- Mi a Softmax függvény?
- Softmax formula
- Softmax-képlet szimbólumainak magyarázata
- A Softmax kiszámítása
- Softmax függvény vs. Sigmoid függvény
- Softmax függvény vs. sigmoid függvény számítása
- Softmax függvény vs Argmax függvény
- Softmax függvény számítása vs. Argmax függvény
- A softmax függvény alkalmazásai
- Softmax függvény a neurális hálózatokban
- Példa a softmax kiszámítására egy neurális hálózatban
- Softmax függvény a megerősítéses tanulásban
- Példa a Softmax kiszámítására a megerősítéses tanulásban
- A megerősítéses tanulás softmax képlet szimbólumainak magyarázata
- Softmax története
Mi a Softmax függvény?
A softmax függvény egy olyan függvény, amely egy K valós értékből álló vektort K valós értékből álló vektorrá alakít, amelyek összege 1. A bemeneti értékek lehetnek pozitívak, negatívak, nullák vagy egynél nagyobbak, de a softmax 0 és 1 közötti értékekké alakítja őket, így valószínűségként értelmezhetők. Ha az egyik bemeneti érték kicsi vagy negatív, a softmax kis valószínűséggé alakítja, ha pedig egy bemeneti érték nagy, akkor nagy valószínűséggé alakítja, de mindig 0 és 1 között marad.
A softmax függvényt néha softargmax függvénynek vagy többosztályos logisztikus regressziónak is nevezik. Ennek az az oka, hogy a softmax a logisztikus regresszió általánosítása, amely többosztályos osztályozásra is használható, és képlete nagyon hasonlít a logisztikus regresszióhoz használt szigmoid függvényhez. A softmax függvény csak akkor használható egy osztályozóban, ha az osztályok kölcsönösen kizárják egymást.
Néhány többrétegű neurális hálózat egy utolsó előtti rétegben végződik, amely valós értékű pontszámokat ad ki, amelyek nem kényelmesen skálázhatók, és amelyekkel nehéz lehet dolgozni. Itt a softmax nagyon hasznos, mert a pontszámokat normalizált valószínűségi eloszlássá alakítja, amely megjeleníthető a felhasználó számára, vagy más rendszerek bemeneteként használható. Ezért szokás a neurális hálózat utolsó rétegeként egy softmax függvényt csatolni.
Softmax formula
A softmax formula a következő:
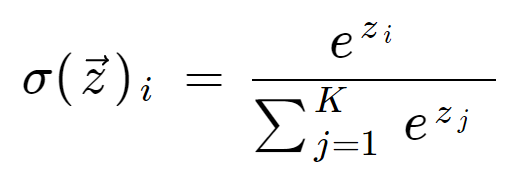
A softmax függvény matematikai definíciója
ahol minden zi érték a bemeneti vektor eleme, és bármilyen valós értéket felvehet. A képlet alján lévő kifejezés a normalizációs kifejezés, amely biztosítja, hogy a függvény minden kimeneti értéke 1-re összegződjön, és így érvényes valószínűségi eloszlást képezzen.
Softmax-képlet szimbólumainak magyarázata
| A softmax-függvény bemeneti vektora, amely a (z0, … zK) | |
| A zi értékek a softmax függvény bemeneti vektorának elemei, és bármilyen valós értéket felvehetnek, pozitív, nulla vagy negatív. Egy neurális hálózat például olyan vektort adhatna ki, mint (-0,62, 8,12, 2,53), ami nem egy érvényes valószínűségi eloszlás, ezért lenne szükség a softmax-ra. | |
 |
A bemeneti vektor minden elemére a szokásos exponenciális függvényt alkalmazzuk. Ez egy 0 feletti pozitív értéket ad, amely nagyon kicsi lesz, ha a bemenet negatív volt, és nagyon nagy, ha a bemenet nagy volt. Ez azonban még mindig nem rögzített a (0, 1) tartományban, ami egy valószínűségtől elvárt. |
 |
A képlet alján lévő kifejezés a normalizációs kifejezés. Ez biztosítja, hogy a függvény összes kimeneti értékeinek összege 1 legyen, és mindegyik a (0, 1) tartományba essen, így egy érvényes valószínűségi eloszlást alkot. |
| A többosztályos osztályozóban az osztályok száma. |
A Softmax kiszámítása
Tegyük fel, hogy van egy három valós értékből álló tömbünk. Ezek az értékek tipikusan egy gépi tanulási modell, például egy neurális hálózat kimenete lehet. Az értékeket valószínűségi eloszlássá akarjuk alakítani.

