- Introducere
- Obiectivul
- A. Metode de filtrare
- Testul Chi-pătrat
- Scorul lui Fisher
- Coeficientul de corelație
- Semnalul de variație
- Mean Absolute Difference (MAD)
- Raportul de dispersie
- B. Wrapper Methods:
- Forward Feature Selection
- Eliminarea retrogradă a caracteristicilor
- Exhaustive Feature Selection
- Eliminarea recursivă a caracteristicilor
- C. Metode încorporate:
- RegularizareLASSO (L1)
- Importanța pădurilor aleatoare
- Concluzie
Introducere
Când se construiește un model de învățare automată în viața reală, este aproape rar ca toate variabilele din setul de date să fie utile pentru a construi un model. Adăugarea de variabile redundante reduce capacitatea de generalizare a modelului și poate reduce, de asemenea, precizia generală a unui clasificator. În plus, adăugarea a tot mai multe variabile la un model crește complexitatea generală a modelului.
Potrivit legii parșimoniei din „Occam’s Razor”, cea mai bună explicație a unei probleme este cea care implică cele mai puține ipoteze posibile. Astfel, selecția caracteristicilor devine o parte indispensabilă a construirii modelelor de învățare automată.
Obiectivul
Obiectivul selecției caracteristicilor în învățarea automată este de a găsi cel mai bun set de caracteristici care să permită construirea unor modele utile ale fenomenelor studiate.
Tehnicile de selecție a caracteristicilor în învățarea automată pot fi clasificate, în linii mari, în următoarele categorii:
Tehnici supervizate: Aceste tehnici pot fi utilizate pentru date etichetate și sunt folosite pentru a identifica caracteristicile relevante pentru creșterea eficienței modelelor supravegheate, cum ar fi clasificarea și regresia.
Tehnici nesupravegheate: Aceste tehnici pot fi utilizate pentru date neetichetate.
Dintr-un punct de vedere taxonomic, aceste tehnici sunt clasificate după cum urmează:
A. Metode de filtrare
B. Metode de înfășurare
C. Metode încorporate
D. Metode hibride
În acest articol, vom discuta câteva tehnici populare de selecție a caracteristicilor în învățarea automată.
A. Metode de filtrare
Metodele de filtrare preiau proprietățile intrinseci ale caracteristicilor măsurate prin statistici univariate în loc de performanța validării încrucișate. Aceste metode sunt mai rapide și mai puțin costisitoare din punct de vedere computațional decât metodele wrapper. Atunci când se tratează date cu dimensiuni mari, este mai ieftin din punct de vedere computațional să se utilizeze metode de filtrare.
Să discutăm câteva dintre aceste tehnici:
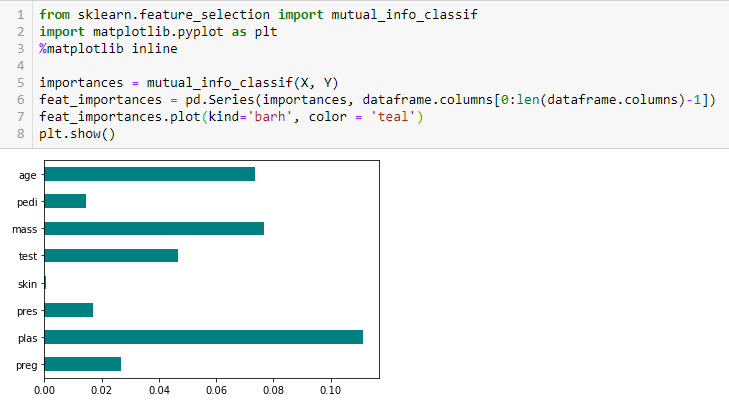
Câștig de informație
Câștigul de informație calculează reducerea entropiei din transformarea unui set de date. Poate fi utilizat pentru selectarea caracteristicilor prin evaluarea câștigului de informație al fiecărei variabile în contextul variabilei țintă.
