Metoda 1, Bad: ORDER BY NEWID()
Ușor de scris, dar se comportă ca un gunoi fierbinte, fierbinte, deoarece scanează întregul index clusterizat, calculând NEWID() pe fiecare rând:
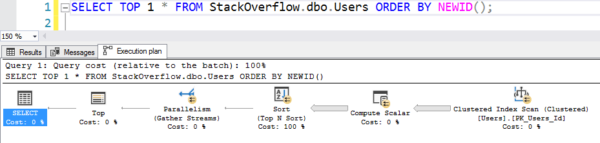
Planul cu scanarea
Aceasta a durat 6 secunde pe mașina mea, mergând în paralel pe mai multe fire de execuție, folosind zeci de secunde de CPU pentru tot acel calcul și sortare. (Iar tabelul Users nu are nici măcar 1GB.)
Metoda 2, mai bună, dar ciudată: TABLESAMPLE
Aceasta a apărut în 2005, și are o tonă de gotchas. Este un fel de a alege o pagină la întâmplare și apoi returnează o grămadă de rânduri din acea pagină. Primul rând este oarecum aleatoriu, dar restul nu sunt.
Transact-.SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Planul pare că face o scanare a tabelei, dar face doar 7 citiri logice:
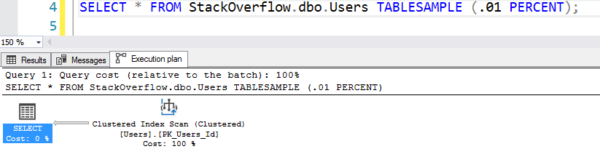
Planul cu scanarea falsă
Dar iată rezultatele – puteți vedea că sare la o pagină aleatorie de 8K și apoi începe să citească rândurile în ordine. Nu sunt chiar rânduri aleatoare.
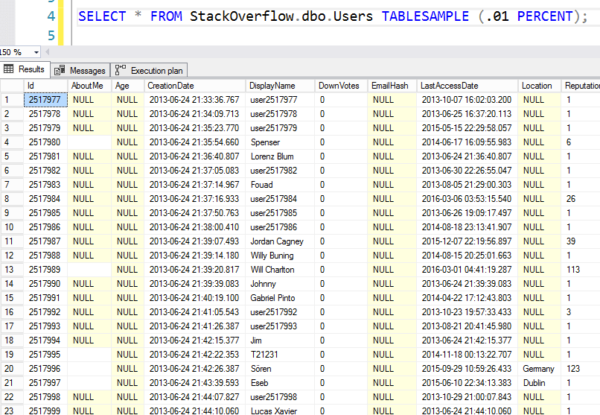
Aleatoare ca numerele de loterie mafiote
În schimb, puteți folosi dimensiunea eșantionului ROWS, dar are niște rezultate destul de ciudate. De exemplu, în tabelul Stack Overflow Users, când am spus TABLESAMPLE (50 ROWS), am primit de fapt 75 de rânduri înapoi. Acest lucru se datorează faptului că SQL Server convertește în schimb dimensiunea rândurilor într-un procent.
Metoda 3, Best but Requires Code: Random Primary Key
Obțineți câmpul ID de top din tabel, generați un număr aleatoriu și căutați acel ID. Aici, sortăm după ID pentru că vrem să găsim înregistrarea de top care există cu adevărat (în timp ce un număr aleatoriu ar fi putut fi șters.) Destul de rapid, dar este bun doar pentru un singur rând aleatoriu. Dacă ați dori 10 rânduri, ar trebui să apelați un cod ca acesta de 10 ori (sau să generați 10 numere aleatorii și să utilizați o clauză IN.)
Planul de execuție arată o scanare a indexului clusterizat, dar nu preia decât un singur rând – vorbim doar de 6 citiri logice pentru tot ceea ce vedeți aici, și se termină aproape instantaneu:

Planul care poate
Există o singură problemă: dacă Id-ul are numere negative, nu va funcționa așa cum se așteaptă. (De exemplu, să zicem că începeți câmpul de identitate la -1 și faceți pasul -1, îndreptându-vă mereu în jos, ca și morala mea.)
Metoda 4, OFFSET-FETCH (2012+)
Daniel Hutmacher a adăugat-o pe aceasta în comentarii:
Și a spus: „Dar funcționează corect doar cu un index clusterizat. Bănuiesc că asta se datorează faptului că va scana pentru rândurile (@rows) într-un heap în loc să facă o căutare de index.”
