I nostri sforzi per la connettività si concentrano sull’espansione dell’accesso e dell’adozione di internet in tutto il mondo. Questo include il nostro lavoro su tecnologie come Terragraph, la nostra collaborazione con gli operatori mobili sugli sforzi per espandere l’accesso rurale, il nostro lavoro come parte del Telecom Infra Project, e programmi come Free Basics. Mentre abbiamo continuato a lavorare su Free Basics, abbiamo ascoltato i feedback e le raccomandazioni della società civile e di altre parti interessate. Abbiamo sviluppato Discover specificamente per affrontare e incorporare quelle raccomandazioni in un nuovo prodotto che supporta la connettività. Oggi, Facebook Connectivity e i nostri partner di Bitel, Claro, Entel e Movistar stanno lanciando una prova di Discover in Perù.
Fornire questo servizio mantenendo le persone al sicuro da potenziali rischi per la sicurezza è stata una sfida tecnica difficile. Volevamo sviluppare un modello che ci permettesse di presentare in modo sicuro le pagine web di tutti i domini disponibili, comprese le loro risorse (script, media, fogli di stile, ecc.). Qui di seguito, camminiamo attraverso il modello che abbiamo costruito, le scelte architettoniche uniche che abbiamo fatto lungo la strada, e i passi che abbiamo preso per mitigare i rischi.
- Da dove siamo partiti
- Architettura iniziale
- Design del dominio
- Cookies
- Migliorare ciò che avevamo costruito
- Miglioramenti dell’architettura in Discover
- JavaScript e la fissazione dei cookie
- Soluzione a due frame
- Frame interno
- Frame esterno
- Interazione con la pagina
- Fissazione asincrona del cookie
- Clickjacking
- Phishing
- Client-side cookies
- Protocollo Bootstrap
- Con protocollo localStorage
- Senza protocollo localStorage
Da dove siamo partiti
Per Free Basics, la nostra sfida era quella di trovare un modo per fornire un servizio a costo zero alle persone che utilizzano il web mobile, anche su telefoni con funzionalità senza supporto di app di terze parti. I partner degli operatori di telefonia mobile potevano fornire il servizio, ma i vincoli di rete e di apparecchiature gateway significavano che solo il traffico verso certe destinazioni (di solito intervalli di indirizzi IP o un elenco di nomi di dominio) poteva essere reso gratuito. Con più di 100 partner a livello globale e il tempo e la difficoltà di cambiare le configurazioni delle apparecchiature di rete dei carrier, ci siamo resi conto che dovevamo trovare un nuovo approccio.
Questo nuovo approccio ci ha richiesto di costruire prima un servizio proxy basato sul web dove l’operatore potesse rendere il servizio disponibile gratuitamente a un singolo dominio: freebasics.com. Da lì, avremmo recuperato le pagine web per conto dell’utente e le avremmo consegnate al suo dispositivo. Anche sui browser moderni, ci sono alcune preoccupazioni con le architetture proxy basate sul web. Sul web, i clienti sono in grado di valutare le intestazioni HTTP di sicurezza come la condivisione delle risorse cross-origin (CORS) e la politica di sicurezza dei contenuti (CSP) e fare uso di cookie direttamente dal sito. Ma in una configurazione di server proxy, il cliente sta interagendo con il proxy, e il proxy agisce come un cliente del sito. Il proxy di siti web di terze parti attraverso un singolo spazio dei nomi viola alcuni presupposti su come i cookie vengono memorizzati, quanto accesso hanno gli script per leggere o modificare il contenuto, e come CORS e CSP vengono valutati.