Testul Chi-pătrat
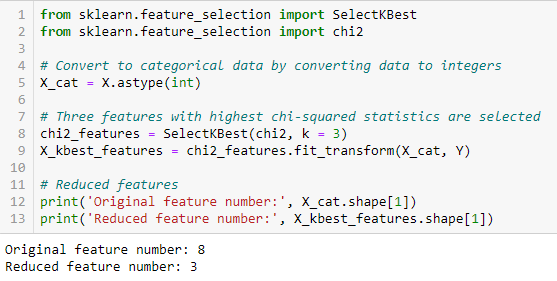
Testul Chi-pătrat este utilizat pentru caracteristicile categorice dintr-un set de date. Se calculează Chi-pătrat între fiecare caracteristică și țintă și se selectează numărul dorit de caracteristici cu cele mai bune scoruri Chi-pătrat. Pentru a aplica corect chi pătrat pentru a testa relația dintre diverse caracteristici din setul de date și variabila țintă, trebuie îndeplinite următoarele condiții: variabilele trebuie să fie categorice, eșantionate independent și valorile trebuie să aibă o frecvență așteptată mai mare de 5.
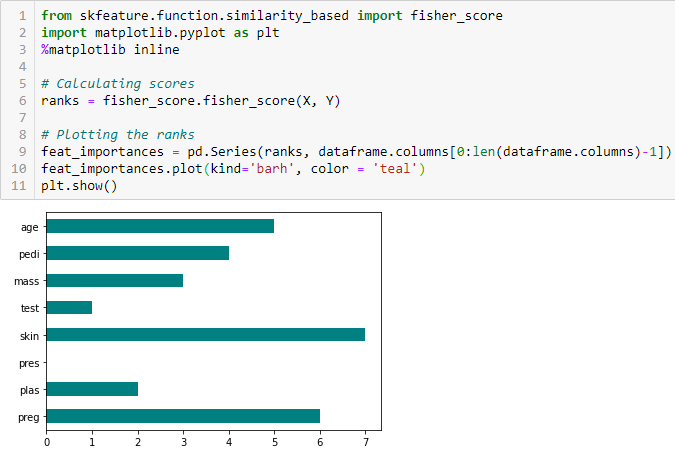
Scorul lui Fisher
Scorul lui Fisher este una dintre cele mai utilizate metode de selecție supravegheată a caracteristicilor. Algoritmul pe care îl vom utiliza returnează rangurile variabilelor pe baza scorului lui Fisher în ordine descrescătoare. Apoi putem selecta variabilele în funcție de caz.
Coeficientul de corelație
Corelația este o măsură a relației liniare dintre 2 sau mai multe variabile. Prin corelație, putem prezice o variabilă pornind de la cealaltă. Logica din spatele utilizării corelației pentru selectarea caracteristicilor este aceea că variabilele bune sunt puternic corelate cu ținta. Mai mult, variabilele ar trebui să fie corelate cu ținta, dar ar trebui să fie necorelate între ele.
Dacă două variabile sunt corelate, putem prezice una din cealaltă. Prin urmare, dacă două caracteristici sunt corelate, modelul are cu adevărat nevoie doar de una dintre ele, deoarece cea de-a doua nu adaugă informații suplimentare. Vom folosi aici corelația Pearson.
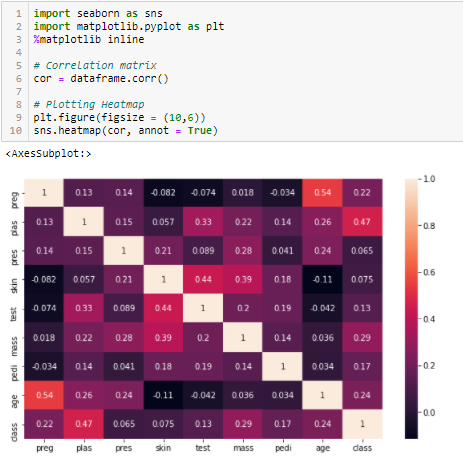
Trebuie să stabilim o valoare absolută, să zicem 0,5, ca prag pentru selectarea variabilelor. Dacă constatăm că variabilele predictive sunt corelate între ele, putem renunța la variabila care are o valoare mai mică a coeficientului de corelație cu variabila țintă. De asemenea, putem calcula coeficienți de corelație multipli pentru a verifica dacă mai mult de două variabile sunt corelate între ele. Acest fenomen este cunoscut sub numele de multicoliniaritate.
