- Co je to funkce Softmax?
- Softmax vzorec
- Vysvětlení symbolů vzorce softmax
- Výpočet Softmax
- Funkce softmax vs. sigmoidní funkce
- Výpočet funkce softmax vs. sigmoidní funkce
- Funkce softmax vs. funkce argmax
- Výpočet funkce softmax vs. funkce argmax
- Použití funkce softmax
- Funkce softmax v neuronových sítích
- Příklad výpočtu softmaxu v neuronové síti
- Funkce softmax v posilovacím učení
- Příklad výpočtu softmaxu v posilovacím učení
- Vysvětlení symbolů vzorce softmax posilovacího učení
- Historie softmaxu
Co je to funkce Softmax?
Funkce Softmax je funkce, která mění vektor K reálných hodnot na vektor K reálných hodnot, jejichž součet je 1. Vstupní hodnoty mohou být kladné, záporné, nulové nebo větší než jedna, ale funkce Softmax je převede na hodnoty mezi 0 a 1, takže je lze interpretovat jako pravděpodobnosti. Pokud je některý ze vstupů malý nebo záporný, softmax jej změní na malou pravděpodobnost, a pokud je některý ze vstupů velký, pak jej změní na velkou pravděpodobnost, ale vždy zůstane mezi 0 a 1.
Funkce softmax se někdy nazývá funkce softargmax nebo logistická regrese více tříd. Je to proto, že softmax je zobecněním logistické regrese, kterou lze použít pro klasifikaci více tříd, a její vzorec je velmi podobný sigmoidní funkci, která se používá pro logistickou regresi. Funkci softmax lze v klasifikátoru použít pouze v případě, že se třídy vzájemně vylučují.
Mnoho vícevrstvých neuronových sítí končí předposlední vrstvou, jejímž výstupem je skóre v reálné hodnotě, které není vhodně škálováno a s nímž se může obtížně pracovat. Zde je softmax velmi užitečný, protože převádí skóre na normalizované rozdělení pravděpodobnosti, které lze zobrazit uživateli nebo použít jako vstup pro jiné systémy. Z tohoto důvodu je obvyklé připojit funkci softmax jako poslední vrstvu neuronové sítě.
Softmax vzorec
Softmax vzorec je následující:
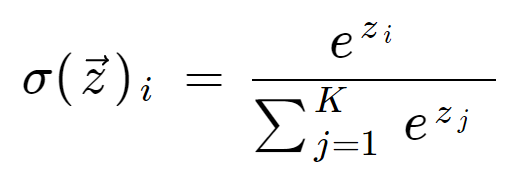
Matematická definice funkce softmax
kde všechny hodnoty zi jsou prvky vstupního vektoru a mohou nabývat libovolné reálné hodnoty. Člen v dolní části vzorce je normalizační člen, který zajišťuje, že všechny výstupní hodnoty funkce budou mít součet 1, a budou tak tvořit platné rozdělení pravděpodobnosti.
Vysvětlení symbolů vzorce softmax
| Vstupní vektor funkce softmax, tvořený (z0, …. zK) | |
| Všechny hodnoty zi jsou prvky vstupního vektoru funkce softmax a mohou nabývat libovolné reálné hodnoty, kladné, nulové nebo záporné. Neuronová síť by například mohla mít na výstupu vektor jako (-0,62, 8,12, 2,53), což není platné rozdělení pravděpodobnosti, proto by bylo nutné použít softmax. | |
 |
Na každý prvek vstupního vektoru se aplikuje standardní exponenciální funkce. Tím se získá kladná hodnota nad 0, která bude velmi malá, pokud byl vstup záporný, a velmi velká, pokud byl vstup velký. Stále však není pevně stanovena v rozsahu (0, 1), což se od pravděpodobnosti vyžaduje. |
 |
Výraz ve spodní části vzorce je normalizační člen. Zajišťuje, že všechny výstupní hodnoty funkce budou mít součet 1 a každá z nich bude v rozsahu (0, 1), čímž tvoří platné rozdělení pravděpodobnosti. |
| Počet tříd ve vícetřídním klasifikátoru. |
Výpočet Softmax
Představme si, že máme pole tří reálných hodnot. Tyto hodnoty by typicky mohly být výstupem modelu strojového učení, například neuronové sítě. Chceme tyto hodnoty převést na pravděpodobnostní rozdělení.

