- Funcția și derivata sa sunt ambele monotone
- Scopul este zero „centrat”
- Optimizarea este mai ușoară
- Derivata /Diferențiala funcției Tanh (f'(x)) va fi cuprinsă între 0 și 1.
Cons:
- Derivata funcției Tanh suferă de „problema gradientului care dispare și a gradientului care explodează”.
- Convergență lentă – deoarece este greu de calculat.(Motivul utilizării funcției matematice exponențiale )
„Tanh este preferată funcției sigmoide deoarece este centrată pe zero și gradienții nu sunt restricționați să se deplaseze într-o anumită direcție”
3. Funcția de activare ReLu (ReLu – unități liniare rectificate):


ReLU este funcția de activare neliniară care a câștigat popularitate în IA. Funcția ReLu este, de asemenea, reprezentată ca f(x) = max(0,x).
- Funcția și derivata sa sunt ambele monotone.
- Principalul avantaj al utilizării funcției ReLU- Nu activează toți neuronii în același timp.
- Eficientă din punct de vedere computațional
- Derivata /Diferențiala funcției Tanh (f'(x)) va fi 1 dacă f(x) > 0 altfel 0.
- Converge foarte repede
Cons:
- Funcția ReLu nu este „zero-centrică”.Aceasta face ca actualizările gradientului să meargă prea departe în direcții diferite. 0 < ieșire < 1, și face ca optimizarea să fie mai dificilă.
- Neuronul mort este cea mai mare problemă. aceasta se datorează faptului că nu este diferențiabilă la zero.
„Problema neuronului care moare/neuronului mort : Deoarece derivata ReLu f'(x) nu este 0 pentru valorile pozitive ale neuronului (f'(x)=1 pentru x ≥ 0), ReLu nu se saturează (explodează) și nu se raportează neuroni morți (Vanishing neuron)-ul. Saturarea și gradientul vanishing apar numai pentru valori negative care, date lui ReLu, se transformă în 0- Aceasta se numește problema neuronului muribund.”
4. Funcția de activare ReLu cu scurgeri:
Funcția ReLU cu scurgeri nu este altceva decât o versiune îmbunătățită a funcției ReLU cu introducerea „pantei constante”


- Leaky ReLU este definit pentru a aborda problema neuronilor muribunzi/neuroni morți.
- Problema neuronului muribund/neuron mort este abordată prin introducerea unei pante mici având valorile negative scalate cu α permite neuronilor corespunzători să „rămână în viață”.
- Funcția și derivata sa sunt ambele monotone
- Amestecă valoarea negativă în timpul propagării înapoi
- Este eficientă și ușor de calculat.
- Derivata lui Leaky este 1 când f(x) > 0 și variază între 0 și 1 când f(x) < 0.
Cons:
- Leaky ReLU nu oferă predicții consistente pentru valori de intrare negative.
5. Funcția de activare ELU (Exponential Linear Units):

- ELU este, de asemenea, propus pentru a rezolva problema neuronilor muribunzi.
- Nu există probleme legate de ReLU mort
- Centrică pe zero
Cons:
- Computere intensivă.
- Similar cu Leaky ReLU, deși teoretic este mai bun decât ReLU, nu există în prezent dovezi bune în practică că ELU este întotdeauna mai bun decât ReLU.
- f(x) este monoton doar dacă alfa este mai mare sau egal cu 0.
- f'(x) derivata lui ELU este monotonă numai dacă alfa este cuprinsă între 0 și 1.
- Convergență lentă datorită funcției exponențiale.
6. P ReLu (ReLU parametric) Funcția de activare:

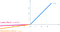
- Ideea de ReLU cu scurgeri poate fi extinsă și mai mult.
- În loc să înmulțim x cu un termen constant, îl putem înmulți cu un „hiperparametru (parametru a-antrenabil)” care pare să funcționeze mai bine leaky ReLU. Această extensie la ReLU cu scurgeri este cunoscută sub numele de ReLU parametric.
- Parametrul α este în general un număr între 0 și 1, și este în general relativ mic.
- Are un ușor avantaj față de ReLU cu scurgeri datorită parametrului antrenabil.
- Ajută la problema neuronilor muribunzi.
Cons:
- La fel ca și Relu cu scurgeri.
- f(x) este monotonă când a> sau =0 și f'(x) este monotonă când a =1
7. Funcția de activare Swish (o funcție de activare cu autogenerare): (Sigmoid Linear Unit)

