Revizuit: 11 decembrie 2020
Sunt subiecții cei care spun adevărul?
Fiabilitatea datelor de auto-raportare este un călcâi al lui Ahile al cercetării prin sondaj. De exemplu, sondajele de opinie au indicat că mai mult de 40 la sută dintre americani merg la biserică în fiecare săptămână. Cu toate acestea, examinând registrele de prezență la biserică, Hadaway și Marlar (2005) au concluzionat că prezența reală a fost mai mică de 22 la sută. În lucrarea sa de referință „Everybody lies” (Toată lumea minte), Seth Stephens-Davidowitz (2017) a găsit numeroase dovezi care să arate că majoritatea oamenilor nu fac ceea ce spun și nu spun ceea ce fac. De exemplu, ca răspuns la sondaje, majoritatea alegătorilor au declarat că etnia candidatului nu este importantă. Cu toate acestea, verificând termenii de căutare în Google, Sephens-Davidowitz a constatat contrariul.Mai exact, atunci când utilizatorii Google au introdus cuvântul „Obama”, aceștia au asociat întotdeauna numele acestuia cu unele cuvinte legate de rasă.
Pentru cercetări privind instruirea bazată pe web, datele de utilizare a web-ului pot fi obținute prin analiza jurnalului de acces al utilizatorului, prin setarea cookie-urilor sau prin încărcarea cache-ului. Cu toate acestea, aceste opțiuni pot avea o aplicabilitate limitată. De exemplu, jurnalul de acces al utilizatorului nu poate urmări utilizatorii care urmează linkuri către alte site-uri web. În plus, abordările bazate pe cookie-uri sau pe memoria cache pot ridica probleme de confidențialitate. În aceste situații, se utilizează date auto-raportate colectate prin sondaje. Acest lucru dă naștere la o întrebare: Cât de precise sunt datele auto-raportate? Cook și Campbell (1979) au subliniat faptul că subiecții (a) tind să raporteze ceea ce cred că cercetătorul se așteaptă să vadă sau (b) raportează ceea ce reflectă în mod pozitiv propriile abilități, cunoștințe, credințe sau opinii. O altă preocupare cu privire la astfel de date se referă la capacitatea subiecților de a-și aminti cu exactitate comportamentele anterioare. Psihologii au avertizat că memoria umană este failibilă(Loftus, 2016; Schacter, 1999). Uneori, oamenii își „amintesc” evenimente care nu s-au întâmplat niciodată. Astfel, fiabilitatea datelor auto-raportate este fragilă.Deși pachetele de software statistic sunt capabile să calculeze numere de până la 16-32 de zecimale, această precizie este lipsită de sens dacă datele nu pot fi exacte nici măcar la nivel de numere întregi. Destul de mulți savanți au avertizat cercetătorii asupra modului în care eroarea de măsurare ar putea paraliza analiza statistică (Blalock, 1974) și au sugerat că o bună practică de cercetare necesită examinarea calității datelor colectate (Fetter,Stowe, & Owings, 1984).
Bias și varianță
Erorile de măsurare includ două componente, și anume, bias și eroare variabilă.Biasul este o eroare sistematică care tinde să împingă scorurile raportate spre un capăt extrem. De exemplu, s-a constatat că mai multe versiuni ale testelor IQ sunt părtinitoare față de cei care nu sunt albi. Aceasta înseamnă că negrii și hispanicii tind să primească scoruri mai mici, indiferent de inteligența lor reală. Eroarea variabilă, cunoscută și sub numele de varianță, tinde să fie aleatorie. Cu alte cuvinte, scorurile raportate ar putea fi fie peste, fie sub scorurile reale (Salvucci, Walter, Conley, Fink, & Saba, 1997).
Constatările acestor două tipuri de erori de măsurare au diferiteimplicații. De exemplu, într-un studiu care a comparat datele autodeclarate privind înălțimea și greutatea cu datele măsurate direct (Hart & Tomazic, 1999),s-a constatat că subiecții au tendința de a-și supradeclara înălțimea, dar de a-și subdeclara greutatea. În mod evident, acest tip de model de eroare este mai degrabă eroare decât varianță. O posibilă explicație a acestei prejudecăți este cămajoritatea persoanelor doresc să prezinte o imagine fizică mai bună celorlalți. Cu toate acestea, dacă eroarea de măsurare este aleatorie, explicația poate fi mai complicată.
