Nos efforts en matière de connectivité se concentrent sur l’élargissement de l’accès à Internet et de son adoption dans le monde entier. Cela inclut notre travail sur des technologies comme Terragraph, notre collaboration avec les opérateurs mobiles sur les efforts visant à étendre l’accès rural, notre travail dans le cadre du projet Telecom Infra, et des programmes comme Free Basics. Tout en continuant à travailler sur Free Basics, nous avons écouté les commentaires et les recommandations de la société civile et des autres parties prenantes. Nous avons développé Discover spécifiquement pour répondre et intégrer ces recommandations dans un nouveau produit qui soutient la connectivité. Aujourd’hui, Facebook Connectivity et nos partenaires de Bitel, Claro, Entel et Movistar lancent un essai de Discover au Pérou.
Fournir ce service tout en gardant les gens à l’abri des risques de sécurité potentiels était un défi technique difficile. Nous voulions développer un modèle qui nous permettrait de présenter en toute sécurité les pages web de tous les domaines disponibles, y compris leurs ressources (scripts, médias, feuilles de style, etc.). Ci-dessous, nous parcourons le modèle que nous avons construit, les choix d’architecture uniques que nous avons faits en cours de route, et les mesures que nous avons prises pour atténuer les risques.
- Où nous avons commencé
- Architecture préliminaire
- Conception du domaine
- Cookies
- Améliorer ce que nous avions construit
- Améliorations de l’architecture dans Discover
- JavaScript et fixation des cookies
- Solution à deux cadres
- Cadre intérieur
- Cadre extérieur
- Interaction avec la page
- Fixation asynchrone des cookies
- Clickjacking
- Phishing
- Client-side cookies
- Protocole bootstrap
- Avec le protocole localStorage
- Without localStorage protocol
Où nous avons commencé
Pour Free Basics, notre défi était de trouver un moyen de fournir un service gratuit aux personnes qui utilisent le web mobile, même sur des téléphones de fonction sans support d’applications tierces. Les partenaires des opérateurs mobiles pouvaient fournir le service, mais les contraintes liées aux équipements de réseau et de passerelle faisaient que seul le trafic vers certaines destinations (généralement des plages d’adresses IP ou une liste de noms de domaine) pouvait être rendu gratuit. Avec plus de 100 partenaires dans le monde et le temps et la difficulté qu’implique la modification des configurations des équipements de réseau des opérateurs, nous avons réalisé que nous devions trouver une nouvelle approche.
Cette nouvelle approche nous a demandé de construire d’abord un service proxy basé sur le web où l’opérateur pouvait rendre le service disponible gratuitement à un seul domaine : freebasics.com. À partir de là, nous allions chercher les pages web au nom de l’utilisateur et les délivrer à son appareil. Même sur les navigateurs modernes, les architectures proxy basées sur le web posent quelques problèmes. Sur le web, les clients sont en mesure d’évaluer les en-têtes HTTP de sécurité comme le partage des ressources entre origines (CORS) et la politique de sécurité du contenu (CSP) et d’utiliser les cookies directement à partir du site. Mais dans une configuration de serveur proxy, le client interagit avec le proxy, et le proxy agit comme un client du site. Le fait d’envoyer des sites Web tiers par le biais d’un espace de noms unique viole certaines hypothèses concernant la façon dont les cookies sont stockés, le degré d’accès des scripts à la lecture ou à la modification du contenu, et la façon dont CORS et CSP sont évalués.