Nejprve můžeme vypočítat exponenciálu každého prvku vstupního pole. To je člen v horní polovině rovnice softmax.
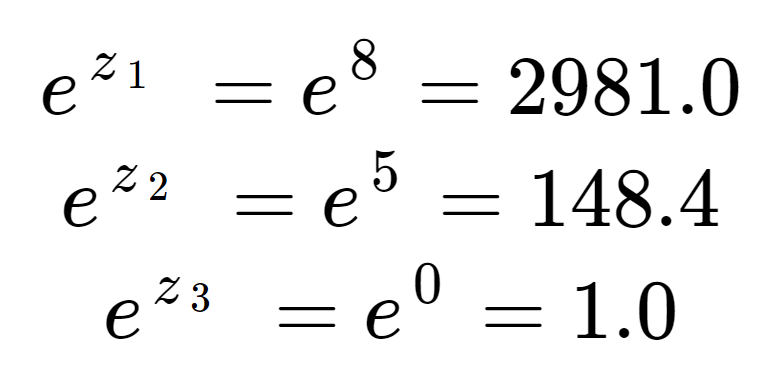
Tyto hodnoty ještě nevypadají jako pravděpodobnosti. Všimněte si, že ve vstupních prvcích je sice 8 jen o málo větší než 5, ale 2981 je mnohem větší než 148 kvůli vlivu exponenciály. Normalizační člen, spodní polovinu rovnice softmaxu, získáme součtem všech tří exponenciálních členů:

Vidíme, že normalizačnímu členu dominuje z1.
Nakonec vydělením normalizačním členem získáme výstup softmaxu pro každý ze tří prvků. Všimněte si, že neexistuje jediná výstupní hodnota, protože softmax transformuje pole na pole stejné délky, v tomto případě 3.
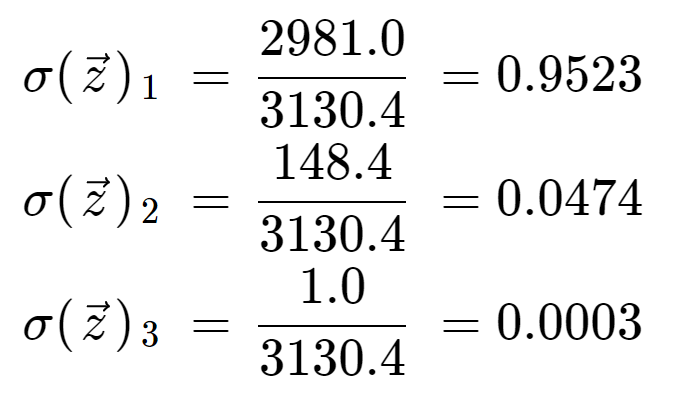
Je informativní zkontrolovat, že máme tři výstupní hodnoty, které jsou všechny platnými pravděpodobnostmi, tj. leží mezi 0 a 1 a jejich součet je 1.
Všimněte si také, že díky exponenciální operaci první prvek, 8, ovládl funkci softmax a vytlačil 5 a 0 na velmi nízké hodnoty pravděpodobnosti.
Použijete-li funkci softmax v modelu strojového učení, měli byste být opatrní, než ji budete interpretovat jako skutečnou pravděpodobnost, protože má tendenci vytvářet hodnoty velmi blízké 0 nebo 1. Pokud by neuronová síť měla výstupní skóre , jako v tomto příkladu, pak by funkce softmax přiřadila první třídě pravděpodobnost 95 %, zatímco ve skutečnosti by v předpovědích neuronové sítě mohla být větší nejistota. To by mohlo vyvolat dojem, že předpověď neuronové sítě má vysokou spolehlivost, i když tomu tak není.
Funkce softmax vs. sigmoidní funkce
Jak bylo uvedeno výše, funkce softmax a sigmoidní funkce jsou si podobné. Softmax pracuje s vektorem, zatímco sigmoida bere skalár.

