Vi kender Node.js for sin lynhurtige ydeevne. Alligevel kan du, som med ethvert sprog, skrive Node.js-kode, der yder dårligere for dine brugere, end du gerne vil have. For at bekæmpe dette har vi brug for passende test af ydeevne. I dag vil vi dække netop dette med et dybdegående kig på, hvordan du opstiller og kører en ydelsestest og analyserer resultaterne, så du kan lave lynhurtige Node.js-applikationer.
Den bedste måde at forstå, hvordan du kan ydeevneteste din applikation på, er at gennemgå et eksempel.
Du kan bruge Node.js til mange formål: skrive scripts til at køre opgaver, køre en webserver eller servere statiske filer, f.eks. et websted. I dag gennemgår vi trinene for at teste et Node.js HTTP-web-API i Node.js. Men hvis du bygger noget andet i Node, skal du ikke bekymre dig – mange af principperne vil være ens.
- Det unikke ved Node.js ydeevne
- Event loopet
- Node.js-ydeevne og event loop
- Trin 1: Valg af værktøj til Node.js præstationstest
- Trin 2: Opret en Node.js-ydeevneprøvningsprofil
- Udnyttelse af flere testprofiler
- Replikering af distribuerede systemer i stor skala
- Trin 3: Opsæt din observerbarhed/overvågning
- Kom godt i gang med en APM
- Værktøjer skræddersyet til Node.js
- Trin 4: Oprettelse af infrastruktur til Node.js-ydeevne-test
- Trin 5: Kør dine tests!
- Nu har du lynhurtig Node.js
Det unikke ved Node.js ydeevne
Hvor vi begynder, skal vi tage et hurtigt kig på et af de mere unikke kendetegn ved Node.js ydeevne. Vi skal have kendskab til disse egenskaber senere, når vi kører vores ydelsestests.
Hvad taler jeg om?
Den store overvejelse for Node.js-programmer er deres enkelttrådede, køre-til-fuldførelse-adfærd – faciliteret af det, der er kendt som event loop’en. Nu ved jeg, hvad du tænker: Det er meget. Så lad os bryde det lidt ned, så vi forstår, hvad disse betyder.
Lad os starte med single threading. Threading, som et koncept, tillader samtidig behandling i et program. Node.js har ikke denne mulighed, i hvert fald ikke i den traditionelle forstand. For at skrive programmer, der udfører flere opgaver på én gang, har vi i stedet den asynkrone kode og event loopet.
Event loopet
Hvad er event loopet?
Event loopet er Node.js’ måde at opdele langvarige processer i små bidder på. Den fungerer som et hjerteslag: Hvert par millisekunder kontrollerer Node.js en arbejdskø for at starte nye opgaver. Hvis der er arbejde, vil den bringe disse ind i kaldestakken og derefter køre dem til afslutning (vi vil snart tale om run-to-completion).
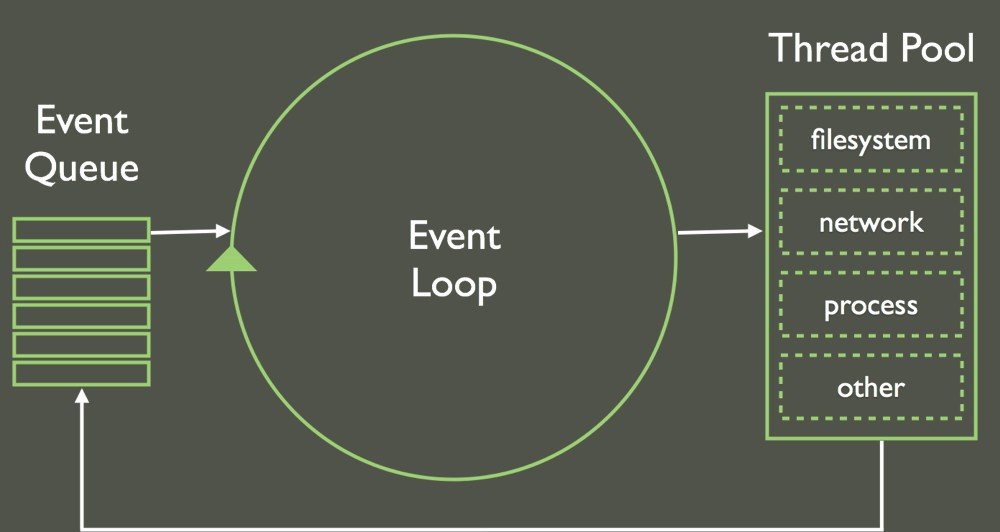
Ved at opdele opgaverne kan Node.js multitaske, hvilket er din erstatning for threading. Det betyder, at mens en opgave venter, kan en anden starte, mens en anden opgave venter. Så i stedet for threading bruger vi asynkron kode, hvilket lettes af programmeringsstile som callbacks, promises og async/await. De fleste af de out-of-the-box Node API’er har både en synkron og asynkron udførelsesmetode.
