- Cos’è la funzione Softmax?
- Formula softmax
- Spiegati i simboli della formula softmax
- Calcolo del Softmax
- Funzione softmax vs funzione sigmoide
- Calcolo della funzione Softmax vs funzione sigmoide
- Funzione softmax vs funzione argmax
- Calcolo della funzione Softmax vs funzione argmax
- Applicazioni della funzione Softmax
- Funzione Softmax nelle reti neurali
- Esempio di calcolo della Softmax in una rete neurale
- Funzione softmax nell’apprendimento per rinforzo
- Esempio di calcolo di Softmax nell’apprendimento per rinforzo
- Reinforcement Learning Softmax Formula Symbols Explained
- Storia del softmax
Cos’è la funzione Softmax?
La funzione softmax è una funzione che trasforma un vettore di K valori reali in un vettore di K valori reali che sommano a 1. I valori di input possono essere positivi, negativi, zero, o maggiori di uno, ma il softmax li trasforma in valori tra 0 e 1, in modo che possano essere interpretati come probabilità. Se uno degli input è piccolo o negativo, il softmax lo trasforma in una piccola probabilità, e se un input è grande, allora lo trasforma in una grande probabilità, ma rimarrà sempre tra 0 e 1.
La funzione softmax è talvolta chiamata funzione softargmax, o regressione logistica multiclasse. Questo perché la softmax è una generalizzazione della regressione logistica che può essere usata per la classificazione multiclasse, e la sua formula è molto simile alla funzione sigmoide che è usata per la regressione logistica. La funzione softmax può essere usata in un classificatore solo quando le classi sono mutuamente esclusive.
Molte reti neurali multistrato terminano in un penultimo strato che produce punteggi con valore reale che non sono convenientemente scalati e che possono essere difficili da lavorare. Qui il softmax è molto utile perché converte i punteggi in una distribuzione di probabilità normalizzata, che può essere visualizzata ad un utente o utilizzata come input per altri sistemi. Per questo motivo è usuale aggiungere una funzione softmax come strato finale della rete neurale.
Formula softmax
La formula softmax è la seguente:
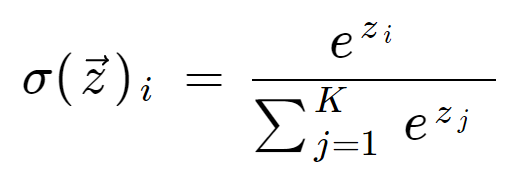
Definizione matematica della funzione softmax
dove tutti i valori zi sono gli elementi del vettore di input e possono assumere qualsiasi valore reale. Il termine in basso nella formula è il termine di normalizzazione che assicura che tutti i valori di uscita della funzione sommino a 1, costituendo così una distribuzione di probabilità valida.
Spiegati i simboli della formula softmax
| Il vettore di ingresso alla funzione softmax, costituito da (z0, … zK) | |
| Tutti i valori zi sono gli elementi del vettore di input alla funzione softmax, e possono assumere qualsiasi valore reale, positivo, zero o negativo. Per esempio una rete neurale potrebbe avere in uscita un vettore come (-0.62, 8.12, 2.53), che non è una distribuzione di probabilità valida, da qui la necessità della softmax. | |
 |
La funzione esponenziale standard è applicata ad ogni elemento del vettore di input. Questo dà un valore positivo sopra lo 0, che sarà molto piccolo se l’input era negativo, e molto grande se l’input era grande. Tuttavia, non è ancora fissato nell’intervallo (0, 1) che è ciò che si richiede a una probabilità. |
 |
Il termine in fondo alla formula è il termine di normalizzazione. Assicura che tutti i valori di uscita della funzione sommino a 1 e siano tutti nell’intervallo (0, 1), costituendo così una valida distribuzione di probabilità. |
| Il numero di classi nel classificatore multiclasse. |
Calcolo del Softmax
Immaginate di avere un array di tre valori reali. Questi valori potrebbero essere tipicamente l’output di un modello di apprendimento automatico come una rete neurale. Vogliamo convertire i valori in una distribuzione di probabilità.