Sigmoidní funkce je ve skutečnosti speciálním případem funkce softmax pro klasifikátor s pouze dvěma vstupními třídami. Můžeme to ukázat, pokud nastavíme vstupní vektor a vypočítáme první výstupní prvek pomocí obvyklého softmaxového vzorce:

Dělíme-li horní a dolní část ex, dostaneme:

To ukazuje, že sigmoidní funkce se stává ekvivalentní softmaxové funkci, pokud máme dvě třídy. Druhou složku vektoru není nutné explicitně počítat, protože když máme dvě pravděpodobnosti, musí se jejich součet rovnat 1. Pokud tedy vyvíjíme klasifikátor dvou tříd pomocí logistické regrese, můžeme použít sigmoidní funkci a nemusíme pracovat s vektory. Pokud však máme více než dvě vzájemně se vylučující třídy, je třeba použít softmax.
Pokud máme více než dvě třídy a ty se vzájemně nevylučují (víceznačkový klasifikátor), pak lze klasifikátor rozdělit na více binárních klasifikátorů, z nichž každý použije vlastní sigmoidní funkci.
Výpočet funkce softmax vs. sigmoidní funkce
Pokud vezmeme vstupní vektor , můžeme jej vložit jak do funkce softmax, tak do funkce sigmoid. Protože sigmoid přebírá skalární hodnotu, vložíme do sigmoidní funkce pouze první prvek.

Sigmoidní funkce dává stejnou hodnotu jako softmax pro první prvek za předpokladu, že druhý vstupní prvek je nastaven na 0. V případě, že sigmoidní funkce přebírá skalární hodnotu, vložíme do sigmoidní funkce pouze první prvek. Protože sigmoida nám dává pravděpodobnost a obě pravděpodobnosti se musí sečíst do 1, není nutné explicitně počítat hodnotu pro druhý prvek.
Funkce softmax vs. funkce argmax
Funkce softmax byla vyvinuta jako vyhlazená a diferencovatelná alternativa funkce argmax. Z tohoto důvodu se funkce softmax někdy explicitněji nazývá funkce softargmax. Stejně jako funkce softmax pracuje funkce argmax s vektorem a převádí každou hodnotu na nulu s výjimkou maximální hodnoty, kde vrací 1.

Běžně se trénuje model strojového učení pomocí funkce softmax, ale při použití modelu pro inferenci se vrstva softmax vymění za vrstvu argmax.
Při trénování musíme použít funkci softmax, protože je diferencovatelná a umožňuje optimalizovat nákladovou funkci. Pro inferenci však někdy potřebujeme, aby model vydal pouze jednu předpovídanou hodnotu, nikoliv pravděpodobnost, a v takovém případě je argmax užitečnější.
Pokud existuje více maximálních hodnot, je běžné, že argmax vrací 1/Nmax, tedy normalizovaný zlomek, takže součet výstupních prvků zůstává 1 jako u softmaxu. Alternativní definice je vracet 1 pro všechny maximální hodnoty nebo jen pro první hodnotu.
Výpočet funkce softmax vs. funkce argmax
Představme si opět vstupní vektor . Softmax vypočítáme stejně jako předtím. Největší hodnotou je první prvek, takže argmax vrátí 1 pro první prvek a 0 pro ostatní.

