktion ausführen soll, von der man weiß, dass sie die höchste Wahrscheinlichkeit für eine Belohnung hat, was als
Exploitation bezeichnet wird, oder ob es einen Erkundungsschritt machen soll, was als Exploration bezeichnet wird.
Beispiel für die Berechnung von Softmax beim Reinforcement Learning
Stellen Sie sich vor, wir trainieren ein Reinforcement-Learning-Modell für ein Pokerspiel gegen einen Menschen. Wir müssen eine Temperatur τ konfigurieren, die festlegt, wie wahrscheinlich es ist, dass das System zufällige Erkundungsaktionen durchführt. Das System hat im Moment zwei Möglichkeiten: ein Ass oder einen König zu spielen. Nach dem, was es bisher gelernt hat, ist es zu 80 % wahrscheinlich, dass das Spielen eines Asses in der gegenwärtigen Situation die beste Strategie ist. Unter der Annahme, dass es keine anderen möglichen Spielzüge gibt, ist es zu 20 % wahrscheinlich, dass das Spielen eines Königs die beste Strategie ist. Wir haben die Temperatur τ auf 2 eingestellt.
Das Reinforcement-Learning-System verwendet die Softmax-Funktion, um die Wahrscheinlichkeit zu erhalten, ein Ass bzw. einen König zu spielen. Die modifizierte Softmax-Formel, die beim Reinforcement Learning verwendet wird, lautet wie folgt:

Reinforcement Learning Softmax Formula Symbols Explained
| Die Wahrscheinlichkeit, dass das Modell nun zum Zeitpunkt t die Aktion a ausführen wird. | |
| Die Aktion, die wir in Betracht ziehen. Zum Beispiel, einen König oder ein Ass zu spielen. | |
 |
Die Temperatur des Systems, konfiguriert als ein Hyperparameter. |
|
Die aktuell beste Schätzung der Erfolgswahrscheinlichkeit, wenn wir die Aktion i durchführen, aus dem, was das Modell bisher gelernt hat. |
Wenn wir unsere Werte in die Gleichung einsetzen, erhalten wir:

Das bedeutet, dass das Modell zwar zu 80 % sicher ist, dass das Ass die richtige Strategie ist, dass es aber nur zu 57 % wahrscheinlich ist, diese Karte zu spielen. Das liegt daran, dass wir beim Verstärkungslernen sowohl der Erkundung (Ausprobieren neuer Strategien) als auch der Ausnutzung (Verwendung bekannter Strategien) einen Wert zuweisen. Wenn wir uns entscheiden, die Temperatur zu erhöhen, wird das Modell „impulsiver“: Es ist wahrscheinlicher, explorative Schritte zu unternehmen, als immer die Gewinnerstrategie zu spielen.
Softmax Geschichte
Die erste bekannte Verwendung der Softmax-Funktion geht dem maschinellen Lernen voraus. Die Softmax-Funktion stammt eigentlich aus der Physik und der statistischen Mechanik, wo sie als Boltzmann-Verteilung oder Gibbs-Verteilung bekannt ist. Sie wurde von dem österreichischen Physiker und Philosophen Ludwig Boltzmann 1868 formuliert.
Boltzmann untersuchte die statistische Mechanik von Gasen im thermischen Gleichgewicht. Er fand heraus, dass die Boltzmann-Verteilung die Wahrscheinlichkeit beschreiben kann, dass sich ein System in einem bestimmten Zustand befindet, wenn die Energie dieses Zustands und die Temperatur des Systems gegeben sind. Seine Version der Formel ähnelte derjenigen, die beim Verstärkungslernen verwendet wird. Tatsächlich wird der Parameter τ im Bereich des verstärkenden Lernens als Hommage an Boltzmann als Temperatur bezeichnet.
Im Jahr 1902 machte der amerikanische Physiker und Chemiker Josiah Willard Gibbs die Boltzmann-Verteilung populär, als er mit ihr die Grundlage für die Thermodynamik und seine Definition der Entropie legte. Sie bildet auch die Grundlage der Spektroskopie, d.h. der Analyse von Materialien durch Betrachtung des Lichts, das sie absorbieren und reflektieren.
1959 schlug Robert Duncan Luce in seinem Buch Individual Choice Behavior: A Theoretical Analysis. Schließlich schlug John S. Bridle 1989 vor, argmax in neuronalen Netzen mit Vorwärtskopplung durch softmax zu ersetzen, da es „die Rangfolge der Eingabewerte beibehält und eine differenzierbare Verallgemeinerung der ‚winner-take-all‘-Operation der Auswahl des Maximalwertes ist“. In den letzten Jahren, als neuronale Netze weit verbreitet wurden, ist Softmax dank dieser Eigenschaften sehr bekannt geworden.