- Qual é a Função Softmax?
- Fórmula softmax
- Símbolos da Fórmula Softmax Explicados
- Calculando o Softmax
- Função Softmax vs Função Sigmóide
- Calculando Softmax Function vs Sigmoid Function
- Função softmax vs Função Argmax
- Cálculo da Função Softmax vs Função Argmax
- Aplicações da Função Softmax
- Função Softmax em Redes Neurais
- Cálculo de Softmax em uma Rede Neural
- Função softmax no Aprendizado de Reforço
- Exemplo Cálculo da Softmax em Aprendizagem de Reforço
- Aprendizagem de Reforço Símbolos de Fórmula Softmax Explicados
- Histórico do softmax
Qual é a Função Softmax?
A função softmax é uma função que transforma um vector de K valores reais num vector de K valores reais que somam a 1. Os valores de entrada podem ser positivos, negativos, zero ou superiores a 1, mas a função softmax transforma-os em valores entre 0 e 1, para que possam ser interpretados como probabilidades. Se um dos inputs é pequeno ou negativo, a softmax transforma-o em uma pequena probabilidade, e se um input é grande, então ele o transforma em uma grande probabilidade, mas sempre permanecerá entre 0 e 1,
A função softmax é às vezes chamada de função softargmax, ou regressão logística multiclasse. Isto porque a softmax é uma generalização da regressão logística que pode ser usada para classificação multi-classe, e sua fórmula é muito similar à função sigmóide que é usada para a regressão logística. A função softmax só pode ser usada em um classificador quando as classes são mutuamente exclusivas.
Muitas redes neurais multicamadas terminam em uma penúltima camada que produz pontuações de valor real que não são convenientemente escaladas e que podem ser difíceis de trabalhar. Aqui o softmax é muito útil porque converte as pontuações para uma distribuição de probabilidade normalizada, que pode ser exibida para um usuário ou usada como entrada para outros sistemas. Por esta razão é usual anexar uma função softmax como camada final da rede neural.
Fórmula softmax
A fórmula softmax é a seguinte:
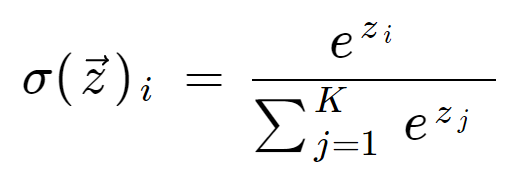
Definição matemática da função softmax
onde todos os valores zi são os elementos do vetor de entrada e podem tomar qualquer valor real. O termo no final da fórmula é o termo de normalização que garante que todos os valores de saída da função serão somados a 1, constituindo assim uma distribuição de probabilidade válida.
Símbolos da Fórmula Softmax Explicados
| O vetor de entrada para a função softmax, composto de (z0, …. zK) | |
| Todos os valores zi são os elementos do vector de entrada para a função softmax, e podem tomar qualquer valor real, positivo, zero ou negativo. Por exemplo, uma rede neural poderia ter um vector de saída como (-0,62, 8,12, 2,53), o que não é uma distribuição de probabilidade válida, daí a necessidade da softmax. | |
 |
A função exponencial padrão é aplicada a cada elemento do vector de entrada. Isto dá um valor positivo acima de 0, que será muito pequeno se o input for negativo, e muito grande se o input for grande. Entretanto, ele ainda não é fixo no intervalo (0, 1), que é o que é exigido de uma probabilidade. |
 |
O termo na parte inferior da fórmula é o termo de normalização. Ele garante que todos os valores de saída da função serão somados a 1 e cada um estará no intervalo (0, 1), constituindo assim uma distribuição de probabilidade válida. |
| |
O número de classes no classificador multiclasse. |
Calculando o Softmax
Imagine que temos um array de três valores reais. Estes valores poderiam ser tipicamente o resultado de um modelo de aprendizagem de uma máquina, como uma rede neural. Queremos converter os valores em uma distribuição de probabilidade.