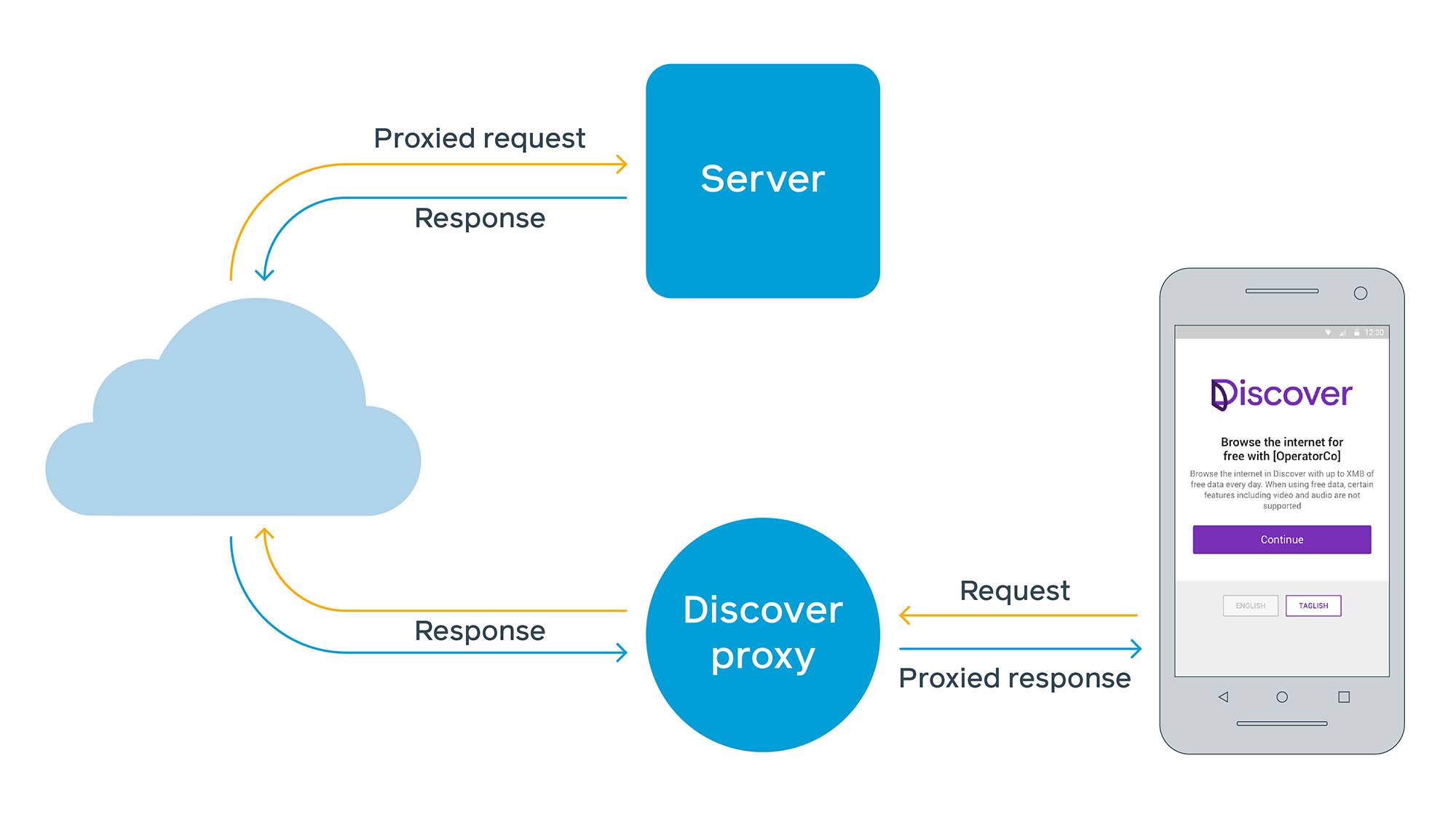
Per affrontare queste preoccupazioni, inizialmente abbiamo imposto alcune semplici limitazioni, tra cui quali siti potevano essere visitati con Free Basics e l’impossibilità di eseguire script. Quest’ultimo è diventato più di un problema nel tempo, dato che molti siti web, inclusi quelli mobili, hanno iniziato a fare affidamento su JavaScript per funzionalità critiche, incluso il rendering dei contenuti.
Architettura iniziale
Design del dominio
Per accomodare la funzionalità limitata di molti gateway di operatori mobili, abbiamo considerato architetture alternative, incluse:
- Una soluzione cooperativa in cui i siti web possono assegnare un sottodominio (ad es,
free.example.com) e risolverlo al nostro spazio IP affinché gli operatori lo rendano gratuito per l’utente.
Questa soluzione aveva dei pro:
- Permetteva una comunicazione diretta end-to-end tra client e server.
