- Vad är softmax-funktionen?
- Softmax-formeln
- Symboler för softmaxformeln förklaras
- Beräkning av Softmax
- Softmax-funktion vs Sigmoid-funktion
- Beräkning av softmaxfunktion vs sigmoidfunktion
- Softmax-funktionen vs argmax-funktionen
- Beräkning av Softmax-funktionen vs Argmax-funktionen
- Användningar av softmax-funktionen
- Softmax-funktionen i neurala nätverk
- Exempel på beräkning av softmax i ett neuralt nätverk
- Softmax-funktionen i förstärkningsinlärning
- Exempel på beräkning av softmax vid förstärkningsinlärning
- Reinforcement Learning Softmax Formula Symbols Explained
- Softmax historia
Vad är softmax-funktionen?
Softmax-funktionen är en funktion som omvandlar en vektor med K reella värden till en vektor med K reella värden som summerar till 1. Ingångsvärdena kan vara positiva, negativa, noll eller större än ett, men softmax omvandlar dem till värden mellan 0 och 1 så att de kan tolkas som sannolikheter. Om en av inmatningarna är liten eller negativ omvandlar softmax den till en liten sannolikhet, och om en inmatning är stor omvandlar den den till en stor sannolikhet, men den förblir alltid mellan 0 och 1.
Softmax-funktionen kallas ibland softargmax-funktionen eller logistisk regression med flera klasser. Detta beror på att softmax är en generalisering av logistisk regression som kan användas för klassificering av flera klasser, och dess formel är mycket lik den sigmoidfunktion som används för logistisk regression. Softmax-funktionen kan användas i en klassificerare endast när klasserna är ömsesidigt uteslutande.
Många neurala nätverk i flera lager slutar i ett näst sista lager som ger ut realvärdespoäng som inte är bekvämt skalade och som kan vara svåra att arbeta med. Här är softmax mycket användbart eftersom det omvandlar poängen till en normaliserad sannolikhetsfördelning, som kan visas för en användare eller användas som indata till andra system. Av denna anledning är det vanligt att lägga till en softmax-funktion som det sista lagret i det neurala nätverket.
Softmax-formeln
Softmax-formeln är följande:
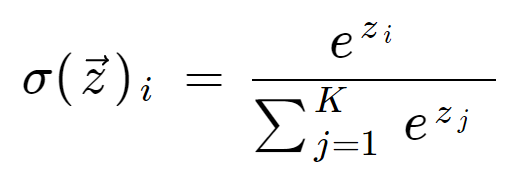
Matematisk definition av softmax-funktionen
där alla zi-värden är elementen i inmatningsvektorn och kan ta vilket verkligt värde som helst. Termen längst ner i formeln är normaliseringstermen som säkerställer att alla utgångsvärden för funktionen summerar till 1 och därmed utgör en giltig sannolikhetsfördelning.
Symboler för softmaxformeln förklaras
| Ingångsvektorn till softmaxfunktionen, som består av (z0, … zK) | ||
| Alla zi-värdena är beståndsdelar i inmatningsvektorn till softmax-funktionen, och de kan anta vilket reellt värde som helst, positivt, noll eller negativt. Ett neuralt nätverk skulle till exempel kunna ha gett ut en vektor som (-0,62, 8,12, 2,53), vilket inte är en giltig sannolikhetsfördelning, varför softmax skulle vara nödvändigt. | ||
 |
Den vanliga exponentialfunktionen tillämpas på varje element i inmatningsvektorn. Detta ger ett positivt värde över 0, som blir mycket litet om inmatningen var negativ och mycket stort om inmatningen var stor. Det är dock fortfarande inte fast inom intervallet (0, 1) vilket är vad som krävs av en sannolikhet. | |
 |
Termen längst ner i formeln är normaliseringstermen. Den säkerställer att alla utgångsvärden av funktionen kommer att summera till 1 och var och en ligga i intervallet (0, 1), vilket utgör en giltig sannolikhetsfördelning. | |
| Antalet klasser i flerklassklassificatorn. |
Beräkning av Softmax
Tänk dig att vi har en matris med tre verkliga värden. Dessa värden kan typiskt sett vara resultatet av en maskininlärningsmodell, t.ex. ett neuralt nätverk. Vi vill omvandla värdena till en sannolikhetsfördelning.