Primeiro podemos calcular o exponencial de cada elemento do array de entrada. Este é o termo na metade superior da equação softmax.
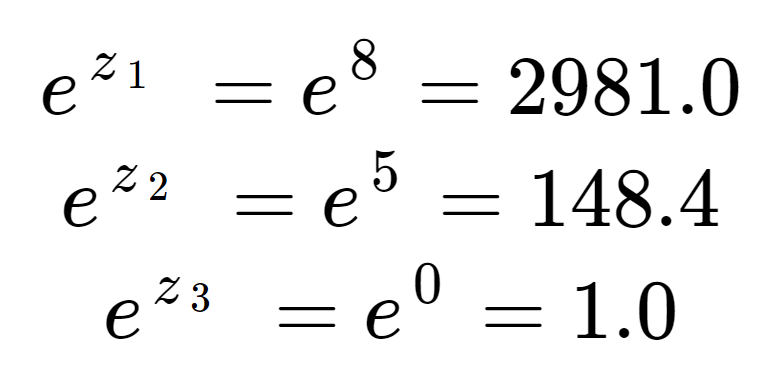
Estes valores ainda não se parecem com probabilidades. Note que nos elementos de entrada, embora 8 seja apenas um pouco maior que 5, 2981 é muito maior que 148, devido ao efeito do exponencial. Podemos obter o termo de normalização, a metade inferior da equação softmax, pela soma dos três termos exponenciais:

Vemos que o termo de normalização foi dominado por z1.
Finalmente, dividindo pelo termo de normalização, obtemos a saída softmax para cada um dos três elementos. Note que não há um único valor de saída porque a softmax transforma um array para um array do mesmo comprimento, neste caso 3.
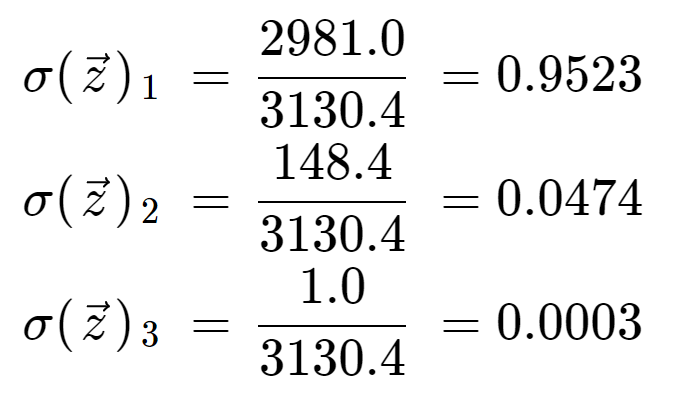
É informativo verificar que temos três valores de saída que são todas probabilidades válidas, ou seja, elas estão entre 0 e 1, e somam a 1.
Nota também que devido à operação exponencial, o primeiro elemento, o 8, dominou a função softmax e espremeu os 5 e 0 em valores de probabilidade muito baixos.
Se você usar a função softmax em um modelo de aprendizagem de máquina, você deve ter cuidado antes de interpretar como uma probabilidade verdadeira, pois ela tem uma tendência a produzir valores muito próximos de 0 ou 1. Se uma rede neural tivesse pontuação de output de , como neste exemplo, então a função softmax teria atribuído 95% de probabilidade à primeira classe, quando na realidade poderia ter havido mais incerteza nas previsões da rede neural. Isso poderia dar a impressão de que a previsão da rede neural tinha uma alta confiança quando não era esse o caso.
Função Softmax vs Função Sigmóide
Como mencionado acima, a função softmax e a função sigmóide são semelhantes. A softmax opera em um vetor enquanto a sigmóide toma um escalar.

Na verdade, a função sigmóide é um caso especial da função softmax para um classificador com apenas duas classes de entrada. Podemos mostrar isso se definirmos o vetor de entrada como sendo e calcularmos o primeiro elemento de saída com a fórmula softmax usual:

Dividindo o topo e o fundo por ex, obtemos:

Isso mostra que a função sigmóide se torna equivalente à função softmax quando temos duas classes. Não é necessário calcular explicitamente o segundo componente vetorial porque quando há duas probabilidades, elas devem somar a 1.Então, se estamos desenvolvendo um classificador de duas classes com regressão logística, podemos usar a função sigmóide e não precisamos trabalhar com vetores. Mas se tivermos mais de duas classes mutuamente exclusivas a softmax deve ser usada.
Se houver mais de duas classes e elas não forem mutuamente exclusivas (um classificador multi-label), então o classificador pode ser dividido em múltiplos classificadores binários, cada um usando sua própria função sigmoid.
Calculando Softmax Function vs Sigmoid Function
Se pegarmos um vetor de input , podemos colocar isso tanto na função softmax quanto na sigmoid. Como o sigmóide toma um valor escalar, colocamos apenas o primeiro elemento na função sigmóide.

A função sigmóide dá o mesmo valor que a softmax para o primeiro elemento, desde que o segundo elemento de entrada esteja definido como 0. Como o sigmóide está nos dando uma probabilidade, e as duas probabilidades devem ser adicionadas a 1, não é necessário calcular explicitamente um valor para o segundo elemento.
Função softmax vs Função Argmax
A função softmax foi desenvolvida como uma alternativa suavizada e diferenciável à função argmax. Por causa disso a função softmax é às vezes mais explicitamente chamada de função softargmax. Assim como a softmax, a função argmax opera em um vetor e converte todos os valores para zero exceto o valor máximo, onde retorna 1.

