Update 29-mai-2018: Scopul acestui articol este triplu (1) Să arătăm că vom avea întotdeauna nevoie de un model de date (fie că este realizat de oameni sau de mașini) (2) Să arătăm că modelarea fizică nu este același lucru cu modelarea logică. De fapt, este foarte diferită și depinde de tehnologia de bază. Cu toate acestea, avem nevoie de ambele. Am ilustrat acest punct folosind Hadoop la nivelul fizic (3) Arătați impactul conceptului de imutabilitate asupra modelării datelor.
- Este modelarea dimensională moartă?
- De ce avem nevoie să ne modelăm datele?
- De ce avem nevoie de modele dimensionale?
- Modelarea datelor vs. modelarea dimensională
- Atunci de ce susțin unii oameni că modelarea dimensională este moartă?
- Depozitul de date este mort Confuzie
- Înțelegerea greșită a schemei pe citire
- Denormalizarea revizuită. Aspectele fizice ale modelului.
- Luând de-normalizarea până la capăt
- Distribuția datelor pe o bază de date relațională distribuită (MPP)
- Distribuția datelor pe Hadoop
- Modele dimensionale pe Hadoop
- Hadoop și dimensiunile care se schimbă lent
- Evoluția stocării pe Hadoop
- Verdict. Sunt modelele dimensionale și schemele în stea depășite?
- Lectură complementară despre modelarea dimensională în era Big Data
Este modelarea dimensională moartă?
Înainte de a vă da un răspuns la această întrebare, haideți să facem un pas înapoi și să ne uităm mai întâi la ceea ce înțelegem prin modelarea dimensională a datelor.
De ce avem nevoie să ne modelăm datele?
Contrariu unei neînțelegeri comune, nu este singurul scop al modelelor de date să servească drept diagramă ER pentru proiectarea unei baze de date fizice. Modelele de date reprezintă complexitatea proceselor de afaceri dintr-o întreprindere. Ele documentează reguli și concepte de afaceri importante și ajută la standardizarea terminologiei cheie a întreprinderii. Ele oferă claritate și ajută la descoperirea gândirii neclare și a ambiguităților legate de procesele de afaceri. În plus, puteți utiliza modelele de date pentru a comunica cu alte părți interesate. Nu ați construi o casă sau un pod fără un plan. Deci, de ce ați construi o aplicație de date, cum ar fi un depozit de date, fără un plan?
De ce avem nevoie de modele dimensionale?
Modelarea dimensională este o abordare specială pentru modelarea datelor. De asemenea, folosim cuvintele data mart sau star schema ca sinonime pentru un model dimensional. Schemele stea sunt optimizate pentru analiza datelor. Aruncați o privire la modelul dimensional de mai jos. Este destul de intuitiv de înțeles. Vedem imediat cum putem felia și tăia datele privind comenzile noastre în funcție de client, produs sau dată și cum putem măsura performanța procesului de afaceri Comenzi prin agregarea și compararea indicatorilor.
Una dintre ideile de bază despre modelarea dimensională este definirea celui mai mic nivel de granularitate într-un proces de afaceri tranzacțional. Atunci când feliem, tăiem și analizăm datele, acesta este nivelul frunzei de la care nu mai putem detalia mai departe. Altfel spus, cel mai mic nivel de granularitate într-o schemă în stea este o alăturare a faptului la toate tabelele de dimensiuni fără nicio agregare.