Först kan vi beräkna exponentialen för varje element i inmatningsmatrisen. Detta är termen i den övre halvan av softmaxekvationen.
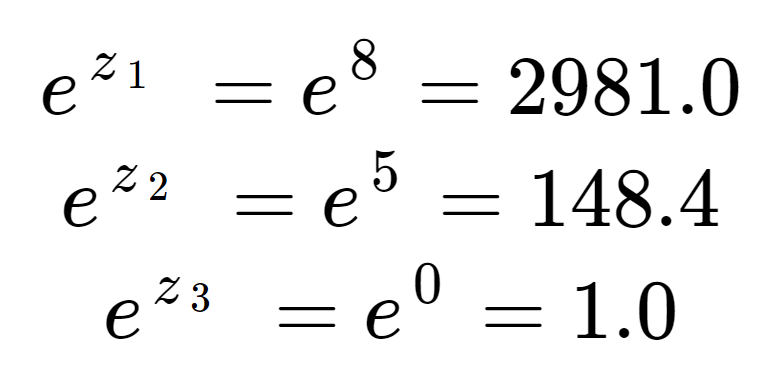
Dessa värden ser inte ut som sannolikheter ännu. Observera att i ingångselementen är 2981 mycket större än 148 på grund av exponentialens effekt, även om 8 bara är lite större än 5. Vi kan få fram normaliseringstermen, den nedre halvan av softmaxekvationen, genom att summera alla tre exponentiella termer:

Vi ser att normaliseringstermen har dominerats av z1.
Slutligt, genom att dividera med normaliseringstermen, får vi softmaxutgången för vart och ett av de tre elementen. Observera att det inte finns ett enda utdatavärde eftersom softmax omvandlar en matris till en matris av samma längd, i detta fall 3.
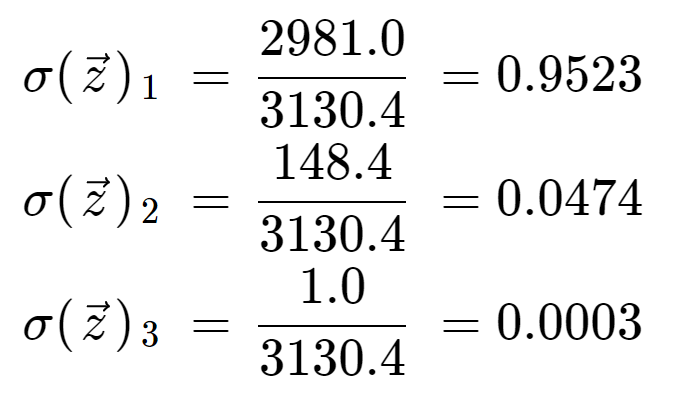
Det är informativt att kontrollera att vi har tre utdatavärden som alla är giltiga sannolikheter, det vill säga att de ligger mellan 0 och 1, och att de summerar till 1.
Bemärk också att på grund av den exponentiella operationen har det första elementet, 8, dominerat softmax-funktionen och pressat ut 5 och 0 till mycket låga sannolikhetsvärden.
Om du använder softmax-funktionen i en maskininlärningsmodell bör du vara försiktig innan du tolkar den som en sann sannolikhet, eftersom den har en tendens att producera värden som ligger mycket nära 0 eller 1. Om ett neuralt nätverk hade utgångsvärden på , som i det här exemplet, skulle softmax-funktionen ha tilldelat den första klassen 95 % sannolikhet, när det i verkligheten kunde ha funnits större osäkerhet i det neurala nätverkets förutsägelser. Detta skulle kunna ge intryck av att det neurala nätverkets förutsägelse hade en hög tillförlitlighet när så inte var fallet.
Softmax-funktion vs Sigmoid-funktion
Som nämnts ovan är softmax-funktionen och Sigmoid-funktionen likartade. Softmax fungerar på en vektor medan sigmoidfunktionen tar en skalär.