Semnalul de variație
Semnalul de variație este o abordare de bază simplă pentru selectarea caracteristicilor. Aceasta elimină toate caracteristicile a căror varianță nu atinge un anumit prag. În mod implicit, elimină toate caracteristicile cu variație zero, adică caracteristicile care au aceeași valoare în toate eșantioanele. Presupunem că trăsăturile cu o varianță mai mare pot conține mai multe informații utile, dar rețineți că nu luăm în considerare relația dintre variabilele trăsăturilor sau dintre variabilele trăsăturilor și variabilele țintă, ceea ce reprezintă unul dintre dezavantajele metodelor de filtrare.

Către get_support returnează un vector boolean în care True înseamnă că variabila nu are o varianță zero.
Mean Absolute Difference (MAD)
‘The mean absolute difference (MAD) calculează diferența absolută față de valoarea medie. Principala diferență între măsurile varianței și MAD este absența pătratului în cea din urmă. MAD, ca și varianța, este, de asemenea, o variantă de scară.”. Aceasta înseamnă că, cu cât este mai mare MAD, cu atât este mai mare puterea de discriminare.
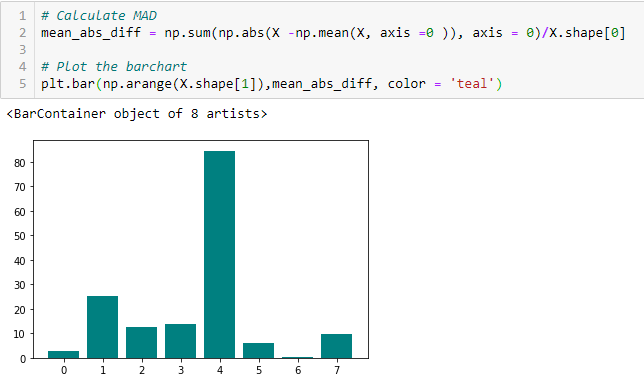
Raportul de dispersie
‘O altă măsură a dispersiei aplică media aritmetică (AM) și media geometrică (GM). Pentru o anumită caracteristică (pozitivă) Xi pe n modele, AM și GM sunt date de
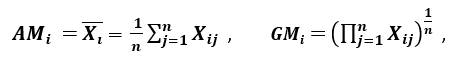
respectiv; întrucât AMi ≥ GMi, egalitatea fiind valabilă dacă și numai dacă Xi1 = Xi2 = …. = Xin, atunci raportul
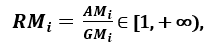
poate fi utilizat ca măsură de dispersie. O dispersie mai mare implică o valoare mai mare a lui Ri, deci o caracteristică mai relevantă. Invers, atunci când toate eșantioanele de caracteristici au (aproximativ) aceeași valoare, Ri este aproape de 1, indicând o caracteristică cu relevanță scăzută.

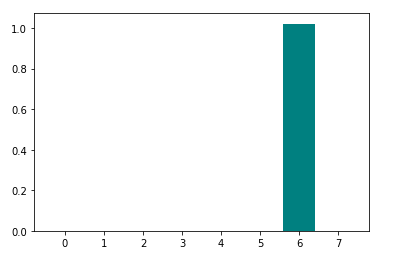 ‘
‘
B. Wrapper Methods:
Învelișurile necesită o anumită metodă pentru a căuta în spațiul tuturor subansamblurilor posibile de caracteristici, evaluând calitatea acestora prin învățarea și evaluarea unui clasificator cu acel subansamblu de caracteristici. Procesul de selecție a caracteristicilor se bazează pe un algoritm specific de învățare automată pe care încercăm să îl adaptăm la un set de date dat. Acesta urmează o abordare de căutare lacomă prin evaluarea tuturor combinațiilor posibile de caracteristici în funcție de criteriul de evaluare. Metodele de înfășurare au ca rezultat, de obicei, o acuratețe de predicție mai bună decât metodele de filtrare.
