Vă întrebați ce sunt schemele Postgresql și de ce sunt importante și cum puteți folosi schemele pentru a vă face implementările de baze de date mai robuste și mai ușor de întreținut? Acest articol va prezenta elementele de bază ale schemelor în Postgresql și vă va arăta cum să le creați cu câteva exemple de bază. Articolele viitoare vor aprofunda exemple despre cum să securizați și să folosiți schemele pentru aplicații reale.
În primul rând, pentru a clarifica o potențială confuzie terminologică, să înțelegem că în lumea Postgresql, termenul „schemă” este poate, din păcate, oarecum supraîncărcat. În contextul mai larg al sistemelor de gestionare a bazelor de date relaționale (RDBMS), termenul „schemă” ar putea fi înțeles ca referindu-se la designul general logic sau fizic al bazei de date, adică la definirea tuturor tabelelor, coloanelor, vederilor și a altor obiecte care constituie definiția bazei de date. În acest context mai larg, o schemă ar putea fi exprimată într-o diagramă entitate-relație (ER) sau într-un script de instrucțiuni de limbaj de definire a datelor (DDL) utilizate pentru a instanția baza de date a aplicației.
În lumea Postgresql, termenul „schemă” ar putea fi mai bine înțeles ca un „namespace”. De fapt, în tabelele sistemului Postgresql, schemele sunt înregistrate în coloane de tabel numite „spațiu de nume”, ceea ce, IMHO, este o terminologie mai exactă. Ca o chestiune practică, ori de câte ori văd „schema” în contextul Postgresql, o reinterpretez în tăcere ca spunând „spațiu de nume”.
Dar poate vă întrebați: „Ce este un spațiu de nume?”. În general, un spațiu de nume este un mijloc destul de flexibil de organizare și identificare a informațiilor prin nume. De exemplu, imaginați-vă două gospodării vecine, familia Smiths, Alice și Bob, și familia Jones, Bob și Cathy (cf. figura 1). Dacă am folosi doar prenumele, s-ar putea crea confuzie cu privire la ce persoană ne referim atunci când vorbim despre Bob. Dar prin adăugarea numelui de familie, Smith sau Jones, identificăm în mod unic la ce persoană ne referim.
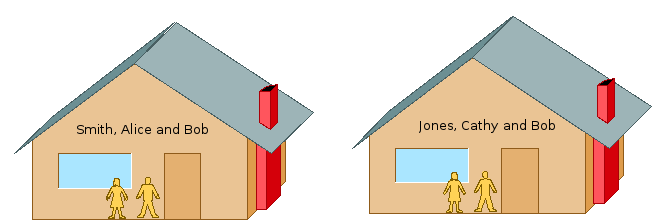
De multe ori, spațiile de nume sunt organizate într-o ierarhie imbricata. Acest lucru permite clasificarea eficientă a unor cantități mari de informații într-o structură foarte fină, cum ar fi, de exemplu, sistemul de nume de domenii de internet. La nivelul superior, „.com”, „.net”, „.org”, „.edu”, etc. definesc spații de nume largi în cadrul cărora sunt înregistrate nume pentru entități specifice, astfel încât, de exemplu, „severalnines.com” și „postgresql.org” sunt definite în mod unic. Dar sub fiecare dintre acestea există un număr de subdomenii comune, cum ar fi „www”, „mail” și „ftp”, de exemplu, care singure sunt duplicate, dar în cadrul spațiilor de nume respective sunt unice.