- Richiedeva un intervento minimo sul lato proxy.
Tuttavia, aveva anche alcuni contro:
- I siti dovevano optare per questo schema, sostenendo costi di ingegneria extra per i proprietari dei siti.
- I browser dovevano richiedere un dominio specifico attraverso la Server Name Indication (SNI), così il proxy avrebbe saputo dove connettersi. Tuttavia, il supporto per SNI non è universale, il che rende questa soluzione meno fattibile.
- Se gli abbonati navigassero accidentalmente su
example.comdirettamente, piuttosto che sul sottodominiofree.example.com, incorrerebbero in spese – e non verrebbero necessariamente reindirizzati al sottodominio a meno che l’operatore non abbia implementato qualche logica extra.
- Incapsulamento IPv4-in-IPv6, dove possiamo incapsulare l’intero spazio IPv4 in una singola sottorete IPv6 di dati liberi. Un resolver DNS personalizzato risolve quindi IPv4 ricorsivamente e risponde con risposte IPv6 incapsulate.
Questa soluzione aveva anche dei pro:
- Non richiedeva la cooperazione del proprietario del sito web.
- Non c’era bisogno di SNI per risolvere l’IP remoto.
E i contro:
- I browser avrebbero visto il dominio
www.example.com.freebasics.com, ma il certificatowww.example.comavrebbe dato luogo a un errore. - Solo pochi carrier gateway supportavano IPv6 in questo modo.
- Anche meno dispositivi supportavano IPv6, specialmente le vecchie versioni del sistema operativo.
Nessuna di queste era una soluzione valida. Alla fine, abbiamo deciso che la migliore architettura possibile sarebbe stata l’origin collapsing, dove il nostro proxy gira all’interno di un singolo namespace di dominio origin-collapsed sotto freebasics.com. Gli operatori possono quindi consentire il traffico verso questa destinazione più facilmente e mantenere le loro configurazioni semplici. Ogni origine di terze parti è codificata in un sottodominio, così possiamo garantire che la risoluzione dei nomi dirigerà sempre il traffico verso un IP libero.
Per esempio:
https://example.com/path/?query=value#anchor
Si riscrive in:
https://https-example-com.0.freebasics.com/path/?query=value#anchor
C’è un’estesa logica lato server per assicurarsi che i link e gli href siano trasformati correttamente. Questa stessa logica aiuta a garantire che anche i siti solo HTTP siano consegnati in modo sicuro su HTTPS su Free Basics tra il client e il proxy. Questo schema di riscrittura degli URL ci permette di utilizzare un singolo spazio dei nomi e un certificato TLS, piuttosto che richiedere un certificato separato per ogni sottodominio su Internet.
Tutte le origini internet diventano fratelli sotto 0.freebasics.com, il che solleva alcune considerazioni sulla sicurezza. Non siamo stati in grado di trarre vantaggio dall’aggiunta del dominio alla Public Suffix List, poiché avremmo dovuto emettere un cookie diverso per ogni origine, il che avrebbe superato i limiti dei cookie del browser.
Cookies
A differenza dei client web, che possono utilizzare i cookie direttamente dal sito, il servizio proxy richiede una configurazione diversa. Free Basics memorizza i cookie degli utenti sul lato server per diverse ragioni:
- I browser mobili di livello inferiore spesso hanno un supporto limitato per i cookie. Se emettiamo anche solo un cookie per sito sotto il nostro dominio proxy, potremmo essere limitati a impostare solo decine di cookie. Se Free Basics dovesse impostare cookie lato client per ogni sito sotto
0.freebasics.com, i vecchi browser raggiungerebbero rapidamente i limiti di memorizzazione dei cookie locali – e anche i browser moderni raggiungerebbero un limite per dominio. - I vincoli dello spazio dei nomi di dominio che dovevamo implementare precludevano anche l’uso di cookie fraterni e gerarchici. Per esempio, un cookie impostato su qualsiasi sottodominio a
.example.comsarebbe normalmente leggibile in qualsiasi altro sottodominio. In altre parole, sea.example.comimposta un cookie su.example.com, allorab.example.comdovrebbe essere in grado di leggerlo. Nel caso di Free Basics,a-example-com.0.freebasics.comimposterebbe un cookie suexample.com.0.freebasics.com, che non è permesso dallo standard. Poiché questo non funziona, altre origini, comeb-example-com.0.freebasics.com, non sarebbero in grado di accedere ai cookie impostati per il loro dominio padre.