- Google Brain Team a propus o nouă funcție de activare, numită Swish, care este pur și simplu f(x) = x – sigmoid(x).
- Experimentele lor arată că Swish tinde să funcționeze mai bine decât ReLU pe modele mai profunde pe o serie de seturi de date dificile.
- Curba funcției Swish este netedă și funcția este diferențiabilă în toate punctele. Acest lucru este util în timpul procesului de optimizare a modelului și este considerat a fi unul dintre motivele pentru care Swish depășește ReLU.
- Funcția Swish nu este „monotonă”. Acest lucru înseamnă că valoarea funcției poate scădea chiar și atunci când valorile de intrare sunt în creștere.
- Funcția este nemărginită în sus și mărginită în jos.
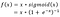
„Swish tinde să egaleze sau să surclaseze continuu ReLu”
Rețineți că valoarea de ieșire a funcției swish poate scădea chiar și atunci când valorile de intrare cresc. Aceasta este o caracteristică interesantă și specifică swish. (Datorită caracterului nemonotonic)
f(x)=2x*sigmoid(beta*x)
Dacă ne gândim că beta=0 este o versiune simplă a lui Swish, care este un parametru care poate fi învățat, atunci partea sigmoidă este întotdeauna 1/2 și f (x) este liniară. Pe de altă parte, dacă beta este o valoare foarte mare, sigmoidul devine o funcție cu aproape două cifre (0 pentru x<0,1 pentru x>0). Astfel, f (x) converge la funcția ReLU. Prin urmare, funcția Swish standard este selectată ca fiind beta = 1. În acest fel, se asigură o interpolare soft (asocierea seturilor de valori variabile cu o funcție în intervalul dat și cu precizia dorită). Excelent! A fost găsită o soluție la problema dispariției gradienților.
8.Softplus
Funcția softplus este similară funcției ReLU, dar este relativ mai lină.Funcția Softplus sau SmoothRelu f(x) = ln(1+exp x).
Derivata funcției Softplus este f'(x) este funcția logistică (1/(1+exp x)).
Valoarea funcției variază între (0, + inf).Atât f(x) cât și f'(x) sunt monotone.
9.Softmax sau funcția exponențială normalizată:

Funcția „softmax” este, de asemenea, un tip de funcție sigmoidală, dar este foarte utilă pentru a gestiona probleme de clasificare multiclasă.
„Softmax poate fi descrisă ca fiind combinația mai multor funcții sigmoidale.”
„Funcția Softmax returnează probabilitatea ca un punct de date să aparțină fiecărei clase individuale.”
În timp ce se construiește o rețea pentru o problemă cu mai multe clase, stratul de ieșire va avea atâția neuroni cât numărul de clase din țintă.
De exemplu, dacă aveți trei clase, vor fi trei neuroni în stratul de ieșire. Să presupunem că ați obținut ieșirea de la neuroni ca .Aplicând funcția softmax peste aceste valori, veți obține următorul rezultat – . Acestea reprezintă probabilitatea ca punctul de date să aparțină fiecărei clase. Din rezultat reiese că intrarea aparține clasei A.
„Observați că suma tuturor valorilor este 1.”
Ce este mai bine să folosim? Cum să o alegem pe cea corectă?
Pentru a fi sincer, nu există o regulă dură și rapidă pentru a alege funcția de activare.Nu putem face diferențe între funcțiile de activare.Fiecare funcție de activare are avantajele și dezavantajele sale.Toate bunele și relele vor fi decise pe baza traseului.
Dar pe baza proprietăților problemei am putea face o alegere mai bună pentru o convergență ușoară și mai rapidă a rețelei.
- Funcțiile sigmoide și combinațiile lor funcționează în general mai bine în cazul problemelor de clasificare
- Funcțiile sigmoide și tanh sunt uneori evitate din cauza problemei gradientului de dispariție
- Funcția de activare ReLU este utilizată pe scară largă în epoca modernă.
- În cazul neuronilor morți în rețelele noastre din cauza funcției ReLU, atunci funcția ReLU cu scurgeri este cea mai bună alegere
- Funcția ReLU ar trebui să fie utilizată numai în straturile ascunse
„Ca regulă generală, se poate începe cu utilizarea funcției ReLU și apoi se poate trece la alte funcții de activare în cazul în care ReLU nu oferă rezultate optime”
.