- ソフトマックス関数とは?
- ソフトマックスの式
- ソフトマックス式の記号の説明
- Softmax
- ソフトマックス関数とシグモイド関数
- Calculating Softmax Function vs Sigmoid Function
- ソフトマックス関数 vs アルグマックス関数
- Calculating Softmax Function vs Argmax Function
- ニューラルネットワークにおけるソフトマックスの計算例
- 強化学習におけるソフトマックス関数
- 強化学習におけるソフトマックスの計算例
- Reinforcement Learning Softmax Formula Symbols Explained
- ソフトマックスの歴史
ソフトマックス関数とは?
ソフトマックス関数とは、K個の実数値のベクトルを、和が1になるベクトルに変換する関数です。入力値は正、負、0、1より大きくても構いませんが、ソフトマックスは0から1の間の値に変換し、確率と解釈できるようにします。 入力の1つが小さいか負であれば、ソフトマックスはそれを小さい確率に変え、入力が大きければ、それを大きい確率に変えるが、常に0と1の間にとどまる。
ソフトマックス関数はソフトアグマックス関数、または多クラスロジスティック回帰と呼ばれることもある。 これは、ソフトマックスが多クラス分類に使えるロジスティック回帰の一般化であり、その式がロジスティック回帰に使われるシグモイド関数に非常に似ているためです。
多くの多層ニューラルネットは最後の層で終わり、都合よくスケールされない実数値のスコアを出力し、それを扱うのは難しいかもしれない。 ここでソフトマックスはスコアを正規化された確率分布に変換し、ユーザーに表示したり、他のシステムの入力として使用できるので非常に有用である。 このため、ニューラルネットワークの最終層としてソフトマックス関数を追加するのが一般的である。
ソフトマックスの式
ソフトマックスの式は次のとおりである。 式の底にある項は正規化項であり、関数のすべての出力値の合計が1になるようにし、有効な確率分布を構成する。
ソフトマックス式の記号の説明
| ソフトマックス関数への入力ベクトルは (z0, …. zK) | |
| すべてのzi値は、ソフトマックス関数への入力ベクトルの要素で、正、ゼロ、負の任意の実数値を取ることができます。 例えばニューラルネットワークは、(-0.62, 8.12, 2.53) のようなベクトルを出力することができるが、これは有効な確率分布ではないため、ソフトマックスが必要となる。 | |
 |
標準指数関数が入力ベクトルの各要素に適用される。 これは0より上の正の値を与え、入力が負であれば非常に小さくなり、入力が大きければ非常に大きくなる。 |
 |
式の底にある項は正規化項である。 これは、関数のすべての出力値の合計が 1 になり、それぞれが範囲 (0, 1) になることを保証し、したがって有効な確率分布を構成します。 |
| マルチクラス分類器におけるクラスの数. |
Softmax
3つの実際の値の配列を持っていると想像してください。 これらの値は通常、ニューラルネットワークのような機械学習モデルの出力になる可能性があります。

最初に、入力配列の各要素の指数を計算することができます。 これはソフトマックスの式の上半分の項である。
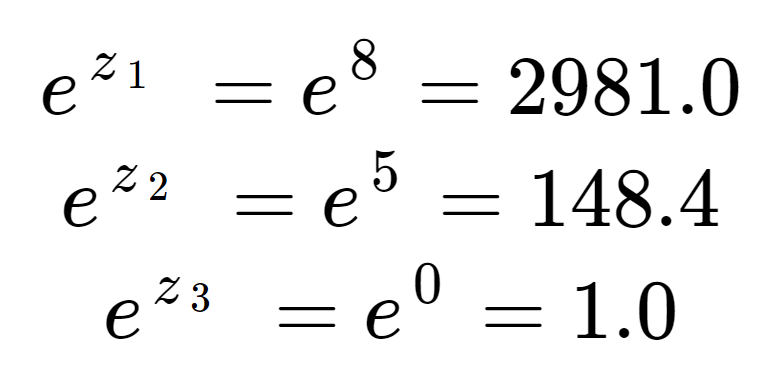
これらの値はまだ確率のように見えない。 入力要素では、8は5より少し大きいだけだが、2981は指数の効果で148よりずっと大きいことに注意されたい。 正規化項は3つの指数項の合計で、ソフトマックス式の下半分である