Per permettere al servizio proxy di accedere a questo barattolo di cookie lato server, Free Basics sfrutta due cookie lato client:
- Il cookie
datr, un identificatore del browser utilizzato per l’integrità del sito. - Il
ick(internet cookie key), che contiene una chiave crittografica usata per criptare il cookie jar lato server. Poiché questa chiave è memorizzata solo sul lato client, il cookie jar lato server non può essere decifrato da Free Basics quando l’utente non sta utilizzando il servizio.
Per aiutare a proteggere la privacy e la sicurezza dell’utente quando si memorizzano i loro cookie in un cookie jar lato server, ci assicuriamo che:
- I cookie lato server sono criptati con un
ickche è tenuto solo sul client. - Quando il client fornisce il
ick, viene dimenticato dal server in ogni richiesta senza mai essere registrato. - Segnaliamo entrambi i cookie lato client come
SecureeHttpOnly. - Facciamo l’hash dell’indice di un cookie usando la chiave lato client in modo che il cookie non sia riconducibile all’utente quando la chiave non è presente.
Permettendo l’esecuzione di script si rischia la fissazione dei cookie lato server. Per evitare questo, escludiamo l’uso di JavaScript da Free Basics. Inoltre, anche se qualsiasi sito web può essere parte di Free Basics, esaminiamo ogni sito individualmente per potenziali vettori di abuso, indipendentemente dal contenuto.
Migliorare ciò che avevamo costruito
Per sostenere un modello che serve qualsiasi sito web, con la possibilità di eseguire script in modo più sicuro, abbiamo dovuto ripensare significativamente la nostra architettura per prevenire minacce, come gli script in grado di leggere o fissare i cookie dell’utente. JavaScript è estremamente difficile da analizzare e impedire l’esecuzione di codice non previsto.
Come esempio, ecco alcuni modi in cui un attaccante potrebbe iniettare codice che dovremmo essere in grado di filtrare:
setTimeout();location = ' javascript:alert(1) <!--';location = 'javascript\n:alert(1) <!--';location = '\x01javascript:alert(1) <!--';var location = 'javascript:alert(1)';for(location in {'javascript:alert(1)':0}); = 'javascript:alert(1)';location.totally_not_assign=location.assign;location.totally_not_assign('javascript:alert(1)');location] = 'javascript:alert(1)';Reflect.set(location, 'href', 'javascript:alert(1)')new Proxy(location, {}).href = 'javascript:alert(1)'Object.assign(window, {location: 'javascript:alert(1)'});Object.assign(location, {href: 'javascript:alert(1)'});location.hash = '#%0a alert(1)';location.protocol = 'javascript:';Il modello che abbiamo ideato estende il design di Free Basics, ma protegge anche il cookie che memorizza la chiave di crittografia dall’essere sovrascritto dagli script. Usiamo un frame esterno di cui ci fidiamo per attestare che il frame interno, che presenta contenuti di terze parti, non sia stato manomesso. La sezione seguente mostra in dettaglio come mitigare la fissazione della sessione e altri attacchi, come il phishing e il clickjacking. Abbiamo delineato un metodo per servire in modo sicuro i contenuti di terze parti, pur consentendo l’esecuzione di JavaScript.
Miglioramenti dell’architettura in Discover
I riferimenti al dominio a questo punto cambieranno al nostro nuovo dominio, un discoverapp.com simile all’origine.
Nel permettere JavaScript da siti di terze parti, abbiamo dovuto riconoscere che questo abilita alcuni vettori per i quali dovevamo prepararci, poiché gli script possono modificare e riscrivere i link, accedere a qualsiasi parte del DOM, e, nel peggiore dei casi, fissare i cookie lato client.