Z tohoto příkladu je zřejmé, že softmax se chová jako „měkká“ aproximace funkce argmax: vrací neceločíselné hodnoty mezi 0 a 1, které lze interpretovat jako pravděpodobnosti. Pokud používáme model strojového učení k odvozování, nikoli k jeho trénování, můžeme chtít od systému celočíselný výstup představující tvrdé rozhodnutí, které přijmeme na základě výstupu modelu, například o léčbě nádoru, autentizaci uživatele nebo přiřazení dokumentu k tématu. S hodnotami argmax se v tomto smyslu pracuje snadněji a lze je použít k sestavení matice záměny a výpočtu přesnosti a odvolávky klasifikátoru.
Použití funkce softmax
Funkce softmax v neuronových sítích
Jedním z použití funkce softmax bude na konci neuronové sítě. Uvažujme konvoluční neuronovou síť, která rozpoznává, zda je na obrázku kočka nebo pes. Všimněte si, že obrázek musí být buď kočka, nebo pes, a nemůže být obojí, proto se tyto dvě třídy vzájemně vylučují. Typicky by poslední plně propojená vrstva této sítě produkovala hodnoty typu, které nejsou normalizované a nelze je interpretovat jako pravděpodobnosti. Pokud do sítě přidáme vrstvu softmax, je možné čísla převést na rozdělení pravděpodobnosti. To znamená, že výstup lze zobrazit uživateli, například aplikace si je na 95 % jistá, že se jedná o kočku. Znamená to také, že výstup může být vložen do jiných algoritmů strojového učení, aniž by musel být normalizován, protože je zaručeno, že bude ležet mezi 0 a 1.
Všimněte si, že pokud síť klasifikuje obrázky na psy a kočky a je nakonfigurována tak, aby měla pouze dvě výstupní třídy, pak je nucena zařadit každý obrázek buď jako psa, nebo jako kočku, i když není ani jedním z nich. Pokud potřebujeme tuto možnost připustit, musíme neuronovou síť překonfigurovat tak, aby měla třetí výstup pro různé.
Příklad výpočtu softmaxu v neuronové síti
Softmax je při trénování neuronové sítě nezbytný. Představme si, že máme konvoluční neuronovou síť, která se učí rozlišovat mezi kočkami a psy. Nastavíme kočku jako třídu 1 a psa jako třídu 2.
Pravděpodobně když do naší sítě zadáme obrázek kočky, síť by na výstupu měla vektor . Když zadáme obrázek psa, chceme výstup .
Zpracování obrazu neuronovou sítí končí v poslední plně propojené vrstvě. Výstupem této vrstvy jsou dvě skóre pro kočku a psa, která nejsou pravděpodobnostmi. Obvyklou praxí je přidat na konec neuronové sítě vrstvu softmax, která výstup převede na pravděpodobnostní rozdělení. na začátku trénování jsou váhy neuronové sítě náhodně nakonfigurovány. Takže obrázek kočky prochází a je převeden stupni zpracování obrazu na skóre . Při přechodu do funkce softmax můžeme získat počáteční pravděpodobnosti

Je jasné, že to není žádoucí. Dokonalá síť by v tomto případě dávala výstup .

Můžeme formulovat ztrátovou funkci naší sítě, která kvantifikuje, jak daleko jsou výstupní pravděpodobnosti sítě od požadovaných hodnot. Čím menší je ztrátová funkce, tím blíže je výstupní vektor správné třídě. Nejběžnější ztrátovou funkcí je v tomto případě křížová ztráta, která v tomto případě vychází:
Protože softmax je spojitě diferencovatelná funkce, je možné vypočítat derivaci ztrátové funkce vzhledem ke každé váze v síti, pro každý obrázek v trénovací množině.
Tato vlastnost nám umožňuje upravit váhy sítě tak, abychom snížili ztrátovou funkci a přiblížili výstup sítě k požadovaným hodnotám a zlepšili přesnost sítě. po několika iteracích trénování aktualizujeme váhy sítě. Nyní, když je do sítě vložen stejný obrázek kočky, plně propojená vrstva vyprodukuje vektor skóre o hodnotě . Proložíme-li jej opět funkcí softmax, získáme výstupní pravděpodobnosti:

