- Wat is de Softmax Functie?
- Softmax-formule
- Softmaxformule-symbolen uitgelegd
- Berekening van de Softmax
- Softmax Functie vs Sigmoid Functie
- Berekening Softmax-functie vs Sigmoid-functie
- Softmax-functie vs Argmax-functie
- Berekening Softmax-functie vs Argmax-functie
- Toepassingen van de softmax-functie
- Softmax-functie in neurale netwerken
- Voorbeeld Berekening van Softmax in een neuraal netwerk
- Softmax-functie in versterkingsleren
- Voorbeeld Berekening van Softmax bij Reinforcement Learning
- Het versterkingsleren Softmax-formule Symbolen Uitleg
- Softmax Geschiedenis
Wat is de Softmax Functie?
De softmax functie is een functie die een vector van K reële waarden verandert in een vector van K reële waarden die opgeteld 1 zijn. De invoerwaarden kunnen positief, negatief, nul, of groter dan 1 zijn, maar de softmax zet ze om in waarden tussen 0 en 1, zodat ze als waarschijnlijkheden geïnterpreteerd kunnen worden. Als een van de inputs klein of negatief is, maakt de softmax er een kleine kans van, en als een input groot is, maakt hij er een grote kans van, maar hij blijft altijd tussen 0 en 1.
De softmax-functie wordt ook wel de softargmax-functie genoemd, of multi-class logistische regressie. Dit komt omdat de softmax een veralgemening is van logistische regressie die kan worden gebruikt voor classificatie in meerdere klassen, en de formule lijkt sterk op de sigmoid-functie die wordt gebruikt voor logistische regressie. De softmax-functie kan alleen in een classificator worden gebruikt wanneer de klassen elkaar wederzijds uitsluiten.
Veel meerlaagse neurale netwerken eindigen in een voorlaatste laag die reële scores geeft die niet gemakkelijk te schalen zijn en waarmee moeilijk te werken kan zijn. Hier is de softmax zeer nuttig omdat hij de scores omzet in een genormaliseerde kansverdeling, die aan een gebruiker kan worden getoond of als invoer voor andere systemen kan worden gebruikt. Daarom is het gebruikelijk een softmax-functie toe te voegen als laatste laag van het neurale netwerk.
Softmax-formule
De softmax-formule ziet er als volgt uit:
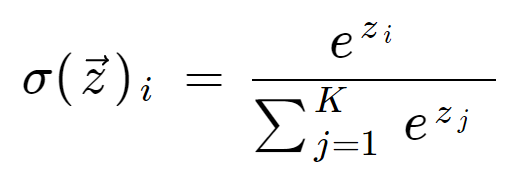
Wiskundige definitie van de softmax-functie
waarbij alle zi-waarden de elementen van de invoervector zijn en elke reële waarde kunnen aannemen. De term onderaan de formule is de normalisatieterm die ervoor zorgt dat alle outputwaarden van de functie bij elkaar opgeteld 1 zijn, en dus een geldige kansverdeling vormen.
Softmaxformule-symbolen uitgelegd
| De inputvector van de softmaxfunctie, die bestaat uit (z0, … zK) | |
| Alle zi-waarden zijn de elementen van de invoervector voor de softmax-functie, en zij kunnen elke reële waarde aannemen, positief, nul of negatief. Een neuraal netwerk zou bijvoorbeeld een vector als (-0,62, 8,12, 2,53) kunnen uitvoeren, wat geen geldige kansverdeling is, vandaar dat de softmax nodig zou zijn. | |
 |
De standaard exponentiële functie wordt toegepast op elk element van de inputvector. Dit geeft een positieve waarde boven 0, die zeer klein zal zijn als de invoer negatief was, en zeer groot als de invoer groot was. De waarde ligt echter nog steeds niet vast in het bereik (0, 1), wat wel van een waarschijnlijkheid wordt verlangd. |
 |
De term onderaan de formule is de normaliseringsterm. Deze zorgt ervoor dat alle uitvoerwaarden van de functie bij elkaar opgeteld 1 zijn en elk in het bereik (0, 1) liggen, zodat ze een geldige kansverdeling vormen. |
| Het aantal klassen in de multiklasse-indeler. |
Berekening van de Softmax
Stel u voor dat we een matrix van drie reële waarden hebben. Deze waarden kunnen typisch de output zijn van een machine-leermodel zoals een neuraal netwerk. We willen de waarden omzetten in een kansverdeling.

