- Co to jest funkcja softmax?
- Sformułowanie softmax
- Softmax Formula Symbols Explained
- Obliczanie Softmax
- Funkcja softmax vs funkcja sigmoidalna
- Obliczanie funkcji softmax vs funkcja sigmoidalna
- Funkcja softmax vs funkcja argmax
- Obliczanie funkcji Softmax vs Funkcja Argmax
- Zastosowania funkcji softmax
- Funkcja softmax w sieciach neuronowych
- Przykład obliczania Softmax w sieci neuronowej
- Funkcja softmax w uczeniu wzmacniającym
- Przykład obliczania Softmax w uczeniu wzmacniającym
- Reinforcement Learning Softmax Formula Symbole Symbole wyjaśnione
- Historia softmax
Co to jest funkcja softmax?
Funkcja softmax jest funkcją, która przekształca wektor K wartości rzeczywistych w wektor K wartości rzeczywistych, które sumują się do 1. Wartości wejściowe mogą być dodatnie, ujemne, zerowe lub większe niż jeden, ale softmax przekształca je w wartości pomiędzy 0 i 1, tak że można je interpretować jako prawdopodobieństwa. Jeśli jedna z wartości wejściowych jest mała lub ujemna, to softmax przekształca ją w małe prawdopodobieństwo, a jeśli wartość wejściowa jest duża, to przekształca ją w duże prawdopodobieństwo, ale zawsze pozostanie ona w przedziale od 0 do 1.
Funkcja softmax jest czasami nazywana funkcją softargmax lub wieloklasową regresją logistyczną. Dzieje się tak dlatego, że softmax jest uogólnieniem regresji logistycznej, która może być używana do klasyfikacji wieloklasowej, a jej wzór jest bardzo podobny do funkcji sigmoidalnej, która jest używana do regresji logistycznej. Funkcja softmax może być użyta w klasyfikatorze tylko wtedy, gdy klasy wzajemnie się wykluczają.
Wiele wielowarstwowych sieci neuronowych kończy się na przedostatniej warstwie, która wyprowadza wyniki o rzeczywistej wartości, które nie są wygodnie skalowane i z którymi może być trudno pracować. Tutaj softmax jest bardzo użyteczny, ponieważ konwertuje wyniki do znormalizowanego rozkładu prawdopodobieństwa, który może być wyświetlony użytkownikowi lub użyty jako dane wejściowe do innych systemów. Z tego powodu zwykle dołącza się funkcję softmax jako ostatnią warstwę sieci neuronowej.
Sformułowanie softmax
Sformułowanie softmax jest następujące:
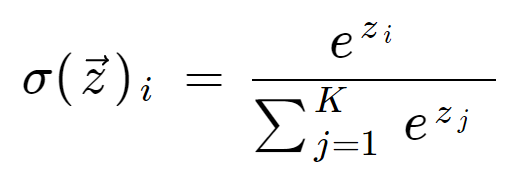
Matematyczna definicja funkcji softmax
gdzie wszystkie wartości zi są elementami wektora wejściowego i mogą przyjmować dowolną wartość rzeczywistą. Termin na dole wzoru to termin normalizacji, który zapewnia, że wszystkie wartości wyjściowe funkcji będą sumować się do 1, stanowiąc tym samym prawidłowy rozkład prawdopodobieństwa.
Softmax Formula Symbols Explained
| Wektor wejściowy funkcji softmax, złożony z (z0, … zK) | |
| Wszystkie wartości zi są elementami wektora wejściowego do funkcji softmax i mogą przyjmować dowolną wartość rzeczywistą, dodatnią, zerową lub ujemną. Na przykład sieć neuronowa mogłaby wyprowadzić wektor taki jak (-0.62, 8.12, 2.53), który nie jest prawidłowym rozkładem prawdopodobieństwa, stąd konieczność zastosowania softmax. | |
 |
Standardowa funkcja wykładnicza jest stosowana do każdego elementu wektora wejściowego. Daje to dodatnią wartość powyżej 0, która będzie bardzo mała, jeśli dane wejściowe były ujemne, i bardzo duża, jeśli dane wejściowe były duże. Jednak nadal nie jest ona stała w przedziale (0, 1), co jest wymagane od prawdopodobieństwa. |
 |
Wyraz na dole wzoru jest wyrazem normalizacji. Zapewnia on, że wszystkie wartości wyjściowe funkcji będą sumować się do 1 i każda z nich będzie w przedziale (0, 1), stanowiąc w ten sposób prawidłowy rozkład prawdopodobieństwa. |
| Liczba klas w klasyfikatorze wieloklasowym. |
Obliczanie Softmax
Wyobraźmy sobie, że mamy tablicę trzech wartości rzeczywistych. Wartości te mogą być typowo wyjściem modelu uczenia maszynowego, takiego jak sieć neuronowa. Chcemy przekształcić te wartości w rozkład prawdopodobieństwa.

