Poate că imaginea de mai sus v-a dat o idee suficientă despre ce este vorba în această postare.
Acest post acoperă unii dintre algoritmii importanți de potrivire a șirurilor de caractere fuzzy(nu exact egale, dar lumpsum aceleași șiruri, să zicem RajKumar & Raj Kumar) care includ:
Distanța Hamming
Distanța Levenstein
Distanța Damerau Levenstein
Potrivirea de șiruri de caractere bazată pe N-Gram
Arborele BK
Algoritmul Bitap
Dar trebuie să știm mai întâi de ce este importantă potrivirea fuzzy având în vedere un scenariu din lumea reală. Ori de câte ori unui utilizator i se permite să introducă orice date, lucrurile pot deveni foarte încurcate, ca în cazul de mai jos!!!
Lasă,
- Numele tău este „Saurav Kumar Agarwal”.
- Ai primit un card de bibliotecă (cu un ID unic, desigur) care este valabil pentru fiecare membru al familiei tale.
- Te duci la o bibliotecă pentru a elibera câteva cărți în fiecare săptămână. Dar pentru aceasta, trebuie mai întâi să faceți o înscriere într-un registru la intrarea în bibliotecă, unde introduceți numele dvs. de identificare &.
Acum, autoritățile bibliotecii decid să analizeze datele din acest registru al bibliotecii pentru a avea o idee despre cititorii unici care o vizitează în fiecare lună. Acum, acest lucru se poate face din mai multe motive (cum ar fi dacă să se meargă pentru extinderea terenului sau nu, ar trebui să se mărească numărul de cărți? etc.).
Ei au planificat să facă acest lucru prin numărarea (nume unice, ID-ul bibliotecii) perechilor înregistrate pentru o lună. Deci, dacă avem
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Aceasta ar trebui să ne dea 4 cititori unici.
Până acum totul e bine
Au estimat că acest număr va fi în jur de 10k-10.5k, dar cifrele au crescut până la ~50k după analiza prin potrivirea exactă a șirurilor de nume.
wooohhh!!!
O estimare destul de proastă trebuie să spun !!
Oare au ratat un truc aici?
După o analiză mai profundă, a apărut o problemă majoră. Amintiți-vă numele dumneavoastră, „Saurav Agarwal”. Au găsit niște intrări care duceau la 5 utilizatori diferiți prin ID-ul bibliotecii dvs. de familie:
- Saurav K Aggrawal (observați dublul ‘g’, ‘ra-ar’, Kumar devine K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Există unele ambiguități, deoarece autoritățile bibliotecii nu știu
- Câte persoane din familia dvs. vizitează biblioteca? dacă aceste 5 nume reprezintă un singur cititor, 2 sau 3 cititori diferiți. Numiți-o o problemă nesupravegheată în care avem un șir care reprezintă nume nestandardizate, dar nu se cunosc numele standardizate ale acestora (de exemplu, Saurav Agarwal: Saurav Kumar Agarwal nu este cunoscut)
- Ar trebui ca toate aceste nume să fuzioneze în „Saurav Kumar Agarwal”? Nu se poate spune, deoarece SK Agarwal poate fi Shivam Kumar Agarwal (de exemplu, numele tatălui dumneavoastră). De asemenea, singurul Agarwal poate fi oricine din familie.
Ultimele 2 cazuri (SK Agarwal & Agarwal) ar necesita unele informații suplimentare (cum ar fi sexul, data nașterii, cărțile eliberate) care vor fi introduse într-un algoritm ML pentru a determina numele real al cititorului & ar trebui să fie lăsat pentru moment. Dar un lucru de care sunt destul de sigur este că primele 3 nume reprezintă aceeași persoană & Nu ar trebui să am nevoie de informații suplimentare pentru a le unifica într-un singur cititor, adică „Saurav Kumar Agarwal”.
Cum se poate face acest lucru?
Aici intervine fuzz string matching, ceea ce înseamnă o potrivire aproape exactă între șiruri care sunt ușor diferite unul de celălalt (în principal din cauza ortografiei greșite), cum ar fi „Agarwal” & „Aggarwal” & „Aggrawal” & „Aggrawal”. Dacă obținem un șir de caractere cu o rată de eroare acceptabilă (de exemplu, o literă greșită), îl vom considera ca fiind o potrivire. Așadar, haideți să explorăm →
Distanța Hamming este cea mai evidentă distanță calculată între două șiruri de lungime egală, care oferă o numărătoare a caracterelor care nu se potrivesc corespunzător unui indice dat. De exemplu: ‘Bat’ & ‘Bet’ are distanța hamming 1 deoarece la indexul 1, ‘a’ nu este egal cu ‘e’
Distanța Levenstein/ Distanța de editare
Chiar presupun că vă simțiți confortabil cu distanța Levenstein & Recursiune. Dacă nu, citiți acest lucru. Explicația de mai jos este mai mult o versiune rezumată a distanței Levenstein.