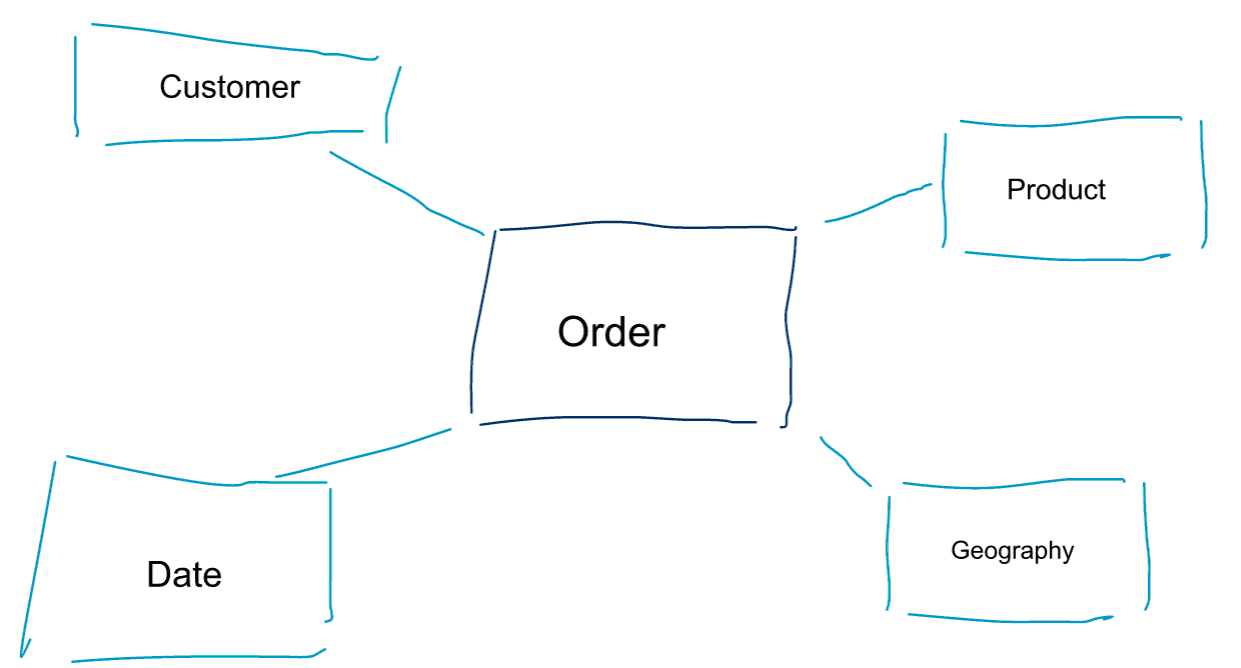
Modelarea datelor vs. modelarea dimensională
În modelarea standard a datelor urmărim să eliminăm repetiția și redundanța datelor. Atunci când se produce o modificare a datelor, trebuie să le modificăm doar într-un singur loc. Acest lucru ajută, de asemenea, la calitatea datelor. Valorile nu se desincronizează în mai multe locuri. Aruncați o privire la modelul de mai jos. Acesta conține diverse tabele care reprezintă concepte geografice. Într-un model normalizat, avem un tabel separat pentru fiecare entitate. Într-un model dimensional avem doar un singur tabel: geografie. În acest tabel, orașele vor fi repetate de mai multe ori. O dată pentru fiecare oraș. Dacă țara își schimbă numele trebuie să actualizăm țara în mai multe locuri
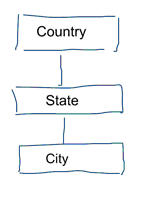
Nota: Modelarea standardizată a datelor este, de asemenea, denumită modelare 3NF.
Abordarea standardizată a modelării datelor nu se potrivește scopului pentru sarcinile de lucru Business Intelligence. O mulțime de tabele au ca rezultat o mulțime de îmbinări. Îmbinările încetinesc lucrurile. În analiza datelor le evităm pe cât posibil. În modelele dimensionale, de-normalizăm mai multe tabele legate între ele într-un singur tabel, de exemplu, diferitele tabele din exemplul nostru anterior pot fi pre-unite într-un singur tabel: geografie.
Atunci de ce susțin unii oameni că modelarea dimensională este moartă?
Cred că veți fi de acord că modelarea datelor în general și modelarea dimensională în special este un exercițiu destul de util. Așadar, de ce susțin unii oameni că modelarea dimensională nu este utilă în era big data și Hadoop?
Așa cum vă puteți imagina, există diverse motive pentru acest lucru.