Prima possiamo calcolare l’esponenziale di ogni elemento della matrice di input. Questo è il termine nella metà superiore dell’equazione softmax.
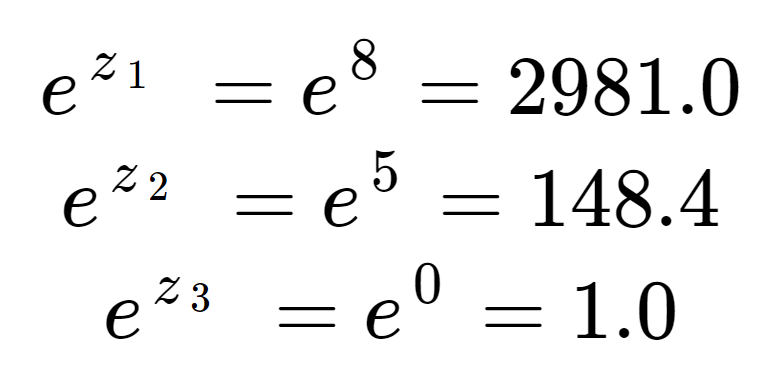
Questi valori non sembrano ancora probabilità. Si noti che negli elementi di ingresso, anche se 8 è solo un po’ più grande di 5, 2981 è molto più grande di 148 a causa dell’effetto dell’esponenziale. Possiamo ottenere il termine di normalizzazione, la metà inferiore dell’equazione softmax, sommando tutti e tre i termini esponenziali:

Vediamo che il termine di normalizzazione è stato dominato da z1.
Infine, dividendo per il termine di normalizzazione, otteniamo l’uscita softmax per ciascuno dei tre elementi. Notate che non c’è un solo valore di uscita perché il softmax trasforma un array in un array della stessa lunghezza, in questo caso 3.
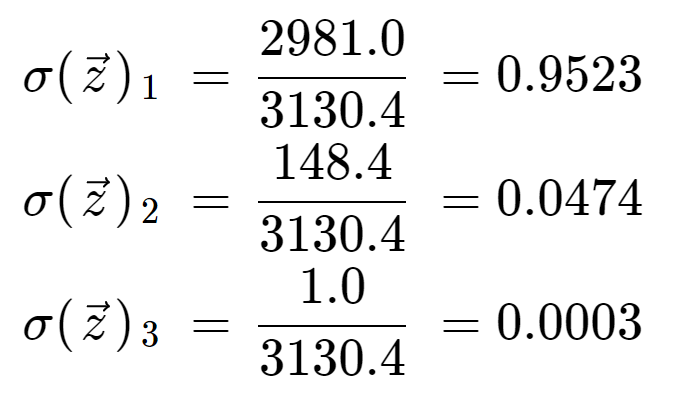
È informativo controllare che abbiamo tre valori di uscita che sono tutti probabilità valide, cioè stanno tra 0 e 1, e sommano a 1.
Nota anche che a causa dell’operazione esponenziale, il primo elemento, l’8, ha dominato la funzione softmax e ha compresso il 5 e lo 0 in valori di probabilità molto bassi.
Se si usa la funzione softmax in un modello di apprendimento automatico, si dovrebbe fare attenzione prima di interpretarla come una vera probabilità, poiché ha la tendenza a produrre valori molto vicini a 0 o 1. Se una rete neurale avesse punteggi in uscita di , come in questo esempio, allora la funzione softmax avrebbe assegnato il 95% di probabilità alla prima classe, quando in realtà potrebbe esserci stata più incertezza nelle previsioni della rete neurale. Questo potrebbe dare l’impressione che la previsione della rete neurale abbia un’alta confidenza quando non è così.
Funzione softmax vs funzione sigmoide
Come detto sopra, la funzione softmax e la funzione sigmoide sono simili. La softmax opera su un vettore mentre la sigmoide prende uno scalare.

In effetti, la funzione sigmoide è un caso speciale della funzione softmax per un classificatore con solo due classi di ingresso. Possiamo dimostrarlo se impostiamo il vettore di input e calcoliamo il primo elemento di output con la solita formula softmax:

Dividendo l’alto e il basso per ex, otteniamo:

Questo dimostra che la funzione sigmoide diventa equivalente alla funzione softmax quando abbiamo due classi. Non è necessario calcolare esplicitamente la seconda componente vettoriale perché quando ci sono due probabilità, esse devono sommarsi a 1. Quindi, se stiamo sviluppando un classificatore a due classi con regressione logistica, possiamo usare la funzione sigmoide e non abbiamo bisogno di lavorare con i vettori. Ma se abbiamo più di due classi che si escludono a vicenda, dovrebbe essere usata la softmax.
Se ci sono più di due classi e non si escludono a vicenda (un classificatore multi-label), allora il classificatore può essere diviso in più classificatori binari, ognuno dei quali usa la propria funzione sigmoide.
Calcolo della funzione Softmax vs funzione sigmoide
Se prendiamo un vettore di input, possiamo metterlo in entrambe le funzioni softmax e sigmoide. Poiché la sigmoide prende un valore scalare, mettiamo solo il primo elemento nella funzione sigmoide.

La funzione sigmoide dà lo stesso valore della softmax per il primo elemento, a condizione che il secondo elemento di input sia impostato a 0. Poiché la sigmoide ci dà una probabilità, e le due probabilità devono sommarsi a 1, non è necessario calcolare esplicitamente un valore per il secondo elemento.
Funzione softmax vs funzione argmax
La funzione softmax è stata sviluppata come alternativa smussata e differenziabile alla funzione argmax. Per questo motivo la funzione softmax è talvolta chiamata più esplicitamente funzione softargmax. Come la softmax, la funzione argmax opera su un vettore e converte ogni valore in zero eccetto il valore massimo, dove restituisce 1.