Lăsați ‘x’= length(Str1) & ‘y’=length(Str2) pentru toată această postare.
Distanța Levenstein calculează numărul minim de editări necesare pentru a converti ‘Str1’ în ‘Str2’, efectuând fie Adăugarea, Eliminarea, fie Înlocuirea caracterelor. Astfel, ‘Cat’ & ‘Bat’ are distanța de editare ‘1’ (Înlocuirea lui ‘C’ cu ‘B’), în timp ce pentru ‘Ceat’ & ‘Bat’, ar fi 2 (Înlocuirea lui ‘C’ cu ‘B’; Ștergerea lui ‘e’).
Vorbind despre algoritm, acesta are în principal 5 pași
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Ceea ce facem este să începem să citim șirurile de caractere de la primul caracter
- Dacă caracterul de la indicele ‘x’ din str1 se potrivește cu caracterul de la indicele ‘y’ din str2, nu este necesară nicio editare & calculăm distanța de editare prin apelarea
LevensteinDistance(str1,str2)
- Dacă nu se potrivesc, știm că este necesară o editare. Așa că adăugăm +1 la actuala edit_distance & calculează recursiv edit_distance pentru 3 condiții & ia minimul din cele trei:
Levenstein(str1,str2) →inserție în str2.
Levenstein(str1,str2) →ștergere în str2
Levenstein(str1,str2)→înlocuire în str2
- Dacă vreunul dintre șiruri rămâne fără caractere în timpul recursiunii, lungimea caracterelor rămase în celălalt șir se adaugă la distanța de editare (primele două instrucțiuni if)
Distanța Demerau-Levenstein
Consideră ‘abcd’ & ‘acbd’. Dacă ne luăm după distanța Levenstein, aceasta ar fi (înlocuiți ‘b’-‘c’ & ‘c’-‘b’ la pozițiile de index 2 & 3 în str2) Dar dacă vă uitați cu atenție, ambele caractere au fost schimbate ca în str1 & dacă introducem o nouă operație ‘Swap’ alături de ‘addition’, ‘ deletion’ & ‘replace’, această problemă poate fi rezolvată. Această introducere ne poate ajuta să rezolvăm probleme precum ‘Agarwal’ & ‘Agrawal’.
Această operație se adaugă prin pseudocodul de mai jos
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Să rulăm operația de mai sus pentru ‘abcd’ & ‘acbd’ unde presupunem
initial_x=1 & initial_y=1 (Pornind indexarea de la 1 & nu de la 0 pentru ambele șiruri).
current x=3 & y=3 deci str1 & str2 la ‘c’ (abcd) & & respectiv ‘b’ (acbd).
Limitele superioare incluse în operația de feliere menționată mai jos. Prin urmare, ‘qwerty’ va însemna ‘qwer’.
- last_matching_index_y va fi ultimul_index din str2 care a corespuns cu str1, adică 2, deoarece ‘c’ din ‘acbd’ (index 2) a corespuns cu ‘c’ din ‘abcd’.
- last_matching_index_x_x va fi ultimul_index din str1 care a corespuns cu str2, adică 2, deoarece ‘c’ din ‘acbd’ (index 2) a corespuns cu ‘c’ din ‘abcd’.
- last_matching_index_x_x va fi ultimul_index din str1 care a corespuns cu str2 i.e 2 deoarece ‘b’ din ‘abcd’ (index 2)s-a potrivit cu ‘b’ din ‘acbd’.
- În consecință, urmând pseudocodul de mai sus, DemarauLevenstein(‘abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‘a’,’a’)=1+0+0+0+0=1. Acesta ar fi fost 2 dacă am fi urmat distanța Levenstein
N-Gramă
N-grama nu este practic altceva decât un set de valori generate dintr-un șir de caractere prin împerecherea secvențială a „n” caractere/cuvinte care apar succesiv. De exemplu: n-grama cu n=2 pentru ‘abcd’ va fi ‘ab’,’bc’,’cd’.
Acum, aceste n-grame pot fi generate pentru șiruri a căror similaritate trebuie măsurată & se pot folosi diferite metrici pentru a măsura similaritatea.