Először is kiszámíthatjuk a bemeneti tömb minden egyes elemének exponenciálisát. Ez a kifejezés a softmax-egyenlet felső felében található.
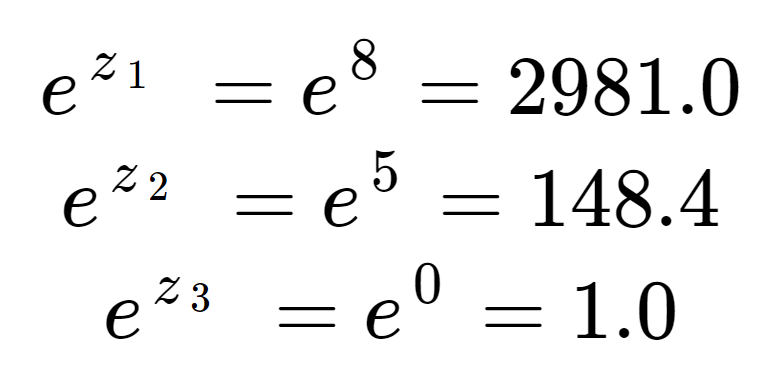
Ezek az értékek még nem valószínűségeknek tűnnek. Vegyük észre, hogy a bemeneti elemekben, bár a 8 csak egy kicsivel nagyobb, mint az 5, a 2981 az exponenciális hatása miatt sokkal nagyobb, mint a 148. A normalizációs kifejezést, a softmax-egyenlet alsó felét a három exponenciális kifejezés összegzésével kapjuk meg:

Láthatjuk, hogy a normalizációs kifejezést a z1 dominálta.
Végül a normalizációs kifejezéssel osztva megkapjuk a softmax kimenetét mindhárom elemre. Vegyük észre, hogy nem egyetlen kimeneti értéket kapunk, mert a softmax egy tömböt egy azonos hosszúságú tömbre, jelen esetben 3-ra alakít át.
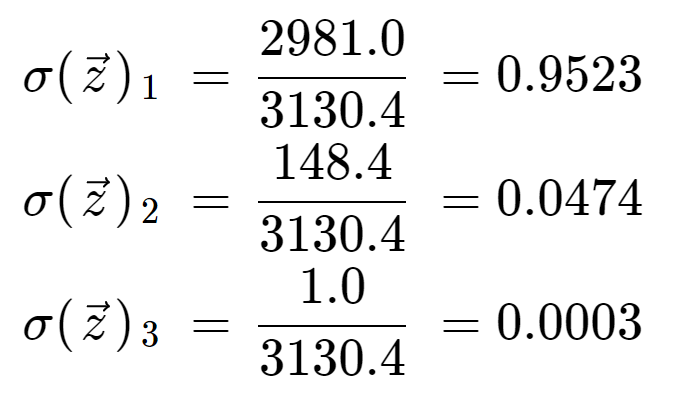
Tanulságos ellenőrizni, hogy három olyan kimeneti értéket kaptunk, amelyek mind érvényes valószínűségek, azaz 0 és 1 között vannak, és összegük 1-re esik.
Megjegyezzük azt is, hogy az exponenciális művelet miatt az első elem, a 8 dominált a softmax függvényben, és nagyon alacsony valószínűségi értékekre szorította ki az 5 és a 0 értékeket.
Ha a softmax függvényt egy gépi tanulási modellben használjuk, óvatosnak kell lennünk, mielőtt valódi valószínűségként értelmezzük, mivel hajlamos nagyon 0-hoz vagy 1-hez közeli értékeket produkálni. Ha egy neurális hálózat kimeneti pontszámai , mint ebben a példában, akkor a softmax függvény 95%-os valószínűséget rendelt volna az első osztályhoz, holott a valóságban nagyobb bizonytalanság lehetett volna a neurális hálózat előrejelzéseiben. Ez azt a benyomást kelthette, hogy a neurális hálózat előrejelzése nagy megbízhatósággal rendelkezett, holott ez nem így volt.
Softmax függvény vs. Sigmoid függvény
Amint már említettük, a softmax függvény és a sigmoid függvény hasonló. A softmax egy vektorral dolgozik, míg a sigmoid egy skalárral.