I själva verket är sigmoidfunktionen ett specialfall av softmaxfunktionen för en klassificerare med endast två indataklasser. Vi kan visa detta om vi sätter ingångsvektorn till att vara och beräknar det första utgångselementet med den vanliga softmaxformeln:

Dividerar vi toppen och botten med ex får vi:

Detta visar att sigmoidfunktionen blir likvärdig med softmaxfunktionen när vi har två klasser. Det är inte nödvändigt att beräkna den andra vektorkomponenten explicit eftersom när det finns två sannolikheter måste de summera till 1. Så om vi utvecklar en tvåklassig klassificerare med logistisk regression kan vi använda sigmoidfunktionen och behöver inte arbeta med vektorer. Men om vi har mer än två ömsesidigt uteslutande klasser bör softmax användas.
Om det finns mer än två klasser och de inte är ömsesidigt uteslutande (en klassificerare med flera etiketter) kan klassificeraren delas upp i flera binära klassificerare, som var och en använder sin egen sigmoidfunktion.
Beräkning av softmaxfunktion vs sigmoidfunktion
Om vi tar en inmatningsvektor kan vi sätta in denna i både softmax- och sigmoidfunktionen. Eftersom sigmoiden tar ett skalärt värde sätter vi bara in det första elementet i sigmoidfunktionen.

Sigmoidfunktionen ger samma värde som softmax för det första elementet, förutsatt att det andra ingående elementet sätts till 0. Eftersom sigmoiden ger oss en sannolikhet, och de två sannolikheterna måste adderas till 1, är det inte nödvändigt att explicit beräkna ett värde för det andra elementet.
Softmax-funktionen vs argmax-funktionen
Softmax-funktionen utvecklades som ett utjämnat och differentierbart alternativ till argmax-funktionen. På grund av detta kallas softmax-funktionen ibland mer explicit för softargmax-funktionen. Liksom softmax fungerar argmax-funktionen på en vektor och omvandlar varje värde till noll utom maxvärdet, där den returnerar 1.

Det är vanligt att träna en maskininlärningsmodell med hjälp av softmax, men att byta ut softmax-skiktet mot ett argmax-skikt när modellen används för inferens.
Vi måste använda softmax i träningen eftersom softmax är differentierbart och gör det möjligt för oss att optimera en kostnadsfunktion. För inferens behöver vi dock ibland en modell som bara ger ut ett enda förutspått värde snarare än en sannolikhet, och då är argmax mer användbart.
När det finns flera maximivärden är det vanligt att argmax returnerar 1/Nmax, det vill säga en normaliserad bråkdel, så att summan av utgångselementen förblir 1, precis som med softmax. En alternativ definition är att returnera 1 för alla maxvärden, eller endast för det första värdet.
Beräkning av Softmax-funktionen vs Argmax-funktionen
Låt oss återigen föreställa oss ingångsvektorn . Vi beräknar softmax-funktionen på samma sätt som tidigare. Det största värdet är det första elementet, så argmax returnerar 1 för det första elementet och 0 för resten.