Depozitul de date este mort Confuzie
În primul rând, unii oameni confundă modelarea dimensională cu depozitarea de date. Ei susțin că depozitarea datelor este moartă și, ca urmare, modelarea dimensională poate fi și ea aruncată la coșul de gunoi al istoriei. Acesta este un argument coerent din punct de vedere logic. Cu toate acestea, conceptul de depozit de date este departe de a fi depășit. Întotdeauna avem nevoie de date integrate și fiabile pentru popularea tablourilor noastre de bord BI. Dacă doriți să aflați mai multe, vă recomand cursul nostru de formare Big Data for Data Warehouse Professionals. În cadrul cursului intru în detalii și explic cum depozitul de date este la fel de relevant ca întotdeauna. Voi arăta, de asemenea, cum instrumentele și tehnologiile emergente de big data sunt utile pentru depozitarea datelor.

Înțelegerea greșită a schemei pe citire
Cel de-al doilea argument pe care îl aud frecvent sună astfel. ‘Noi urmăm o abordare schema on read și nu mai avem nevoie să ne modelăm datele’. În opinia mea, conceptul de schema on read este una dintre cele mai mari neînțelegeri în analiza datelor. Sunt de acord că este util să stocați inițial datele brute într-un volum de date care nu conține prea multe scheme. Cu toate acestea, acest argument nu ar trebui să fie folosit ca o scuză pentru a nu vă modela datele cu totul. Abordarea „schema la citire” nu face decât să arunce cu piciorul în coșul de gunoi și responsabilitatea către procesele din aval. Cineva trebuie să se ocupe în continuare de definirea tipurilor de date. Fiecare proces care accesează datele fără schemă trebuie să își dea seama singur ce se întâmplă. Acest tip de muncă se adună, este complet redundant și poate fi evitat cu ușurință prin definirea tipurilor de date și a unei scheme adecvate.
Denormalizarea revizuită. Aspectele fizice ale modelului.
Există, de fapt, unele argumente valide pentru declararea modelelor dimensionale ca fiind învechite? Există, într-adevăr, unele argumente mai bune decât cele două pe care le-am enumerat mai sus. Ele necesită o anumită înțelegere a modelării fizice a datelor și a modului în care funcționează Hadoop. Aveți răbdare cu mine.
Mai devreme am menționat pe scurt unul dintre motivele pentru care ne modelăm datele în mod dimensional. Acesta este în legătură cu modul în care datele sunt stocate fizic în depozitul nostru de date. În modelarea standard a datelor, fiecare entitate din lumea reală primește propriul tabel. Facem acest lucru pentru a evita redundanța datelor și riscul ca problemele de calitate a datelor să se strecoare în datele noastre. Cu cât avem mai multe tabele, cu atât avem nevoie de mai multe îmbinări. Acesta este dezavantajul. Alăturările de tabele sunt costisitoare, în special atunci când alăturăm un număr mare de înregistrări din seturile noastre de date. Atunci când modelăm datele în mod dimensional, consolidăm mai multe tabele într-una singură. Spunem că efectuăm o pre-joncțiune sau de-normalizăm datele. Acum avem mai puține tabele, mai puține îmbinări și, ca rezultat, o latență mai mică și o performanță mai bună a interogărilor.
Participați la discuția acestei postări pe LinkedIn
Luând de-normalizarea până la capăt
De ce să nu ducem de-normalizarea până la capăt? Să scăpăm de toate îmbinările și să avem doar un singur tabel de fapte? Într-adevăr, acest lucru ar elimina cu totul necesitatea oricăror îmbinări. Cu toate acestea, după cum vă puteți imagina, are unele efecte secundare. În primul rând, crește cantitatea de stocare necesară. Acum trebuie să stocăm o mulțime de date redundante. Odată cu apariția formatelor de stocare columnară pentru analiza datelor, acest lucru este mai puțin îngrijorător în prezent. Cea mai mare problemă a denormalizării este faptul că, de fiecare dată când valoarea unuia dintre atribute se modifică, trebuie să actualizăm valoarea în mai multe locuri – posibil mii sau milioane de actualizări. O modalitate de a ocoli această problemă este de a reîncărca complet modelele noastre în fiecare noapte. Adesea, acest lucru va fi mult mai rapid și mai ușor decât aplicarea unui număr mare de actualizări. Bazele de date columnare adoptă de obicei următoarea abordare. Acestea stochează mai întâi actualizările datelor în memorie și le scriu în mod asincron pe disc.