Eerst kunnen we de exponentiële van elk element van de input-array berekenen. Dit is de term in de bovenste helft van de softmax-vergelijking.
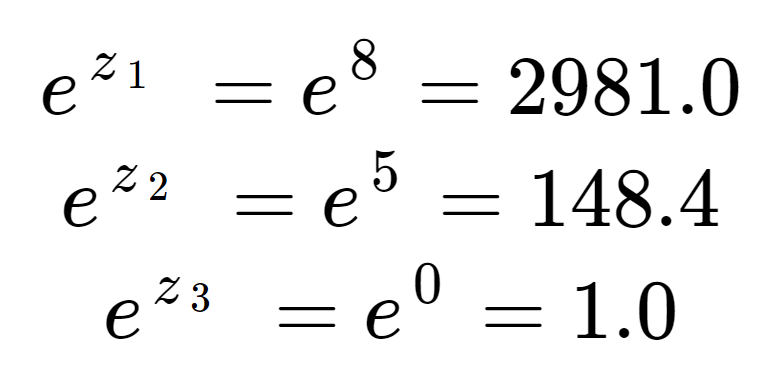
Deze waarden zien er nog niet uit als waarschijnlijkheden. Merk op dat in de invoerelementen, hoewel 8 slechts een beetje groter is dan 5, 2981 veel groter is dan 148 als gevolg van het effect van de exponentiële. We kunnen de normaliseringsterm, de onderste helft van de softmax-vergelijking, verkrijgen door alle drie exponentiële termen bij elkaar op te tellen:

We zien dat de normaliseringsterm wordt gedomineerd door z1.
Delend door de normaliseringsterm, verkrijgen we tenslotte de softmax-uitgang voor elk van de drie elementen. Merk op dat er niet één enkele outputwaarde is omdat de softmax een matrix omzet in een matrix van dezelfde lengte, in dit geval 3.
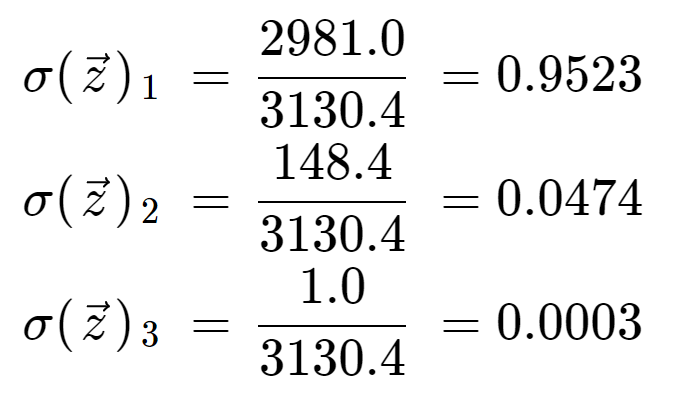
Het is informatief te controleren dat we drie outputwaarden hebben die alle geldige waarschijnlijkheden zijn, dat wil zeggen dat ze tussen 0 en 1 liggen, en dat ze opgeteld 1 zijn.
Merk ook op dat door de exponentiële werking het eerste element, de 8, de softmax-functie heeft gedomineerd en de 5 en 0 heeft weggedrukt in zeer lage waarschijnlijkheidswaarden.
Als je de softmax-functie gebruikt in een machine-leermodel, moet je voorzichtig zijn voordat je het interpreteert als een echte waarschijnlijkheid, omdat het de neiging heeft om waarden te produceren die heel dicht bij 0 of 1 liggen. Als een neuraal netwerk outputscores had van , zoals in dit voorbeeld, dan zou de softmax-functie 95% waarschijnlijkheid hebben toegekend aan de eerste klasse, terwijl er in werkelijkheid meer onzekerheid had kunnen zitten in de voorspellingen van het neurale netwerk. Dit zou de indruk kunnen wekken dat de voorspelling van het neurale netwerk een hoog vertrouwen had, terwijl dat niet het geval was.
Softmax Functie vs Sigmoid Functie
Zoals hierboven vermeld, zijn de softmax functie en de sigmoid functie gelijkaardig. De softmax werkt op een vector, terwijl de sigmoïde een scalair neemt.