Se poate argumenta că erorile variabile, care sunt de natură aleatorie, s-ar anula reciproc și, prin urmare, ar putea să nu reprezinte o amenințare pentru studiu. De exemplu, este posibil ca primul utilizator să își supraestimeze activitățile pe internet cu 10%, dar al doilea utilizator să le subestimeze pe ale sale cu 10%. În acest caz, este posibil ca media să fie totuși corectă. Cu toate acestea, supraestimarea și subestimarea cresc variabilitatea distribuției. În multe teste parametrice, variabilitatea în interiorul grupului este utilizată ca termen de eroare. O variabilitate umflată ar afecta cu siguranță semnificația testului. Unele texte pot întări concepția eronată de mai sus. De exemplu, Deese (1972) a spus,
Teoria statistică ne spune că fiabilitatea observațiilor este proporțională cu rădăcina pătrată a numărului lor. Cu cât sunt mai multe observații, cu atât mai multă influență aleatorie va exista. Iar teoria statistică susține că, cu cât sunt mai multe erori aleatoare, cu atât este mai probabil ca acestea să se anuleze reciproc și să producă o distribuție anormală (p.55).
În primul rând, este adevărat că, pe măsură ce mărimea eșantionului crește, varianța distribuției scade, aceasta nu garantează că forma distribuției se va apropia de normalitate. În al doilea rând, fiabilitatea (calitatea datelor) ar trebui să fie legată de măsurare mai degrabă decât de determinarea dimensiunii eșantionului. O dimensiune mare a eșantionului cu o mulțime de erori de măsurare, chiar și erori aleatorii, ar umfla termenul de eroare pentru testele parametrice.
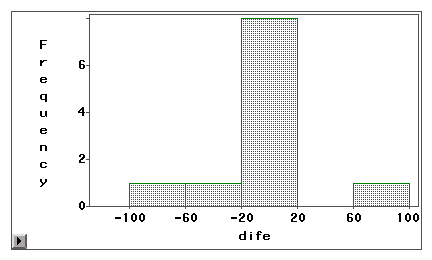
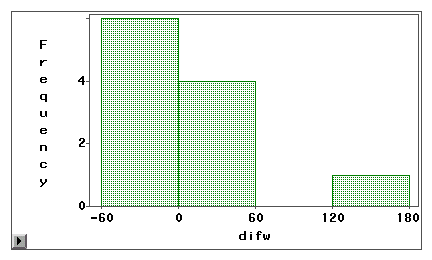
Un grafic stem-and-leaf sau o histogramă poate fi folosit pentru a examina vizual dacă o eroare de măsurare se datorează unei distorsiuni sistematice sau unei varianțe aleatorii. În exemplul următor, două tipuri de acces la internet (navigare pe web și e-mail) sunt măsurate atât prin sondaj autodeclarat, cât și prin jurnalul de bord. Scorurile de diferență (măsurarea 1 – măsurarea 2) sunt reprezentate grafic în următoarele histograme.
Primul grafic relevă faptul că majoritatea scorurilor de diferență sunt centrate în jurul valorii de zero. Subdeclararea și supradeclararea apar în apropierea ambelor capete sugerează că eroarea de măsurare este o eroare aleatorie mai degrabă decât o prejudecată sistematică.
Cel de-al doilea grafic indică în mod clar că există un grad ridicat de erori de măsurare deoarece foarte puține scoruri de diferență sunt centrate în jurul valorii de zero. Mai mult decât atât, distribuția este înclinată negativ și astfel eroarea este o prejudecată în loc de varianță.
Cât de fiabilă este memoria noastră?
Schacter (1999) a avertizat că memoria umană este failibilă. Există șapte defecte ale memoriei noastre:
- Tranzitivitatea: Scăderea accesibilității informațiilor în timp.
- Absenteismul: Procesare neatentă sau superficială care contribuie la amintiri slabe.