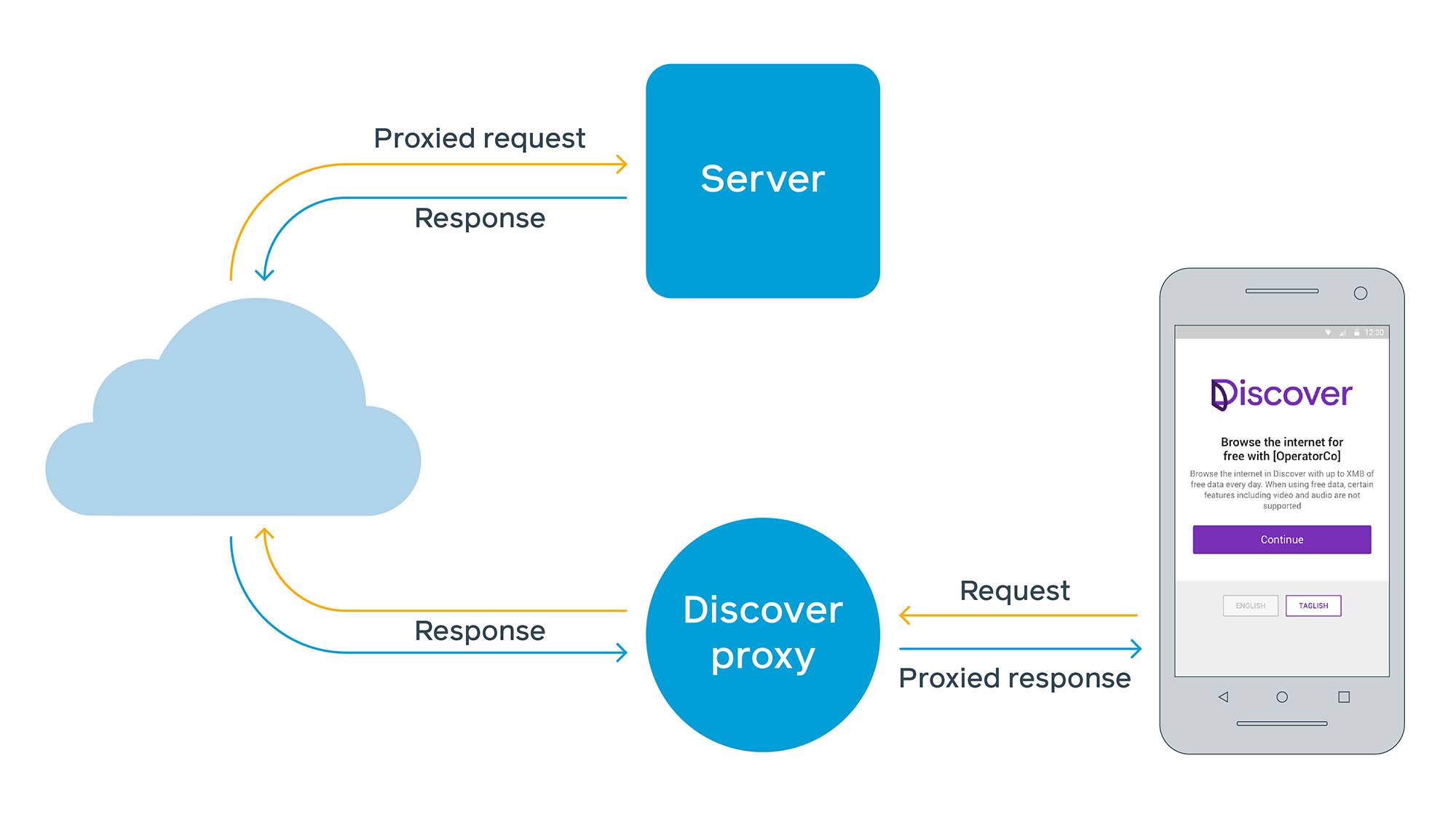
Pour répondre à ces préoccupations, nous avons initialement imposé quelques limitations simples, notamment les sites qui pouvaient être visités avec Free Basics et l’impossibilité d’exécuter des scripts. Ce dernier point est devenu plus problématique au fil du temps, car de nombreux sites Web, y compris les sites mobiles, ont commencé à s’appuyer sur JavaScript pour des fonctionnalités critiques, notamment le rendu du contenu.
Architecture préliminaire
Conception du domaine
Pour tenir compte de la fonctionnalité limitée de nombreuses passerelles d’opérateurs mobiles, nous avons envisagé des architectures alternatives, notamment :
- Une solution coopérative où les sites Web peuvent allouer un sous-domaine (par ex,
free.example.com) et le résoudre dans notre espace IP pour que les opérateurs le rendent gratuit à l’utilisateur.
Cette solution avait des avantages:
- Elle permettait une communication directe de bout en bout entre le client et le serveur.
- Elle nécessitait une intervention minimale du côté du proxy.
Cependant, il présentait aussi quelques inconvénients :
- Les sites devaient opter pour ce schéma, ce qui entraînait des coûts d’ingénierie supplémentaires pour les propriétaires de sites.
