Aggiornamento 29-Maggio-2018: Lo scopo di questo articolo è triplice (1) Mostrare che avremo sempre bisogno di un modello di dati (sia fatto da umani che da macchine) (2) Mostrare che la modellazione fisica non è la stessa della modellazione logica. Infatti è molto diversa e dipende dalla tecnologia sottostante. Però abbiamo bisogno di entrambi. Ho illustrato questo punto usando Hadoop al livello fisico (3) Mostrare l’impatto del concetto di immutabilità sulla modellazione dei dati.
- La modellazione dimensionale è morta?
- Perché abbiamo bisogno di modellare i nostri dati?
- Perché abbiamo bisogno di modelli dimensionali?
- Data Modelling vs Dimensional Modelling
- Perché alcuni sostengono che la modellazione dimensionale è morta?
- Il Data Warehouse è morto Confusione
- Il malinteso Schema on Read
- Denormalizzazione rivisitata. Gli aspetti fisici del modello.
- Per portare la de-normalizzazione alla sua piena conclusione
- Distribuzione dei dati su un database relazionale distribuito (MPP)
- Distribuzione dei dati su Hadoop
- Modelli dimensionali su Hadoop
- Hadoop e le dimensioni che cambiano lentamente
- Evoluzione dello storage su Hadoop
- Il verdetto. I modelli dimensionali e gli schemi a stella sono obsoleti?
- Lettura complementare sulla modellazione dimensionale nell’era dei Big Data
La modellazione dimensionale è morta?
Prima di darvi una risposta a questa domanda facciamo un passo indietro e diamo un’occhiata a cosa intendiamo per modellazione dimensionale dei dati.
Perché abbiamo bisogno di modellare i nostri dati?
Al contrario di un malinteso comune, non è l’unico scopo dei modelli di dati di servire come un diagramma ER per progettare un database fisico. I modelli di dati rappresentano la complessità dei processi di business in un’impresa. Documentano importanti regole e concetti di business e aiutano a standardizzare la terminologia aziendale chiave. Forniscono chiarezza e aiutano a scoprire pensieri confusi e ambiguità sui processi di business. Inoltre, si possono usare i modelli di dati per comunicare con altre parti interessate. Non costruireste una casa o un ponte senza un progetto. Quindi perché costruire un’applicazione di dati come un data warehouse senza un piano?
Perché abbiamo bisogno di modelli dimensionali?
La modellazione dimensionale è un approccio speciale alla modellazione dei dati. Usiamo anche le parole data mart o star schema come sinonimi di un modello dimensionale. Gli schemi a stella sono ottimizzati per l’analisi dei dati. Date un’occhiata al modello dimensionale qui sotto. È abbastanza intuitivo da capire. Vediamo immediatamente come possiamo affettare e tagliare i dati dei nostri ordini per cliente, prodotto o data e misurare le prestazioni del processo aziendale degli ordini aggregando e confrontando le metriche.
Una delle idee centrali della modellazione dimensionale è quella di definire il livello più basso di granularità in un processo aziendale transazionale. Quando affettiamo e tagliamo e perforiamo i dati, questo è il livello foglia da cui non possiamo scendere ulteriormente. Detto in un altro modo, il livello più basso di granularità in uno schema a stella è un join del fatto a tutte le tabelle di dimensione senza alcuna aggregazione.