In feite is de sigmoïde-functie een speciaal geval van de softmax-functie voor een classificator met slechts twee ingangsklassen. We kunnen dit aantonen als we de invoervector op zijn zetten en het eerste uitvoerelement berekenen met de gebruikelijke softmax-formule:

Door de boven- en onderkant door ex te delen, krijgen we:

Dit toont aan dat de sigmoid-functie gelijkwaardig wordt aan de softmax-functie wanneer we twee klassen hebben. Het is niet nodig de tweede vectorcomponent expliciet te berekenen, want als er twee waarschijnlijkheden zijn, moeten die bij elkaar opgeteld 1 zijn. Als we dus een tweeklassenclassificator ontwikkelen met logistische regressie, kunnen we de sigmoidfunctie gebruiken en hoeven we niet met vectoren te werken. Maar als we meer dan twee elkaar uitsluitende klassen hebben, moet de softmax worden gebruikt.
Als er meer dan twee klassen zijn en ze sluiten elkaar niet uit (een multi-label classifier), dan kan de classifier worden opgesplitst in meerdere binaire classifiers, die elk hun eigen sigmoid-functie gebruiken.
Berekening Softmax-functie vs Sigmoid-functie
Als we een invoervector nemen, kunnen we deze zowel in de softmax- als in de sigmoid-functie plaatsen. Aangezien de sigmoïde een scalaire waarde neemt, stoppen we alleen het eerste element in de sigmoïdefunctie.

De sigmoïdefunctie geeft dezelfde waarde als de softmax voor het eerste element, op voorwaarde dat het tweede invoerelement op 0 wordt gezet. Aangezien de sigmoïde ons een waarschijnlijkheid geeft, en de twee waarschijnlijkheden moeten optellen tot 1, is het niet nodig om expliciet een waarde voor het tweede element te berekenen.
Softmax-functie vs Argmax-functie
De softmax-functie werd ontwikkeld als een afgevlakt en differentieerbaar alternatief voor de argmax-functie. Daarom wordt de softmax-functie soms explicieter de softargmax-functie genoemd. Net als de softmax werkt de argmax-functie op een vector en zet elke waarde om in nul, behalve de maximumwaarde, waarvoor hij 1 teruggeeft.

Het is gebruikelijk om een machine-leermodel te trainen met behulp van de softmax, maar de softmax-laag te vervangen door een argmax-laag wanneer het model wordt gebruikt voor inferentie.
We moeten de softmax gebruiken bij training omdat de softmax differentieerbaar is en ons in staat stelt een kostenfunctie te optimaliseren. Voor inferentie hebben we echter soms een model nodig dat slechts één voorspelde waarde weergeeft in plaats van een waarschijnlijkheid, in welk geval de argmax nuttiger is.
Wanneer er meerdere maximumwaarden zijn, is het gebruikelijk dat de argmax 1/Nmax teruggeeft, dat wil zeggen een genormaliseerde breuk, zodat de som van de uitvoerelementen 1 blijft, zoals bij de softmax. Een alternatieve definitie is om 1 terug te geven voor alle maximum waarden, of alleen voor de eerste waarde.
Berekening Softmax-functie vs Argmax-functie
Stel ons opnieuw de ingangsvector voor. We berekenen de softmax zoals voorheen. De grootste waarde is het eerste element, dus de argmax zal 1 teruggeven voor het eerste element en 0 voor de rest.