- Les navigateurs devaient demander un domaine spécifique par le biais de l’indication du nom du serveur (SNI), afin que le proxy sache où se connecter. Cependant, le support de SNI n’est pas universel, ce qui rendait cette solution moins viable.
- Si les abonnés naviguaient accidentellement vers
example.comdirectement, plutôt que vers le sous-domainefree.example.com, ils encourraient des frais – et ne seraient pas nécessairement redirigés vers le sous-domaine, à moins que l’opérateur n’ait mis en place une logique supplémentaire.
- Encapsulation IPv4-en-IPv6, où nous pouvons encapsuler tout l’espace IPv4 dans un seul sous-réseau IPv6 de données libres. Un résolveur DNS personnalisé résout alors IPv4 de manière récursive et répond avec des réponses IPv6 encapsulées.
Cette solution avait aussi des avantages:
- Elle ne nécessitait pas la coopération du propriétaire du site web.
- Il n’y avait pas besoin de SNI pour résoudre l’IP distante.
Et contre:
- Les navigateurs verraient le domaine
www.example.com.freebasics.com, mais le certificatwww.example.comentraînerait une erreur. - Seulement quelques passerelles de transporteurs supportaient IPv6 de cette façon.
- Encore moins de périphériques supportaient IPv6, en particulier les anciennes versions du système d’exploitation.
Aucune de ces solutions n’était viable. En fin de compte, nous avons décidé que la meilleure architecture possible serait le collapsing d’origine, où notre proxy s’exécute dans un seul espace de noms de domaine collapsé d’origine sous freebasics.com. Les opérateurs peuvent alors autoriser plus facilement le trafic de liste vers cette destination et garder leurs configurations simples. Chaque origine tierce est codée dans un sous-domaine, de sorte que nous pouvons garantir que la résolution de nom dirigera toujours le trafic vers une IP libre.
Par exemple:
https://example.com/path/?query=value#anchor
Est réécrit en:
https://https-example-com.0.freebasics.com/path/?query=value#anchor
Il existe une logique étendue côté serveur pour s’assurer que les liens et les hrefs sont correctement transformés. Cette même logique permet de s’assurer que même les sites en HTTP seulement sont livrés de manière sécurisée en HTTPS sur Free Basics entre le client et le proxy. Ce schéma de réécriture d’URL nous permet d’utiliser un seul espace de noms et un seul certificat TLS, plutôt que de nécessiter un certificat distinct pour chaque sous-domaine sur Internet.
Toutes les origines internet deviennent des frères et sœurs sous 0.freebasics.com, ce qui soulève certaines considérations de sécurité. Nous n’avons pas été en mesure de tirer parti de l’ajout du domaine à la liste des suffixes publics, car nous aurions dû émettre un cookie différent pour chaque origine, ce qui aurait fini par dépasser les limites de cookies des navigateurs.
Cookies
Contrairement aux clients web, qui peuvent utiliser les cookies directement à partir du site, le service proxy nécessite une configuration différente. Free Basics stocke les cookies des utilisateurs côté serveur pour plusieurs raisons :
- Les navigateurs mobiles de niveau inférieur ont souvent un support limité des cookies. Si nous émettons ne serait-ce qu’un seul cookie par site sous notre domaine proxy, nous pourrions être limités à la définition de quelques dizaines de cookies. Si Free Basics devait définir des cookies côté client pour chaque site sous
0.freebasics.com, les navigateurs plus anciens atteindraient rapidement les limites de stockage des cookies locaux – et même les navigateurs modernes atteindraient une limite par domaine. - Les contraintes d’espace de noms de domaine que nous devions mettre en œuvre ont également empêché l’utilisation de cookies frères et sœurs et hiérarchiques. Par exemple, un cookie défini sur n’importe quel sous-domaine à
.example.comserait normalement lisible sur n’importe quel autre sous-domaine. En d’autres termes, sia.example.complace un cookie sur.example.com, alorsb.example.comdevrait être capable de le lire. Dans le cas de Free Basics,a-example-com.0.freebasics.complacerait un cookie surexample.com.0.freebasics.com, ce qui n’est pas autorisé par la norme. Puisque cela ne fonctionne pas, d’autres origines, commeb-example-com.0.freebasics.com, ne seraient pas en mesure d’accéder aux cookies définis pour leur domaine parent.