É comum treinar um modelo de aprendizagem de máquina usando a softmax mas trocar a camada de softmax por uma camada argmax quando o modelo é usado para inferência.
Temos que usar a softmax em treinamento porque a softmax é diferenciável e nos permite otimizar uma função de custo. Entretanto, para inferência às vezes precisamos de um modelo apenas para produzir um único valor previsto e não uma probabilidade, neste caso o argmax é mais útil.
Quando existem múltiplos valores máximos é comum que o argmax retorne 1/Nmax, que é uma fração normalizada, de forma que a soma dos elementos de saída permaneça 1 como com a softmax. Uma definição alternativa é retornar 1 para todos os valores máximos, ou apenas para o primeiro valor.
Cálculo da Função Softmax vs Função Argmax
Deixe-nos imaginar novamente o vetor de entrada . Nós calculamos a softmax como antes. O maior valor é o primeiro elemento, portanto o argmax retornará 1 para o primeiro elemento e 0 para o resto.

Está claro a partir deste exemplo que a softmax se comporta como uma aproximação ‘soft’ ao argmax: ela retorna valores não-inteiros entre 0 e 1 que podem ser interpretados como probabilidades. Se estamos usando um modelo de aprendizagem de máquina para inferência, ao invés de treiná-lo, podemos querer um output inteiro do sistema representando uma decisão difícil que tomaremos com o output do modelo, tal como tratar um tumor, autenticar um usuário, ou atribuir um documento a um tópico. Os valores de argmax são mais fáceis de trabalhar neste sentido e podem ser usados para construir uma matriz de confusão e calcular a precisão e recall de um classificador.
Aplicações da Função Softmax
Função Softmax em Redes Neurais
Um uso da função softmax seria no final de uma rede neural. Vamos considerar uma rede neural convolucional que reconhece se uma imagem é um gato ou um cachorro. Note que uma imagem deve ser ou um gato ou um cachorro, e não pode ser ambas, portanto as duas classes são mutuamente exclusivas. Normalmente, a camada final totalmente conectada dessa rede produziria valores como os que não são normalizados e não podem ser interpretados como probabilidades. Se adicionarmos uma camada de softmax à rede, é possível traduzir os números em uma distribuição de probabilidades. Isto significa que a saída pode ser exibida para um usuário, por exemplo, o aplicativo tem 95% de certeza de que se trata de um gato. Isso também significa que a saída pode ser alimentada em outros algoritmos de aprendizagem da máquina sem a necessidade de ser normalizada, uma vez que é garantido que ela esteja entre 0 e 1.
Note que se a rede está classificando imagens em cães e gatos, e está configurada para ter apenas duas classes de saída, então ela é forçada a categorizar cada imagem como cão ou gato, mesmo que não seja nenhuma delas. Se precisamos permitir essa possibilidade, então devemos reconfigurar a rede neural para ter uma terceira saída para miscelânea.
Cálculo de Softmax em uma Rede Neural
O softmax é essencial quando estamos treinando uma rede neural. Imagine que temos uma rede neural convolucional que está aprendendo a distinguir entre cães e gatos. Nós definimos gato como sendo classe 1 e cão como sendo classe 2.
Idealmente, quando introduzimos uma imagem de um gato na nossa rede, a rede produziria o vector . Quando introduzimos uma imagem de cão, queremos uma saída .
O processamento da imagem da rede neural termina na camada final totalmente ligada. Esta camada produz dois resultados para gato e cão, que não são probabilidades. É prática comum adicionar uma camada softmax ao final da rede neural, que converte o output em uma distribuição de probabilidade. No início do treinamento, os pesos da rede neural são configurados aleatoriamente. Então a imagem do gato passa e é convertida pelos estágios de processamento de imagem para pontuação . Passando para a função softmax podemos obter as probabilidades iniciais

Claramente isto não é desejável. Uma rede perfeita, neste caso, produziria .