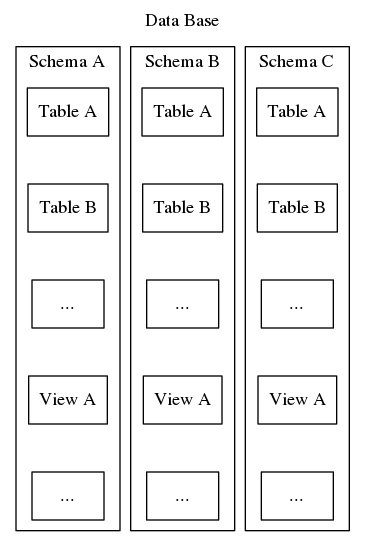
Schemele Postgresql servesc aceluiași scop de organizare și identificare, însă, spre deosebire de cel de-al doilea exemplu de mai sus, schemele Postgresql nu pot fi imbricate într-o ierarhie. Deși o bază de date poate conține mai multe scheme, există întotdeauna un singur nivel și, prin urmare, în cadrul unei baze de date, numele schemelor trebuie să fie unice. De asemenea, fiecare bază de date trebuie să includă cel puțin o schemă. Ori de câte ori se instanțiază o nouă bază de date, se creează o schemă implicită numită „public”. Conținutul unei scheme include toate celelalte obiecte ale bazei de date, cum ar fi tabele, vizualizări, proceduri stocate, declanșatori etc. Pentru a vizualiza, consultați figura 2, care descrie o imbricație asemănătoare unei păpuși matrioșka care arată unde se încadrează schemele în structura unei baze de date Postgresql.
Pe lângă simpla organizare a obiectelor bazei de date în grupuri logice pentru a le face mai ușor de gestionat, schemele au scopul practic de a evita coliziunea de nume. O paradigmă operațională implică definirea unei scheme pentru fiecare utilizator al bazei de date, astfel încât să asigure un anumit grad de izolare, un spațiu în care utilizatorii își pot defini propriile tabele și vizualizări fără a interfera unii cu alții. O altă abordare constă în instalarea unor instrumente terțe sau a unor extensii ale bazei de date în schemele individuale, astfel încât toate componentele aferente să rămână împreună din punct de vedere logic. Un articol ulterior din această serie va detalia o abordare nouă a proiectării robuste a aplicațiilor, utilizând schemele ca mijloc de indirection pentru a limita expunerea proiectării fizice a bazei de date și pentru a prezenta în schimb o interfață utilizator care rezolvă cheile sintetice și facilitează întreținerea pe termen lung și gestionarea configurației pe măsură ce cerințele sistemului evoluează.
Să facem niște cod!
Cea mai simplă comandă pentru a crea o schemă în cadrul unei baze de date este
CREATE SCHEMA hollywood;Această comandă necesită privilegii de creare în baza de date, iar schema nou-creată „hollywood” va fi deținută de utilizatorul care invocă comanda. O invocare mai complexă poate include elemente opționale care să specifice un proprietar diferit și poate include chiar instrucțiuni DDL care să instanțieze obiecte ale bazei de date în cadrul schemei, toate într-o singură comandă!
Formul general este
CREATE SCHEMA schemaname ]unde „username” este cine va deține schema, iar „schema_element” poate fi una dintre anumite comenzi DDL (consultați documentația Postgresql pentru detalii). Sunt necesare privilegii de superutilizator pentru a utiliza opțiunea AUTHORIZATION.
Așa că, de exemplu, pentru a crea o schemă numită „hollywood” care să conțină o tabelă numită „films” și o vizualizare numită „winners” într-o singură comandă, ați putea face
CREATE SCHEMA hollywood CREATE TABLE films (title text, release date, awards text) CREATE VIEW winners AS SELECT title, release FROM films WHERE awards IS NOT NULL;Obiectele suplimentare ale bazei de date pot fi create ulterior în mod direct, de exemplu, o tabelă suplimentară ar fi adăugată la schemă cu
CREATE TABLE hollywood.actors (name text, dob date, gender text);Rețineți în exemplul de mai sus prefixarea numelui tabelei cu numele schemei. Acest lucru este necesar deoarece, în mod implicit, adică fără o specificație explicită a schemei, noile obiecte ale bazei de date sunt create în cadrul oricărei scheme curente, pe care o vom aborda în continuare.