Bonus Track #1: Watch Us Discussing This
Te-ai întrebat vreodată cum este să fii în camera de chat a companiei noastre? Această discuție Slack de 10 minute vă va da o idee destul de bună:
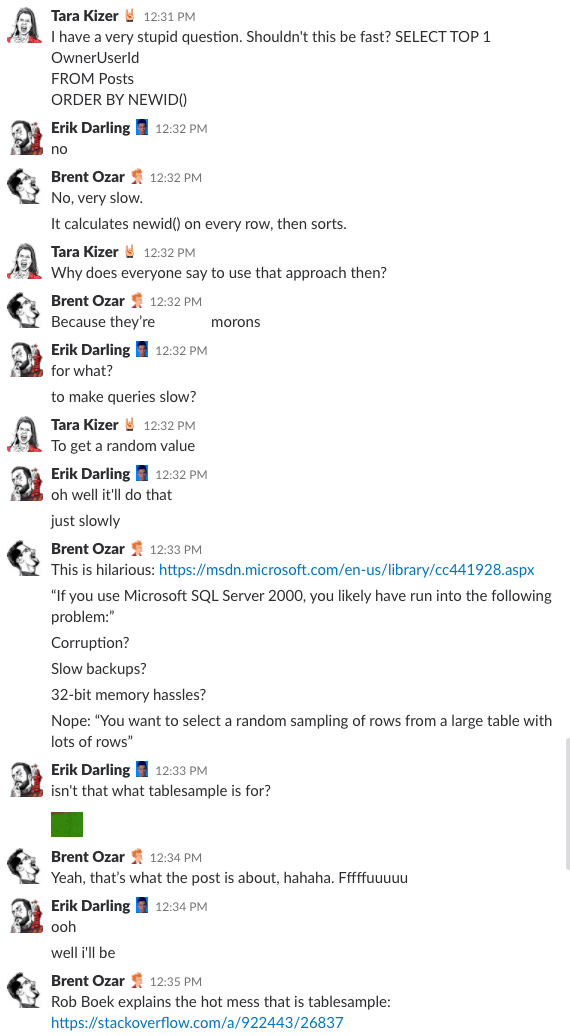
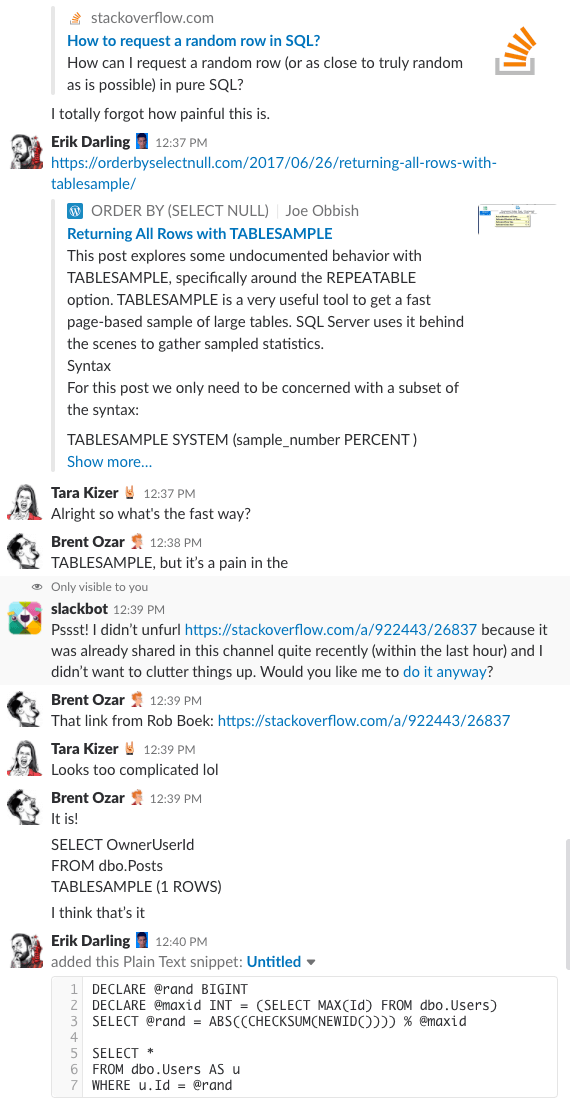
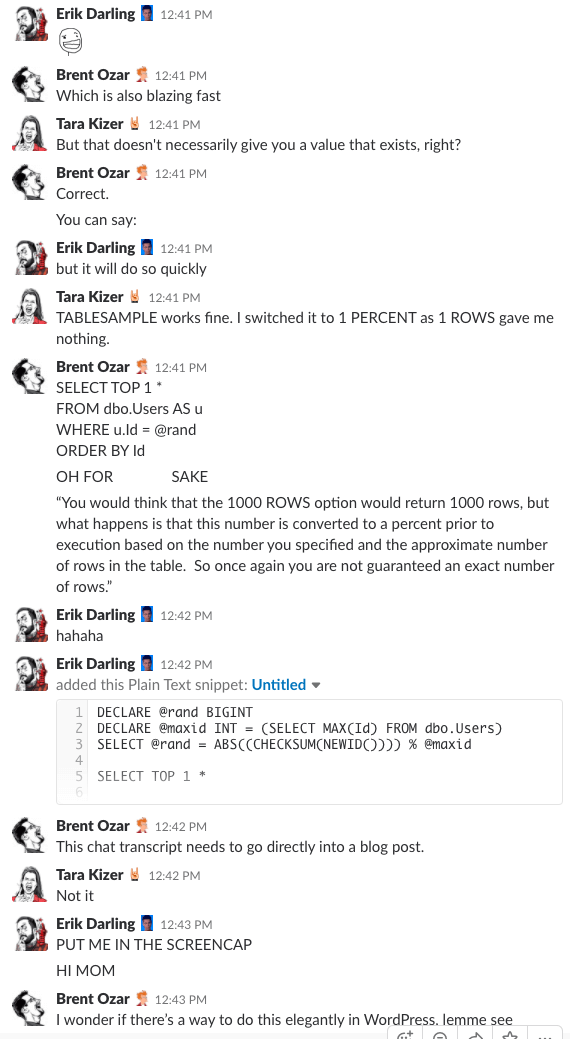
Alertă de spoiler: nu a existat. Am făcut doar capturi de ecran.
Bonus Track #2: Mitch Wheat Digs Deeper
Vrei o analiză în profunzime a caracterului aleator al mai multor tehnici diferite? Mitch Wheat se scufundă foarte adânc, cu tot cu grafice!