A sigmoid függvény valójában a softmax függvény speciális esete egy olyan osztályozóhoz, amelynek csak két bemeneti osztálya van. Ezt megmutathatjuk, ha a bemeneti vektort úgy állítjuk be, hogy legyen, és az első kimeneti elemet a szokásos softmax-képlettel számoljuk ki:

A felső és alsó értéket exszel osztva megkapjuk:

Ez azt mutatja, hogy a szigmoidfüggvény ekvivalenssé válik a softmaxfüggvénnyel, ha két osztályunk van. Nem szükséges a második vektorkomponenst explicit módon kiszámítani, mert ha két valószínűség van, akkor azok összegének 1-re kell lennie. így ha kétosztályos osztályozót fejlesztünk logisztikus regresszióval, akkor használhatjuk a szigmoid függvényt, és nem kell vektorokkal dolgoznunk. De ha kettőnél több egymást kölcsönösen kizáró osztályunk van, akkor a softmaxot kell használni.
Ha kettőnél több osztály van, és ezek nem zárják ki egymást (multi-label osztályozó), akkor az osztályozót több bináris osztályozóra lehet bontani, amelyek mindegyike a saját sigmoid függvényét használja.
Softmax függvény vs. sigmoid függvény számítása
Ha veszünk egy bemeneti vektort , akkor ezt mind a softmax, mind a sigmoid függvénybe be tudjuk tenni. Mivel a sigmoid skalár értéket vesz fel, csak az első elemet tesszük a sigmoid függvénybe.

A sigmoid függvény az első elemre ugyanazt az értéket adja, mint a softmax, feltéve, hogy a második bemeneti elemet 0-ra állítjuk. Mivel a szigmoid függvény egy valószínűséget ad, és a két valószínűségnek össze kell adódnia 1-re, a második elemhez nem szükséges explicit módon kiszámítani egy értéket.
Softmax függvény vs Argmax függvény
A softmax függvényt az argmax függvény simított és differenciálható alternatívájaként fejlesztették ki. Emiatt a softmax függvényt néha kifejezőbben softargmax függvénynek nevezik. A softmax-hoz hasonlóan az argmax függvény is egy vektoron dolgozik, és minden értéket nullává alakít, kivéve a maximális értéket, ahol 1-et ad vissza.

A gépi tanulási modellt gyakran a softmax segítségével képezzük, de a softmax réteget argmax rétegre cseréljük, amikor a modellt következtetésre használjuk.
A softmax-ot azért kell használnunk a képzésben, mert a softmax differenciálható, és lehetővé teszi egy költségfüggvény optimalizálását. Következtetéshez azonban néha arra van szükségünk, hogy a modell csak egyetlen előrejelzett értéket adjon ki a valószínűség helyett, ilyenkor az argmax hasznosabb.
Ha több maximális érték van, akkor az argmax általában 1/Nmax-ot, azaz egy normalizált törtet ad vissza, így a kimeneti elemek összege 1 marad, mint a softmax esetében. Egy alternatív definíció szerint az összes maximális értékre vagy csak az első értékre ad vissza 1-et.
Softmax függvény számítása vs. Argmax függvény
Még egyszer képzeljük el a bemeneti vektort . A softmaxot az előzőekhez hasonlóan kiszámítjuk. A legnagyobb érték az első elem, így az argmax az első elemre 1-et, a többi elemre pedig 0-t fog visszaadni.