Reamintiți-vă cum în primul exemplu de spațiu de nume de mai sus, aveam două persoane numite Bob și am descris cum să le deconflictualizăm sau să le distingem prin includerea numelui de familie. Dar în cadrul fiecărei gospodării Smith și Jones în parte, fiecare familie înțelege că „Bob” se referă la cel care merge cu gospodăria respectivă. Astfel, de exemplu, în contextul fiecărei gospodării respective, Alice nu trebuie să se adreseze soțului ei ca Bob Jones, iar Cathy nu trebuie să se refere la soțul ei ca Bob Smith: fiecare dintre ele poate spune doar „Bob”.
Schema curentă Postgresql este un fel de gospodărie în exemplul de mai sus. Obiectele din schema curentă pot fi referite necalificate, dar referirea la obiecte cu nume asemănător din alte scheme necesită calificarea numelui prin prefixarea numelui schemei ca mai sus.
Schema curentă este derivată din parametrul de configurare „search_path”. Acest parametru stochează o listă de nume de scheme separate prin virgulă și poate fi examinat cu comanda
SHOW search_path;sau setat la o nouă valoare cu
SET search_path TO schema ;Primul nume de schemă din listă este „schema curentă” și este cea în care sunt create obiectele noi dacă este specificat fără calificarea numelui schemei.
Lista de nume de scheme separate prin virgulă servește, de asemenea, pentru a determina ordinea de căutare prin care sistemul localizează obiectele existente cu nume necalificat. De exemplu, revenind la cartierul Smith și Jones, o livrare de pachete adresată doar lui „Bob” ar necesita vizitarea fiecărei gospodării până la găsirea primului locuitor cu numele „Bob”. Rețineți că este posibil ca acesta să nu fie destinatarul. Aceeași logică se aplică pentru Postgresql. Sistemul caută tabelele, vizualizările și alte obiecte din cadrul schemelor în ordinea din search_path, iar apoi se utilizează primul obiect găsit care se potrivește cu numele. Obiectele cu nume calificat de schemă sunt utilizate direct, fără a se face referire la search_path.
În configurația implicită, interogarea variabilei de configurare search_path relevă această valoare
SHOW search_path; Search_path-------------- "$user", publicSistemul interpretează prima valoare prezentată mai sus ca fiind numele actual al utilizatorului conectat și se adaptează la cazul de utilizare menționat anterior, în care fiecărui utilizator i se alocă o schemă cu nume de utilizator pentru un spațiu de lucru separat de ceilalți utilizatori. Dacă nu a fost creată o astfel de schemă cu nume de utilizator, această intrare este ignorată și schema „public” devine schema curentă în care sunt create noi obiecte.
Așa, revenind la exemplul nostru anterior de creare a tabelului „hollywood.actors”, dacă nu am fi calificat numele tabelului cu numele schemei, atunci tabelul ar fi fost creat în schema publică. Dacă am anticipat crearea tuturor obiectelor în cadrul unei scheme specifice, atunci ar putea fi convenabil să setați variabila search_path, cum ar fi
SET search_path TO hollywood,public;facilitarea stenogramei de tastare a numelor necalificate pentru a crea sau accesa obiectele bazei de date.
Există, de asemenea, o funcție de informații de sistem care returnează schema curentă cu o interogare
select current_schema();În caz de îngrădire a ortografiei, proprietarul unei scheme poate schimba numele, cu condiția ca utilizatorul să aibă și privilegii de creare pentru baza de date, cu
ALTER SCHEMA old_name RENAME TO new_name;Și, în cele din urmă, pentru a șterge o schemă dintr-o bază de date, există o comandă drop
DROP SCHEMA schema_name;Comanda DROP va eșua dacă schema conține obiecte, deci acestea trebuie șterse mai întâi, sau, opțional, puteți șterge recursiv o schemă cu tot conținutul său cu opțiunea CASCADE
DROP SCHEMA schema_name CASCADE;Aceste noțiuni de bază vă vor ajuta să începeți să înțelegeți schemele!