E’ comune addestrare un modello di apprendimento automatico usando la softmax ma sostituire lo strato softmax con uno strato argmax quando il modello viene usato per l’inferenza.
Dobbiamo usare la softmax in addestramento perché la softmax è differenziabile e ci permette di ottimizzare una funzione di costo. Tuttavia, per l’inferenza a volte abbiamo bisogno di un modello solo per produrre un singolo valore previsto piuttosto che una probabilità, nel qual caso l’argmax è più utile.
Quando ci sono più valori massimi è comune che l’argmax restituisca 1/Nmax, cioè una frazione normalizzata, in modo che la somma degli elementi in uscita rimanga 1 come con il softmax. Una definizione alternativa è quella di restituire 1 per tutti i valori massimi, o solo per il primo valore.
Calcolo della funzione Softmax vs funzione argmax
Immaginiamo di nuovo il vettore di input . Calcoliamo il softmax come prima. Il valore più grande è il primo elemento, quindi l’argmax restituirà 1 per il primo elemento e 0 per il resto.

È chiaro da questo esempio che la softmax si comporta come un’approssimazione ‘soft’ dell’argmax: restituisce valori non interi tra 0 e 1 che possono essere interpretati come probabilità. Se stiamo usando un modello di apprendimento automatico per l’inferenza, piuttosto che addestrarlo, potremmo volere un output intero dal sistema che rappresenti una decisione difficile da prendere con l’output del modello, come trattare un tumore, autenticare un utente, o assegnare un documento ad un argomento. I valori argmax sono più facili da lavorare in questo senso e possono essere usati per costruire una matrice di confusione e calcolare la precisione e il richiamo di un classificatore.
Applicazioni della funzione Softmax
Funzione Softmax nelle reti neurali
Un uso della funzione softmax sarebbe alla fine di una rete neurale. Consideriamo una rete neurale convoluzionale che riconosce se un’immagine è un gatto o un cane. Si noti che un’immagine deve essere o un gatto o un cane, e non può essere entrambi, quindi le due classi si escludono a vicenda. Tipicamente, lo strato finale completamente connesso di questa rete produrrebbe valori come che non sono normalizzati e non possono essere interpretati come probabilità. Se aggiungiamo uno strato softmax alla rete, è possibile tradurre i numeri in una distribuzione di probabilità. Questo significa che l’output può essere mostrato all’utente, per esempio l’app è sicura al 95% che questo sia un gatto. Significa anche che l’output può essere inserito in altri algoritmi di apprendimento automatico senza bisogno di essere normalizzato, poiché è garantito che si trovi tra 0 e 1.
Nota che se la rete sta classificando le immagini in cani e gatti, ed è configurata per avere solo due classi di output, allora è costretta a classificare ogni immagine come cane o gatto, anche se non è nessuna delle due. Se dobbiamo permettere questa possibilità, allora dobbiamo riconfigurare la rete neurale per avere una terza uscita per miscellanea.
Esempio di calcolo della Softmax in una rete neurale
La softmax è essenziale quando stiamo addestrando una rete neurale. Immaginiamo di avere una rete neurale convoluzionale che sta imparando a distinguere tra cani e gatti. Impostiamo il gatto come classe 1 e il cane come classe 2.
Idealmente, quando inseriamo l’immagine di un gatto nella nostra rete, la rete emette il vettore . Quando inseriamo un’immagine di un cane, vogliamo un output .
L’elaborazione delle immagini della rete neurale termina allo strato finale completamente connesso. Questo strato produce due punteggi per gatto e cane, che non sono probabilità. E’ pratica comune aggiungere uno strato softmax alla fine della rete neurale, che converte l’output in una distribuzione di probabilità.All’inizio dell’addestramento, i pesi della rete neurale sono configurati in modo casuale. Quindi l’immagine del gatto passa attraverso e viene convertita dalle fasi di elaborazione dell’immagine in punteggi . Passando nella funzione softmax possiamo ottenere le probabilità iniziali

Chiaramente questo non è desiderabile. Una rete perfetta in questo caso produrrebbe .