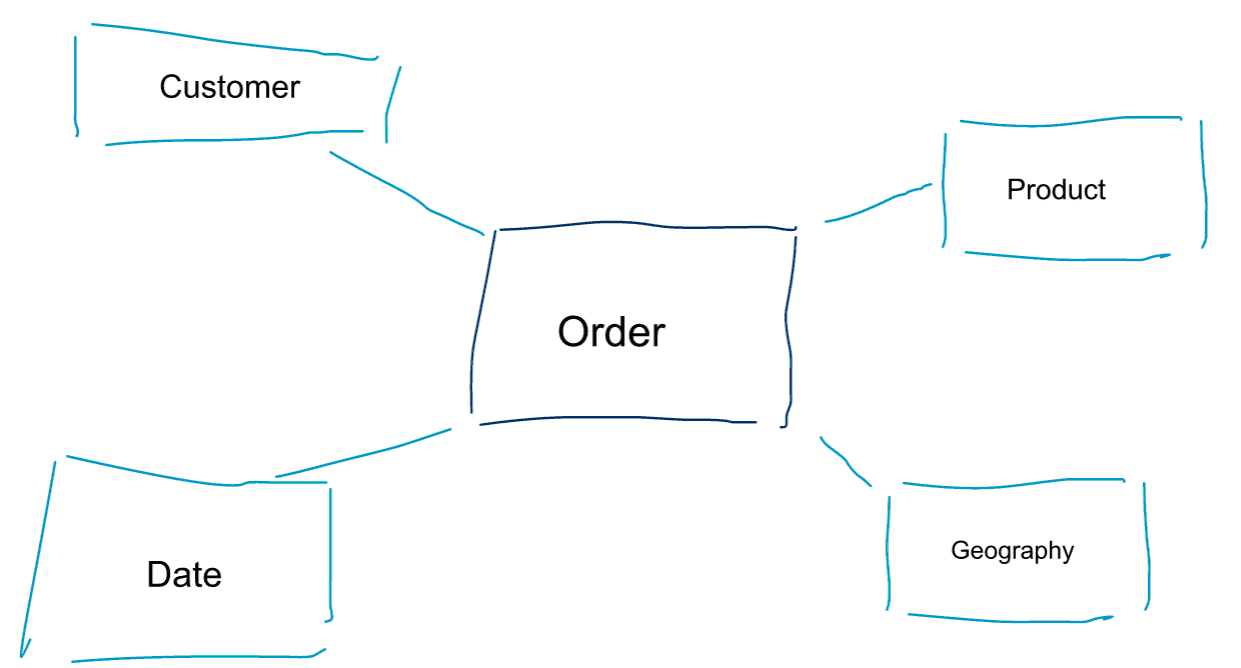
Data Modelling vs Dimensional Modelling
Nella modellazione standard dei dati miriamo ad eliminare la ripetizione dei dati e la ridondanza. Quando avviene un cambiamento nei dati abbiamo bisogno di cambiarli solo in un posto. Questo aiuta anche la qualità dei dati. I valori non vanno fuori sincrono in più posti. Dai un’occhiata al modello qui sotto. Contiene varie tabelle che rappresentano concetti geografici. In un modello normalizzato abbiamo una tabella separata per ogni entità. In un modello dimensionale abbiamo solo una tabella: geografia. In questa tabella, le città saranno ripetute più volte. Una volta per ogni città. Se il paese cambia il suo nome dobbiamo aggiornare il paese in molti posti
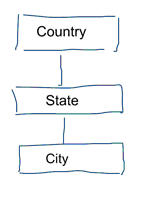
Nota: La modellazione dei dati standard è anche chiamata modellazione 3NF.
L’approccio standard alla modellazione dei dati non è adatto allo scopo per carichi di lavoro di Business Intelligence. Un sacco di tabelle portano a un sacco di join. Le giunzioni rallentano le cose. Nell’analisi dei dati le evitiamo dove possibile. Nei modelli dimensionali de-normalizziamo più tabelle correlate in un’unica tabella, ad esempio le varie tabelle del nostro esempio precedente possono essere pre-unite in una sola tabella: geografia.
Perché alcuni sostengono che la modellazione dimensionale è morta?
Penso che tu sia d’accordo che la modellazione dei dati in generale e la modellazione dimensionale in particolare è un esercizio abbastanza utile. Allora perché alcune persone sostengono che la modellazione dimensionale non è utile nell’era dei grandi dati e di Hadoop?
Come potete immaginare ci sono varie ragioni per questo.