正規化項はz1に支配されていることがわかります。
最後に、正規化項で割ると、3要素それぞれについてソフトマックス出力が得られます。
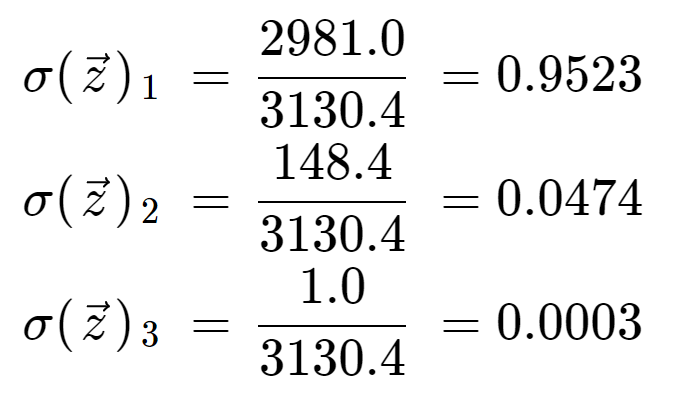
3つの出力値がありますが、これらはすべて有効な確率で、つまり0と1の間にあり、それらの和が1になることを確認するのは有益な情報です。
また、指数演算により、最初の要素である8はソフトマックス関数を支配し、5と0を非常に低い確率値に絞り込んでいることに注意してください。
機械学習モデルでソフトマックス関数を使用する場合、0 や 1 に非常に近い値を生成する傾向があるため、真の確率として解釈する前に注意する必要があります。 この例のようにニューラルネットワークの出力スコアが 、であった場合、ソフトマックス関数は最初のクラスに95%の確率を割り当てたことになりますが、実際にはニューラルネットワークの予測にはもっと不確実性があった可能性があります。
ソフトマックス関数とシグモイド関数
前述のように、ソフトマックス関数とシグモイド関数は類似しています。 シグモイドがスカラーを取るのに対して、ソフトマックスはベクトルを操作します。

実際、シグモイド関数は入力クラスが2つだけの分類器に対するソフトマックス関数の特殊ケースと言えます。 入力ベクトルをareにして、最初の出力要素を通常のソフトマックスの式で計算すれば、このことがわかる:

上と下をexで割ると、次のようになる:

このことから、2クラスあるとシグモイド関数がソフトマックス関数と同等になることがわかる。 つまり、ロジスティック回帰で2クラス分類器を開発する場合、シグモイド関数を使えば、ベクトルを扱う必要がないのです。
2つ以上のクラスがあり、それらが相互に排他的でない場合(マルチラベル分類器)、分類器は複数のバイナリ分類器に分割でき、それぞれが独自のシグモイド関数を使用します。
Calculating Softmax Function vs Sigmoid Function
入力ベクトルを取る場合、これをソフトマックスとシグモイドの両方の関数に入れることができます。

シグモイド関数は、2番目の入力要素を0に設定すれば、1番目の要素に対してソフトマックスと同じ値を与えます。
ソフトマックス関数 vs アルグマックス関数
ソフトマックス関数はアルグマックス関数に代わる平滑化および微分可能な関数として開発されたもので、アルグマックス関数はソフトマックス関数と同じ値を与える。 このため、ソフトマックス関数はより明示的にソフトアーマックス関数と呼ばれることもあります。

ソフトマックスを使用して機械学習モデルを訓練し、推論に使用する場合はソフトマックス層からargmax層に切り替えるのが一般的である。
複数の最大値がある場合、argmaxは1/Nmax、つまり正規化した分数を返すのが一般的で、softmaxと同様に出力要素の合計が1のままとなるようにします。
Calculating Softmax Function vs Argmax Function
ここで再び入力ベクトル.を想像してみましょう。 先ほどと同じようにソフトマックスを計算する。 最大の値は最初の要素なので、argmaxは最初の要素に対して1を、残りの要素に対して0を返します。

この例から、softmaxがargmaxの「柔らかい」近似として動作することは明らかです:それは確率として解釈できる0と1間の非整数値を返します。 機械学習モデルを学習させるのではなく、推論に使う場合、腫瘍の治療、ユーザーの認証、ドキュメントのトピックへの割り当てなど、モデル出力で行う難しい決定を表すシステムからの整数出力が必要かもしれません。 この意味でargmax値は扱いやすく、混同行列を構築し、分類器の精度と再現率を計算するために使用することができる。 ある画像が猫か犬かを認識する畳み込みニューラルネットワークを考えてみよう。 画像は猫か犬のどちらかでなければならず、両方はありえないので、この2つのクラスは相互に排他的であることに注意してください。 通常、このネットワークの最後の完全連結層は、正規化されておらず、確率として解釈できないような値を生成する。 もし、このネットワークにソフトマックス層を追加すれば、数値を確率分布に変換することが可能になる。 つまり、「このアプリは95%の確率で猫です」というように、出力をユーザーに表示することができる。 また、出力は 0 と 1 の間にあることが保証されているので、正規化する必要がなく、他の機械学習アルゴリズムに供給できることを意味します。
ネットワークが画像を犬と猫に分類し、2 つの出力クラスのみを持つように構成されている場合、すべての画像を犬または猫のどちらにも分類することを強制され、それがどちらでもなくても、そのことに注意ください。
ニューラルネットワークにおけるソフトマックスの計算例
ソフトマックスは、ニューラルネットワークを学習させるときに不可欠である。 例えば、猫と犬の区別を学習する畳み込みニューラルネットワークがあるとする。 猫をクラス 1、犬をクラス 2 とします。
理想的には、猫の画像をネットワークに入力すると、ネットワークはベクトルを出力します。
ニューラルネットワークの画像処理は、最後の完全連結層で終了します。 この層は猫と犬に対して2つのスコアを出力するが、これは確率ではない。 ニューラルネットワークの最後には、出力を確率分布に変換するソフトマックス層を追加するのが一般的である。 そこで、猫の画像は、画像処理段階を経て、点数に変換される。 ソフトマックス関数に渡すと、初期確率

