- Introduzione
- Obiettivo
- A. Metodi di filtraggio
- Chi-square Test
- Fisher’s Score
- Coefficiente di correlazione
- Soglia di varianza
- Mean Absolute Difference (MAD)
- Rapporto di dispersione
- B. Metodi Wrapper:
- Forward Feature Selection
- Backward Feature Elimination
- Exhaustive Feature Selection
- Recursive Feature Elimination
- C. Metodi incorporati:
- Regolarizzazione LASSO (L1)
- Random Forest Importance
- Conclusione
Introduzione
Quando si costruisce un modello di apprendimento automatico nella vita reale, è quasi raro che tutte le variabili nel set di dati siano utili per costruire un modello. L’aggiunta di variabili ridondanti riduce la capacità di generalizzazione del modello e può anche ridurre la precisione complessiva di un classificatore. Inoltre, aggiungere sempre più variabili a un modello aumenta la complessità complessiva del modello.
Secondo la legge della parsimonia del ‘Rasoio di Occam’, la migliore spiegazione a un problema è quella che implica il minor numero di ipotesi possibili. Così, la selezione delle caratteristiche diventa una parte indispensabile della costruzione di modelli di apprendimento automatico.
Obiettivo
L’obiettivo della selezione delle caratteristiche nell’apprendimento automatico è quello di trovare il miglior set di caratteristiche che permetta di costruire modelli utili dei fenomeni studiati.
Le tecniche per la selezione delle caratteristiche nell’apprendimento automatico possono essere classificate ampiamente nelle seguenti categorie:
Tecniche supervisionate: Queste tecniche possono essere usate per dati etichettati e sono usate per identificare le caratteristiche rilevanti per aumentare l’efficienza dei modelli supervisionati come la classificazione e la regressione.
Tecniche non supervisionate: Queste tecniche possono essere usate per dati non etichettati.
Da un punto di vista tassonomico, queste tecniche sono classificate come segue:
A. Metodi filtro
B. Metodi wrapper
C. Metodi incorporati
D. Metodi ibridi
In questo articolo, discuteremo alcune tecniche popolari di selezione delle caratteristiche nell’apprendimento automatico.
A. Metodi di filtraggio
I metodi di filtraggio raccolgono le proprietà intrinseche delle caratteristiche misurate tramite statistiche univariate invece delle prestazioni di convalida incrociata. Questi metodi sono più veloci e meno costosi dal punto di vista computazionale dei metodi wrapper. Quando si ha a che fare con dati altamente dimensionali, è computazionalmente più economico usare metodi filtro.
Discutiamo alcune di queste tecniche:
Information Gain
Information gain calcola la riduzione di entropia dalla trasformazione di un set di dati. Può essere usato per la selezione delle caratteristiche valutando l’Information gain di ogni variabile nel contesto della variabile target.
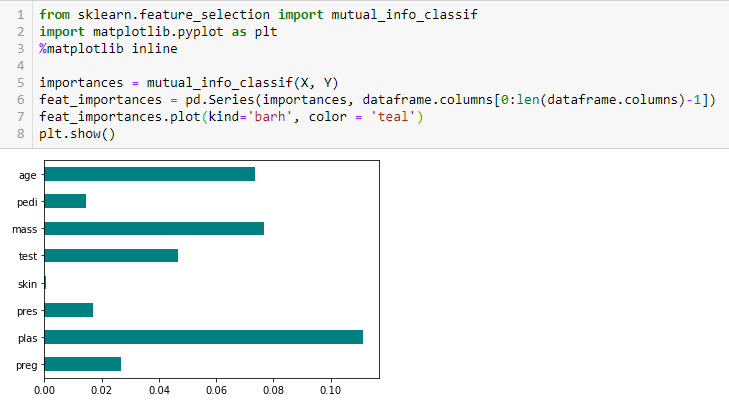
Chi-square Test
Il Chi-square test è usato per caratteristiche categoriche in un dataset. Calcoliamo il Chi-quadro tra ogni caratteristica e l’obiettivo e selezioniamo il numero desiderato di caratteristiche con i migliori punteggi del Chi-quadro. Per applicare correttamente il chi-quadrato al fine di testare la relazione tra varie caratteristiche nel dataset e la variabile obiettivo, devono essere soddisfatte le seguenti condizioni: le variabili devono essere categoriche, campionate indipendentemente e i valori devono avere una frequenza attesa maggiore di 5.
