Vi känner till Node.js för dess blixtsnabba prestanda. Men precis som med alla andra språk kan du skriva Node.js-kod som fungerar sämre för dina användare än du skulle vilja. För att motverka detta behöver vi adekvat prestandatestning. Idag kommer vi att täcka just detta med en djupgående titt på hur du sätter upp och kör ett prestandatest och analyserar resultaten så att du kan göra blixtsnabba Node.js-program.
Det bästa sättet att förstå hur du prestandatestar ditt program är att gå igenom ett exempel.
Du kan använda Node.js för många syften: skriva skript för att köra uppgifter, köra en webbserver eller servera statiska filer, till exempel en webbplats. Idag går vi igenom stegen för att testa ett Node.js HTTP web API. Men om du bygger något annat i Node behöver du inte oroa dig – många av principerna kommer att vara likartade.
- Den unika karaktären hos Node.js prestanda
- Händelseslingan
- Node.js prestanda och händelseslingan
- Steg 1: Välja verktyg för prestandatest av Node.js
- Steg 2: Skapa en Node.js prestandatestprofil
- Att utnyttja flera testprofiler
- Replikering av storskaliga distribuerade system
- Steg 3: Ställ in din observerbarhet/övervakning
- Att komma igång med en APM
- Verktyg som är skräddarsydda för Node.js
- Steg 4: Skapa infrastruktur för prestandatest av Node.js
- Steg 5: Kör dina tester!
- Nu har du blixtsnabba Node.js
Den unika karaktären hos Node.js prestanda
Innan vi börjar ska vi ta en snabb titt på en av de mer unika egenskaperna hos Node.js prestanda. Vi kommer att behöva ha kunskap om dessa egenskaper senare när vi kör våra prestandatester.
Vad pratar jag om?
Det stora övervägandet för Node.js-program är deras enkeltrådade, kör-till-avslut-beteende – underlättat av det som kallas händelseslingan. Nu vet jag vad du tänker: det är mycket. Så låt oss dela upp detta lite så att vi förstår vad dessa betyder.
Låt oss börja med single threading. Trådning, som koncept, möjliggör samtidig bearbetning inom ett program. Node.js har inte denna möjlighet, åtminstone inte i traditionell mening. För att skriva program som utför flera uppgifter samtidigt har vi istället den asynkrona koden och händelseslingan.
Händelseslingan
Vad är händelseslingan?
Händelseslingan är Node.js sätt att bryta ner långvariga processer i små bitar. Den fungerar som ett hjärtslag: Varannan millisekund kontrollerar Node.js en arbetskö för att starta nya uppgifter. Om det finns arbete kommer Node.js att föra in dessa i anropsstapeln och sedan köra dem tills de är färdiga (vi kommer snart att prata om run-to-completion).
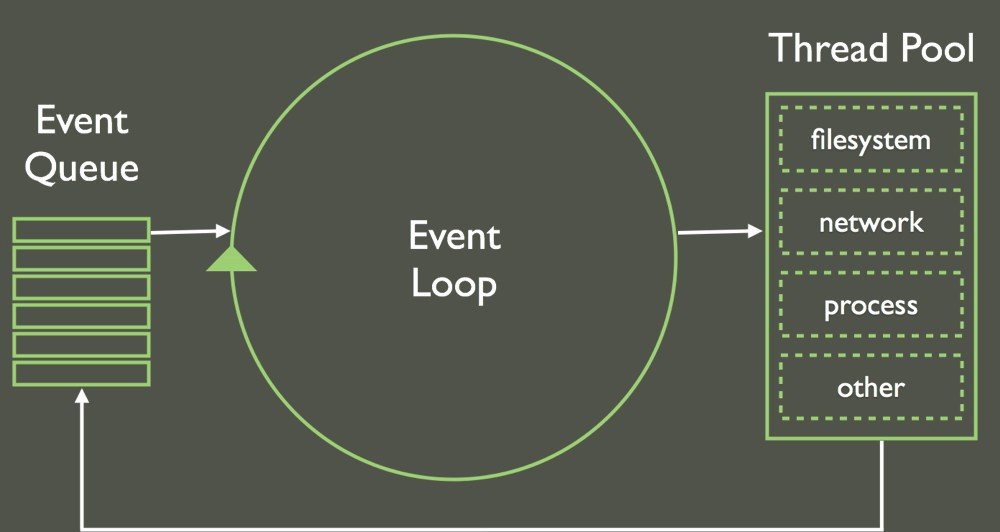
Då Node.js bryter ner uppgifter kan Node.js utföra flera olika arbetsuppgifter, vilket är ditt substitut för trådindelning. Det innebär att medan en uppgift väntar kan en annan starta. Så i stället för threading använder vi asynkron kod, vilket underlättas av programmeringsstilar som callbacks, promises och async/await. De flesta av de färdiga Node-API:erna har både en synkron och asynkron exekveringsmetod.