Po pierwsze możemy obliczyć wykładnik każdego elementu tablicy wejściowej. Jest to termin w górnej połowie równania softmax.
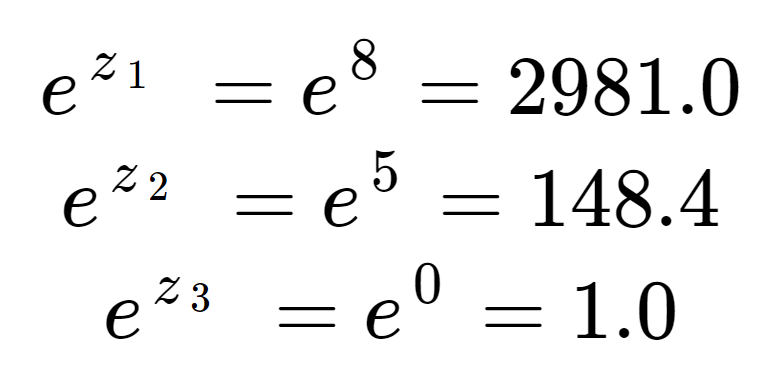
Wartości te nie wyglądają jeszcze jak prawdopodobieństwa. Zauważmy, że w elementach wejściowych, chociaż 8 jest tylko trochę większe niż 5, 2981 jest znacznie większe niż 148 z powodu efektu wykładniczego. Możemy otrzymać termin normalizacji, dolną połowę równania softmax, poprzez zsumowanie wszystkich trzech terminów wykładniczych:

Widzimy, że termin normalizacji został zdominowany przez z1.
W końcu, dzieląc przez termin normalizacji, otrzymujemy wyjście softmax dla każdego z trzech elementów. Zauważ, że nie ma jednej wartości wyjściowej, ponieważ softmax przekształca tablicę w tablicę o tej samej długości, w tym przypadku 3.
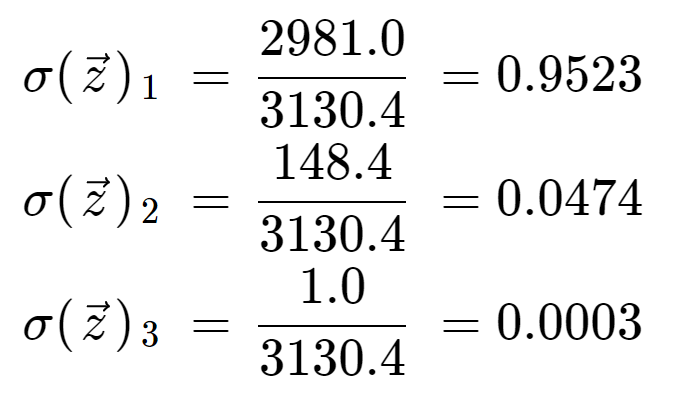
Informacyjne jest sprawdzenie, że mamy trzy wartości wyjściowe, które wszystkie są prawidłowymi prawdopodobieństwami, to znaczy leżą pomiędzy 0 i 1, i sumują się do 1.
Zauważ również, że z powodu operacji wykładniczej, pierwszy element, 8, zdominował funkcję softmax i wycisnął 5 i 0 do bardzo niskich wartości prawdopodobieństwa.
Jeśli używasz funkcji softmax w modelu uczenia maszynowego, powinieneś być ostrożny przed interpretowaniem jej jako prawdziwego prawdopodobieństwa, ponieważ ma ona tendencję do produkowania wartości bardzo bliskich 0 lub 1. Jeśli sieć neuronowa miałaby wyniki wyjściowe równe , jak w tym przykładzie, to funkcja softmax przypisałaby 95% prawdopodobieństwa pierwszej klasie, podczas gdy w rzeczywistości przewidywania sieci neuronowej mogły być bardziej niepewne. Mogłoby to sprawiać wrażenie, że przewidywania sieci neuronowej miały wysoką pewność, podczas gdy tak nie było.
Funkcja softmax vs funkcja sigmoidalna
Jak wspomniano powyżej, funkcja softmax i funkcja sigmoidalna są podobne. Softmax operuje na wektorze, podczas gdy sigmoid przyjmuje skalar.