Pour permettre au service proxy d’accéder à ce pot de cookies côté serveur, Free Basics exploite deux cookies côté client :
- Le cookie
datr, un identifiant de navigateur utilisé à des fins d’intégrité du site. - Le
ick(clé de cookie internet), qui contient une clé cryptographique utilisée pour chiffrer le pot de cookies côté serveur. Comme cette clé n’est stockée que du côté du client, le pot de cookies côté serveur ne peut pas être déchiffré par Free Basics lorsque l’utilisateur n’utilise pas le service.
Pour aider à protéger la confidentialité et la sécurité des utilisateurs lors du stockage de leurs cookies dans un pot de cookies côté serveur, nous nous assurons que :
- Les cookies côté serveur sont chiffrés avec une
ickqui n’est conservée que sur le client. - Lorsque le client fournit le
ick, il est oublié par le serveur à chaque requête sans jamais être enregistré. - Nous marquons les deux cookies côté client comme
SecureetHttpOnly. - Nous hachons l’index d’un cookie en utilisant la clé côté client afin que le cookie ne soit pas traçable jusqu’à l’utilisateur lorsque la clé n’est pas présente.
Autoriser l’exécution de scripts risque la fixation des cookies côté serveur. Pour éviter cela, nous excluons l’utilisation de JavaScript de Free Basics. En outre, même si n’importe quel site web peut faire partie de Free Basics, nous examinons chaque site individuellement pour détecter les vecteurs d’abus potentiels, quel que soit le contenu.
Améliorer ce que nous avions construit
Pour soutenir un modèle desservant n’importe quel site web, avec la possibilité d’exécuter des scripts de manière plus sécurisée, nous avons dû repenser considérablement notre architecture pour empêcher les menaces, telles que les scripts pouvant soit lire soit fixer les cookies de l’utilisateur. JavaScript est extrêmement difficile à analyser et à empêcher l’exécution d’un code involontaire.
À titre d’exemple, voici quelques façons dont un attaquant pourrait injecter du code que nous devrions être en mesure de filtrer :
setTimeout();location = ' javascript:alert(1) <!--';location = 'javascript\n:alert(1) <!--';location = '\x01javascript:alert(1) <!--';var location = 'javascript:alert(1)';for(location in {'javascript:alert(1)':0}); = 'javascript:alert(1)';location.totally_not_assign=location.assign;location.totally_not_assign('javascript:alert(1)');location] = 'javascript:alert(1)';Reflect.set(location, 'href', 'javascript:alert(1)')new Proxy(location, {}).href = 'javascript:alert(1)'Object.assign(window, {location: 'javascript:alert(1)'});Object.assign(location, {href: 'javascript:alert(1)'});location.hash = '#%0a alert(1)';location.protocol = 'javascript:';Le modèle que nous avons imaginé a étendu la conception de Free Basics, mais il protège également le cookie qui stocke la clé de chiffrement d’être écrasé par des scripts. Nous utilisons un cadre extérieur auquel nous faisons confiance pour attester que le cadre intérieur, qui présente du contenu tiers, n’est pas altéré. La section suivante montre en détail comment nous atténuons la fixation de session et d’autres attaques, telles que le phishing et le clickjacking. Nous exposons une méthode pour servir en toute sécurité du contenu tiers tout en permettant l’exécution de JavaScript.
Améliorations de l’architecture dans Discover
Les références au domaine à ce stade changeront pour notre nouveau domaine, un discoverapp.com à l’origine effondrée similaire.
En autorisant JavaScript à partir de sites tiers, nous avons dû reconnaître que cela permet certains vecteurs auxquels nous devions nous préparer, car les scripts peuvent modifier et réécrire les liens, accéder à n’importe quelle partie du DOM et, dans le pire des cas, fixer les cookies côté client.