Okej, så du kanske undrar: vad har all denna teknikjargong med prestanda att göra?
Låt mig förklara…
Node.js prestanda och händelseslingan
Föreställ dig att du bygger en Node.js applikation med två slutpunkter: en för filuppladdning och en som hämtar en användarprofil. API:et för användarprofiler kommer förmodligen att begäras betydligt oftare än API:et för filuppladdning, och om det inte svarar tillräckligt snabbt kommer det att blockera varje sidladdning för varje användare – inte bra.
API:et för användaruppladdning används sällan. Dessutom förväntar sig användarna att uppladdning av uppgifter tar tid, men de är mycket mindre förlåtande när det gäller sidladdningstider. Om vi inte programmerar med händelseslingan i åtanke, medan filen laddas upp, kan Node.js komma att lägga beslag på alla systemresurser och blockera andra användare från att använda ditt program-uh-oh!
Och det är därför du måste förstå att Node.js är enkeltrådig. När vi ändrar vår applikation måste vi ta hänsyn till detta beteende. Vi vill undvika att göra långkörande uppgifter synkront, till exempel göra nätverksförfrågningar, skriva filer eller utföra en tung beräkning.
När vi nu känner till Node.js enkeltrådade natur kan vi använda den till vår fördel. Låt oss gå igenom steg för steg hur du kan konfigurera, köra och analysera ett prestandatest av din Node.js applikation för att se till att du gör ditt bästa för att utnyttja Node.js prestandafunktioner.
Steg 1: Välja verktyg för prestandatest av Node.js
Först vill du välja ett verktyg som gör att du kan köra dina prestandatest. Det finns många verktyg där ute, alla med olika för- och nackdelar för Node.js prestandatestning. En viktig sak att tänka på är att även om du testar en Node.js-applikation, om du ska prestandatesta från omvärlden över ett nätverk, spelar det ingen roll om ditt prestandatestverktyg är skrivet i Node.js.
För grundläggande HTTP-prestandatestning tycker jag om Artillery, ett okomplicerat prestandatestverktyg som är skrivet i Node.js. Det är också särskilt bra på att köra prestandatester för API-förfrågningar. Artillery fungerar genom att skriva en konfigurationsfil som definierar din belastningsprofil. Du talar om för Artillery vilka ändpunkter du vill begära, i vilken takt, under vilken varaktighet osv.
Ett grundläggande testskript ser ut så här:
config: target: 'https://artillery.io' phases: - duration: 60 arrivalRate: 20 defaults: headers: x-my-service-auth: '987401838271002188298567'scenarios:- flow:- get:url: "/docs"Här begär du Artillerys webbplats under 60 sekunder med 20 nya användare som anländer till URL:en.
För att köra testet utför du helt enkelt:
artillery run your_config.yml
Artillery kommer att göra så många förfrågningar till ditt program som du har instruerat det att göra. Detta är användbart för att bygga prestandatestprofiler som efterliknar din produktionsmiljö. Vad menar jag med prestandatestprofil? Det tar vi upp nu.
Steg 2: Skapa en Node.js prestandatestprofil
En prestandatestprofil, som ovan, är en definition av hur ditt prestandatest ska köras. Du vill efterlikna hur din produktionstrafik beter sig, eller förväntas bete sig, om möjligt för att kunna göra en korrekt Node.jsprestandainställning. Om du till exempel bygger en webbplats för evenemang kan du förvänta dig mycket trafik när du släpper biljetter, så du vill bygga en profil som efterliknar detta beteende. Du vill testa din applikations förmåga att skala med stora mängder belastning på kort tid. Om du driver en webbplats för e-handel kan du också förvänta dig jämnare trafik. Här bör dina prestandatestprofiler återspegla detta beteende.