Uit dit voorbeeld blijkt dat de softmax zich gedraagt als een ‘zachte’ benadering van de argmax: hij geeft niet-integere waarden tussen 0 en 1 terug die als waarschijnlijkheden kunnen worden geïnterpreteerd. Als we een machine-leermodel gebruiken voor inferentie, in plaats van het te trainen, willen we misschien een geheel getal dat een harde beslissing weergeeft die we met de modeloutput zullen nemen, zoals het behandelen van een tumor, het authentiseren van een gebruiker, of het toewijzen van een document aan een onderwerp. De argmax-waarden zijn in die zin gemakkelijker om mee te werken en kunnen worden gebruikt om een verwarringsmatrix op te bouwen en de precisie en recall van een classificator te berekenen.
Toepassingen van de softmax-functie
Softmax-functie in neurale netwerken
Eén gebruik van de softmax-functie zou aan het einde van een neuraal netwerk zijn. Laten we een convolutioneel neuraal netwerk beschouwen dat herkent of een afbeelding een kat of een hond is. Merk op dat een afbeelding óf een kat óf een hond moet zijn, en niet beide kan zijn, daarom sluiten de twee klassen elkaar uit. Typisch zou de laatste volledig aangesloten laag van dit netwerk waarden produceren die niet genormaliseerd zijn en niet als waarschijnlijkheden kunnen worden geïnterpreteerd. Als we een softmax-laag aan het netwerk toevoegen, is het mogelijk de getallen te vertalen in een waarschijnlijkheidsverdeling. Dit betekent dat de output aan een gebruiker kan worden getoond, bijvoorbeeld dat de app 95% zeker is dat dit een kat is. Het betekent ook dat de output kan worden ingevoerd in andere machine learning algoritmen zonder dat het genormaliseerd hoeft te worden, omdat het gegarandeerd tussen 0 en 1 ligt.
Merk op dat als het netwerk afbeeldingen classificeert in honden en katten, en is geconfigureerd om slechts twee output klassen te hebben, dan is het gedwongen om elke afbeelding te categoriseren als hond of kat, zelfs als het geen van beide is. Als we met deze mogelijkheid rekening moeten houden, dan moeten we het neurale netwerk herconfigureren om een derde uitgang voor diversen te hebben.
Voorbeeld Berekening van Softmax in een neuraal netwerk
De softmax is essentieel wanneer we een neuraal netwerk trainen. Stel dat we een convolutioneel neuraal netwerk hebben dat leert onderscheid te maken tussen katten en honden. We stellen kat in als klasse 1 en hond als klasse 2.
Eigenlijk zou het netwerk, wanneer we een afbeelding van een kat in ons netwerk invoeren, de vector uitvoeren. Wanneer we een afbeelding van een hond invoeren, willen we een uitvoer .
De beeldverwerking van het neurale netwerk eindigt bij de laatste volledig aangesloten laag. Deze laag geeft twee scores voor kat en hond, die geen waarschijnlijkheden zijn. Het is gebruikelijk om aan het eind van het neurale netwerk een softmax-laag toe te voegen, die de output omzet in een waarschijnlijkheidsverdeling.Aan het begin van de training zijn de neurale netwerkgewichten willekeurig geconfigureerd. Het beeld van de kat wordt dus doorlopen en door de beeldverwerkingsstadia omgezet in scores . Door de softmax-functie in te voeren krijgen we de beginwaarschijnlijkheden

Het is duidelijk dat dit niet wenselijk is. Een perfect netwerk zou in dit geval .

We kunnen een verliesfunctie van ons netwerk formuleren die aangeeft hoe ver de uitvoerkansen van het netwerk van de gewenste waarden verwijderd zijn. Hoe kleiner de verliesfunctie, hoe dichter de uitgangsvector bij de juiste klasse ligt. De meest gebruikelijke verliesfunctie is in dit geval het cross-entropieverlies, dat in dit geval als volgt wordt berekend:
Omdat de softmax een continu differentieerbare functie is, is het mogelijk de afgeleide van de verliesfunctie te berekenen met betrekking tot elk gewicht in het netwerk, voor elk beeld in de trainingsverzameling.
Door deze eigenschap kunnen we de gewichten van het netwerk aanpassen om de verliesfunctie te verminderen en de netwerkoutput dichter bij de gewenste waarden te brengen en de nauwkeurigheid van het netwerk te verbeteren.Na een aantal iteraties van de training, werken we de gewichten van het netwerk bij. Wanneer nu hetzelfde kattenbeeld in het netwerk wordt ingevoerd, geeft de volledig verbonden laag een scorevector van . Wanneer we dit opnieuw door de softmax-functie halen, krijgen we uitvoerkansen:

Dit is duidelijk een beter resultaat en komt dichter bij de gewenste uitvoer van . Wanneer we het cross-entropy verlies opnieuw berekenen,