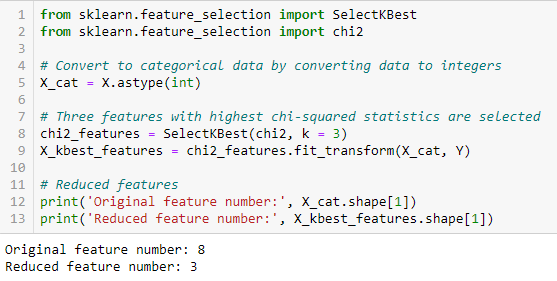
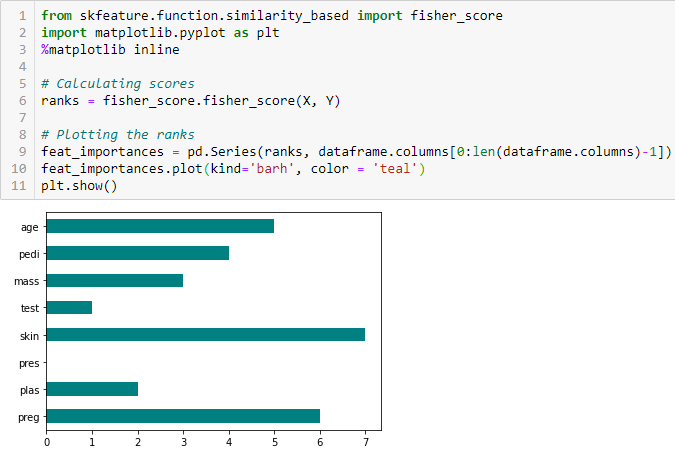
Fisher’s Score
Fisher score è uno dei metodi supervisionati di selezione delle caratteristiche più utilizzati. L’algoritmo che useremo restituisce i ranghi delle variabili basati sul punteggio di Fisher in ordine decrescente. Possiamo quindi selezionare le variabili secondo il caso.
Coefficiente di correlazione
La correlazione è una misura della relazione lineare di 2 o più variabili. Attraverso la correlazione, possiamo prevedere una variabile dall’altra. La logica dietro l’uso della correlazione per la selezione delle caratteristiche è che le buone variabili sono altamente correlate con l’obiettivo. Inoltre, le variabili dovrebbero essere correlate con l’obiettivo ma non dovrebbero essere correlate tra loro.
Se due variabili sono correlate, possiamo prevedere una dall’altra. Quindi, se due caratteristiche sono correlate, il modello ha davvero bisogno solo di una di esse, poiché la seconda non aggiunge informazioni aggiuntive. Useremo qui la Correlazione di Pearson.
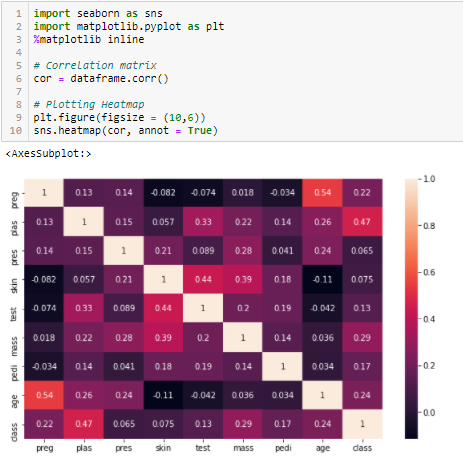
Dobbiamo impostare un valore assoluto, diciamo 0,5 come soglia per selezionare le variabili. Se troviamo che le variabili predittrici sono correlate tra loro, possiamo eliminare la variabile che ha un valore di coefficiente di correlazione più basso con la variabile obiettivo. Possiamo anche calcolare coefficienti di correlazione multipli per controllare se più di due variabili sono correlate tra loro. Questo fenomeno è noto come multicollinearità.