Il Data Warehouse è morto Confusione
Prima di tutto, alcune persone confondono la modellazione dimensionale con il data warehousing. Sostengono che il data warehousing è morto e di conseguenza anche la modellazione dimensionale può essere consegnata alla pattumiera della storia. Questo è un argomento logicamente coerente. Tuttavia, il concetto di data warehouse è tutt’altro che obsoleto. Abbiamo sempre bisogno di dati integrati e affidabili per popolare i nostri cruscotti di BI. Se vuoi saperne di più, ti consiglio il nostro corso di formazione Big Data for Data Warehouse Professionals. Nel corso entro nei dettagli e spiego come il data warehouse sia più rilevante che mai. Mostrerò anche come gli strumenti e le tecnologie emergenti dei big data sono utili per il data warehousing.

Il malinteso Schema on Read
Il secondo argomento che sento spesso è il seguente. ‘Seguiamo un approccio schema on read e non abbiamo più bisogno di modellare i nostri dati’. Secondo me, il concetto di schema on read è uno dei più grandi malintesi nell’analisi dei dati. Sono d’accordo sul fatto che è utile memorizzare inizialmente i dati grezzi in un dump di dati che è leggero di schema. Tuttavia, questo argomento non dovrebbe essere usato come una scusa per non modellare del tutto i vostri dati. L’approccio dello schema in lettura è solo calciare giù il barattolo e la responsabilità per i processi a valle. Qualcuno deve ancora mordere la pallottola della definizione dei tipi di dati. Ogni processo che accede al dump di dati senza schema deve capire da solo cosa sta succedendo. Questo tipo di lavoro si aggiunge, è completamente ridondante, e può essere facilmente evitato definendo i tipi di dati e uno schema adeguato.
Denormalizzazione rivisitata. Gli aspetti fisici del modello.
Ci sono effettivamente degli argomenti validi per dichiarare obsoleti i modelli dimensionali? Ci sono effettivamente alcuni argomenti migliori dei due che ho elencato sopra. Richiedono una certa comprensione della modellazione fisica dei dati e del modo in cui funziona Hadoop. Abbiate pazienza.
Prima ho accennato brevemente a una delle ragioni per cui modelliamo i nostri dati dimensionalmente. È in relazione al modo in cui i dati sono memorizzati fisicamente nel nostro negozio di dati. Nella modellazione standard dei dati, ogni entità del mondo reale ha la propria tabella. Lo facciamo per evitare la ridondanza dei dati e il rischio di problemi di qualità dei dati che si insinuano nei nostri dati. Più tabelle abbiamo, più join abbiamo bisogno. Questo è lo svantaggio. Le tabelle sono costose, specialmente quando uniamo un gran numero di record dai nostri set di dati. Quando modelliamo i dati dimensionalmente, consolidiamo più tabelle in una sola. Diciamo che pre-uniamo o de-normalizziamo i dati. Ora abbiamo meno tabelle, meno join, e di conseguenza una minore latenza e migliori prestazioni delle query.
Partecipa alla discussione di questo post su LinkedIn
Per portare la de-normalizzazione alla sua piena conclusione
Perché non portare la de-normalizzazione alla sua piena conclusione? Sbarazzarsi di tutte le giunzioni e avere solo una singola tabella dei fatti? In effetti questo eliminerebbe del tutto la necessità di qualsiasi join. Tuttavia, come potete immaginare, ha alcuni effetti collaterali. Prima di tutto, aumenta la quantità di memoria richiesta. Ora abbiamo bisogno di memorizzare molti dati ridondanti. Con l’avvento dei formati di archiviazione a colonne per l’analisi dei dati, questo è meno preoccupante al giorno d’oggi. Il problema maggiore della de-normalizzazione è il fatto che ogni volta che il valore di uno degli attributi cambia dobbiamo aggiornare il valore in più posti – possibilmente migliaia o milioni di aggiornamenti. Un modo per aggirare questo problema è quello di ricaricare completamente i nostri modelli ogni notte. Spesso questo sarà molto più veloce e facile che applicare un gran numero di aggiornamenti. I database colonnari tipicamente adottano il seguente approccio. Memorizzano prima gli aggiornamenti dei dati in memoria e li scrivono asincronicamente su disco.