La soluzione che abbiamo trovato doveva affrontare la fissazione dei cookie, quindi invece di cercare di analizzare e bloccare certe chiamate di script, abbiamo deciso di rilevarla mentre accade e renderla inutile. Questo si ottiene come segue:
- Al momento dell’iscrizione, generiamo un nuovo
ickcasuale e sicuro. - Inviamo
ickal browser come unHttpOnlycookie. - Poi HMAC un valore chiamato
icktda un digest di entrambiickedatr(per evitare la fissazione di entrambi) e memorizziamo una copia diicktsul client, in una posizione inlocalStoragein cui un potenziale attaccante non può scrivere. La posizione che usiamo èhttps://www.0.discoverapp.com, che non serve mai contenuti di terze parti. Poiché questa origine è sorella di tutte le origini di terze parti, l’abbassamento del dominio o qualsiasi altro tipo di modifica del dominio non può verificarsi, e l’origine è considerata affidabile. - Inseriamo
ickt, derivato dal cookieickvisto nella richiesta, all’interno dell’HTML in ogni risposta proxy di terze parti. - Quando la pagina viene caricata, confrontiamo il
icktincorporato con ilicktaffidabile usandowindow.postMessage(), e invalidiamo la sessione se c’è una mancata corrispondenza cancellando i cookiedatreick. - Impediamo l’interazione dell’utente con la pagina fino al completamento di questo processo.
Come ulteriore protezione, impostiamo un nuovo cookie datr se rileviamo più cookie nella stessa posizione, incorporando un timestamp in modo da poter usare sempre il più recente.
Soluzione a due frame
Per la validazione, abbiamo bisogno di un modo per una pagina di terzi di interrogare il valore ickt e validarlo. Lo facciamo incorporando il sito di terze parti all’interno di un <iframe> in una pagina all’origine sicura e iniettando un pezzo di JavaScript nel sito di terze parti. Costruiamo un frame esterno sicuro e un frame interno di terze parti.
Frame interno
Con il frame interno, iniettiamo uno script in ogni pagina proxy che serviamo. Iniettiamo anche il valore ickt calcolato dal ick visto nella richiesta insieme ad esso. Il comportamento del frame interno è il seguente:
- Controllo con il frame esterno:
-
postMessagein alto conicktincorporato nella pagina. - Attendere.
- Se lo script riceve un riconoscimento dall’origine sicura, lasciamo che l’utente interagisca con la pagina.
- Se lo script aspetta troppo a lungo o ottiene una risposta da un’origine inaspettata, facciamo navigare il frame verso una schermata di errore senza contenuti di terze parti (la nostra pagina “Oops”), perché è possibile che il frame esterno non ci sia o sia diverso da quello che il frame interno si aspetta.
-
- Controlla con
parent:-
postMessageaparent. - Aspetta.
- Se lo script ottiene una risposta con
source===parente origine sotto.0.discoverapp.com, procederà. - Se lo script aspetta troppo a lungo, o ottiene una risposta da un’origine inaspettata, passeremo alla pagina “Oops”.
-
Alcune note sul frame interno:
- Anche se venisse aggirato, i potenziali attaccanti sarebbero in grado di fissare solo un’origine su cui possono ottenere l’esecuzione del codice, rendendo i vettori di fissazione dei cookie ridondanti.
- Prevediamo che un’origine benigna non eluderà deliberatamente il protocollo di messaggistica interno-esterno.
Frame esterno
Il frame esterno è lì per attestare che il frame interno è coerente:
- Ci assicuriamo che il frame esterno sia sempre il frame superiore con JavaScript e
X-Frame-Options: DENY. - Attendiamo
postMessage. - Se il frame esterno riceve un messaggio:
- Si tratta di un’origine del frame interno?
- Se sì, riporta il valore
icktcorretto?- Se sì, invia un messaggio di riconoscimento.
- Se no, cancella la sessione, elimina tutti i cookie e passa a un’origine sicura.
- Se il frame esterno non riceve un messaggio per alcuni secondi o il subframe non è il frame interno più alto, rimuoviamo la posizione dalla barra degli indirizzi del frame sicuro.
Interazione con la pagina
Per evitare condizioni di gara in cui una persona potrebbe inserire una password sotto un cookie fissato prima che il frame interno abbia completato la verifica, è importante impedire alle persone di interagire con la pagina prima che la sequenza di verifica del frame interno sia completata.