Să discutăm câteva dintre aceste tehnici:
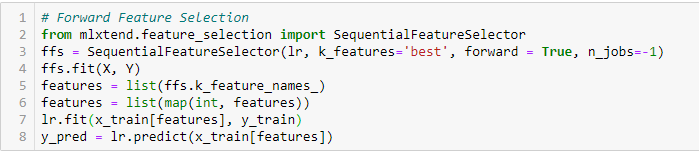
Forward Feature Selection
Este o metodă iterativă în care începem cu variabila cu cea mai bună performanță în raport cu obiectivul. Apoi, selectăm o altă variabilă care oferă cea mai bună performanță în combinație cu prima variabilă selectată. Acest proces continuă până când se atinge criteriul prestabilit.
Eliminarea retrogradă a caracteristicilor
Această metodă funcționează exact invers față de metoda Forward Feature Selection. Aici, începem cu toate caracteristicile disponibile și construim un model. Apoi, eliminăm din model variabila care oferă cea mai bună valoare a măsurii de evaluare. Acest proces este continuat până când se atinge criteriul prestabilit.
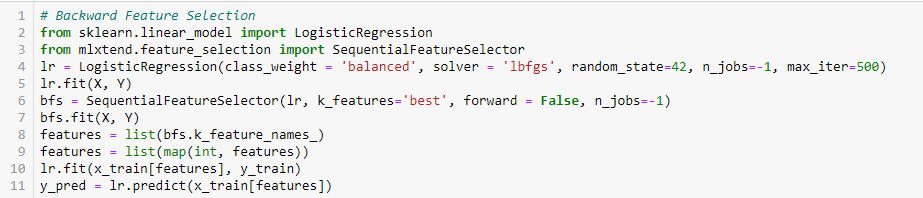
Această metodă, împreună cu cea discutată mai sus, este cunoscută și sub numele de metoda Sequential Feature Selection.
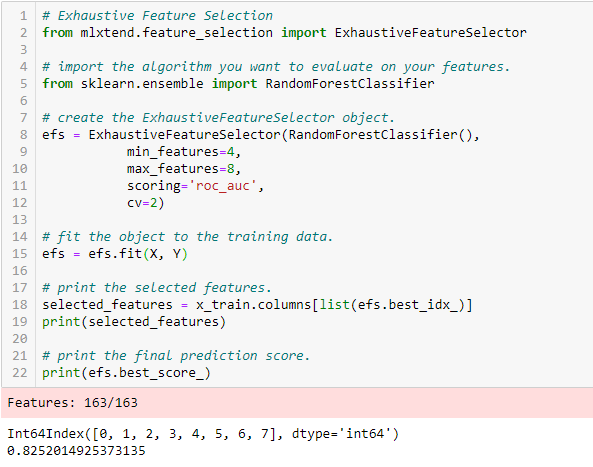
Exhaustive Feature Selection
Aceasta este cea mai robustă metodă de selecție a caracteristicilor abordată până acum. Aceasta este o evaluare prin forță brută a fiecărui subset de caracteristici. Aceasta înseamnă că încearcă toate combinațiile posibile de variabile și returnează cel mai performant subset.
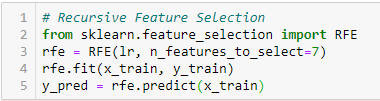
Eliminarea recursivă a caracteristicilor
‘Dat fiind un estimator extern care atribuie ponderi caracteristicilor (de exemplu, coeficienții unui model liniar), scopul eliminării recursive a caracteristicilor (RFE) este de a selecta caracteristicile prin luarea în considerare în mod recursiv a unor seturi din ce în ce mai mici de caracteristici. În primul rând, estimatorul este antrenat pe setul inițial de caracteristici, iar importanța fiecărei caracteristici este obținută fie prin intermediul unui atribut coef_, fie prin intermediul unui atribut feature_importances_.
Apoi, cele mai puțin importante caracteristici sunt eliminate din setul curent de caracteristici. Această procedură se repetă în mod recursiv asupra setului de caracteristici selectate până când se ajunge în cele din urmă la numărul dorit de caracteristici de selectat.”