Ez a példa alapján világos, hogy a softmax úgy viselkedik, mint az argmax “lágy” közelítése: 0 és 1 közötti nem egész értékeket ad vissza, amelyek valószínűségként értelmezhetők. Ha egy gépi tanulási modellt használunk következtetésre, ahelyett, hogy betanítanánk, akkor lehet, hogy egy egészértékű kimenetet szeretnénk a rendszertől, amely egy kemény döntést képvisel, amelyet a modell kimenetével fogunk meghozni, például egy daganat kezelésére, egy felhasználó hitelesítésére vagy egy dokumentum témához rendelésére. Az argmax értékekkel ebben az értelemben könnyebb dolgozni, és felhasználhatók egy zavarmátrix létrehozására és az osztályozó pontosságának és visszahívásának kiszámítására.
A softmax függvény alkalmazásai
Softmax függvény a neurális hálózatokban
A softmax függvény egyik felhasználása egy neurális hálózat végén lenne. Tekintsünk egy konvolúciós neurális hálózatot, amely felismeri, hogy egy kép macska vagy kutya. Vegyük észre, hogy egy képnek vagy macskának vagy kutyának kell lennie, és nem lehet mindkettő, tehát a két osztály kölcsönösen kizárja egymást. Tipikusan ennek a hálózatnak az utolsó, teljesen összekapcsolt rétege olyan értékeket állítana elő, amelyek nem normalizáltak, és nem értelmezhetők valószínűségként. Ha a hálózathoz hozzáadunk egy softmax réteget, akkor a számokat lefordíthatjuk valószínűségi eloszlássá. Ez azt jelenti, hogy a kimenet megjeleníthető a felhasználó számára, például az alkalmazás 95%-ban biztos benne, hogy ez egy macska. Ez azt is jelenti, hogy a kimenet más gépi tanulási algoritmusokba is betáplálható anélkül, hogy normalizálni kellene, mivel garantáltan 0 és 1 között van.
Megjegyezzük, hogy ha a hálózat a képeket kutyákra és macskákra osztályozza, és úgy van beállítva, hogy csak két kimeneti osztálya legyen, akkor kénytelen minden képet kutyának vagy macskának minősíteni, még akkor is, ha az egyik sem az. Ha ezt a lehetőséget is figyelembe kell vennünk, akkor úgy kell átkonfigurálnunk a neurális hálózatot, hogy legyen egy harmadik kimenet a különféle osztályok számára.
Példa a softmax kiszámítására egy neurális hálózatban
A softmax alapvető fontosságú, amikor egy neurális hálózatot képezünk. Képzeljük el, hogy van egy konvolúciós neurális hálózatunk, amely megtanulja megkülönböztetni a macskákat és a kutyákat. A macskát az 1. osztályba, a kutyát pedig a 2. osztályba soroljuk.
Ideális esetben, amikor egy macskáról készült képet adunk be a hálózatunkba, a hálózat a vektort adná ki . Amikor egy kutya képét adjuk be, egy .
A neurális hálózat képfeldolgozása az utolsó teljesen összekapcsolt rétegnél ér véget. Ez a réteg két pontszámot ad ki a macskára és a kutyára, amelyek nem valószínűségek. Szokásos gyakorlat, hogy a neurális hálózat végére egy softmax réteget adunk, amely a kimenetet valószínűségi eloszlássá alakítja.A képzés kezdetén a neurális hálózat súlyai véletlenszerűen vannak beállítva. Így a macskakép átmegy és a képfeldolgozási szakaszok pontszámokká alakítják . A softmax függvénybe lépve a kezdeti valószínűségeket kapjuk

Ez nyilvánvalóan nem kívánatos. Egy tökéletes hálózat ebben az esetben .

Hálózatunk veszteségfüggvényét fogalmazhatjuk meg, amely számszerűsíti, hogy a hálózat kimeneti valószínűségei milyen messze vannak a kívánt értékektől. Minél kisebb a veszteségfüggvény, annál közelebb van a kimeneti vektor a helyes osztályhoz. A leggyakoribb veszteségfüggvény ebben az esetben a kereszt-entrópia veszteség, amely ebben az esetben:
Mivel a softmax egy folytonosan differenciálható függvény, a veszteségfüggvény deriváltját a hálózat minden súlya tekintetében, a tanulóhalmaz minden képére ki lehet számítani.
Ez a tulajdonság lehetővé teszi, hogy a hálózat súlyait úgy állítsuk be, hogy a veszteségfüggvényt csökkentve a hálózat kimenete közelebb kerüljön a kívánt értékekhez, és javuljon a hálózat pontossága.A képzés több iterációja után frissítjük a hálózat súlyait. Most, amikor ugyanazt a macskaképet adjuk be a hálózatba, a teljesen összekapcsolt réteg egy pontszámvektort ad ki . Ha ezt ismét a softmax függvényen keresztülvisszük, a következő kimeneti valószínűségeket kapjuk:

Ez egyértelműen jobb eredmény, és közelebb van a kívánt kimeneti értékhez . Újraszámolva a keresztentrópia veszteséget,