Att utnyttja flera testprofiler
En rolig och intressant punkt att notera är att du kan skapa olika testprofiler och köra dem på ett överlappande sätt. Du kan till exempel skapa en profil som efterliknar din basnivå av trafik – säg 100 förfrågningar per minut – och sedan efterlikna vad som skulle kunna hända om du fick mycket trafik till din webbplats, till exempel om du lägger ut några sökmotorannonser. Att testa flera scenarier är viktigt för en grundlig Node.js-prestandainställning.
Replikering av storskaliga distribuerade system
Jag måste ta en sekund här för att notera en sak: När en applikation når en viss storlek förlorar efterliknande av belastning på det här sättet sin genomförbarhet. De trafikvolymer du kan ha kan vara så vilda, oförutsägbara eller stora i volym att det är svårt att skapa ett realistiskt likadant sätt att testa din applikation innan den släpps.
Men vad händer om detta är fallet? Vad gör vi då? Vi testar i produktion.
Du kanske tänker: ”Woah, vänta lite! Är det inte meningen att vi ska testa före release?”
Det kan du göra, men när ett system når en viss storlek kan det vara vettigt att utnyttja olika prestandateststrategier. Du kan utnyttja koncept som canary releasing för att sätta ut dina ändringar i produktion och testa dem endast med en viss procent av användarna. Om du ser en prestandaförlust kan du byta ut trafiken tillbaka till din tidigare implementering. Den här processen uppmuntrar verkligen till experimenterande, och det bästa är att du testar på din riktiga produktionsapplikation, så du behöver inte oroa dig för att testresultaten inte efterliknar produktionen.
So långt har vi bestämt oss för våra verktyg och vi har skapat profiler som återskapar vår produktion, till exempel trafik och arbetsbelastningar. Vad gör vi härnäst? Vi måste se till att vi har de data vi behöver för att analysera vår applikation, och det gör vi med hjälp av verktyg för Node.js prestandaövervakning och Application Performance Management (APM). Vad är en APM? Läs vidare så får du veta det!
Steg 3: Ställ in din observerbarhet/övervakning
Vi vill inte bara köra vårt prestandatest mot vår applikation och hoppas och be. Om vi gör det kommer vi inte att kunna förstå hur den presterar och om den gör vad vi tror att den ska göra. Så innan vi börjar bör vi ställa oss frågor som: ”Hur ser bra ut för min applikation? Vilka är mina SLA:er och KPI:er? Vilka mätvärden behövs för att effektivt felsöka ett prestandaproblem?”
Om din app fungerar långsamt eller annorlunda än vad du förväntade dig behöver du data för att förstå varför så att du kan förbättra den. Alla produktionsapplikationer som är värda sitt salt använder någon form av observations- och/eller övervakningslösning. Dessa verktyg, som ofta kallas APM:er, gör det möjligt för dig att visa kritiska Node.js prestandamätningar om din körda applikation.
Att komma igång med en APM
APM:er finns i olika former och storlekar, alla med olika funktioner, prislappar, säkerhetsimplikationer, prestanda, you name it. Det lönar sig att handla lite för att hitta det bästa verktyget för dina behov. Det är dessa verktyg som kommer att ge oss de insikter och data vi behöver när vi kör våra Node.js prestandatester.
Så, om vi vet att vi ska övervaka vår applikation – vad exakt ska vi övervaka?
Idealt vill du ha så mycket data som möjligt – men hur mycket vi än älskar data; vi måste vara realistiska om var vi ska börja! Det bästa stället att börja är följande tre områden:
- Aggregerade loggar – Applikationsloggar som antingen implicit avges av vissa bibliotek eller explicit av en utvecklare för att få en inblick i en applikation. Med de flesta verktygen för aggregerade loggar kan du enkelt söka och visualisera dina loggade data. I vårt fall kan vi logga ut prestandan för var och en av våra API:er och plotta dem i ett diagram.