Distribuția datelor pe o bază de date relațională distribuită (MPP)
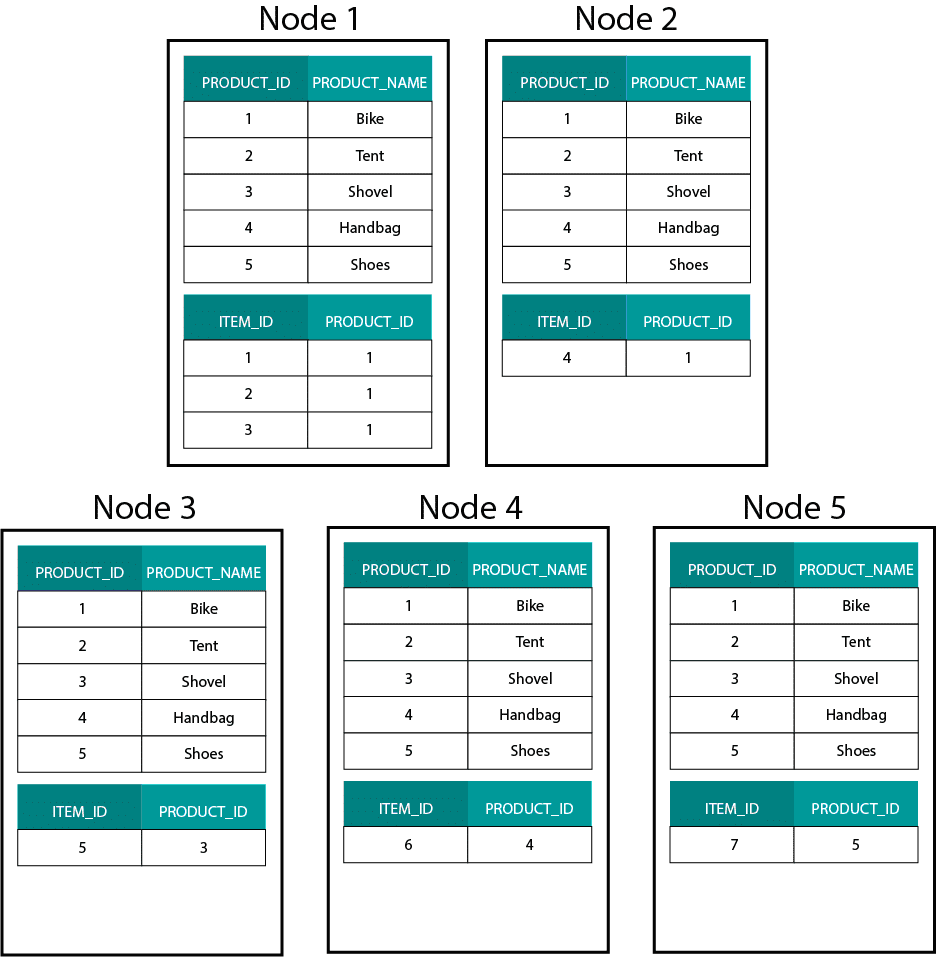
Când creăm modele dimensionale pe Hadoop, de exemplu Hive, SparkSQL etc., trebuie să înțelegem mai bine o caracteristică de bază a tehnologiei care o distinge de o bază de date relațională distribuită (MPP), cum ar fi Teradata etc. Atunci când distribuim datele între nodurile unei MPP, avem control asupra plasării înregistrărilor. În funcție de strategia noastră de partiționare, de exemplu, hash, listă, interval etc., putem colocaliza cheile înregistrărilor individuale în mai multe file de pe același nod. Având garantată co-localitatea datelor, îmbinările noastre sunt super-rapide, deoarece nu trebuie să trimitem date în rețea. Aruncați o privire la exemplul de mai jos. Înregistrările cu același ORDER_ID din tabelele ORDER și ORDER_ITEM ajung pe același nod.