Per prevenire questo, il server aggiunge style="display:none" all’elemento <html> di ogni pagina. Il frame interno lo rimuove quando riceve la conferma del frame esterno.
Il codice JavaScript può ancora essere eseguito e le risorse sono ancora recuperate. Ma finché la persona non ha inserito alcun input nella pagina, il browser non fa nulla che un potenziale attaccante non avrebbe potuto fare semplicemente visitando il sito – a meno che il sito non sia già vulnerabile al cross-site request forgery (CSRF).
Scegliendo questa soluzione, abbiamo dovuto risolvere altri possibili risultati, in particolare:
- Fissazione asincrona dei cookie.
- Clickjacking dovuto al framing.
- Phishing che impersona il dominio Discover.
Fino a questo punto, le protezioni che abbiamo implementato hanno tenuto conto delle fissazioni sincrone, ma possono anche avvenire in modo asincrono. Per prevenire questo, usiamo un classico metodo di prevenzione CSRF. Richiediamo ai POST di portare un parametro di query con il datr visto al caricamento della pagina. Poi confrontiamo il parametro della query con il cookie datr visto nella richiesta. Se non corrispondono, non soddisfiamo la richiesta.
Per evitare la fuga di datr, incorporiamo una versione criptata del datr all’interno del frame interno e ci assicuriamo che questo parametro di query sia aggiunto ad ogni oggetto <form> e XHR. Poiché la pagina non può ricavare il token datr da sola, il datr aggiunto è quello visto in quel momento.
Per le richieste anonime, richiediamo che abbiano anche il parametro di query datr. L’anonimato è preservato perché non lo facciamo trapelare al sito terzo – manca il cookie ick, quindi non possiamo usare il barattolo dei cookie. Tuttavia, in questo caso, non siamo in grado di validare contro il cookie datr, quindi i POST anonimi possono essere fatti sotto sessioni fissate. Ma poiché sono anonimi e senza il ick, nessuna informazione sensibile può trapelare.
Clickjacking
Quando un sito invia X-Frame-Options: DENY, non verrà caricato in un frame interno. Questa intestazione è usata dai siti web per prevenire l’esposizione a certi tipi di attacchi, come il clickjacking. Rimuoviamo questa intestazione dalla risposta HTTP ma chiediamo al frame interno di verificare che parent sia il frame della finestra top utilizzando postMessage. Se la convalida fallisce, portiamo l’utente alla pagina “Oops”.
Phishing
La “barra degli indirizzi” che forniamo nel frame sicuro è usata per esporre all’utente l’origine del frame interno più in alto. Tuttavia, può essere copiata da siti di phishing che impersonano Discover. Impediamo ai link malevoli di navigare lontano da Discover impedendo la navigazione dall’alto usando <iframe sandbox>. Il frame esterno può essere evitato solo navigando direttamente verso un altro sito.
Il document.cookie permette a JavaScript di leggere e modificare i cookies che non sono contrassegnati HttpOnly. Supportare questo in modo sicuro è impegnativo in un sistema che mantiene i cookie sul server.
Accesso ai cookie: Quando una richiesta viene ricevuta, il proxy enumera tutti i cookie che sono visibili a quell’origine. Quindi allegherà un carico utile JSON alla pagina di risposta. Il codice lato client viene iniettato per shimare document.cookie e rendere questi cookie visibili ad altri script, come se fossero veri cookie lato client.
Modificare i cookie: Se gli script sono autorizzati a impostare arbitrariamente i cookie che il server poi accetta, questo potrebbe portare alla fissazione, dove l’origine evil.com potrebbe impostare un cookie sensibile su example.com.
Fidarsi delle capacità CORS del browser non sarebbe sufficiente in questo caso – l’origine a.example.com che cerca di impostare un cookie su example.com sarà bloccato dal browser, poiché queste origini sono fratelli e non gerarchiche.
Anche così, quando il server riceve un nuovo cookie impostato dal client, non può far rispettare in modo sicuro se il dominio di destinazione è consentito; l’origine dell’autore è nota solo sul client e non è sempre inviata al server in un modo di cui ci si possa fidare.