Soglia di varianza
La soglia di varianza è un semplice approccio di base alla selezione delle caratteristiche. Rimuove tutte le caratteristiche la cui varianza non soddisfa una certa soglia. Per impostazione predefinita, rimuove tutte le caratteristiche a varianza zero, cioè le caratteristiche che hanno lo stesso valore in tutti i campioni. Assumiamo che le caratteristiche con una varianza più alta possano contenere più informazioni utili, ma si noti che non stiamo prendendo in considerazione la relazione tra le variabili delle caratteristiche o tra le caratteristiche e le variabili di destinazione, che è uno degli svantaggi dei metodi di filtraggio.

Il get_support restituisce un vettore booleano dove True significa che la variabile non ha varianza zero.
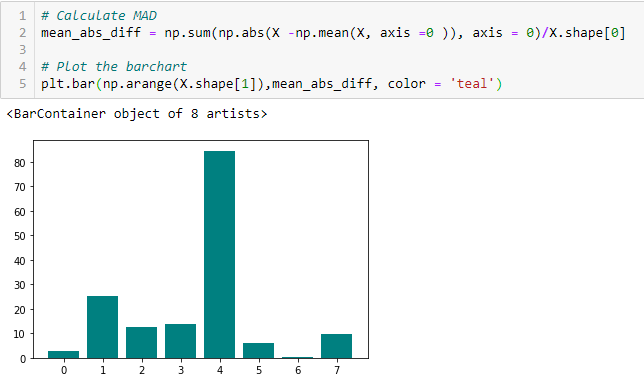
Mean Absolute Difference (MAD)
‘La differenza assoluta media (MAD) calcola la differenza assoluta dal valore medio. La differenza principale tra le misure di varianza e MAD è l’assenza del quadrato in quest’ultima. La MAD, come la varianza, è anche una variante di scala”. Ciò significa che maggiore è la MAD, maggiore è il potere discriminatorio.
Rapporto di dispersione
‘Un’altra misura di dispersione applica la media aritmetica (AM) e la media geometrica (GM). Per una data caratteristica (positiva) Xi su n modelli, l’AM e la GM sono date rispettivamente da
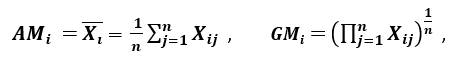
; poiché AMi ≥ GMi, con l’uguaglianza che vale se e solo se Xi1 = Xi2 = …. = Xin, allora il rapporto
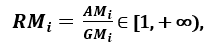
può essere usato come misura di dispersione. Una maggiore dispersione implica un valore più alto di Ri, quindi una caratteristica più rilevante. Al contrario, quando tutti i campioni di caratteristiche hanno (più o meno) lo stesso valore, Ri è vicino a 1, indicando una caratteristica di bassa rilevanza.

 ‘
‘
B. Metodi Wrapper:
I wrapper richiedono un metodo per cercare lo spazio di tutti i possibili sottoinsiemi di caratteristiche, valutando la loro qualità attraverso l’apprendimento e la valutazione di un classificatore con quel sottoinsieme di caratteristiche. Il processo di selezione delle caratteristiche si basa su uno specifico algoritmo di apprendimento automatico che stiamo cercando di adattare a un dato set di dati. Segue un approccio di ricerca avida, valutando tutte le possibili combinazioni di caratteristiche rispetto al criterio di valutazione. I metodi wrapper di solito risultano in una migliore accuratezza predittiva rispetto ai metodi di filtro.