W rzeczywistości, funkcja sigmoid jest specjalnym przypadkiem funkcji softmax dla klasyfikatora z tylko dwoma klasami wejściowymi. Możemy to pokazać, jeśli ustawimy wektor wejściowy na be i obliczymy pierwszy element wyjściowy za pomocą zwykłej formuły softmax:

Dzieląc górę i dół przez ex, otrzymamy:

To pokazuje, że funkcja sigmoidalna staje się równoważna funkcji softmax, gdy mamy dwie klasy. Nie jest konieczne jawne obliczanie drugiej składowej wektora, ponieważ gdy istnieją dwa prawdopodobieństwa, muszą one sumować się do 1. Tak więc, jeśli opracowujemy dwuklasowy klasyfikator za pomocą regresji logistycznej, możemy użyć funkcji sigmoidalnej i nie musimy pracować z wektorami. Ale jeśli mamy więcej niż dwie wzajemnie wykluczające się klasy, należy użyć funkcji softmax.
Jeśli istnieją więcej niż dwie klasy i nie są one wzajemnie wykluczające się (klasyfikator wieloznakowy), wtedy klasyfikator może być podzielony na wiele klasyfikatorów binarnych, z których każdy używa własnej funkcji sigmoidalnej.
Obliczanie funkcji softmax vs funkcja sigmoidalna
Jeśli weźmiemy wektor wejściowy, możemy umieścić go zarówno w funkcji softmax, jak i sigmoidalnej. Ponieważ sigmoida przyjmuje wartość skalarną, do funkcji sigmoidy wstawiamy tylko pierwszy element.

Funkcja sigmoidy daje taką samą wartość jak softmax dla pierwszego elementu, pod warunkiem, że drugi element wejściowy jest ustawiony na 0. Ponieważ sigmoida podaje nam prawdopodobieństwo, a dwa prawdopodobieństwa muszą sumować się do 1, nie jest konieczne jawne obliczanie wartości dla drugiego elementu.
Funkcja softmax vs funkcja argmax
Funkcja softmax została opracowana jako wygładzona i różniczkowalna alternatywa dla funkcji argmax. Z tego powodu funkcja softmax jest czasami bardziej jednoznacznie nazywana funkcją softargmax. Podobnie jak softmax, funkcja argmax operuje na wektorze i konwertuje każdą wartość na zero z wyjątkiem wartości maksymalnej, gdzie zwraca 1.

Powszechne jest trenowanie modelu uczenia maszynowego za pomocą softmax, ale zamienia warstwę softmax na warstwę argmax, gdy model jest używany do wnioskowania.
Musimy używać softmax w szkoleniu, ponieważ softmax jest różniczkowalna i pozwala nam na optymalizację funkcji kosztu. Jednak w przypadku wnioskowania czasami potrzebujemy modelu tylko do wyprowadzenia pojedynczej przewidywanej wartości, a nie prawdopodobieństwa, w którym to przypadku argmax jest bardziej użyteczny.
Gdy istnieje wiele wartości maksymalnych, często argmax zwraca 1/Nmax, czyli znormalizowany ułamek, tak że suma elementów wyjściowych pozostaje 1, jak w przypadku softmax. Alternatywną definicją jest zwrócenie 1 dla wszystkich wartości maksymalnych lub tylko dla pierwszej wartości.
Obliczanie funkcji Softmax vs Funkcja Argmax
Wyobraźmy sobie ponownie wektor wejściowy . Softmax obliczamy tak jak poprzednio. Największą wartością jest pierwszy element, więc argmax zwróci 1 dla pierwszego elementu i 0 dla pozostałych.