zien we dat het verlies is afgenomen, wat aangeeft dat het neurale netwerk is verbeterd.
De methode waarbij de verliesfunctie wordt gedifferentieerd om te bepalen hoe de gewichten van het netwerk moeten worden aangepast, zou niet mogelijk zijn geweest als we de argmax-functie hadden gebruikt, omdat deze niet differentieerbaar is. De eigenschap van differentiabiliteit maakt de softmax-functie nuttig voor het trainen van neurale netwerken.
Softmax-functie in versterkingsleren
In versterkingsleren wordt de softmax-functie ook gebruikt wanneer een model moet beslissen tussen het nemen van de actie waarvan op dat moment bekend is dat deze de hoogste waarschijnlijkheid op een beloning heeft,
exploitatie genoemd, of het nemen van een verkennende stap, exploratie genoemd.
Voorbeeld Berekening van Softmax bij Reinforcement Learning
Stel u voor dat we een reinforcement learning-model trainen om poker te spelen tegen een mens. We moeten een temperatuur τ instellen, die bepaalt hoe waarschijnlijk het is dat het systeem willekeurige verkennende acties onderneemt. Het systeem heeft op dit moment twee opties: een Aas spelen of een Koning spelen. Van wat het tot nu toe geleerd heeft, is het spelen van een Aas 80% waarschijnlijk de winnende strategie in de huidige situatie. Ervan uitgaande dat er geen andere mogelijkheden zijn, dan is het spelen van een Koning 20% waarschijnlijk om de winnende strategie te zijn. We hebben de temperatuur τ ingesteld op 2.
Het reinforcement learning systeem gebruikt de softmax functie om de waarschijnlijkheid van het spelen van respectievelijk een Aas en een Koning te verkrijgen. De aangepaste softmax-formule die bij het versterkingsleren wordt gebruikt, ziet er als volgt uit:

Het versterkingsleren Softmax-formule Symbolen Uitleg
| De waarschijnlijkheid dat het model nu actie a zal ondernemen op tijdstip t. | |
| De actie die we overwegen te ondernemen. Bijvoorbeeld om een Koning of een Aas te spelen. | |
 |
De temperatuur van het systeem, geconfigureerd als een hyperparameter. |
|
De huidige beste schatting van de kans op succes als we actie i ondernemen, op basis van wat het model tot nu toe heeft geleerd. |
Als we onze waarden in de vergelijking invoeren, krijgen we:

Dit betekent dat hoewel het model op dit moment 80% zeker weet dat de Aas de juiste strategie is, het slechts 57% waarschijnlijk is dat het die kaart zal spelen. Dit komt omdat we bij versterkingsleren een waarde toekennen aan zowel exploratie (het uitproberen van nieuwe strategieën) als exploitatie (het gebruik van bekende strategieën). Als we ervoor kiezen de temperatuur te verhogen, wordt het model ‘impulsiever’: de kans is groter dat het verkennende stappen zet in plaats van altijd de winnende strategie te spelen.
Softmax Geschiedenis
Het eerste bekende gebruik van de softmax-functie dateert van vóór het machinaal leren. De softmax-functie is in feite ontleend aan de natuurkunde en de statistische mechanica, waar zij bekend staat als de Boltzmann-verdeling of de Gibbs-verdeling. Zij werd geformuleerd door de Oostenrijkse natuurkundige en filosoof Ludwig Boltzmann in 1868.
Boltzmann bestudeerde de statistische mechanica van gassen in thermisch evenwicht. Hij ontdekte dat de Boltzmann-verdeling de waarschijnlijkheid kon beschrijven van het aantreffen van een systeem in een bepaalde toestand, gegeven de energie van die toestand, en de temperatuur van het systeem. Zijn versie van de formule was vergelijkbaar met die welke wordt gebruikt in versterkingsleren. De parameter τ wordt in het domein van het versterkingsleren inderdaad temperatuur genoemd als een eerbetoon aan Boltzmann.
In 1902 populariseerde de Amerikaanse natuurkundige en scheikundige Josiah Willard Gibbs de Boltzmann verdeling toen hij deze gebruikte om de basis te leggen voor de thermodynamica en zijn definitie van entropie. Het vormt ook de basis van spectroscopie, dat is de analyse van materialen door te kijken naar het licht dat ze absorberen en weerkaatsen.
In 1959 stelde Robert Duncan Luce het gebruik van de softmax-functie voor versterkingsleren voor in zijn boek Individual Choice Behavior: A Theoretical Analysis. Tenslotte stelde John S. Bridle in 1989 voor om de argmax in feedforward neurale netwerken te vervangen door softmax omdat deze “de rangorde van zijn invoerwaarden behoudt, en een differentieerbare veralgemening is van de ‘winner-take-all’ operatie van het kiezen van de maximale waarde”. De laatste jaren, nu neurale netwerken op grote schaal worden gebruikt, is de softmax dankzij deze eigenschappen zeer bekend geworden.