C. Metode încorporate:
Aceste metode înglobează avantajele metodelor de înveliș și de filtrare, prin includerea interacțiunilor caracteristicilor, dar și prin menținerea unui cost de calcul rezonabil. Metodele încorporate sunt iterative în sensul că se ocupă de fiecare iterație a procesului de formare a modelului și extrage cu atenție acele caracteristici care contribuie cel mai mult la formarea pentru o anumită iterație.
Să discutăm câteva dintre aceste tehnici, faceți clic aici:
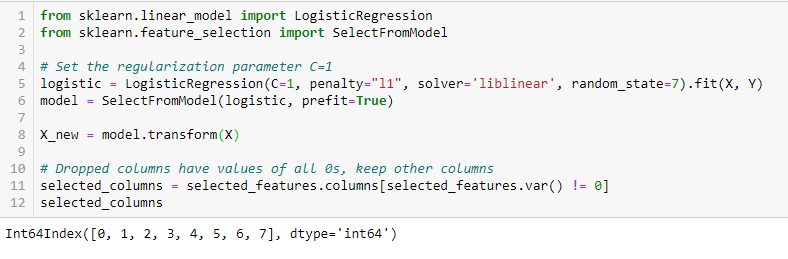
RegularizareLASSO (L1)
Regularizarea constă în adăugarea unei penalizări la diferiți parametri ai modelului de învățare automată pentru a reduce libertatea modelului, adică pentru a evita supraadaptarea. În cazul regularizării modelului liniar, penalizarea se aplică asupra coeficienților care multiplică fiecare dintre predictori. Dintre diferitele tipuri de regularizare, Lasso sau L1 are proprietatea de a micșora unii dintre coeficienți la zero. Prin urmare, caracteristica respectivă poate fi eliminată din model.
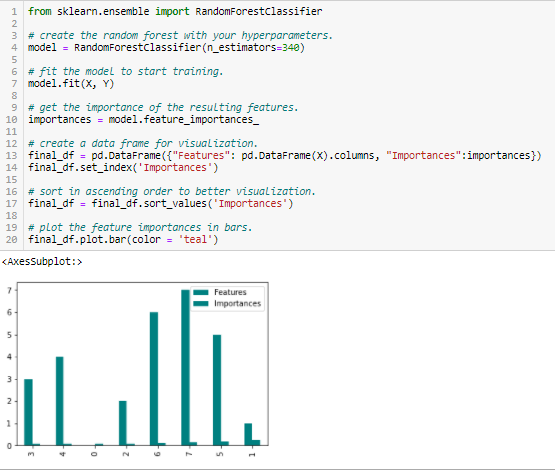
Importanța pădurilor aleatoare
Pădurile aleatoare sunt un fel de algoritm de bagging care agregă un număr specificat de arbori de decizie. Strategiile bazate pe arbori utilizate de pădurile aleatoare se clasifică în mod natural în funcție de cât de bine îmbunătățesc puritatea nodului sau, cu alte cuvinte, o scădere a impurității (impuritatea Gini) pe toți arborii. Nodurile cu cea mai mare scădere a impurității apar la începutul arborilor, în timp ce notele cu cea mai mică scădere a impurității apar la sfârșitul arborilor. Astfel, prin tăierea arborilor sub un anumit nod, putem crea un subset al celor mai importante caracteristici.
Concluzie
Am discutat câteva tehnici de selecție a caracteristicilor. Am lăsat în mod intenționat tehnicile de extragere a caracteristicilor, cum ar fi analiza componentelor principale, descompunerea valorii singulare, analiza discriminantă liniară etc. Aceste metode ajută la reducerea dimensionalității datelor sau la reducerea numărului de variabile, păstrând în același timp varianța datelor.
În afară de metodele discutate mai sus, există multe alte metode de selecție a caracteristicilor. Există și metode hibride care utilizează atât tehnici de filtrare, cât și de înfășurare. Dacă doriți să explorați mai mult despre tehnicile de selecție a caracteristicilor, un material de lectură foarte cuprinzător, în opinia mea, ar fi „Feature Selection for Data and Pattern Recognition” de Urszula Stańczyk și Lakhmi C. Jain.