Distribuzione dei dati su un database relazionale distribuito (MPP)
Quando si creano modelli dimensionali su Hadoop, ad esempio Hive, SparkSQL ecc. dobbiamo capire meglio una caratteristica fondamentale della tecnologia che la distingue da un database relazionale distribuito (MPP) come Teradata ecc. Quando si distribuiscono i dati tra i nodi in un MPP abbiamo il controllo sul posizionamento dei record. In base alla nostra strategia di partizionamento, ad esempio hash, lista, range, ecc. possiamo collocare le chiavi dei singoli record tra le schede dello stesso nodo. Con la co-località dei dati garantita, i nostri join sono super-veloci poiché non abbiamo bisogno di inviare alcun dato attraverso la rete. Date un’occhiata all’esempio qui sotto. I record con lo stesso ORDER_ID dalle tabelle ORDER e ORDER_ITEM finiscono sullo stesso nodo.
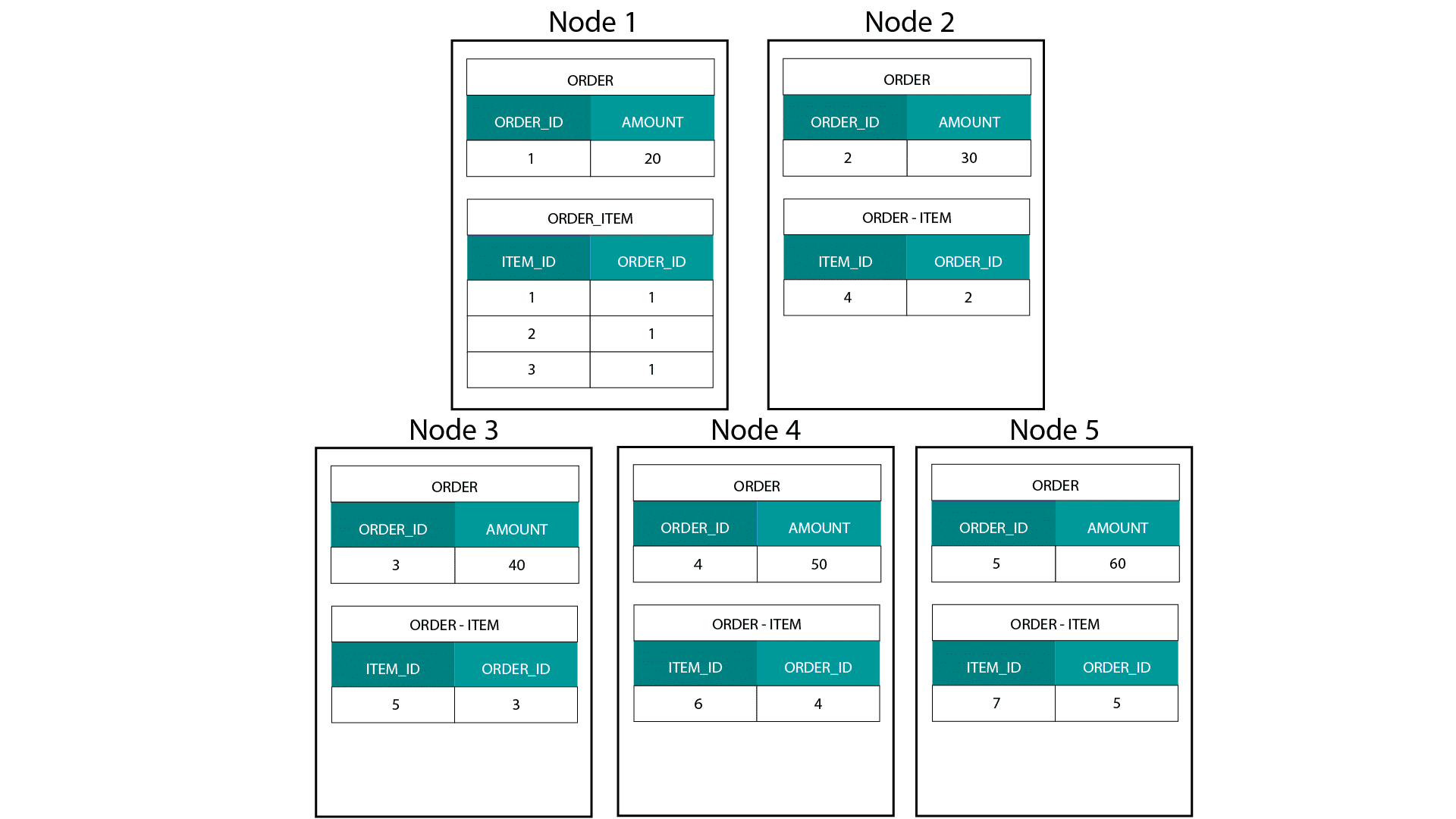
Le chiavi per order_id della tabella order e order_item sono co-localizzate sugli stessi nodi.