Podemos formular uma função de perda da nossa rede que quantifica a distância entre as probabilidades de saída da rede e os valores desejados. Quanto menor a função de perda, mais próximo o vetor de saída está da classe correta. A função de perda mais comum neste caso é a perda de cross-entropy que neste caso chega a:
Porque a softmax é uma função continuamente diferenciável, é possível calcular a derivada da função de perda com respeito a cada peso na rede, para cada imagem no conjunto de treinamento.
Esta propriedade permite-nos ajustar os pesos da rede de forma a reduzir a função de perda e tornar a saída da rede mais próxima dos valores desejados e melhorar a precisão da rede. Agora quando a mesma imagem de gato é inserida na rede, a camada totalmente conectada produz um vetor de pontuação de . Colocando isto através da função softmax novamente, obtemos probabilidades de saída:

Este é claramente um resultado melhor e mais próximo da saída desejada de . Recalculando a perda de centralidade cruzada,

vemos que a perda foi reduzida, indicando que a rede neural melhorou.
O método de diferenciação da função de perda para determinar como ajustar os pesos da rede não teria sido possível se tivéssemos usado a função argmax, pois não é diferenciável. A propriedade de diferenciação torna a função softmax útil para o treinamento de redes neurais.
Função softmax no Aprendizado de Reforço
No aprendizado de reforço, a função softmax também é usada quando um modelo precisa decidir entre tomar a ação atualmente conhecida por ter a maior probabilidade de recompensa, chamada
exploração, ou tomar um passo exploratório, chamado exploração.
Exemplo Cálculo da Softmax em Aprendizagem de Reforço
Imagine que estamos treinando um modelo de aprendizagem de reforço para jogar poker contra um humano. Devemos configurar uma temperatura τ, que define a probabilidade de o sistema tomar ações exploratórias aleatórias. O sistema tem duas opções no momento: jogar um Ás ou jogar um Rei. Pelo que aprendeu até agora, jogar um Ás é 80% de probabilidade de ser a estratégia vencedora na situação actual. Assumindo que não há outras jogadas possíveis, então jogar um Ás tem 20% de probabilidade de ser a estratégia vencedora. Nós configuramos a temperatura τ para 2.
O sistema de aprendizagem de reforço usa a função softmax para obter a probabilidade de jogar um Ás e um Rei, respectivamente. A fórmula softmax modificada utilizada na aprendizagem de reforço é a seguinte:

Aprendizagem de Reforço Símbolos de Fórmula Softmax Explicados
| A probabilidade de o modelo agora tomar uma ação no momento t. | |
| |
A ação que estamos considerando tomar. Por exemplo, para jogar um Rei ou um Ás. |
 |
A temperatura do sistema, configurado como um hiperparâmetro. |
|
A melhor estimativa actual da probabilidade de sucesso se tomarmos medidas i, a partir do que o modelo aprendeu até agora. |
Pondo os nossos valores na equação que obtemos:

Isto significa que embora o modelo esteja actualmente 80% certo de que o Ás é a estratégia correcta, é apenas 57% provável que jogue essa carta. Isto porque na aprendizagem do reforço atribuímos um valor à exploração (testando novas estratégias) bem como à exploração (usando estratégias conhecidas). Se optarmos por aumentar a temperatura, o modelo torna-se mais ‘impulsivo’: é mais provável que se dêem passos exploratórios em vez de se jogar sempre a estratégia vencedora.
Histórico do softmax
O primeiro uso conhecido da função softmax é anterior à aprendizagem da máquina. A função softmax é de fato emprestada da física e mecânica estatística, onde é conhecida como a distribuição Boltzmann ou a distribuição Gibbs. Ela foi formulada pelo físico e filósofo austríaco Ludwig Boltzmann em 1868.
Boltzmann estava estudando a mecânica estatística dos gases em equilíbrio térmico. Ele descobriu que a distribuição de Boltzmann poderia descrever a probabilidade de encontrar um sistema em determinado estado, dada a energia desse estado, e a temperatura do sistema. A sua versão da fórmula era semelhante à utilizada na aprendizagem do reforço. De fato, o parâmetro τ é chamado de temperatura no campo da aprendizagem de reforço como uma homenagem a Boltzmann.
Em 1902 o físico e químico americano Josiah Willard Gibbs popularizou a distribuição de Boltzmann quando ele a usou para lançar as bases da termodinâmica e sua definição de entropia. Ela também forma a base da espectroscopia, que é a análise dos materiais através da luz que eles absorvem e refletem.
Em 1959 Robert Duncan Luce propôs o uso da função softmax para a aprendizagem de reforço em seu livro Individual Choice Behavior: Uma Análise Teórica. Finalmente em 1989 John S. Bridle sugeriu que a argmax nas redes neurais feedforward deveria ser substituída por softmax porque ela “preserva a ordem de classificação de seus valores de entrada, e é uma generalização diferenciável da operação “vencedora-take-all” de escolher o valor máximo”. Nos últimos anos, como as redes neurais se tornaram amplamente utilizadas, a softmax tornou-se bem conhecida graças a essas propriedades.