Okay, så måske undrer du dig: Hvad har alt dette tekniske fagjargon med ydeevne at gøre?
Lad mig forklare…
Node.js-ydeevne og event loop
Forestil dig, at du bygger et Node.js-program med to endpoints: et til upload af filer og et, der henter en brugerprofil. Brugerprofil-API’et vil sandsynligvis blive anmodet betydeligt oftere end filopload, og hvis det ikke svarer hurtigt nok, vil det blokere hver sideindlæsning for hver bruger – ikke godt.
Brugeropload-API’et bruges sjældent. Desuden forventer brugerne, at upload af opgaver tager tid, men de er meget mindre tilgivende med hensyn til sideindlæsningstider. Hvis vi ikke programmerer med event loopet i tankerne, mens filen uploades, kan Node.js ende med at opsluge alle systemressourcerne og blokere andre brugere fra at bruge din applikation-uh-oh!
Og det er derfor, du skal forstå Node.js’ single-threaded natur. Når vi ændrer vores applikation, skal vi overveje denne adfærd. Vi vil gerne undgå at udføre langvarige opgaver synkront, f.eks. lave netværksanmodninger, skrive filer eller udføre en tung beregning.
Nu kender vi Node.js’ single-threaded natur, og vi kan bruge den til vores fordel. Lad os gennemgå trin for trin, hvordan du kan opsætte, køre og analysere en præstationstest af din Node.js applikation for at sikre, at du gør dit bedste for at udnytte Node.js præstationsmuligheder.
Trin 1: Valg af værktøj til Node.js præstationstest
Først skal du vælge et værktøj, der giver dig mulighed for at køre dine præstationstest. Der findes mange værktøjer derude, alle med forskellige fordele og ulemper til Node.js-ydeevnejustering. En vigtig ting at overveje er, at selvom du tester en Node.js-applikation, hvis du skal ydeevneteste fra omverdenen på tværs af et netværk, er det ligegyldigt, om dit værktøj til ydeevnetest er skrevet i Node.js.
Til grundlæggende HTTP-præstationstest kan jeg godt lide Artillery, et simpelt værktøj til ydeevnetest, der er skrevet i Node.js. Det er også særligt godt til at køre ydelsestests for API-forespørgsler. Artillery fungerer ved at skrive en konfigurationsfil, der definerer din belastningsprofil. Du fortæller Artillery, hvilke endpoints du vil anmode om, med hvilken hastighed, i hvilken varighed osv.
Et grundlæggende testskript ser således ud:
config: target: 'https://artillery.io' phases: - duration: 60 arrivalRate: 20 defaults: headers: x-my-service-auth: '987401838271002188298567'scenarios:- flow:- get:url: "/docs"Her anmoder du om Artillerys websted i en periode på 60 sekunder med 20 nye brugere, der ankommer til URL’en.
For at køre testen skal du derefter blot udføre:
artillery run your_config.yml
Artillery foretager så mange anmodninger til dit program, som du har instrueret det til. Dette er nyttigt til at opbygge profiler for præstationstest, der efterligner dit produktionsmiljø. Hvad mener jeg med præstationstestprofil? Lad os dække det nu.
Trin 2: Opret en Node.js-ydeevneprøvningsprofil
En ydeevneprøvningsprofil er som ovenfor en definition af, hvordan din ydeevneprøvning skal køre. Du ønsker at efterligne, hvordan din produktionstrafik opfører sig eller forventes at opføre sig, hvis det er muligt for at foretage præcis Node.js-ydeevnejustering. Hvis du f.eks. er ved at opbygge et eventwebsted, vil du forvente masser af trafik omkring det tidspunkt, hvor du frigiver billetter, så du vil bygge en profil, der efterligner denne adfærd. Du vil gerne teste din applikations evne til at skalere med store mængder belastning på kort tid. Alternativt, hvis du driver et e-handelswebsted, kan du måske forvente jævn trafik. Her bør dine profiler for ydelsestest afspejle denne adfærd.