Distribuzione dei dati su Hadoop
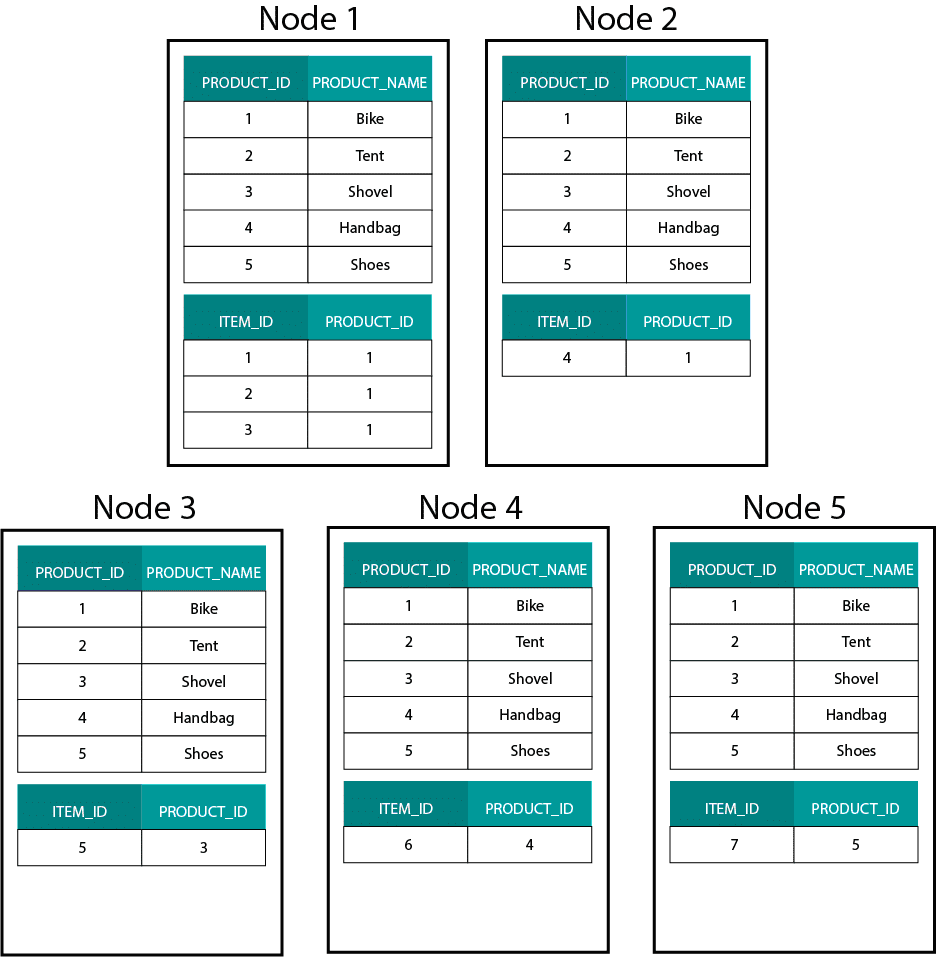
Questo è molto diverso dai sistemi basati su Hadoop. Lì dividiamo i nostri dati in pezzi di grandi dimensioni e li distribuiamo e replichiamo attraverso i nostri nodi sul Hadoop Distributed File System (HDFS). Con questa strategia di distribuzione dei dati non possiamo garantire la co-località dei dati. Dai un’occhiata all’esempio qui sotto. I record per la chiave ORDER_ID finiscono su nodi diversi.