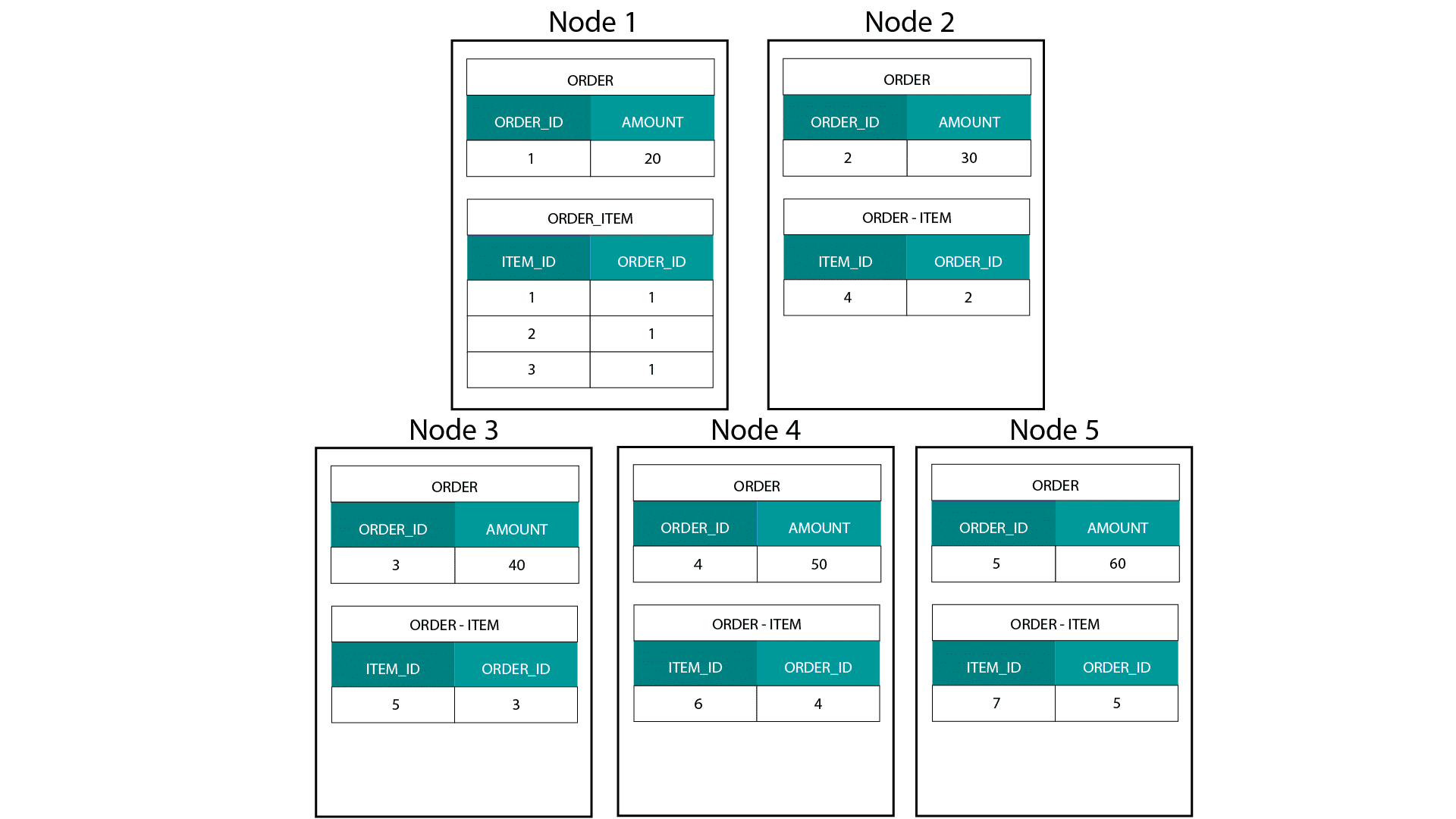
Celele pentru order_id din tabelele order și order_item sunt colocalizate pe aceleași noduri.