Discutiamo alcune di queste tecniche:
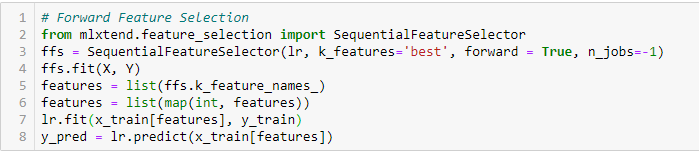
Forward Feature Selection
Questo è un metodo iterativo in cui iniziamo con la variabile più performante rispetto al target. Successivamente, selezioniamo un’altra variabile che dà le migliori prestazioni in combinazione con la prima variabile selezionata. Questo processo continua fino al raggiungimento del criterio prestabilito.
Backward Feature Elimination
Questo metodo funziona esattamente al contrario del metodo Forward Feature Selection. Qui, iniziamo con tutte le caratteristiche disponibili e costruiamo un modello. Successivamente, selezioniamo la variabile dal modello che dà il miglior valore di misura di valutazione. Questo processo continua fino a quando il criterio prestabilito è raggiunto.
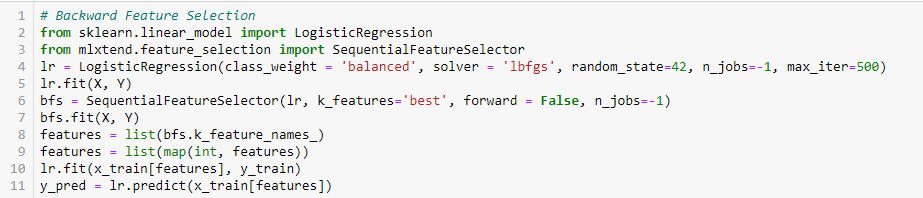
Questo metodo insieme a quello discusso sopra è anche conosciuto come metodo Sequential Feature Selection.
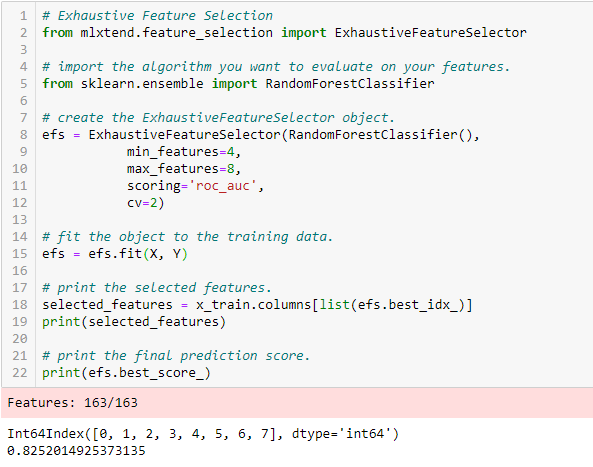
Exhaustive Feature Selection
Questo è il metodo di selezione delle caratteristiche più robusto trattato finora. Si tratta di una valutazione a forza bruta di ogni sottoinsieme di caratteristiche. Questo significa che prova ogni possibile combinazione delle variabili e restituisce il sottoinsieme con le migliori prestazioni.
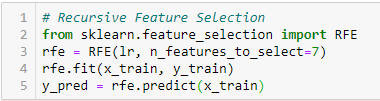
Recursive Feature Elimination
‘Dato uno stimatore esterno che assegna pesi alle caratteristiche (ad esempio, i coefficienti di un modello lineare), l’obiettivo della recursive feature elimination (RFE) è di selezionare le caratteristiche considerando ricorsivamente insiemi sempre più piccoli di caratteristiche. In primo luogo, lo stimatore è addestrato sull’insieme iniziale di caratteristiche e l’importanza di ogni caratteristica è ottenuta o attraverso un attributo coef_ o attraverso un attributo feature_importances_.
Poi, le caratteristiche meno importanti vengono eliminate dall’insieme corrente di caratteristiche. Questa procedura viene ripetuta ricorsivamente sull’insieme sfrondato fino a raggiungere il numero desiderato di caratteristiche da selezionare.”