látjuk, hogy a veszteség csökkent, ami azt jelzi, hogy a neurális hálózat javult.
A veszteségfüggvény differenciálásának módszere annak megállapítása érdekében, hogy hogyan kell beállítani a hálózat súlyait, nem lett volna lehetséges, ha az argmax függvényt használjuk, mert az nem differenciálható. A differenciálhatóság tulajdonsága teszi a softmax függvényt hasznossá a neurális hálózatok képzéséhez.
Softmax függvény a megerősítéses tanulásban
A megerősítéses tanulásban a softmax függvényt akkor is használják, amikor a modellnek döntenie kell, hogy az éppen ismert, legnagyobb valószínűséggel jutalomhoz vezető cselekvést hajtja-e végre, amit
kihasználásnak nevezünk, vagy egy felfedező lépést tesz, amit felfedezésnek nevezünk.
Példa a Softmax kiszámítására a megerősítéses tanulásban
Képzeljük el, hogy egy megerősítéses tanuló modellt képezünk ki arra, hogy pókerezzünk egy ember ellen. Be kell állítanunk egy τ hőmérsékletet, amely meghatározza, hogy a rendszer milyen valószínűséggel végezzen véletlenszerű felfedező akciókat. A rendszernek jelenleg két lehetősége van: egy ász vagy egy király kijátszása. Az eddig tanultak alapján az ász kijátszása 80%-os valószínűséggel a nyerő stratégia a jelenlegi helyzetben. Feltételezve, hogy nincs más lehetséges játék, akkor a király kijátszása 20%-os valószínűséggel a nyerő stratégia. A τ hőmérsékletet 2-re állítottuk be.
A megerősített tanulási rendszer a softmax függvényt használja az ász és a király kijátszásának valószínűségére. A megerősítéses tanulásban használt módosított softmax képlet a következő:

A megerősítéses tanulás softmax képlet szimbólumainak magyarázata
| A valószínűsége annak, hogy a modell most a cselekvést fogja végrehajtani t időpontban. | |
| A cselekvés, amelynek végrehajtását fontolgatjuk. Például, hogy királyt vagy ászt játszunk. | |
 |
A rendszer hőmérséklete, hiperparaméterként beállítva. |
|
A siker valószínűségének jelenlegi legjobb becslése, ha i akciót hajtunk végre, abból, amit a modell eddig megtanult. |
Az értékeinket az egyenletbe helyezve megkapjuk:

Ez azt jelenti, hogy bár a modell jelenleg 80%-ban biztos abban, hogy az ász a helyes stratégia, csak 57%-os valószínűséggel játssza ki ezt a lapot. Ennek az az oka, hogy a megerősítéses tanulásban a felfedezésnek (új stratégiák kipróbálása) és a kihasználásnak (ismert stratégiák használata) egyaránt értéket tulajdonítunk. Ha úgy döntünk, hogy növeljük a hőmérsékletet, a modell “impulzívabbá” válik: nagyobb valószínűséggel tesz felfedező lépéseket ahelyett, hogy mindig a nyerő stratégiát játszaná ki.
Softmax története
A softmax függvény első ismert használata megelőzte a gépi tanulást. A softmax függvény valójában a fizikából és a statisztikai mechanikából származik, ahol Boltzmann-eloszlás vagy Gibbs-eloszlás néven ismert. Ezt Ludwig Boltzmann osztrák fizikus és filozófus fogalmazta meg 1868-ban.
Boltzmann a termikus egyensúlyban lévő gázok statisztikai mechanikáját tanulmányozta. Rájött, hogy a Boltzmann-eloszlással leírható annak a valószínűsége, hogy egy rendszer egy bizonyos állapotban van, adott az adott állapot energiája és a rendszer hőmérséklete. Az ő változata a képletnek hasonló volt, mint amit a megerősítéses tanulásban használnak. A τ paramétert a megerősítéses tanulás területén valóban hőmérsékletnek nevezik Boltzmann tiszteletére.
1902-ben Josiah Willard Gibbs amerikai fizikus és kémikus népszerűsítette a Boltzmann-eloszlást, amikor a termodinamika megalapozására és az entrópia definíciójának megalkotására használta. Ez képezi a spektroszkópia alapját is, vagyis az anyagok elemzését az általuk elnyelt és visszavert fény vizsgálatával.
1959-ben Robert Duncan Luce az Individual Choice Behavior című könyvében javasolta a softmax függvény használatát a megerősítéses tanuláshoz: A Theoretical Analysis című könyvében. Végül 1989-ben John S. Bridle azt javasolta, hogy a feedforward neurális hálózatokban az argmax-ot váltsa fel a softmax, mert “megőrzi a bemeneti értékek rangsorát, és differenciálható általánosítása a maximális értéket kiválasztó “győztes mindent visz” műveletnek”. Az elmúlt években, ahogy a neurális hálózatok széles körben elterjedtek, a softmax ezeknek a tulajdonságoknak köszönhetően vált ismertté.