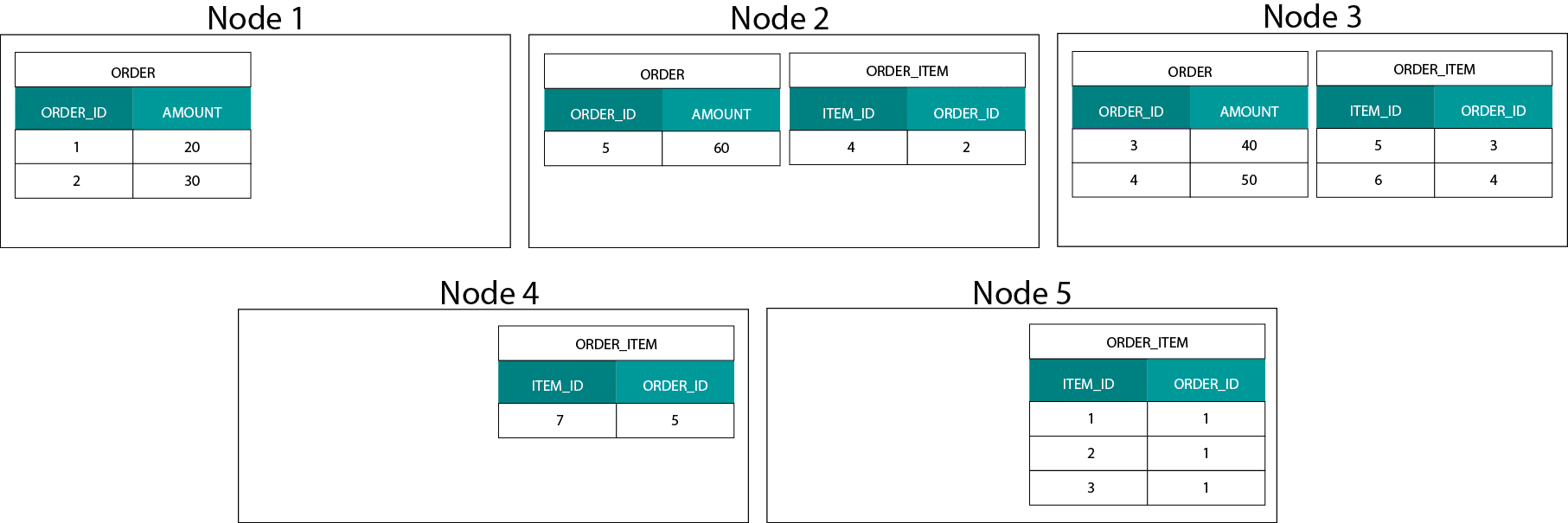
Per fare un join, dobbiamo inviare i dati attraverso la rete, il che ha un impatto sulle prestazioni.
Una strategia per affrontare questo problema è replicare una delle tabelle di join su tutti i nodi del cluster. Questo è chiamato broadcast join e noi usiamo la stessa strategia su un MPP. Come potete immaginare, funziona solo per piccole tabelle di ricerca o di dimensione.
Come facciamo allora quando abbiamo una grande tabella di fatti e una grande tabella di dimensione, ad esempio cliente o prodotto? O anche quando abbiamo due grandi tabelle dei fatti.
Modelli dimensionali su Hadoop
Per aggirare questo problema di prestazioni possiamo de-normalizzare le grandi tabelle delle dimensioni nella nostra tabella dei fatti per garantire che i dati siano co-localizzati. Possiamo trasmettere le tabelle di dimensione più piccole su tutti i nostri nodi.