Udnyttelse af flere testprofiler
Et sjovt og interessant punkt at bemærke er, at du kan oprette forskellige testprofiler og køre dem på en overlappende måde. Du kan f.eks. oprette en profil, der efterligner dit basisniveau af trafik – f.eks. 100 forespørgsler pr. minut – og derefter efterligne, hvad der kunne ske, hvis du oplevede meget trafik til dit websted, f.eks. hvis du udsendte nogle søgemaskineannoncer. Det er vigtigt at teste flere scenarier for grundig Node.js performance tuning.
Replikering af distribuerede systemer i stor skala
Jeg må tage et sekund her for at bemærke noget: Når en applikation når en vis størrelse, mister efterligning af belastning på denne måde sin gennemførlighed. De trafikmængder, du kan have, kan være så vilde, uforudsigelige eller store i volumen, at det er svært at skabe en realistisk lignende måde at teste din applikation på før frigivelse.
Men hvad nu hvis dette er tilfældet? Hvad skal vi så gøre? Vi tester i produktion.
Du tænker måske: “Woah, vent lige lidt! Skal vi ikke teste før frigivelse?”
Det kan du godt, men når et system når en vis størrelse, kan det give mening at udnytte forskellige strategier til test af ydeevne. Du kan udnytte koncepter som canary releasing til at sætte dine ændringer ud i produktion og kun teste dem med en vis procentdel af brugerne. Hvis du ser en ydelsesnedgang, kan du bytte trafikken tilbage til din tidligere implementering. Denne proces tilskynder virkelig til eksperimenter, og det bedste er, at du tester på din rigtige produktionsapplikation, så du behøver ikke bekymre dig om, at testresultaterne ikke efterligner produktionen.
Så langt har vi besluttet os for vores værktøj, og vi har oprettet profiler, der genskaber vores produktion, som trafik og arbejdsbelastninger. Hvad gør vi nu? Vi skal sikre, at vi har de data, vi har brug for til at analysere vores applikation, og det gør vi ved hjælp af Node.js ydelsesovervågning og Application Performance Management (APM)-værktøjer. Hvad er en APM? Læs videre, så skal jeg fortælle dig det!
Trin 3: Opsæt din observerbarhed/overvågning
Vi ønsker ikke bare at køre vores præstationstest mod vores applikation og håbe og bede. Hvis vi gør det, vil vi ikke være i stand til at forstå, hvordan den præsterer, og om den gør det, som vi tror, den skal. Så før vi begynder, bør vi stille os selv spørgsmål som: “For min applikation, hvad ser godt ud? Hvad er mine SLA’er og KPI’er? Hvilke målinger er nødvendige for effektivt at debugge et ydelsesproblem?”
Hvis din app fungerer langsomt eller anderledes end forventet, har du brug for data for at forstå hvorfor, så du kan forbedre den. Alle produktionsapplikationer, der er noget værd, bruger en eller anden form for observerbarhed og/eller overvågningsløsning. Disse værktøjer, ofte kaldet APM’er, giver dig mulighed for at se kritiske Node.js-præstationsmetrikker om din kørende applikation.
Kom godt i gang med en APM
APM’er findes i forskellige former og størrelser, alle med forskellige funktioner, prisskilte, sikkerhedsimplikationer, ydeevne, you name it. Det kan betale sig at shoppe lidt rundt for at finde det bedste værktøj til dine behov. Det er disse værktøjer, der vil give os den indsigt og de data, vi har brug for, når vi kører vores Node.js ydelsestests.
Så, hvis vi ved, at vi skal overvåge vores applikation – hvad skal vi så præcist overvåge?
Idealt set vil du have så mange data som muligt – men lige så meget som vi elsker data; vi er nødt til at være realistiske med hensyn til, hvor vi skal starte! Det bedste sted at starte er med følgende tre områder:
- Aggregerede logs-Applikationslogs udsender enten implicit af nogle biblioteker eller eksplicit af en udvikler for at få et indblik i en applikation. De fleste aggregerede logværktøjer giver dig mulighed for nemt at søge og visualisere dine loggede data. I vores tilfælde kunne vi logge ydelsen for hver af vores API’er og plotte dem på en graf.