Per forzare il client a dimostrare che è idoneo a impostare i cookie su un dominio specifico, il server invierà, oltre al payload JSON, una lista di token crittografici per ciascuna delle origini in cui l’origine richiedente è autorizzata a impostare i cookie. Questi token sono salati con il valore ick, quindi non possono essere trasferiti tra utenti.
Lo shim lato client per document.cookie si occupa di risolvere e incorporare il token nel testo effettivo del cookie che viene inviato al proxy. Il proxy può quindi verificare che l’origine di scrittura abbia effettivamente posseduto il token per scrivere nel dominio di destinazione del cookie, e lo memorizza nel barattolo dei cookie lato server, inviandolo nuovamente al client la prossima volta che la pagina viene richiesta.
Protocollo Bootstrap
Il modello contiene tre tipi di origine: origine portale (Discover portal, ecc.), origine sicura (frame esterno) e origine di riscrittura (frame interno). Ognuno ha una necessità diversa:
- L’origine portale richiede
datr. - L’origine sicura richiede
ickt. - L’origine di riscrittura richiede
datreick.
Con protocollo localStorage
Ecco una rappresentazione del processo di bootstrap per la maggior parte dei moderni browser mobili:
È importante notare che per evitare la riflessione, l’endpoint di bootstrap all’origine sicura emette sempre un nuovo ick e ickt; ick non dipende mai dall’input dell’utente. Si noti che poiché abbiamo impostato domain=.discoverapp.com su entrambi ick e datr, essi sono disponibili in tutti i tipi di origine, e ickt è disponibile solo sull’origine sicura.
Senza protocollo localStorage
Perché alcuni browser, come Opera Mini (popolare in molti paesi dove Discover opera), non supportano localStorage, non siamo in grado di memorizzare i valori ick e ickt. Questo significa che dobbiamo usare un protocollo diverso:
Abbiamo deciso di separare l’origine di riscrittura dall’origine sicura in modo che non condividano lo stesso suffisso host come da Public Suffix List. Usiamo www.0.discoverapp.com per memorizzare la copia sicura di ickt (come cookie), e spostiamo tutte le origini di terze parti sotto 0.i.org. In un browser ben educato, impostare un cookie sull’origine sicura lo renderà inaccessibile a tutte le origini di riscrittura.
Da quando le origini sono separate, il nostro processo di bootstrap diventa un processo in due fasi. Prima, potevamo impostare ick nella stessa richiesta in cui abbiamo fornito localStorage con ickt. Ora, abbiamo bisogno di avviare due origini, in richieste separate, senza aprire i vettori di fissazione di ick.
Lo risolviamo avviando prima l’origine sicura con il cookie ickt e dando all’utente una versione cifrata di ick, con una chiave nota solo al proxy. Il icktesto cifrato è accompagnato da una nonce che può essere usata per decifrare quel particolare ick nell’origine di riscrittura e impostare un cookie, ma solo una volta.
Un attaccante potrebbe scegliere di:
- Utilizzare la nonce per rivelare il cookie
ick. - Passarlo all’utente per fissarne il valore.
In entrambi i casi, l’attaccante non può contemporaneamente conoscere e forzare un particolare valore ick su un utente. Il processo sincronizza anche datrtra le origini.
Questa architettura è stata sottoposta a sostanziali test di sicurezza interni ed esterni. Crediamo di aver sviluppato un design che è abbastanza robusto da resistere ai tipi di attacchi alle applicazioni web che vediamo in natura e fornire in modo sicuro la connettività che è sostenibile per gli operatori mobili. Dopo il lancio di Discover in Perù, stiamo progettando di lanciare ulteriori prove di Discover con gli operatori partner in un certo numero di altri paesi in cui abbiamo testato le caratteristiche del prodotto, tra cui Thailandia, Filippine e Iraq. Prevediamo che Discover sarà attivo in questi ulteriori paesi nelle prossime settimane, ed esploreremo ulteriori prove dove gli operatori partner vogliono partecipare.
Vorremmo ringraziare Berk Demir per il suo aiuto in questo lavoro.
Nel tentativo di essere più inclusivi nel nostro linguaggio, abbiamo modificato questo post per sostituire “whitelist” con “allowlist.”