が得られますが、これは明らかに望ましくありません。 この場合、完璧なネットワークであれば、0.9805> 
を出力するだろう。このネットワークの損失関数は、ネットワークの出力確率が望ましい値からどれだけ離れているかを定量化するものである。 損失関数が小さいほど、出力ベクトルは正しいクラスに近くなる。 この場合、最も一般的な損失関数はクロスエントロピー損失で、この場合、次のようになる:
ソフトマックスは連続微分可能関数なので、学習セット内のすべての画像について、ネットワークのすべての重みに関する損失関数の微分を計算することが可能である。
この特性により、損失関数を減らし、ネットワークの出力を望ましい値に近づけ、ネットワークの精度を向上させるために、ネットワークの重みを調整することができる。 数回の学習後、ネットワークの重みを更新し、同じ猫画像をネットワークに入力すると、完全連結層はスコアベクトルを出力する。 これを再びソフトマックス関数にかけると、出力確率が得られる:

これは明らかに良い結果で、望ましい出力である.に近づいている。 クロスエントロピーの損失を再計算すると、

損失が減少しており、ニューラルネットワークが改善したことがわかる。
この損失関数を微分して、ネットワークの重みをどう調整するかという方法は、もし argmax 関数を使った場合は微分不可能であるため不可能であっただろう。
強化学習におけるソフトマックス関数
強化学習において、モデルが現在最も高い確率で報酬が得られるとわかっている行動をとるか、
探査と呼ばれる探索的なステップをとるかを決める必要がある場合にも、ソフトマックス関数が使われる。
強化学習におけるソフトマックスの計算例
強化学習モデルを訓練して、人間とポーカーをすることを想像してみよう。 システムがランダムな探索行動を取る可能性を設定する温度τを設定する必要がある。 システムは現在、エースを出すかキングを出すかの2つの選択肢を持っている。 これまでの学習から、現在の状況ではエースをプレイすることが80%の確率で勝利する戦略である。 他に可能性のあるプレイがないと仮定すると、キングをプレイすることは20%の確率で勝利することになる。 温度τを2に設定した。
強化学習システムはソフトマックス関数を用いて、エースとキングのプレイ確率をそれぞれ求めた。 強化学習で用いられる修正ソフトマックス式は以下の通りである:

Reinforcement Learning Softmax Formula Symbols Explained
| 時間tでモデルが今行為aをとる確率 | |
 |
ハイパーパラメータとして構成されたシステムの温度です。 |
|
モデルがこれまでに学習した内容から、行動iを取った場合の成功確率の現在の最良推定値です。 |
式に値を入れると、こうなります。

これは、モデルは現在、エースが正しい戦略であると80%確信しているが、そのカードを出す可能性は57%しかないことを意味します。 これは、強化学習では、探索(新しい戦略を試すこと)と利用(既知の戦略を使用すること)に価値を割り当てるからです。
ソフトマックスの歴史
ソフトマックス関数の最初の使用は、機械学習より前に知られていたものである。 ソフトマックス関数は物理学や統計力学から借用したものであり、ボルツマン分布やギブス分布として知られている。 これは、オーストリアの物理学者であり哲学者でもあった Ludwig Boltzmann が 1868 年に定式化しました。 彼はボルツマン分布が、ある状態のエネルギーと系の温度が与えられたときに、ある状態にある系を見つける確率を記述できることを発見した。 この式は、強化学習で使われる式と似ている。 実際、強化学習の分野では、ボルツマンへのオマージュとして、パラメータτを温度と呼ぶ。
1902年にアメリカの物理学者で化学者のジョサイア・ウィラード・ギブスが、熱力学と彼のエントロピーの定義の基礎を築くためにボルツマン分布を使用し、普及した。 また、分光学(物質が吸収し、反射する光を見て分析すること)の基礎にもなっている。
1959年、Robert Duncan Luceは著書『Individual Choice Behavior』で強化学習へのソフトマックス関数の利用を提案した。 A Theoretical Analysis)で強化学習にソフトマックス関数を用いることを提案した。 また、1989年にはJohn S. Bridleが「入力値の順位が保たれ、最大値を選ぶという『勝者総取り』操作の微分可能な一般化である」ことから、フィードフォワードニューラルネットワークのargmaxをsoftmaxに置き換えるべきであると提案した。 近年、ニューラルネットワークが広く使われるようになり、このような性質からソフトマックスがよく知られるようになった
。