Distribuția datelor pe Hadoop
Acest lucru este foarte diferit de sistemele bazate pe Hadoop. Acolo împărțim datele noastre în bucăți de dimensiuni mari și le distribuim și replicăm în nodurile noastre pe sistemul de fișiere distribuite Hadoop (HDFS). Cu această strategie de distribuție a datelor nu putem garanta co-localitatea datelor. Aruncați o privire la exemplul de mai jos. Înregistrările pentru cheia ORDER_ID ajung pe noduri diferite.
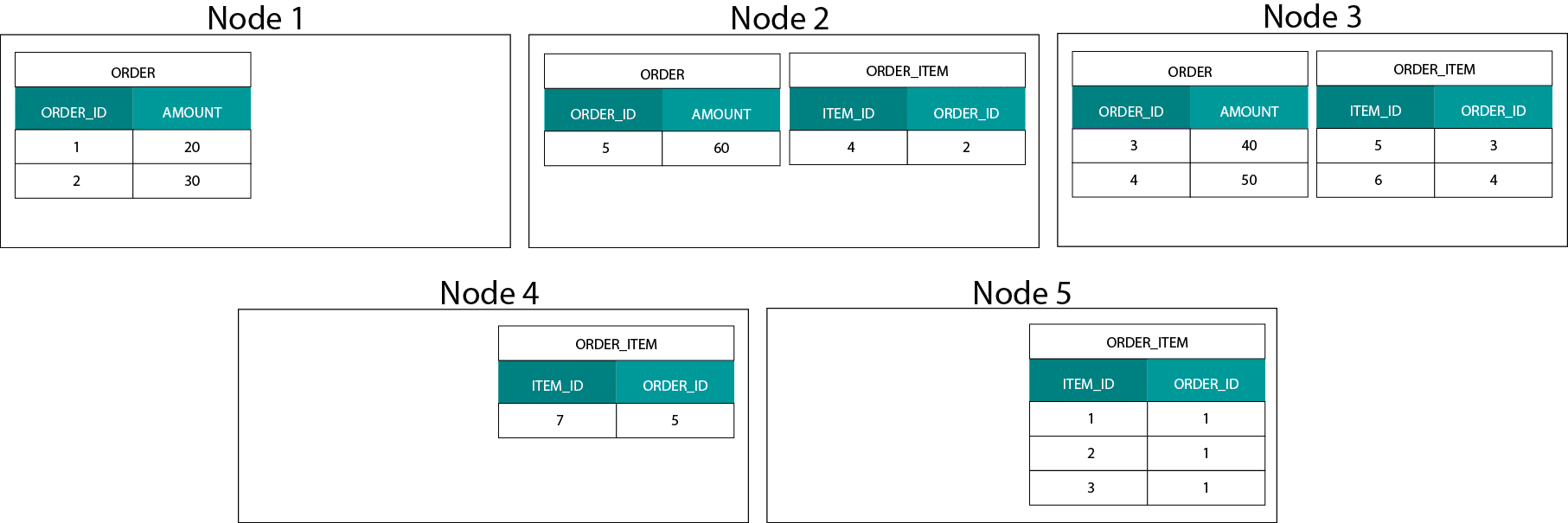
Pentru a ne alătura, trebuie să trimitem date prin rețea, ceea ce are impact asupra performanței.
O strategie de abordare a acestei probleme este replicarea unuia dintre tabelele de alăturare pe toate nodurile din cluster. Acest lucru se numește broadcast join și folosim aceeași strategie pe un MPP. După cum vă puteți imagina, aceasta funcționează numai pentru tabelele de consultare sau de dimensiuni mici.
Atunci, ce facem atunci când avem o tabelă de fapte mare și o tabelă de dimensiuni mare, de exemplu client sau produs? Sau, într-adevăr, atunci când avem două tabele de date mari.
Modele dimensionale pe Hadoop
Pentru a ocoli această problemă de performanță, putem de-normaliza tabelele de dimensiuni mari în tabela de date pentru a garanta că datele sunt colocalizate. Putem difuza tabelele de dimensiuni mai mici în toate nodurile noastre.