- Insikter om infrastrukturen-Din applikation kommer att köras på en värd av olika slag, så du kommer troligen att vilja se alla data. Om du kör i molnet ger de flesta leverantörer dig dessa data (om än i en grov form) direkt. De data du får från dessa verktyg täcker saker som CPU- och minnesanvändning av din värd, anslutningsdata etc.
- Applikationsövervakning – Denna typ av verktyg sitter vanligtvis i din applikationskod och kan dra insikter om hur funktioner utför/anropas, vilka fel vi kastar etc.
Vissa APM-verktyg, som Retrace, har alla eller de flesta av dessa tre funktioner samlade i en, medan andra kan vara mer specialiserade. Beroende på dina krav kanske du vill ha ett verktyg som gör allt eller en hel rad verktyg för olika ändamål.
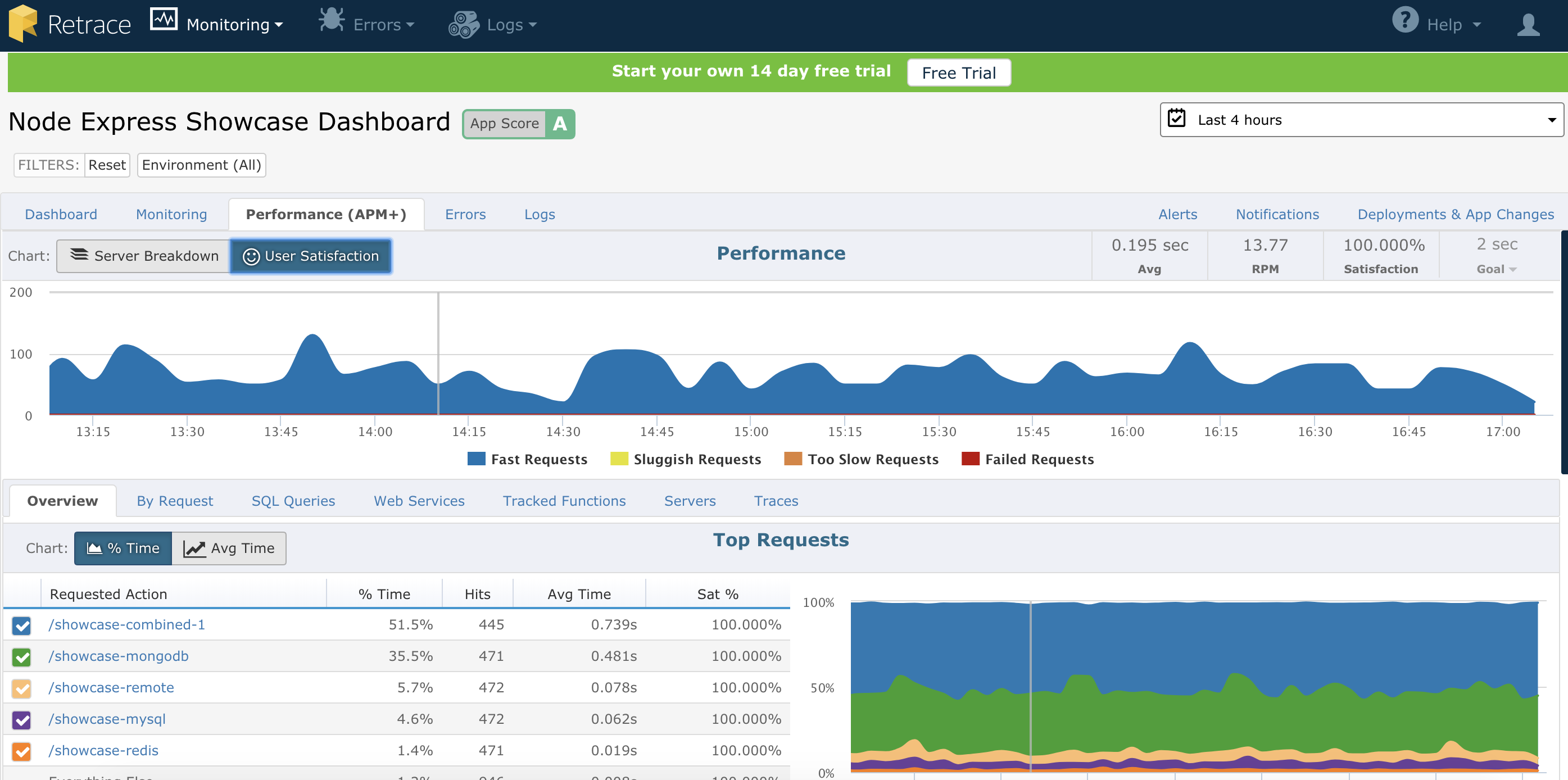
Verktyg som är skräddarsydda för Node.js
Ovanpå verktygen kan vi också inkludera andra Node.js-specifika verktyg och profilerare, som flamgrafer, som tittar på vårt funktionsutförande eller extraherar data om vårt utförande av händelseslingor. I takt med att du blir mer väl insatt i prestandatestning av Node.js kommer dina krav på data bara att öka. Du kommer att vilja fortsätta att shoppa runt, experimentera och uppdatera dina verktyg för att verkligen förstå din applikation.