- Blocaj: Inaccesibilitatea temporară a informațiilor care sunt stocate în memorie.
- Atribuire greșită Atribuirea unei amintiri sau idei unei surse greșite.
- Sugestibilitate: Amintiri care sunt implantate ca urmare a unor întrebări sau așteptări sugestive.
- Bias: Distorsiuni retrospective și influențe inconștiente care sunt legate de cunoștințele și convingerile actuale.
- Persistență: Amintiri patologice-informații sau evenimente pe care nu le putem uita, chiar dacă ne-am dori să putem.
 |
„Nu am nici o amintire despre acestea. Nu-mi amintesc că am semnat documentul pentruWhitewater. Nu-mi amintesc de ce a dispărut documentul, dar a reapărut mai târziu. Nu-mi amintesc nimic.” „Îmi amintesc că am aterizat (în Bosnia) sub focul lunetiștilor. Trebuia să fie un fel de ceremonie de întâmpinare la aeroport, dar în schimb am alergat cu capul plecat pentru a ne urca în vehicule pentru a ajunge la baza noastră.” În timpul anchetei privind trimiterea de informații clasificate prin intermediul unui server personal de e-mail, Clinton a declarat FBI că nu-și poate „aminti” sau „aminti” nimic de 39 de ori. Atenție: A fost descoperit un nou virus informatic numit „Clinton”. Dacă computerul este infectat, va apărea frecvent acest mesaj „out of memory” (fără memorie), chiar dacă are o memorie RAM adecvată. |
| Întrebare: „Dacă Vernon Jordon ne-a spus că aveți o memorie extraordinară, una dintre cele mai mari memorii pe care le-a văzut vreodată la un politician, ar fi acesta un lucru pe care ați dori să-l contestați?”
R: „Am o memorie bună…Dar nu-mi amintesc dacă am fost singur cu Monica Lewinsky sau nu. Cum aș putea să țin evidența atâtor femei din viața mea?” Întrebare: De ce Clinton a recomandat-o pe Lewinsky pentru un loc de muncă la Revlon? A: El știa că ea ar fi bună la inventat lucruri. |
 |
Este important de reținut că, uneori, fiabilitatea memoriei noastre este legată de caracterul dezirabil al rezultatului. De exemplu, atunci când un cercetător medical încearcă să colecteze date relevante de la mame ai căror copii sunt sănătoși și de la mame ai căror copii sunt malformați, datele de la cele din urmă sunt de obicei mai precise decât cele de la primele. Acest lucru se datorează faptului cămamele cu copii malformați au trecut în revistă cu atenție fiecare boală care a apărut în timpul sarcinii, fiecare medicament luat, fiecare detaliu legat direct sau de la distanță de tragedie în încercarea de a găsi o explicație. Dimpotrivă, mamele bebelușilor sănătoși nu acordă prea multă atenție informațiilor precedente (Aschengrau & SeageIII, 2008). Umflarea GPA este un alt exemplu al modului în care dezirabilitateaafectează acuratețea memoriei și integritatea datelor. În unele situații existăo diferență de gen în ceea ce privește umflarea GPA. Un studiu realizat de Caskie etal. (2014) a constatat că, în cadrul grupului de studenți cu GPA mai mică, femeile au fost mai predispuse decât bărbații să raporteze o GPA mai mare decât cea reală.
Pentru a contracara problema erorilor de memorie, unii cercetători au sugerat colectarea de date legate de gândul sau sentimentul de moment al participantului, mai degrabă decât să îi ceară acestuia să își amintească evenimente îndepărtate (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Următoarele exemple sunt itemi de sondaj din Programul pentru Evaluarea Internațională a Elevilor 2018: „Ați fost tratat cu respect în toată ziua de ieri?”. „Ați zâmbit sau ați râs mult ieri?”. „Ați învățat sau ați făcut ceva interesant ieri?”. (Organisation forEconomic Cooperation and Development, 2017). Cu toate acestea, răspunsuldepinde de ceea ce i s-a întâmplat participantului în jurul acelui anumit moment, ceea ce ar putea să nu fie tipic. Mai exact, chiar dacă respondentul nu a zâmbit sau nu a râs mult ieri, acest lucru nu implică în mod necesar faptul că respondentul este întotdeauna nefericit.