Pentru a uni două tabele de date mari, putem anina tabelul cu granularitate mai mică în tabelul cu granularitate mai mare, de exemplu, un tabel ORDER_ITEM mare aninat în tabelul ORDER. Motoarele moderne de interogare, cum ar fi Impala sau Drill, ne permit să aplatizăm aceste date

Această strategie de cuibărire a datelor este, de asemenea, utilă pentru conceptele dureroase ale lui Kimball, cum ar fi tabelele-punte pentru reprezentarea relațiilor M:N într-un model dimensional.
Hadoop și dimensiunile care se schimbă lent
Stocarea pe sistemul de fișiere Hadoop este imuabilă. Cu alte cuvinte, puteți doar să inserați și să adăugați înregistrări. Nu puteți modifica datele. Dacă veniți dintr-un trecut de depozit de date relațional, acest lucru poate părea puțin ciudat la început. Cu toate acestea, sub capotă, bazele de date funcționează într-un mod similar. Ele stochează toate modificările aduse datelor într-un jurnal imuabil de scriere anticipată (cunoscut în Oracle sub numele de redo log) înainte ca un proces să actualizeze în mod asincron datele din fișierele de date.
Ce impact are imuabilitatea asupra modelelor noastre dimensionale? Este posibil să vă amintiți conceptul de dimensiuni cu schimbare lentă (Slowly Changing Dimensions – SCD) de la cursul de modelare dimensională. SCD-urile păstrează opțional istoricul modificărilor aduse atributelor. Acestea ne permit să raportăm măsurătorile în funcție de valoarea unui atribut la un moment dat. Totuși, acesta nu este un comportament implicit. În mod implicit, actualizăm tabelele de dimensiuni cu cele mai recente valori. Deci, care sunt opțiunile noastre pe Hadoop? Nu uitați! Nu putem actualiza datele. Putem pur și simplu să facem din SCD comportamentul implicit și să auditam orice modificări. Dacă dorim să rulăm rapoarte în funcție de valorile actuale, putem crea o vizualizare deasupra SCD care să recupereze doar cea mai recentă valoare. Acest lucru poate fi realizat cu ușurință folosind funcții de fereastră. Alternativ, putem rula un așa-numit serviciu de compactare care creează fizic o versiune separată a tabelului de dimensiuni cu doar cele mai recente valori.
Evoluția stocării pe Hadoop
Aceste limitări Hadoop nu au trecut neobservate de către vânzătorii de platforme Hadoop. În Hive avem acum tranzacții ACID și tabele actualizabile. Pe baza numărului de probleme majore deschise și a propriei mele experiențe, această caracteristică nu pare să fie încă pregătită pentru producție, deși . Cloudera a adoptat o abordare diferită. Cu Kudu, au creat un nou format de stocare actualizabil care nu se află pe HDFS, ci pe sistemul de fișiere local al sistemului de operare. Acesta scapă complet de limitările Hadoop și este similar cu stratul tradițional de stocare dintr-un MPP columnar. În general, probabil că este mai bine să executați orice caz de utilizare a BI și a tablourilor de bord pe un MPP, de exemplu Impala + Kudu, decât pe Hadoop. Acestea fiind spuse, MPP-urile au propriile lor limitări în ceea ce privește reziliența, concurența și scalabilitatea. Atunci când vă confruntați cu aceste limitări, Hadoop și vărul său apropiat Spark sunt opțiuni bune pentru sarcinile de lucru BI. Acoperim toate aceste limitări în cursul nostru de formare Big Data for Data Warehouse Professionals (Date mari pentru profesioniștii în depozite de date) și facem recomandări când să folosiți un RDBMS și când să folosiți SQL pe Hadoop/Spark.
Verdict. Sunt modelele dimensionale și schemele în stea depășite?
Știm cu toții că Ralph Kimball s-a retras. Dar ideile și conceptele sale de principiu sunt încă valabile și continuă să trăiască. Trebuie să le adaptăm pentru noile tehnologii și tipuri de stocare, dar ele încă adaugă valoare.
Învață-mă Big Data pentru a-mi avansa în carieră
Lectură complementară despre modelarea dimensională în era Big Data
Tom Breur: Trecutul și viitorul modelării dimensionale
Edosa Odaro: 5 sfaturi radicale pentru o integrare rapidă a Big Data – Modelul anti Data Warehouse
.