C. Metodi incorporati:
Questi metodi racchiudono i benefici di entrambi i metodi wrapper e filtro, includendo le interazioni delle caratteristiche ma anche mantenendo un costo computazionale ragionevole. I metodi incorporati sono iterativi nel senso che si prendono cura di ogni iterazione del processo di formazione del modello ed estraggono attentamente quelle caratteristiche che contribuiscono maggiormente alla formazione per una particolare iterazione.
Discutiamo alcune di queste tecniche cliccando qui:
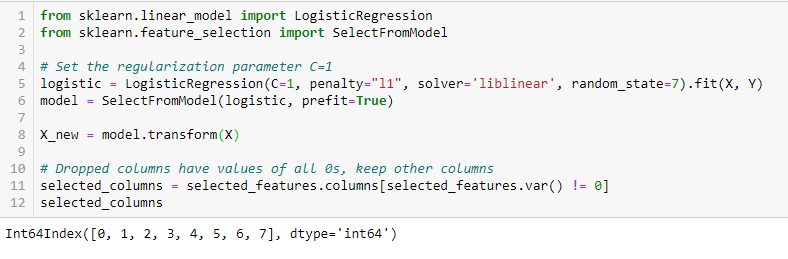
Regolarizzazione LASSO (L1)
La regolarizzazione consiste nell’aggiungere una penalità ai diversi parametri del modello di apprendimento automatico per ridurre la libertà del modello, cioè per evitare un over-fitting. Nella regolarizzazione dei modelli lineari, la penalità viene applicata sui coefficienti che moltiplicano ciascuno dei predittori. Tra i diversi tipi di regolarizzazione, Lasso o L1 ha la proprietà che è in grado di ridurre alcuni dei coefficienti a zero. Pertanto, quella caratteristica può essere rimossa dal modello.
Random Forest Importance
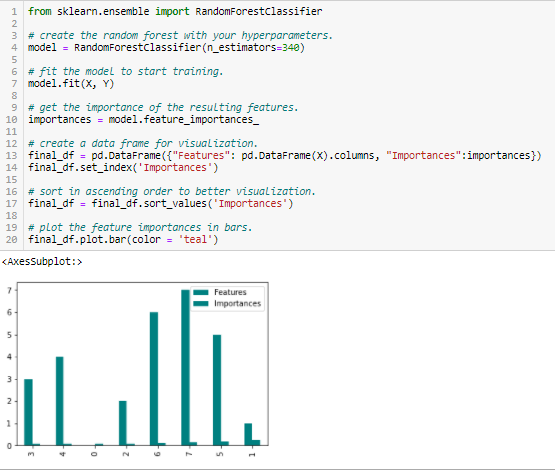
Random Forests è un tipo di algoritmo di Bagging che aggrega un numero specificato di alberi di decisione. Le strategie basate sugli alberi utilizzate dalle foreste casuali si classificano naturalmente in base a quanto migliorano la purezza del nodo, o in altre parole una diminuzione dell’impurità (impurità Gini) su tutti gli alberi. I nodi con la maggiore diminuzione dell’impurità si trovano all’inizio degli alberi, mentre le note con la minore diminuzione dell’impurità si trovano alla fine degli alberi. Così, potando gli alberi sotto un particolare nodo, possiamo creare un sottoinsieme delle caratteristiche più importanti.
Conclusione
Abbiamo discusso alcune tecniche per la selezione delle caratteristiche. Abbiamo lasciato appositamente le tecniche di estrazione delle caratteristiche come l’analisi delle componenti principali, la decomposizione dei valori singolari, l’analisi discriminante lineare, ecc. Questi metodi aiutano a ridurre la dimensionalità dei dati o a ridurre il numero di variabili preservando la varianza dei dati.
Oltre ai metodi discussi sopra, ci sono molti altri metodi di selezione delle caratteristiche. Ci sono anche metodi ibridi che usano sia tecniche di filtraggio che di avvolgimento. Se volete approfondire le tecniche di selezione delle caratteristiche, un ottimo materiale di lettura completo, a mio parere, sarebbe “Feature Selection for Data and Pattern Recognition” di Urszula Stańczyk e Lakhmi C. Jain.