Să fie ‘abcd’ & ‘acbd’ 2 șiruri de șiruri care trebuie să fie potrivite.
n-grame cu n=2 pentru
‘abcd’=ab,bc,cd
‘acbd’=ac,cb,bd
Compararea componentelor (qgrame)
Contul de n-grame potrivite exact pentru cele două șiruri. Aici, ar fi 0
Cosine Similarity
Calcularea produsului punctat după convertirea n-grame generate pentru șiruri de caractere în vectori
Component match (no order considered)
Corelarea componentelor n-grame ignorând ordinea elementelor din interiorul acestora, adică bc=cb.
Există multe alte astfel de măsurători, cum ar fi distanța Jaccard, indicele Tversky etc., care nu au fost discutate aici.
BK Tree
BK tree este unul dintre cei mai rapizi algoritmi pentru a găsi șiruri de caractere similare (dintr-un grup de șiruri) pentru un șir dat. Arborele BK utilizează o
- Distanța Levenstein
- Inegalitate triunghiulară (va fi abordată până la sfârșitul acestei secțiuni)
pentru a afla șirurile similare (& nu doar un singur șir cel mai bun).
Un arbore BK este creat folosind un grup de cuvinte dintr-un dicționar disponibil. Să spunem că avem un dicționar D={Book, Books, Books, Cake, Boo, Boon, Cook, Cape, Cart}
Un arbore BK este creat prin
- Selectarea unui nod rădăcină (poate fi orice cuvânt). Să fie „Books”
- Se trece prin fiecare cuvânt W din dicționarul D, se calculează distanța Levenstein față de nodul rădăcină și se face cuvântul W copil al rădăcinii dacă nu există un copil cu aceeași distanță Levenstein pentru părinte. Inserarea cărților & Cake.
Levenstein(Books,Book)=1 & Levenstein(Books,Cake)=4. Deoarece nu s-a găsit niciun copil cu aceeași distanță pentru „Book”, faceți-le copii noi pentru rădăcină.
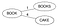
- Dacă există un copil cu aceeași distanță Levenstein pentru părintele P, acum considerați acel copil ca fiind un părinte P1 pentru acel cuvânt W, calculați Levenstein(părinte, cuvânt) și dacă nu există niciun copil cu aceeași distanță pentru părintele P1, faceți din cuvântul W un nou copil pentru P1, altfel continuați să coborâți în arbore.
Considerați să introduceți Boo. Levenstein(Book, Boo)=1, dar există deja un copil cu aceeași distanță, adică Books. Prin urmare, calculați acum Levenstein(Books, Boo)=2. Deoarece nu există un copil cu aceeași distanță pentru Books, faceți din Boo copilul lui Books.

Similar, introduceți toate cuvintele din dicționar în arborele BK

După ce arborele BK este pregătit, pentru a căuta cuvinte similare pentru un cuvânt dat (cuvânt de interogare) trebuie să stabilim un prag_de_toleranță, de exemplu „t”.
- Aceasta este distanța maximă de editare (edit_distance) pe care o vom lua în considerare pentru similitudinea dintre orice nod & query_word. Orice lucru care depășește această valoare este respins.
- De asemenea, vom lua în considerare doar acei copii ai unui nod părinte pentru compararea cu Query în cazul în care Levenstein(Child, Parent) este în interiorul
de ce? vom discuta acest lucru în scurt timp
- Dacă această condiție este adevărată pentru un copil, atunci vom calcula doar Levenstein(Child, Query) care va fi considerat similar cu query dacă
Levenshtein(Child, Query)≤t.
- În consecință, nu vom calcula distanța Levenstein pentru toate nodurile/cuvintele din dicționar cu cuvântul de interogare &, economisind astfel mult timp atunci când fondul de cuvinte este imens
În consecință, pentru ca un Copil să fie similar cu Interogare dacă
- Levenstein(Părinte, Interogare)-t ≤ Levenstein(Copil,Părinte) ≤ Levenstein(Părinte,Interogare)+t
- Levenstein(Copil,Interogare)≤t
Vă prezentăm rapid un exemplu. Fie ‘t’=1
După ce cuvântul pentru care trebuie să găsim cuvinte similare este ‘Care’ (cuvânt de interogare)
- Levenstein(Book,Care)=4. Deoarece 4>1, ‘Carte’ este respins. Acum vom lua în considerare doar acei copii ai lui ‘Book’ care au o LevisteinDistance(Child,’Book’) între 3(4-1) & 5(4+1). Prin urmare, vom respinge ‘Books’ & toți copiii săi, deoarece 1 nu se află în limitele stabilite
- Cum Levenstein(Cake, Book)=4 care se află între 3 & 5, vom verifica Levenstein(Cake, Care)=1 care este ≤1, deci un cuvânt similar.