Ce să facem?
Câțiva cercetători resping utilizarea datelor auto-raportate din cauza presupusei calități slabe a acestora. De exemplu, atunci când un grup de cercetători a investigat dacă religiozitatea ridicată a dus la o mai mică aderență la directivele de adăpostire în SUA în timpul pandemiei COVID19, aceștia au folosit numărul de congregații la 10.000 de locuitori ca măsură indirectă a religiozității din regiune, în loc de religiozitatea auto-raportată, care tinde să reflecte dezirabilitatea socială (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Cu toate acestea, Chan (2009) a susținut că așa-numita calitate slabă a datelor auto-raportate nu este nimic mai mult decât o legendă urbană. Conduși de dorința socială, respondenții ar putea furniza cercetătorilor date inexacte în unele ocazii, dar acest lucru nu se întâmplă tot timpul. De exemplu, este puțin probabil ca respondenții să mintă cu privire la datele lor demografice, cum ar fi sexul și etnia. În al doilea rând, deși este adevărat că respondenții au tendința de a-și falsifica răspunsurile în studiile experimentale, această problemă este mai puțin gravă în cazul măsurilor utilizate în studiile de teren și în mediile naturaliste. Mai mult, există numeroase măsuri bine stabilite de autoevaluare a diferitelor construcții psihologice, care au obținut dovezi de validitate a construcției atât prin validare convergentă, cât și discriminantă. De exemplu, trăsăturile de personalitate Big-five, personalitatea proactivă, dispoziția afectivă, autoeficacitatea, orientările de scop, sprijinul organizațional perceput și multe altele.În domeniul epidemiologiei, Khoury, James și Erickson (1994) au afirmatcă efectul prejudecății de reamintire este supraevaluat. Dar concluzia lor s-ar putea să nu fie bine aplicată în alte domenii, cum ar fi educația și psihologia. în ciuda amenințării de inexactitate a datelor, este imposibil pentru cercetător să urmărească fiecare subiect cu o cameră video și să înregistreze tot ceea ce face. Cu toate acestea, cercetătorul poate folosi un subset de subiecți pentru a obține date observate, cum ar fi jurnalul de acces al utilizatorului sau jurnalul zilnic pe suport de hârtie al accesului la web. Rezultatele vor fi apoi comparate cu rezultatul datelor autodeclarate de toți subiecții¹ pentru o estimare a erorii de măsurare.De exemplu,
- Când jurnalul de acces al utilizatorului este la dispoziția cercetătorului, acesta poate cere subiecților să raporteze frecvența cu care accesează serverul web.Subiecții nu ar trebui să fie informați că activitățile lor pe internet au fost înregistrate de către webmaster, deoarece acest lucru poate afecta comportamentul participanților.
- cercetătorul poate cere unui subset de utilizatori să țină un jurnal al activităților lor pe internet timp de o lună. După aceea, aceiașiutilizatori sunt rugați să completeze un sondaj cu privire la utilizarea lor pe internet.
Cineva poate argumenta că abordarea cu jurnalul de bord este prea solicitantă. Într-adevăr,în multe studii de cercetare științifică, subiecților li se cere mult mai mult decât atât. De exemplu, atunci când oamenii de știință au studiat modul în care somnul profund în timpul călătoriilor spațiale pe distanțe lungi ar afecta sănătatea umană, participanților li s-a cerut să stea în pat timp de o lună. Într-un studiu privind modul în care un mediu închis afectează psihologia umană în timpul călătoriei în spațiu, subiecții au fost, de asemenea, închiși individual într-o cameră timp de o lună. Este nevoie de un cost ridicat pentru a căuta adevăruri științifice.
După ce se colectează diferite surse de date, discrepanța dintre jurnalul de bord și datele raportate poate fi analizată pentru a estima fiabilitatea datelor. La prima vedere, această abordare seamănă cu un test-retest de fiabilitate, dar nu este așa. În primul rând, în cazul fiabilității test-retest, instrumentul utilizat în două sau mai multe situații trebuie să fie același. În al doilea rând, atunci când fiabilitatea test-retest este scăzută, sursa erorilor se află în interiorul instrumentului. Cu toate acestea, atunci când sursa erorilor este externă instrumentului, cum ar fi erorile umane, fiabilitatea inter-evaluator este mai adecvată.