Per unire due grandi tabelle dei fatti possiamo annidare la tabella con la granularità più bassa dentro la tabella con la granularità più alta, ad esempio una grande tabella ORDER_ITEM annidata dentro la tabella ORDER. I moderni motori di query come Impala o Drill ci permettono di appiattire questi dati

Questa strategia di annidamento dei dati è anche utile per i concetti dolorosi di Kimball come le tabelle ponte per rappresentare le relazioni M:N in un modello dimensionale.
Hadoop e le dimensioni che cambiano lentamente
Il salvataggio sul File System di Hadoop è immutabile. In altre parole si possono solo inserire e aggiungere record. Non è possibile modificare i dati. Se venite da un background di data warehouse relazionale, questo può sembrare un po’ strano all’inizio. Tuttavia, sotto il cofano i database funzionano in modo simile. Memorizzano tutte le modifiche ai dati in un registro di scrittura immutabile (conosciuto in Oracle come redo log) prima che un processo aggiorni asincronicamente i dati nei file di dati.
Che impatto ha l’immutabilità sui nostri modelli dimensionali? Potreste ricordare il concetto di Slowly Changing Dimensions (SCDs) dal vostro corso di modellazione dimensionale. Le SCD preservano opzionalmente la storia delle modifiche agli attributi. Ci permettono di riportare le metriche rispetto al valore di un attributo in un determinato momento. Questo non è però il comportamento predefinito. Per default aggiorniamo le tabelle delle dimensioni con gli ultimi valori. Quindi quali sono le nostre opzioni su Hadoop? Ricordate! Non possiamo aggiornare i dati. Possiamo semplicemente rendere SCD il comportamento predefinito e controllare qualsiasi cambiamento. Se vogliamo eseguire dei report sui valori attuali, possiamo creare una vista sopra l’SCD che recupera solo l’ultimo valore. Questo può essere fatto facilmente usando le funzioni di windowing. In alternativa, possiamo eseguire un cosiddetto servizio di compattazione che crea fisicamente una versione separata della tabella delle dimensioni con solo gli ultimi valori.
Evoluzione dello storage su Hadoop
Queste limitazioni di Hadoop non sono passate inosservate ai fornitori delle piattaforme Hadoop. In Hive ora abbiamo transazioni ACID e tabelle aggiornabili. Sulla base del numero di problemi importanti aperti e della mia esperienza personale, questa caratteristica non sembra essere ancora pronta per la produzione. Cloudera ha adottato un approccio diverso. Con Kudu hanno creato un nuovo formato di archiviazione aggiornabile che non si trova su HDFS ma sul file system locale del sistema operativo. Si sbarazza completamente delle limitazioni di Hadoop ed è simile allo strato di archiviazione tradizionale in un MPP a colonne. In generale, è probabilmente meglio eseguire qualsiasi caso di utilizzo di BI e dashboard su un MPP, ad esempio Impala + Kudu, piuttosto che su Hadoop. Detto questo, gli MPP hanno delle limitazioni proprie quando si tratta di resilienza, concorrenza e scalabilità. Quando ci si imbatte in queste limitazioni, Hadoop e il suo cugino stretto Spark sono buone opzioni per i carichi di lavoro di BI. Copriamo tutte queste limitazioni nel nostro corso di formazione Big Data for Data Warehouse Professionals e facciamo raccomandazioni su quando usare un RDBMS e quando usare SQL su Hadoop/Spark.
Il verdetto. I modelli dimensionali e gli schemi a stella sono obsoleti?
Sappiamo tutti che Ralph Kimball è andato in pensione. Ma le sue idee e concetti principali sono ancora validi e vivono. Dobbiamo adattarli alle nuove tecnologie e tipi di memorizzazione, ma aggiungono ancora valore.
Insegnami i Big Data per far avanzare la mia carriera
Lettura complementare sulla modellazione dimensionale nell’era dei Big Data
Tom Breur: Il passato e il futuro della modellazione dimensionale
Edosa Odaro: 5 suggerimenti radicali per una rapida integrazione dei Big Data – Il modello anti Data Warehouse