Z tego przykładu jasno wynika, że softmax zachowuje się jak „miękka” aproksymacja argmax: zwraca niecałkowite wartości między 0 a 1, które można interpretować jako prawdopodobieństwa. Jeśli używamy modelu uczenia maszynowego do wnioskowania, a nie do jego trenowania, możemy chcieć, aby na wyjściu systemu pojawiła się liczba całkowita reprezentująca twardą decyzję, którą podejmiemy na podstawie danych wyjściowych modelu, taką jak leczenie guza, uwierzytelnienie użytkownika lub przypisanie dokumentu do tematu. Wartości argmax są łatwiejsze do pracy w tym sensie i mogą być używane do budowania macierzy konfuzji i obliczania precyzji i recall klasyfikatora.
Zastosowania funkcji softmax
Funkcja softmax w sieciach neuronowych
Jednym z zastosowań funkcji softmax może być na końcu sieci neuronowej. Rozważmy konwencjonalną sieć neuronową, która rozpoznaje, czy obraz jest kotem czy psem. Zauważmy, że obraz musi być albo kotem, albo psem i nie może być obydwoma, dlatego te dwie klasy wzajemnie się wykluczają. Typowo, ostatnia w pełni połączona warstwa tej sieci produkowałaby wartości, które nie są znormalizowane i nie mogą być interpretowane jako prawdopodobieństwo. Jeśli dodamy do sieci warstwę softmax, możliwe jest przetłumaczenie liczb na rozkład prawdopodobieństwa. Oznacza to, że dane wyjściowe mogą być wyświetlane użytkownikowi, na przykład aplikacja jest w 95% pewna, że to jest kot. Oznacza to również, że wyjście może być podawany do innych algorytmów uczenia maszynowego bez konieczności normalizacji, ponieważ jest gwarantowana leżeć między 0 i 1.
Zauważ, że jeśli sieć jest klasyfikowanie obrazów do psów i kotów, i jest skonfigurowany, aby mieć tylko dwie klasy wyjściowe, to jest zmuszony do sklasyfikowania każdego obrazu jako psa lub kota, nawet jeśli jest to ani. Jeśli musimy dopuścić taką możliwość, to musimy przekonfigurować sieć neuronową tak, aby miała trzecie wyjście dla różnych.
Przykład obliczania Softmax w sieci neuronowej
Softmax jest niezbędna, gdy trenujemy sieć neuronową. Wyobraźmy sobie, że mamy konwencjonalną sieć neuronową, która uczy się rozróżniać koty od psów. Ustawiamy kota jako klasę 1 i psa jako klasę 2.
Idealnie, gdy wprowadzimy obraz kota do naszej sieci, sieć wyprowadzi wektor . Kiedy wprowadzamy obraz psa, chcemy wyjście .
Obróbka obrazu sieci neuronowej kończy się na ostatniej w pełni połączonej warstwie. Warstwa ta wyprowadza dwa wyniki dla kota i psa, które nie są prawdopodobieństwami. Jest to zwykła praktyka, aby dodać warstwę softmax do końca sieci neuronowej, która przekształca wyjście do rozkładu prawdopodobieństwa.Na początku szkolenia, wagi sieci neuronowej są losowo skonfigurowane. Tak więc obraz kota przechodzi przez i jest przekształcany przez etapy przetwarzania obrazu na wyniki . Przechodząc do funkcji softmax możemy uzyskać początkowe prawdopodobieństwa

Jasno widać, że nie jest to pożądane. Idealna sieć w tym przypadku produkowałaby

Możemy sformułować funkcję straty naszej sieci, która określa, jak daleko prawdopodobieństwa wyjściowe sieci są od pożądanych wartości. Im mniejsza funkcja straty, tym wektor wyjściowy jest bliższy prawidłowej klasie. Najczęstszą funkcją straty w tym przypadku jest strata entropii krzyżowej, która w tym przypadku wynosi:
Ponieważ softmax jest funkcją różniczkowalną w sposób ciągły, możliwe jest obliczenie pochodnej funkcji straty w odniesieniu do każdej wagi w sieci, dla każdego obrazu w zbiorze treningowym.
Ta właściwość pozwala nam dostosować wagi sieci w celu zmniejszenia funkcji straty i uczynić wyjście sieci bliższe pożądanym wartościom i poprawić dokładność sieci.Po kilku iteracjach szkolenia, aktualizujemy wagi sieci. Teraz, gdy ten sam obraz kota jest wprowadzany do sieci, w pełni połączona warstwa wyprowadza wektor wyników o wartości