Nu har vi konfigurerat våra verktyg, fått realistiska profiler för vår prestanda och förstått vår applikationsprestanda, vi är nästan redo att köra våra tester. Men innan vi gör det finns det ytterligare ett steg: att skapa testinfrastruktur.
Steg 4: Skapa infrastruktur för prestandatest av Node.js
Du kan köra prestandatester från din egen maskin om du vill, men det finns problem med att göra detta. Hittills har vi försökt riktigt hårt – till exempel med våra testprofiler – för att se till att våra prestandatester replikeras. En annan faktor för att replikera våra tester är att se till att vi alltid kör dem på samma infrastruktur (läs: maskin).
Ett av de enklaste sätten att uppnå en konsekvent testinfrastruktur är att utnyttja molnhosting. Välj en värd/maskin som du vill starta dina tester från och se till att varje gång du kör testerna är det alltid från samma maskin – och helst från samma plats också – för att undvika att dina data blir snedvridna på grund av förfrågningslatens.
Det är en bra idé att skriva ut den här infrastrukturen i skript, så att du kan skapa och ta ner den när det behövs. Det kallas ”infrastruktur som kod”. De flesta molnleverantörer har nativt stöd för detta, eller så kan du använda ett verktyg som Terraform för att hjälpa dig.
Phew! Vi har täckt en hel del hittills och vi är framme vid det sista steget: att köra våra tester.
Steg 5: Kör dina tester!
Det sista steget är att faktiskt köra våra tester. Om vi startar vår kommandoradskonfiguration (som vi gjorde i steg 1) kommer vi att se förfrågningar till vår Node.js-applikation. Med vår övervakningslösning kan vi kontrollera hur vår händelseslinga presterar, om vissa förfrågningar tar längre tid än andra, om anslutningarna tar slut osv.
Den bästa grädden på moset för dina prestandatester är att överväga att lägga in dem i din bygg- och testpipeline. Ett sätt att göra detta är att köra dina prestandatester över natten så att du kan granska dem varje morgon. Artillery erbjuder ett trevligt och enkelt sätt att skapa dessa rapporter, som kan hjälpa dig att upptäcka eventuella prestandaregressioner i Node.js.
Nu har du blixtsnabba Node.js
Det var allt.
I dag har vi behandlat händelseslingans betydelse för prestandan i din JavaScript-applikation, hur du väljer verktyg för prestandatestning, hur du ställer in konsekventa prestandatestprofiler med Artillery, vilken övervakning du vill ställa in för att diagnostisera Node.js prestandaproblem, och slutligen hur och när du ska köra dina prestandatester för att få ut mesta möjliga värde för dig och ditt team.
Experimentera med övervakningsverktyg som Retrace APM för Node.js, gör små ändringar så att du kan testa effekten av ändringarna, och granska dina testrapporter ofta så att du kan upptäcka regressioner. Nu har du allt du behöver för att utnyttja Node.js prestandafunktioner och skriva en superpresterande applikation som dina användare älskar!