La solution que nous avons trouvée devait s’attaquer à la fixation des cookies, donc au lieu d’essayer d’analyser et de bloquer certains appels de script, nous avons décidé de le détecter au moment où il se produit et de le rendre inutile. Ceci est réalisé de la manière suivante :
- Lors de l’inscription, nous générons un nouveau
ickaléatoire sécurisé. - Nous envoyons
ickau navigateur comme un cookieHttpOnly. - Nous effectuons ensuite un HMAC d’une valeur appelée
icktà partir d’un condensé deicketdatr(pour éviter la fixation pour les deux) et nous stockons une copie deicktsur le client, dans un emplacement danslocalStorageauquel un attaquant potentiel ne peut pas écrire. L’emplacement que nous utilisons esthttps://www.0.discoverapp.com, qui ne sert jamais de contenu tiers. Puisque cette origine est frère et sœur de toutes les origines tierces, l’abaissement de domaine ou tout autre type de modification de domaine ne peut pas se produire, et l’origine est jugée de confiance. - Nous intégrons
ickt, dérivé du cookieickvu dans la requête, à l’intérieur du HTML dans chaque réponse de proxy tiers. - Lorsque la page se charge, nous comparons le
icktintégré avec leicktde confiance en utilisantwindow.postMessage(), et nous invalidons la session s’il y a un désaccord en supprimant les cookiesdatretick. - Nous empêchons l’interaction de l’utilisateur avec la page jusqu’à ce que ce processus soit terminé.
Comme protection supplémentaire, nous définissons un nouveau cookie datr si nous détectons plusieurs cookies au même endroit, en intégrant un horodatage pour pouvoir toujours utiliser le plus récent.
Solution à deux cadres
Pour la validation, nous avons besoin d’un moyen pour une page tierce d’interroger la valeur ickt et de la valider. Nous faisons cela en intégrant le site tiers dans un <iframe> dans une page à l’origine sécurisée et en injectant un morceau de JavaScript dans le site tiers. Nous construisons un cadre extérieur sécurisé et un cadre intérieur tiers.
Cadre intérieur
Dans le cadre intérieur, nous injectons un script dans chaque page proxiée que nous servons. Nous injectons également avec lui la valeur ickt calculée à partir du ick vu dans la requête. Le comportement du cadre interne est le suivant:
- Vérifier avec le cadre externe:
-
postMessageau sommet avecicktintégré dans la page. - Attendre.
- Si le script obtient un accusé de réception de l’origine sécurisée, nous laissons l’utilisateur interagir avec la page.
- Si le script attend trop longtemps ou obtient une réponse d’une origine inattendue, nous faisons naviguer le cadre vers un écran d’erreur sans contenu tiers (notre page « Oops »), car il est possible que le cadre extérieur ne soit pas là ou soit différent de ce que le cadre intérieur attend.
-
- Vérifier avec
parent:-
postMessageàparent. - Attendre.
- Si le script obtient une réponse avec
source===parentet une origine sous.0.discoverapp.com, il poursuivra. - Si le script attend trop longtemps, ou obtient une réponse d’une origine inattendue, nous naviguerons vers la page « Oups ».
-
Quelques notes sur le cadre intérieur :
- Même s’il est contourné, les attaquants potentiels ne pourraient se fixer que sur une origine sur laquelle ils peuvent obtenir l’exécution de code, rendant les vecteurs de fixation des cookies redondants.
- Nous supposons qu’une origine bénigne ne contournera pas délibérément le protocole de messagerie inner-outer.
Cadre extérieur
Le cadre extérieur est là pour attester que le cadre intérieur est cohérent :
- Nous nous assurons que le cadre extérieur est toujours le cadre supérieur avec JavaScript et
X-Frame-Options: DENY. - Attendez
postMessage. - Si le cadre extérieur reçoit un message :
- Est-il issu d’une origine du cadre intérieur ?
- Si oui, signale-t-il la valeur
icktcorrecte ?- Si oui, envoyez un message d’accusé de réception.
- Si non, supprimez la session, supprimez tous les cookies et naviguez vers une origine sûre.
- Si le cadre extérieur ne reçoit pas de message pendant quelques secondes ou si le sous-cadre n’est pas le cadre intérieur le plus haut, on supprime l’emplacement de la barre d’adresse du cadre sécurisé.
Interaction avec la page
Pour éviter les conditions de course où une personne pourrait entrer un mot de passe sous un témoin fixé avant que le cadre intérieur ait terminé la vérification, il est important d’empêcher les gens d’interagir avec la page avant que la séquence de vérification du cadre intérieur ne soit terminée.
Pour empêcher cela, le serveur ajoute style="display:none" à l’élément <html> de chaque page. Le cadre interne le supprimera lorsqu’il obtiendra la confirmation du cadre externe.