Jest to wyraźnie lepszy wynik i bliższy pożądanej wartości wyjściowej . Przeliczając stratę entropii krzyżowej,

widzimy, że strata zmniejszyła się, wskazując, że sieć neuronowa uległa poprawie.
Metoda różnicowania funkcji straty w celu ustalenia, jak dostosować wagi sieci nie byłaby możliwa, gdybyśmy użyli funkcji argmax, ponieważ nie jest ona różniczkowalna. Właściwość różniczkowalności sprawia, że funkcja softmax jest przydatna do szkolenia sieci neuronowych.
Funkcja softmax w uczeniu wzmacniającym
W uczeniu wzmacniającym funkcja softmax jest również używana, gdy model musi zdecydować między podjęciem działania, o którym aktualnie wiadomo, że ma największe prawdopodobieństwo nagrody, zwanego
eksploatacją, a podjęciem kroku eksploracyjnego, zwanego eksploracją.
Przykład obliczania Softmax w uczeniu wzmacniającym
Wyobraźmy sobie, że trenujemy model uczenia wzmacniającego, aby grał w pokera przeciwko człowiekowi. Musimy skonfigurować temperaturę τ, która określa, jak prawdopodobne jest, że system będzie podejmował losowe działania eksploracyjne. System ma w tej chwili dwie opcje: zagrać asa lub zagrać króla. Z tego, czego nauczył się do tej pory, zagranie asa jest w 80% prawdopodobne jako strategia wygrywająca w obecnej sytuacji. Zakładając, że nie ma innych możliwych zagrań, zagranie króla ma 20% szans na wygraną. Skonfigurowaliśmy temperaturę τ na 2.
System uczenia wzmacniającego używa funkcji softmax do uzyskania prawdopodobieństwa zagrania odpowiednio asa i króla. Zmodyfikowana formuła softmax stosowana w uczeniu wzmacniającym jest następująca:

Reinforcement Learning Softmax Formula Symbole Symbole wyjaśnione
| Prawdopodobieństwo, że model podejmie teraz działanie a w czasie t. | |
| Działanie, którego podjęcie rozważamy. Na przykład, zagranie króla lub asa. | |
 |
Temperatura systemu, skonfigurowana jako hiperparametr. |
|
Obecnie najlepsze oszacowanie prawdopodobieństwa sukcesu, jeśli podejmiemy akcję i, na podstawie tego, czego model nauczył się do tej pory. |
Wstawiając nasze wartości do równania otrzymujemy:

To oznacza, że chociaż model jest obecnie w 80% pewny, że as jest poprawną strategią, to prawdopodobieństwo zagrania tej karty wynosi tylko 57%. Dzieje się tak dlatego, że w uczeniu wzmacniającym przypisujemy wartość zarówno eksploracji (testowaniu nowych strategii), jak i eksploatacji (stosowaniu znanych strategii). Jeśli zdecydujemy się zwiększyć temperaturę, model staje się bardziej „impulsywny”: jest bardziej prawdopodobne, że podejmie kroki eksploracyjne, zamiast zawsze grać zwycięską strategią.
Historia softmax
Pierwsze znane użycie funkcji softmax poprzedza uczenie maszynowe. Funkcja softmax jest w rzeczywistości zapożyczona z fizyki i mechaniki statystycznej, gdzie jest znana jako rozkład Boltzmanna lub rozkład Gibbsa. Został on sformułowany przez austriackiego fizyka i filozofa Ludwiga Boltzmanna w 1868 roku.
Boltzmann badał mechanikę statystyczną gazów w równowadze termicznej. Odkrył, że rozkład Boltzmanna może opisać prawdopodobieństwo znalezienia systemu w pewnym stanie, biorąc pod uwagę energię tego stanu i temperaturę systemu. Jego wersja wzoru była podobna do tej używanej w uczeniu wzmacniającym. Rzeczywiście, parametr τ jest nazywany temperaturą w dziedzinie uczenia wzmacniającego jako hołd dla Boltzmanna.
W 1902 roku amerykański fizyk i chemik Josiah Willard Gibbs spopularyzował rozkład Boltzmanna, kiedy użył go do stworzenia podstaw termodynamiki i jego definicji entropii. Stanowi również podstawę spektroskopii, czyli analizy materiałów poprzez spojrzenie na światło, które pochłaniają i odbijają.
W 1959 roku Robert Duncan Luce zaproponował użycie funkcji softmax do uczenia się wzmocnień w swojej książce Individual Choice Behavior: A Theoretical Analysis. Wreszcie w 1989 roku John S. Bridle zasugerował, że argmax w sieciach neuronowych feedforward powinien być zastąpiony przez softmax, ponieważ „zachowuje porządek rangowy wartości wejściowych i jest różnicowym uogólnieniem operacji 'zwycięzca bierze wszystko’ polegającej na wybieraniu wartości maksymalnej”. W ostatnich latach, gdy sieci neuronowe stały się szeroko stosowane, softmax stała się dobrze znana dzięki tym właściwościom.
.