- Reajustând limitele, pentru copiii lui Cake, devin 0(1-1) & 2(1+1)
- Acum atât Cape & Cart are Levenstein(Copil, Părinte)=1 & respectiv 2, ambii sunt eligibili pentru a fi testați cu „Care”.
- Cum Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, doar Cape este considerat a fi un cuvânt similar cu ‘Care’.
În concluzie, am găsit 2 cuvinte similare cu ‘Care’, care sunt: Cake & Cape
Dar pe ce bază decidem asupra limitelor
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
pentru orice nod copil?
Acest lucru rezultă din Inegalitatea triunghiului care afirmă
Distanța (A,B) + Distanța(B,C)≥Distanța(A,C) unde A,B,C sunt laturile unui triunghi.
Cum ne ajută această idee să ajungem la aceste limite, să vedem:
Să fie Query,=Q Parent=P & Child=C formează un triunghi cu distanța Levenstein ca lungime a muchiei. Fie ‘t’ pragul_de_toleranță. Atunci, Prin inegalitatea de mai sus
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Încă o dată, prin inegalitatea triunghiului,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Algoritmul Bitap
Este, de asemenea, un algoritm foarte rapid care poate fi folosit pentru potrivirea șirurilor fuzzy destul de eficient. Acest lucru se datorează faptului că utilizează operații de tip bitwise & deoarece acestea sunt destul de rapide, algoritmul este cunoscut pentru viteza sa. Fără să pierdem timpul, să începem:
După ce S0=’ababc’ este modelul care trebuie potrivit cu șirul S1=’abdababababc’.
În primul rând,
- Căutați toate caracterele unice din S1 & S0 care sunt a,b,c,d
- Formați modele de biți pentru fiecare caracter. Cum?

- Întoarceți modelul S0 pentru a fi căutat
- Pentru modelul de biți pentru caracterul x, puneți 0 acolo unde apare în model, altfel 1. În T, ‘a’ apare la locul 3 & 5, am plasat 0 în acele poziții & restul 1.
În mod similar, formați toate celelalte modele de biți pentru diferite caractere din dicționar.
S0=abababc S1=abdababababc
- Treceți o stare inițială a unui model de biți de lungime(S0) cu toți 1. În cazul nostru, ar fi 11111 (starea S).
- Cum începem căutarea în S1 și trecem prin orice caracter,
schimbăm un 0 la bitul cel mai de jos, adică al cincilea bit de la dreapta în S &
Operație OR pe S cu T.
Prin urmare, pe măsură ce întâlnim primul ‘a’ în S1, vom
- Schimbă la stânga un 0 în S la bitul cel mai de jos pentru a forma 11111 →11110
- 11010 | 11110=11110
Acum, când trecem la al doilea caracter ‘b’
- Schimbă 0 în S i.e pentru a forma 11110 →11100
- S |T=11100 | 10101=11101
Cum se întâlnește ‘d’
- Schimbă 0 în S pentru a forma 11101 →11010
- S |T=11010 |11111=11111
Observați că, deoarece ‘d’ nu este în S0, starea S se resetează. După ce parcurgeți întregul S1, veți obține stările de mai jos la fiecare caracter

Cum știu dacă am găsit vreo potrivire fuzz/plină?
- Dacă un 0 ajunge la bitul cel mai de sus în modelul de biți State S (ca în cazul ultimului caracter „c”), aveți o potrivire completă
- Pentru potrivirea fuzz, observați 0 în diferite poziții din State S. Dacă 0 se află pe locul 4, am găsit 4/5 caractere în aceeași secvență ca în S0. În mod similar pentru 0 în alte locuri.
Un lucru pe care probabil ați observat că toți acești algoritmi lucrează pe baza similitudinii ortografice a șirurilor de caractere. Pot exista și alte criterii pentru fuzzy matching? Da,
Fonetica
În continuare vom acoperi algoritmii de potrivire fuzzy pe bază de fonetică (bazată pe sunet, cum ar fi Saurav & Sourav, ar trebui să aibă o potrivire exactă în fonetică) !!!
- Reducerea dimensiunilor (3 părți)
- Algoritmi NLP(5 părți)
- Bazele învățării prin întărire (5 părți)
- Începând cu timpul…Series (7 părți)
- Detectarea obiectelor folosind YOLO (3 părți)
- Tensorflow pentru începători (concepte + exemple) (4 părți)
- Prelucrarea seriilor de timp (cu coduri)
- Analiza datelor pentru începători
- Statistică pentru începători (4 părți)