Procedura sugerată mai sus poate fi conceptualizată ca o măsurare a fiabilității între date, care seamănă cu cea a fiabilității inter-evaluator și a măsurilor repetate. Există patru modalități de estimare a fiabilității inter-rater, și anume, coeficientul Kappa, indicele de inconsecvență,ANOVA cu măsuri repetate și analiza de regresie. Următoarea secțiunedescrie modul în care aceste măsurători ale fiabilității inter-evaluatori pot fi utilizate ca măsurători ale fiabilității între date.
Coeficientul Kappa
În cercetările psihologice și educaționale, nu este neobișnuit să se utilizeze doi sau mai mulți evaluatori în procesul de măsurare a temei atunci când evaluarea implică judecăți subiective (de exemplu, notarea eseurilor). Fiabilitatea între evaluatori, care se măsoară prin coeficientul Kappa, este utilizată pentru a indica fiabilitatea datelor.De exemplu, performanța participanților este evaluată de doi sau mai mulți evaluatori ca fiind „maestru” sau „non-maestru” (1 sau 0). Astfel, această măsurătoare este de obicei calculată în procedurile de analiză a datelor categorice, cum ar fi PROC FREQ în SAS, „măsurarea acordului” în SPSS sau calculatorul Kappa anonline (Lowry, 2016). Imaginea de mai jos este o captură de ecran a calculatorului online Vassarstats.
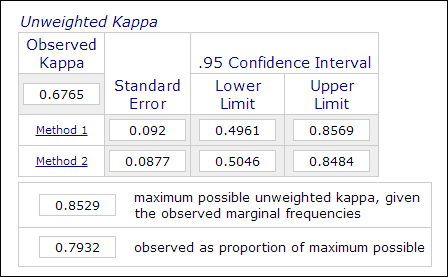
Este important de reținut că, chiar dacă 60 la sută din două seturi de date concordă unul cu celălalt, nu înseamnă că măsurătorile sunt fiabile.Deoarece rezultatul este dihotomic, există o șansă de 50 la sută ca cele două măsurători să fie de acord. Coeficientul Kappa ia în considerare acest lucru șiexigă un grad mai mare de potrivire pentru a ajunge la consistență.
În contextul instruirii bazate pe Web, fiecare categorie de utilizare a website-ului auto-raportat poate fi recodificată ca o variabilă binară. De exemplu, atunci când întrebarea unu este „cât de des utilizați telnet”, răspunsurile categorice posibile sunt „a: zilnic”, „b: de trei până la cinci ori pe săptămână”, „c: de trei-cinci ori pe lună”, „d: rar” și „e:niciodată”. În acest caz, cele cinci categorii pot fi recodificate în cinci variabile: Q1A, Q1B, Q1C, Q1D și Q1E. Apoi, toate aceste variabile binare pot fi anexate pentru a forma un tabel R X 2, așa cum se arată în tabelul următor.Cu această structură de date, răspunsurile pot fi codificate ca „1” sau „0” și, astfel, este posibilă măsurarea acordului de clasificare. Acordul poate fi calculat cu ajutorul coeficientului Kappa și astfel se poate estima fiabilitatea datelor.
Subiecți Date din jurnalul de evidență Self-date din raport Subiect 1 1 1 Subiect 2 0 0 Subiect 3 1 0 0 .
Subiect 4 0 1 Index of Inconsistency
O altă modalitate de a calcula datele categorice menționate mai sus este Index ofInconsistency (IOI). În exemplul de mai sus, deoarece există două măsurători (date logaritmice și date raportate de sine stătătoare) și cinci opțiuni în răspuns, se formează un tabel 4X4. Primul pas pentru a calcula IOI este de a împărți tabelul RXC în mai multe subtablouri 2X2. De exemplu, ultima opțiune „niciodată” este tratată ca o categorie și toate celelalte sunt împărțite într-o altă categorie ca „nu niciodată”, așa cum se arată în următorul tabel.