To je zjevně lepší výsledek a blíží se požadovanému výstupu . Přepočítáme-li ztrátu křížové entropie,

vidíme, že se ztráta snížila, což znamená, že se neuronová síť zlepšila.
Způsob diferencování ztrátové funkce za účelem zjištění, jak upravit váhy sítě, by nebyl možný, kdybychom použili funkci argmax, protože ta není diferencovatelná. Vlastnost diferencovatelnosti činí funkci softmax užitečnou pro trénování neuronových sítí.
Funkce softmax v posilovacím učení
V posilovacím učení se funkce softmax používá také tehdy, když se model potřebuje rozhodnout mezi provedením akce, o níž je aktuálně známo, že má nejvyšší pravděpodobnost odměny, což se nazývá
využití, nebo provedením průzkumného kroku, který se nazývá průzkum.
Příklad výpočtu softmaxu v posilovacím učení
Představte si, že trénujeme model posilovacího učení, aby hrál poker proti člověku. Musíme nastavit teplotu τ, která určuje, s jakou pravděpodobností bude systém provádět náhodné průzkumné akce. Systém má v současné době dvě možnosti: zahrát eso nebo zahrát krále. Z toho, co se doposud naučil, vyplývá, že zahrání esa je v současné situaci s 80% pravděpodobností vítěznou strategií. Za předpokladu, že neexistují žádné jiné možnosti, je 20% pravděpodobnost, že vítěznou strategií bude zahrání krále. Teplotu τ jsme nastavili na 2.
Systém učení s posílením používá funkci softmax k získání pravděpodobnosti zahrání esa, resp. krále. Upravený vzorec softmax používaný v posilovacím učení je následující:

Vysvětlení symbolů vzorce softmax posilovacího učení
| Pravděpodobnost, že model nyní provede akci a v čase t. | |
| Akce, kterou zvažujeme provést. Například zahrát krále nebo eso. | |
 |
Teplota systému, nastavená jako hyperparametr. |
|
Aktuální nejlepší odhad pravděpodobnosti úspěchu, pokud provedeme akci i, z toho, co se model dosud naučil. |
Posazením našich hodnot do rovnice dostaneme:

To znamená, že ačkoli si je model aktuálně z 80 % jistý, že eso je správná strategie, je pravděpodobnost, že tuto kartu zahraje, pouze 57 %. Je to proto, že při posilovacím učení přiřazujeme hodnotu jak průzkumu (testování nových strategií), tak využití (používání známých strategií). Pokud se rozhodneme zvýšit teplotu, model se stane více „impulzivním“: je pravděpodobnější, že bude podnikat spíše průzkumné kroky, než aby vždy hrál vítěznou strategii.
Historie softmaxu
První známé použití funkce softmax předchází strojovému učení. Funkce softmax je ve skutečnosti převzata z fyziky a statistické mechaniky, kde je známa jako Boltzmannovo rozdělení nebo Gibbsovo rozdělení. Formuloval ji rakouský fyzik a filozof Ludwig Boltzmann v roce 1868.
Boltzmann se zabýval statistickou mechanikou plynů v tepelné rovnováze. Zjistil, že Boltzmannovým rozdělením lze popsat pravděpodobnost nalezení systému v určitém stavu při dané energii tohoto stavu a teplotě systému. Jeho verze vzorce byla podobná té, která se používá v posilování učení. Ostatně parametr τ se v oblasti posilovacího učení nazývá teplota jako pocta Boltzmannovi.
V roce 1902 zpopularizoval Boltzmannovo rozdělení americký fyzik a chemik Josiah Willard Gibbs, když s jeho pomocí položil základy termodynamiky a své definice entropie. Tvoří také základ spektroskopie, tj. analýzy materiálů pomocí pozorování světla, které pohlcují a odrážejí.
V roce 1959 navrhl Robert Duncan Luce ve své knize Individual Choice Behavior (Chování při individuální volbě) použití funkce softmax pro posilovací učení: A Theoretical Analysis. Nakonec v roce 1989 John S. Bridle navrhl, aby byla funkce argmax ve feedforward neuronových sítích nahrazena funkcí softmax, protože „zachovává pořadí svých vstupních hodnot a je diferencovatelným zobecněním operace výběru maximální hodnoty ‚vítěz bere vše'“. V posledních letech, kdy se neuronové sítě začaly široce používat, se softmax díky těmto vlastnostem stal dobře známým.
.