Le code JavaScript est toujours autorisé à s’exécuter, et les ressources sont toujours récupérées. Mais tant que la personne n’a pas saisi de données dans la page, le navigateur ne fait rien qu’un attaquant potentiel n’aurait pas pu faire simplement en visitant le site – à moins que le site ne soit déjà vulnérable à la contrefaçon de requête intersite (CSRF).
En choisissant d’opter pour cette solution, nous avons ensuite dû résoudre d’autres résultats possibles, en particulier :
- Fixation asynchrone des cookies.
- Clickjacking dû au framing.
- Phishing se faisant passer pour le domaine Discover.
Jusqu’à présent, les protections que nous avons mises en place ont pris en compte les fixations synchrones, mais elles peuvent également se produire de manière asynchrone. Pour éviter cela, nous utilisons une méthode classique de prévention CSRF. Nous demandons aux POSTs de porter un paramètre de requête avec le datr vu lors du chargement de la page. Nous comparons ensuite le paramètre de requête avec le cookie datr vu dans la requête. S’ils ne correspondent pas, nous ne satisfaisons pas la demande.
Pour éviter la fuite du datr, nous intégrons une version cryptée du datr à l’intérieur du cadre interne et nous nous assurons que ce paramètre de requête est ajouté à chaque objet <form> et XHR. Comme la page ne peut pas dériver le jeton datr par elle-même, le datr ajouté est celui vu à ce moment-là.
Pour les requêtes anonymes, nous exigeons qu’elles aient également le paramètre de requête datr. L’anonymat est préservé car nous ne le divulguons pas au site tiers – le cookie ick est absent, nous ne pouvons donc pas utiliser la boîte à cookies. Cependant, dans ce cas, nous ne sommes pas en mesure de valider par rapport au cookie datr, donc les POST anonymes peuvent être effectués sous des sessions fixes. Mais comme ils sont anonymes et dépourvus du ick, aucune information sensible ne peut fuir.
Clickjacking
Lorsqu’un site envoie X-Frame-Options: DENY, il ne se charge pas dans un cadre intérieur. Cet en-tête est utilisé par les sites Web pour éviter de s’exposer à certains types d’attaques, comme le clickjacking. Nous supprimons cet en-tête de la réponse HTTP mais demandons au cadre intérieur de vérifier que parent est le cadre de la fenêtre top en utilisant postMessage. Si la validation échoue, nous faisons naviguer l’utilisateur vers la page « Oops ».
Phishing
La « barre d’adresse » que nous fournissons dans le cadre sécurisé est utilisée pour exposer l’origine du cadre interne le plus haut à l’utilisateur. Cependant, elle peut être copiée par des sites de phishing qui se font passer pour Discover. Nous empêchons les liens malveillants de s’éloigner de Discover en empêchant la navigation supérieure à l’aide de <iframe sandbox>. Le cadre extérieur ne peut être échappé qu’en naviguant directement vers un autre site.
Le document.cookie permet à JavaScript de lire et de modifier les cookies qui ne sont pas marqués HttpOnly. Prendre en charge cela de manière sécurisée est un défi dans un système qui maintient les cookies sur le serveur.
Accéder aux cookies : Lorsqu’une demande est reçue, le proxy énumérera tous les cookies qui sont visibles pour cette origine. Il joindra ensuite une charge utile JSON à la page de réponse. Du code côté client est injecté pour shim document.cookie et rendre ces cookies visibles pour les autres scripts, comme s’il s’agissait de véritables cookies côté client.
Modification des cookies : Si les scripts sont autorisés à définir arbitrairement des cookies que le serveur accepte ensuite, cela pourrait conduire à une fixation, où l’origine evil.com pourrait définir un cookie sensible sur example.com.
La confiance dans les capacités CORS du navigateur ne serait pas suffisante dans ce cas – l’origine a.example.com essayant de définir un cookie sur example.com sera bloquée par le navigateur, puisque ces origines sont frères et sœurs et non hiérarchiques.
Même ainsi, lorsque le serveur reçoit un nouveau cookie défini par le client, il ne peut pas faire respecter de manière sécurisée si le domaine cible est autorisé ; l’origine de l’écrivain n’est connue que sur le client et n’est pas toujours envoyée au serveur d’une manière à laquelle nous pouvons faire confiance.