Det framgår tydligt av det här exemplet att softmax beter sig som en ”mjuk” approximation av argmax: den returnerar icke-integrala värden mellan 0 och 1 som kan tolkas som sannolikheter. Om vi använder en maskininlärningsmodell för inferens, snarare än att träna den, kanske vi vill ha en heltalsutgång från systemet som representerar ett hårt beslut som vi kommer att fatta med hjälp av modellutgången, t.ex. att behandla en tumör, autentisera en användare eller tilldela ett dokument till ett ämne. Argmax-värdena är lättare att arbeta med i detta avseende och kan användas för att bygga en förvirringsmatris och beräkna precisionen och återkallelsen av en klassificerare.
Användningar av softmax-funktionen
Softmax-funktionen i neurala nätverk
En användning av softmax-funktionen skulle vara i slutet av ett neuralt nätverk. Låt oss betrakta ett konvolutionellt neuralt nätverk som känner igen om en bild är en katt eller en hund. Observera att en bild måste vara antingen en katt eller en hund och kan inte vara både och, därför är de två klasserna ömsesidigt uteslutande. Typiskt sett skulle det sista fullt anslutna lagret i detta nätverk producera värden som inte är normaliserade och inte kan tolkas som sannolikheter. Om vi lägger till ett softmax-skikt till nätverket är det möjligt att översätta siffrorna till en sannolikhetsfördelning. Detta innebär att resultatet kan visas för en användare, till exempel att appen är 95 % säker på att detta är en katt. Det innebär också att resultatet kan matas in i andra maskininlärningsalgoritmer utan att behöva normaliseras, eftersom det garanterat ligger mellan 0 och 1.
Bemärk att om nätverket klassificerar bilder i hundar och katter, och är konfigurerat för att bara ha två utgångsklasser, tvingas det kategorisera varje bild som antingen hund eller katt, även om det inte är någon av dem. Om vi måste tillåta denna möjlighet måste vi konfigurera om det neurala nätverket så att det har en tredje utgång för diverse.
Exempel på beräkning av softmax i ett neuralt nätverk
Softmax är viktigt när vi tränar ett neuralt nätverk. Föreställ dig att vi har ett konvolutionellt neuralt nätverk som lär sig att skilja mellan katter och hundar. Vi ställer in katt som klass 1 och hund som klass 2.
I själva verket, när vi matar in en bild av en katt i vårt nätverk, skulle nätverket ge ut vektorn . När vi matar in en bild av en hund vill vi ha ett utdata .
Den neurala nätverksbildbehandlingen slutar vid det sista fullt anslutna lagret. Detta lager ger ut två poäng för katt och hund, som inte är sannolikheter. Det är vanlig praxis att lägga till ett softmax-skikt i slutet av det neurala nätverket, som omvandlar resultatet till en sannolikhetsfördelning.I början av träningen är vikterna i det neurala nätverket slumpmässigt konfigurerade. Så kattbilden går igenom och omvandlas av bildbehandlingsstegen till poäng . Genom att passera in i softmax-funktionen kan vi få de initiala sannolikheterna

Det är uppenbart att detta inte är önskvärt. Ett perfekt nätverk skulle i detta fall ge ut .

Vi kan formulera en förlustfunktion för vårt nätverk som kvantifierar hur långt nätverkets utdatasannolikheter är från de önskade värdena. Ju mindre förlustfunktionen är, desto närmare är utgångsvektorn den korrekta klassen. Den vanligaste förlustfunktionen i det här fallet är cross-entropy loss som i det här fallet blir:
Då softmax är en kontinuerligt differentierbar funktion är det möjligt att beräkna förlustfunktionens derivata med avseende på varje vikt i nätverket, för varje bild i träningsuppsättningen.
Denna egenskap gör det möjligt för oss att justera nätverkets vikter för att minska förlustfunktionen och få nätverkets utdata att närma sig de önskade värdena och förbättra nätverkets noggrannhet.Efter flera iterationer av träning uppdaterar vi nätverkets vikter. När samma kattbild nu matas in i nätverket ger det fullt anslutna lagret ut en poängvektor på . Genom att sätta detta genom softmax-funktionen igen får vi utdatasannolikheter:

Detta är ett klart bättre resultat och närmare det önskade resultatet på . Om vi räknar om förlusten av korsentropin,

ser vi att förlusten har minskat, vilket tyder på att det neurala nätverket har förbättrats.
Metoden att differentiera förlustfunktionen för att fastställa hur vi ska justera nätets vikter hade inte varit möjlig om vi hade använt argmax-funktionen, eftersom den inte är differentierbar. Egenskapen differentierbarhet gör softmax-funktionen användbar för träning av neurala nätverk.
Softmax-funktionen i förstärkningsinlärning
I förstärkningsinlärning används softmax-funktionen också när en modell måste bestämma sig mellan att vidta den åtgärd som för tillfället är känd för att ha den högsta sannolikheten för en belöning, så kallad
utnyttjande, eller att ta ett utforskande steg, så kallad utforskning.
Exempel på beräkning av softmax vid förstärkningsinlärning
Föreställ dig att vi tränar en förstärkningsinlärningsmodell för att spela poker mot en människa. Vi måste konfigurera en temperatur τ, som anger hur sannolikt det är att systemet ska vidta slumpmässiga utforskande åtgärder. Systemet har för närvarande två alternativ: att spela ett ess eller att spela en kung. Utifrån vad det har lärt sig hittills är det 80 % troligt att spela ett ess är den vinnande strategin i den aktuella situationen. Om man antar att det inte finns några andra möjliga spelalternativ är det 20 % troligt att en kung är den vinnande strategin. Vi har konfigurerat temperaturen τ till 2.
Det förstärkande inlärningssystemet använder softmax-funktionen för att få fram sannolikheten för att spela ett ess respektive en kung. Den modifierade softmaxformeln som används vid förstärkningsinlärning är följande:

Reinforcement Learning Softmax Formula Symbols Explained
| Sannolikheten för att modellen nu kommer att vidta åtgärd a vid tidpunkt t. | |
| Den åtgärd som vi överväger att vidta. Till exempel att spela en kung eller ett ess. | |
 |
Systemets temperatur, konfigurerad som en hyperparameter. |
|
Den nuvarande bästa uppskattningen av sannolikheten för framgång om vi vidtar åtgärd i, utifrån vad modellen har lärt sig hittills. |
Om vi sätter in våra värden i ekvationen får vi:

Detta innebär att även om modellen för närvarande är 80 % säker på att esset är den rätta strategin, är det bara 57 % sannolikt att den kommer att spela det kortet. Detta beror på att vi vid förstärkningsinlärning tilldelar ett värde till utforskning (testning av nya strategier) samt utnyttjande (användning av kända strategier). Om vi väljer att öka temperaturen blir modellen mer ”impulsiv”: den är mer benägen att ta utforskande steg i stället för att alltid spela den vinnande strategin.
Softmax historia
Den första kända användningen av softmax-funktionen föregår maskininlärning. Softmax-funktionen är i själva verket lånad från fysik och statistisk mekanik, där den är känd som Boltzmann-fördelningen eller Gibbs-fördelningen. Den formulerades av den österrikiske fysikern och filosofen Ludwig Boltzmann 1868.
Boltzmann studerade den statistiska mekaniken hos gaser i termisk jämvikt. Han fann att Boltzmannfördelningen kunde beskriva sannolikheten för att finna ett system i ett visst tillstånd, givet tillståndens energi och systemets temperatur. Hans version av formeln liknade den som används vid förstärkningsinlärning. Faktum är att parametern τ kallas temperatur inom området förstärkningsinlärning som en hyllning till Boltzmann.
År 1902 populariserade den amerikanske fysikern och kemisten Josiah Willard Gibbs Boltzmann-fördelningen när han använde den för att lägga grunden för termodynamiken och sin definition av entropi. Den utgör också grunden för spektroskopi, dvs. analys av material genom att titta på det ljus som de absorberar och reflekterar.
1959 föreslog Robert Duncan Luce användningen av softmax-funktionen för förstärkningsinlärning i sin bok Individual Choice Behavior: A Theoretical Analysis. Slutligen föreslog John S. Bridle 1989 att argmax i feedforward neurala nätverk borde ersättas av softmax eftersom den ”bevarar rangordningen av sina ingångsvärden och är en differentierbar generalisering av ’winner-take-all’-operationen att välja det högsta värdet”. Under de senaste åren, då neurala nätverk har blivit allmänt använda, har softmax blivit välkänt tack vare dessa egenskaper.