- Infrastrukturindsigt-Din applikation vil køre på en vært af forskellige slags, så du vil sandsynligvis gerne se alle data. Hvis du kører i skyen, giver de fleste udbydere dig disse data (om end i en grov form) out of the box. De data, du får fra disse værktøjer, vil dække ting som CPU- og hukommelsesforbrug på din vært, forbindelsesdata osv.
- Applikationsovervågning – Denne type værktøj sidder normalt i din applikationskode og kan trække indsigt i, hvordan funktioner udfører/kaldes, hvilke fejl vi kaster osv.
Nogle APM-værktøjer, som Retrace, har alle eller de fleste af disse tre funktioner samlet i et, mens andre kan være mere specialiserede. Afhængigt af dine krav vil du måske have ét værktøj, der kan det hele, eller en hel række værktøjer til forskellige formål.
Værktøjer skræddersyet til Node.js
Oven på værktøjer kan vi også inkludere andre Node.js-specifikke værktøjer og profilere, som flame graphs, der kigger på vores funktionsudførelse eller uddrager data om vores udførelse af eventloop. Efterhånden som du bliver mere velbevandret i Node.js-ydeevneprøvning, vil dine krav til data kun vokse. Du vil gerne blive ved med at shoppe rundt, eksperimentere og opdatere dine værktøjer for virkelig at forstå din applikation.
Nu har vi opsat vores værktøjer, fået realistiske profiler for vores ydeevne og forstået vores applikations ydeevne, og vi er næsten klar til at køre vores tests. Men før vi gør det, er der endnu et trin: oprettelse af testinfrastruktur.
Trin 4: Oprettelse af infrastruktur til Node.js-ydeevne-test
Du kan køre ydeevnetest fra din egen maskine, hvis du ønsker det, men der er problemer med at gøre dette. Indtil videre har vi forsøgt virkelig hårdt – f.eks. med vores testprofiler – at sikre, at vores ydelsestests replikeres. En anden faktor i replikering af vores tests er at sikre, at vi altid kører dem på den samme infrastruktur (læs: maskine).
En af de nemmeste måder at opnå en konsistent testinfrastruktur på er at udnytte cloud-hosting. Vælg en vært/maskine, du vil starte dine tests fra, og sørg for, at hver gang du kører dine tests, er det altid fra den samme maskine – og helst også fra den samme placering – for at undgå at skævvride dine data baseret på forespørgselslatensitet.
Det er en god idé at scripte denne infrastruktur, så du kan oprette og nedbryde den efter behov. Man kalder denne idé for “infrastruktur som kode”. De fleste cloud-udbydere understøtter det nativt, eller du kan bruge et værktøj som Terraform til at hjælpe dig.
Phew! Vi har dækket en masse område indtil nu, og vi er nået til det sidste trin: at køre vores tests.
Trin 5: Kør dine tests!
Det sidste trin er faktisk at køre vores tests. Hvis vi starter vores kommandolinjekonfiguration (som vi gjorde i trin 1), vil vi se anmodninger til vores Node.js-program. Med vores overvågningsløsning kan vi kontrollere, hvordan vores event loop klarer sig, om visse anmodninger tager længere tid end andre, om forbindelserne går ud i tid osv.
Den bedste prikken over i’et for dine ydelsestests er at overveje at lægge dem ind i din build- og testpipeline. En måde at gøre dette på er at køre dine ydelsestests natten over, så du kan gennemgå dem hver morgen. Artillery giver en fin og enkel måde at oprette disse rapporter på, som kan hjælpe dig med at opdage eventuelle regressioner i Node.js-ydeevne.
Nu har du lynhurtig Node.js
Det er en wrap.
I dag dækkede vi begivenhedsloopens relevans for ydelsen af din JavaScript-applikation, hvordan du vælger dit værktøj til ydelsestestning, hvordan du opstiller konsistente profiler for ydelsestestning med Artillery, hvilken overvågning du vil opsætte for at diagnosticere Node.js-ydeevneproblemer, og endelig hvordan og hvornår du skal køre dine ydelsestests for at få mest muligt ud af dem for dig og dit team.
Eksperimenter med overvågningsværktøjer som Retrace APM for Node.js, lav små ændringer, så du kan teste virkningen af ændringer, og gennemgå dine testrapporter ofte, så du kan opdage regressioner. Nu har du alt, hvad du behøver for at udnytte Node.js’ præstationsmuligheder og skrive et superperformant program, som dine brugere elsker!