Self-.date raportate Log Niciodată Nu niciodată Nu niciodată Total Niciodată a .
b a+b Nu niciodată c d c+d Total a+c b+d n=Suma(a-d) Procentul de IOI se calculează cu următoarea formulă:
IOI% = 100*(b+c)/ unde p = (a+c)/n
După ce IOI este calculat pentru fiecare subtablet 2X2, se utilizează o medie a tuturor indicilor ca indicator al inconsistenței măsurii. Criteriul pentru a judeca dacă datele sunt consecvente este următorul:
- Un IOI mai mic de 20 este o varianță scăzută
- Un IOI între 20 și 50 este o varianță moderată
- Un IOI peste 50 este o varianță ridicată
Fiabilitatea datelor este exprimată în această ecuație: r = 1 – IOI
Coeficientul de corelație intraclasă
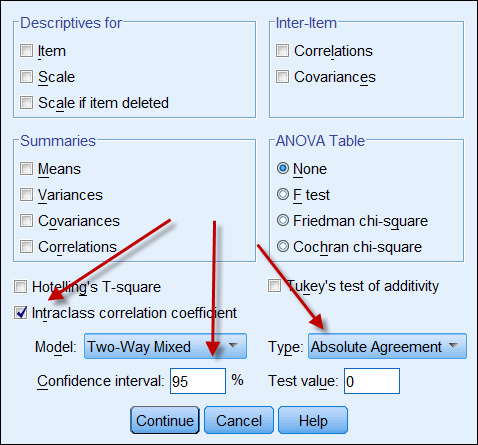
Dacă ambele surse de date produc date continue, atunci se poate calcula coeficientul de corelație intraclasă pentru a indica fiabilitatea datelor. Următoarea este o captură de ecran a opțiunilor ICC din SPSS. În Typetexistă două opțiuni: „consistență” și „acord absolut”. Dacă se alege „consistență”, atunci chiar dacă un set de numere are o consistență ridicată (de exemplu, 9, 8, 9, 9, 8, 7…) și celălalt are o consistență scăzută (de exemplu, 4,3, 4, 3, 3, 2…), corelația lor puternică implică în mod greșit faptul că datele sunt în concordanță una cu cealaltă. Prin urmare, este recomandabil să se aleagă „acordul absolut”.
Măsuri repetate
Măsurarea fiabilității între date poate fi, de asemenea, conceptualizată și proceduralizată ca oANOVA cu măsuri repetate. Într-o ANOVA cu măsuri repetate, măsurătorile sunt efectuate la aceiași subiecți de mai multe ori, cum ar fi pretest, intermediar și posttest. În acestcontext, subiecții sunt, de asemenea, măsurați în mod repetat prin jurnalul utilizatorului web, jurnalul de bord și sondajul auto-raportat. Următorul este codul SAS pentru o ANOVA cu măsuri repetate:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
În programul de mai sus, numărul de site-uri web vizitate de nouă voluntari este înregistrat în jurnalul de acces al utilizatorului, în jurnalul personal și în sondajul auto-raportat. Utilizatorii sunt tratați ca factor între subiecți, în timp ce cele trei măsuri sunt considerate ca factor între măsuri. Următorul este un rezultat condensat:
Sursa de variație DF Mediu pătrat Between-subject (user) 8 10442.50 Between-measure (time) 2 488.93 Residual 16 454.80 Pe baza informațiilor de mai sus, coeficientul de fiabilitate poate fi calculat cu ajutorul acestei formule (Fisher, 1946; Horst, 1949):
r = MSîntre-măsuri – MSresidual ————————————————————– MSbetween-measure + (dfbetween-people X MSresidual) Să introducem numărul în formulă:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) Fiabilitatea este de aproximativ 0,0008, ceea ce este extrem de scăzut. Prin urmare, putem să mergem acasă și să uităm de aceste date. Din fericire, este vorba doar de un set de date ahypothetic. Dar, ce se întâmplă dacă este un set de date real? Trebuie să fiți suficient de duri pentru a renunța la datele slabe, mai degrabă decât să publicați niște rezultate care sunt total nesigure.