Pour forcer le client à prouver qu’il est éligible pour définir des cookies sur un domaine spécifique, le serveur enverra, en plus de la charge utile JSON, une liste de jetons cryptographiques pour chacune des origines auxquelles l’origine requérante est autorisée à définir des cookies. Ces jetons sont salés avec la valeur ick, ils ne peuvent donc pas être transférés entre les utilisateurs.
Le shim côté client pour document.cookie se charge de résoudre et d’intégrer le jeton dans le texte réel du cookie qui est envoyé au proxy. Le proxy peut alors vérifier que l’origine d’écriture possède bien le jeton pour écrire dans le domaine cible du cookie, et le stocke dans la jarre à cookies côté serveur, l’envoyant à nouveau au client la prochaine fois que la page est demandée.
Protocole bootstrap
Le modèle contient trois types d’origine : origine portail (Discover portal, etc.), origine sécurisée (cadre extérieur), et origine de réécriture (cadre intérieur). Chacun a un besoin différent:
- L’origine portail nécessite
datr. - L’origine sécurisée nécessite
ickt. - L’origine de réécriture nécessite
datretick.
Avec le protocole localStorage
Voici une représentation du processus d’amorçage pour la plupart des navigateurs mobiles modernes:
Il est important de noter que pour éviter la réflexion, le point d’extrémité d’amorçage à l’origine sécurisée émet toujours un nouveau ick et ickt ; ick ne dépend jamais de l’entrée de l’utilisateur. Notez que parce que nous définissons domain=.discoverapp.com sur ick et datr, ils sont disponibles dans tous les types d’origine, et ickt n’est disponible que sur l’origine sécurisée.
Without localStorage protocol
Parce que certains navigateurs, tels que Opera Mini (populaire dans de nombreux pays où Discover opère), ne supportent pas localStorage, nous sommes incapables de stocker les valeurs ick et ickt. Cela signifie que nous devons utiliser un protocole différent:
Nous avons décidé de séparer l’origine de réécriture de l’origine sécurisée afin qu’elles ne partagent pas le même suffixe d’hôte selon la liste de suffixes publics. Nous utilisons www.0.discoverapp.com pour stocker la copie sécurisée de ickt (comme un cookie), et déplaçons toutes les origines tierces sous 0.i.org. Dans un navigateur qui se comporte bien, la définition d’un cookie sur l’origine sécurisée la rendra inaccessible à toutes les origines de réécriture.
Puisque les origines sont maintenant séparées, notre processus d’amorçage devient un processus en deux étapes. Avant, nous pouvions définir ick dans la même requête que nous provisionnons localStorage avec ickt. Maintenant, nous devons amorcer deux origines, dans des demandes séparées, sans ouvrir les vecteurs de fixation ick.
Nous résolvons cela en amorçant d’abord l’origine sécurisée avec le cookie ickt et en donnant à l’utilisateur une version chiffrée de ick, avec une clé connue uniquement du proxy. Le texte chiffré ick est accompagné d’un nonce qui peut être utilisé pour déchiffrer ce ick particulier dans l’origine de réécriture et définir un cookie, mais seulement une fois.
Un attaquant pourrait choisir soit :
- Utiliser le nonce pour révéler le cookie
ick. - Le passer à l’utilisateur pour fixer sa valeur.
Dans les deux cas, l’attaquant ne peut pas simultanément connaître et imposer une valeur ick particulière à un utilisateur. Le processus synchronise également datr entre les origines.
Cette architecture a été soumise à d’importants tests de sécurité internes et externes. Nous pensons avoir développé une conception suffisamment robuste pour résister aux types d’attaques d’applications web que nous voyons dans la nature et fournir en toute sécurité une connectivité durable pour les opérateurs mobiles. Après le lancement de Discover au Pérou, nous prévoyons de procéder à d’autres essais Discover avec des opérateurs partenaires dans un certain nombre d’autres pays où nous avons testé les fonctionnalités du produit en version bêta, notamment en Thaïlande, aux Philippines et en Irak. Nous prévoyons que Discover sera en direct dans ces pays supplémentaires dans les semaines à venir, et nous explorerons d’autres essais où les opérateurs partenaires veulent participer.
Nous tenons à remercier Berk Demir pour son aide sur ce travail.
Dans un effort pour être plus inclusif dans notre langage, nous avons modifié ce post pour remplacer « whitelist » par « allowlist ».