Possiamo formulare una funzione di perdita della nostra rete che quantifica quanto le probabilità di uscita della rete sono lontane dai valori desiderati. Più piccola è la funzione di perdita, più il vettore di uscita è vicino alla classe corretta. La funzione di perdita più comune in questo caso è la perdita di cross-entropia che in questo caso viene a:
Perché la softmax è una funzione continuamente differenziabile, è possibile calcolare la derivata della funzione di perdita rispetto ad ogni peso della rete, per ogni immagine del set di allenamento.
Questa proprietà ci permette di regolare i pesi della rete per ridurre la funzione di perdita e rendere l’output della rete più vicino ai valori desiderati e migliorare la precisione della rete. Ora, quando la stessa immagine di un gatto viene immessa nella rete, lo strato completamente connesso produce un vettore di punteggio di

. Ricalcolando la perdita cross-entropia,

vediamo che la perdita si è ridotta, indicando che la rete neurale è migliorata.
Il metodo di differenziare la funzione di perdita per accertare come regolare i pesi della rete non sarebbe stato possibile se avessimo usato la funzione argmax, perché non è differenziabile. La proprietà della differenziabilità rende la funzione softmax utile per l’addestramento delle reti neurali.
Funzione softmax nell’apprendimento per rinforzo
Nell’apprendimento per rinforzo, la funzione softmax è anche usata quando un modello deve decidere tra intraprendere l’azione che al momento è nota per avere la più alta probabilità di ricompensa, chiamata
sfruttamento, o fare un passo esplorativo, chiamato esplorazione.
Esempio di calcolo di Softmax nell’apprendimento per rinforzo
Immaginiamo di addestrare un modello di apprendimento per rinforzo a giocare a poker contro un umano. Dobbiamo configurare una temperatura τ, che stabilisce quanto è probabile che il sistema compia azioni esplorative casuali. Il sistema ha due opzioni al momento: giocare un Asso o giocare un Re. Da quello che ha imparato finora, giocare un Asso ha l’80% di probabilità di essere la strategia vincente nella situazione attuale. Assumendo che non ci siano altre possibili giocate, giocare un Re ha il 20% di probabilità di essere la strategia vincente. Abbiamo configurato la temperatura τ a 2.
Il sistema di apprendimento per rinforzo usa la funzione softmax per ottenere la probabilità di giocare rispettivamente un Asso e un Re. La formula softmax modificata usata nell’apprendimento per rinforzo è la seguente:

Reinforcement Learning Softmax Formula Symbols Explained
| La probabilità che il modello intraprenda l’azione a al tempo t. | |
| L’azione che stiamo prendendo in considerazione. Per esempio, giocare un Re o un Asso. | |
 |
La temperatura del sistema, configurata come iperparametro. |
|
La migliore stima attuale della probabilità di successo se intraprendiamo l’azione i, da ciò che il modello ha imparato finora. |
Mettendo i nostri valori nell’equazione si ottiene:

Questo significa che sebbene il modello sia attualmente sicuro all’80% che l’Asso sia la strategia corretta, ha solo il 57% di probabilità di giocare quella carta. Questo perché nell’apprendimento per rinforzo assegniamo un valore all’esplorazione (provare nuove strategie) e allo sfruttamento (usare strategie conosciute). Se scegliamo di aumentare la temperatura, il modello diventa più ‘impulsivo’: è più probabile che faccia passi esplorativi piuttosto che giocare sempre la strategia vincente.
Storia del softmax
Il primo uso conosciuto della funzione softmax è precedente all’apprendimento automatico. La funzione softmax è infatti presa in prestito dalla fisica e dalla meccanica statistica, dove è conosciuta come la distribuzione di Boltzmann o la distribuzione di Gibbs. Fu formulata dal fisico e filosofo austriaco Ludwig Boltzmann nel 1868.
Boltzmann stava studiando la meccanica statistica dei gas in equilibrio termico. Trovò che la distribuzione di Boltzmann poteva descrivere la probabilità di trovare un sistema in un certo stato, data l’energia di quello stato e la temperatura del sistema. La sua versione della formula era simile a quella utilizzata nell’apprendimento per rinforzo. Infatti, il parametro τ è chiamato temperatura nel campo dell’apprendimento per rinforzo come un omaggio a Boltzmann.
Nel 1902 il fisico e chimico americano Josiah Willard Gibbs rese popolare la distribuzione di Boltzmann quando la usò per porre le basi della termodinamica e la sua definizione di entropia. È anche la base della spettroscopia, cioè l’analisi dei materiali guardando la luce che assorbono e riflettono.
Nel 1959 Robert Duncan Luce propose l’uso della funzione softmax per l’apprendimento di rinforzo nel suo libro Individual Choice Behavior: A Theoretical Analysis. Infine, nel 1989 John S. Bridle ha suggerito che l’argmax nelle reti neurali feedforward dovrebbe essere sostituito da softmax perché “conserva l’ordine di rango dei suoi valori di input, ed è una generalizzazione differenziabile dell’operazione ‘winner-take-all’ di scegliere il valore massimo”. Negli ultimi anni, poiché le reti neurali sono diventate ampiamente utilizzate, la softmax è diventata ben nota grazie a queste proprietà.