Analiza corelațională și de regresie
Analiza corelațională, care utilizează coeficientul de moment al produsului lui Pearson, este foarte simplă și deosebit de utilă atunci când scalele a două măsurători nu sunt aceleași. De exemplu, jurnalul serverului web poate urmări numărul de pagini accesate, în timp ce datele raportate de sine stătător au o scală de tip Likert (de exemplu, Cât de des navigați pe internet? 5 = foarte des, 4 = des, 3 = uneori, 2 = rar, 5 = niciodată). În acest caz, scorurile auto-raportate pot fi utilizate ca predictor pentru a face o regresie față de accesarea paginilor.
O abordare similară este analiza de regresie, în care un set de scoruri (de exemplu, datele din sondaj) este tratat ca predictor, în timp ce un alt set de scoruri (de exemplu, jurnalul zilnic al utilizatorului) este considerat variabila dependentă. În cazul în care se utilizează mai mult de două măsuri, se poate aplica un model de regresie multiplă, adică cea care dă un rezultat mai precis (de exemplu, jurnalul de acces al utilizatorilor la internet) este considerată ca fiind variabila dependentă, iar toate celelalte măsuri (de exemplu, jurnalul zilnic al utilizatorului, datele din sondaj) sunt tratate ca variabile independente.
Referință
- Aschengrau, A., & Seage III, G. (2008). Esențialități de epidemiologie în sănătatea publică. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) Măsurarea în științele sociale: Teorii și strategii. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Acuratețea GPA auto-raportate la colegiu: Diferențe moderate de gen în funcție de nivelul de realizare și de autoeficacitatea academică. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Deci, de ce să mă întrebi pe mine? Sunt chiar atât de proaste datele de auto-raport? În Charles E. Lance și Robert J. Vandenberg (Eds.), Statistical and methodological myths and urban legends (Mituri statistice și metodologice și legende urbane): Doctrină, veridicitate și fabulație în științele organizaționale și sociale (pp309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-experimentarea: Probleme de proiectare și analiză. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validitatea și fiabilitatea metodei de eșantionare a experienței. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psihologia ca știință și artă. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, 10 august). Religia și reacția la orientările COVID-19mitigare. Psiholog american. Publicație online în avans. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). Liceul și dincolo de el. Un studiu longitudinal național pentru anii 1980, calitatea răspunsurilor elevilor de liceu la itemii din chestionar. (NCES 84-216).Washington, D. C.: Departamentul de Educație al Statelor Unite ale Americii. Biroul de cercetare și îmbunătățire a educației. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). The incrementalvalidity of average state self-reports over global self-reports ofpersonality. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Metode statistice pentru lucrătorii din cercetare (ed. a 10-a). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). CâțiAmericani participă la cult în fiecare săptămână? O abordare alternativă la măsurători? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 August). Compararea distribuțiilor de percentilă pentru măsurile antropometrice între trei seturi de date. Lucrare prezentată la Annual Joint Statistical Meeting, Baltimore, MD.
- Horst, P. (1949). O expresie generalizată pentru fiabilitatea măsurilor. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). On theuse of affected controls to address recall bias in case-control studiesesof birth defects. Teratology, 49, 273-281.
- Loftus, E. (2016, aprilie). Ficțiunea memoriei. Lucrare prezentată la Western Psychological Association Convention. Long Beach, CA.
- Lowry, R. (2016). Kappa ca măsură a concordanței în sortarea categorială. Retrieved from http://vassarstats.net/kappa.html
- Organizația pentru Cooperare și Dezvoltare Economică. (2017). Chestionar de bunăstare pentru PISA 2018. Paris: Autor. Retrieved from https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Cele șapte păcate ale memoriei: Insights from psychology and cognitive neuroscience (Perspective din psihologie și neuroștiințe cognitive). American Psychology, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Studii privind erorile de măsurare la Centrul Național de Statistică a Educației. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Toată lumea minte: Big data, new data și ce ne poate spune internetul despre cine suntem cu adevărat. New York, NY: Dey Street Books.
 Urcă la meniul principal
Urcă la meniul principal Alte cursuriMotor de căutare
|

Contactați-mă
|