- La funzione e la sua derivata sono entrambe monotone
- L’uscita è zero “centrica”
- L’ottimizzazione è più facile
- Derivata /Differenziale della funzione Tanh (f'(x)) si trova tra 0 e 1.
Cons:
- La derivata della funzione Tanh soffre di “Vanishing gradient and Exploding gradient problem”.(Uso ragionevole della funzione matematica esponenziale)
“Tanh è preferito alla funzione sigmoide perché è centrato su zero e i gradienti non sono limitati a muoversi in una certa direzione”
3. Funzione di attivazione ReLu (ReLu – Unità lineari rettificate):


ReLU è la funzione di attivazione non lineare che ha guadagnato popolarità nell’IA. La funzione ReLu è anche rappresentata come f(x) = max(0,x).
- La funzione e la sua derivata sono entrambe monotone.
- Principale vantaggio di usare la funzione ReLU- Non attiva tutti i neuroni allo stesso tempo.
- Efficiente dal punto di vista computazionale
- Derivata /Differenziale della funzione Tanh (f'(x)) sarà 1 se f(x) > 0 altrimenti 0.
- Converte molto velocemente
Cons:
- La funzione ReLu non è “zero-centrica”. 0 < uscita < 1, e rende l’ottimizzazione più difficile.
- Il neurone morto è il problema più grande.Questo è dovuto alla non-differenziabilità a zero.
“Problema del neurone morente/neurone morto: Poiché la derivata f'(x) di ReLu non è 0 per i valori positivi del neurone (f'(x)=1 per x ≥ 0), ReLu non si satura (exploid) e non vengono riportati neuroni morti (Vanishing neuron). La saturazione e il gradiente evanescente si verificano solo per valori negativi che, dati a ReLu, sono trasformati in 0- Questo è chiamato il problema del neurone morente.”
4. Funzione di attivazione di ReLu che perde:
La funzione leaky ReLU non è altro che una versione migliorata della funzione ReLU con l’introduzione della “pendenza costante”


- Leaky ReLU è definito per affrontare il problema del neurone morente/neurone morto.
- Il problema del neurone morente/neurone morto è affrontato introducendo una piccola pendenza che ha i valori negativi scalati da α permette ai loro neuroni corrispondenti di “rimanere vivi”.
- La funzione e la sua derivata sono entrambe monotone
- Permette il valore negativo durante la propagazione posteriore
- È efficiente e facile da calcolare.
- La derivata di Leaky è 1 quando f(x) > 0 e varia tra 0 e 1 quando f(x) < 0.
Cons:
- Leaky ReLU non fornisce previsioni coerenti per valori di input negativi.
5. Funzione di attivazione ELU (unità lineari esponenziali):

- ELU è anche proposto per risolvere il problema del neurone morente.
- Nessun problema di Dead ReLU
- Zero-centrico
Cons:
- Computing intensive.
- Simile a Leaky ReLU, anche se teoricamente migliore di ReLU, non ci sono attualmente buone prove nella pratica che ELU sia sempre migliore di ReLU.
- f(x) è monotono solo se alfa è maggiore o uguale a 0.
- f'(x) derivata di ELU è monotona solo se alfa sta tra 0 e 1.
- Convergenza lenta dovuta alla funzione esponenziale.
6. P ReLu (Parametric ReLU) Funzione di attivazione:

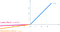
- L’idea di leaky ReLU può essere estesa ulteriormente.
- Invece di moltiplicare x con un termine costante possiamo moltiplicarlo con un “iperparametro (un parametro addestrabile)” che sembra funzionare meglio della leaky ReLU. Questa estensione di Leaky ReLU è conosciuta come Parametric ReLU.
- Il parametro α è generalmente un numero tra 0 e 1, ed è generalmente relativamente piccolo.
- Ha un leggero vantaggio su Leaky Relu grazie al parametro addestrabile.
- Gestire il problema del neurone che muore.
Cons:
- Simile al leaky Relu.
- f(x) è monotono quando a> o =0 e f'(x) è monotono quando a =1
7. Swish (A Self-Gated) Activation Function:(Sigmoid Linear Unit)

- Google Brain Team ha proposto una nuova funzione di attivazione, chiamata Swish, che è semplicemente f(x) = x – sigmoid(x).
- I loro esperimenti mostrano che Swish tende a funzionare meglio di ReLU su modelli più profondi attraverso una serie di set di dati impegnativi.
- La curva della funzione Swish è liscia e la funzione è differenziabile in tutti i punti. Questo è utile durante il processo di ottimizzazione del modello ed è considerato uno dei motivi per cui Swish supera ReLU.
- La funzione Swish è “non monotona”. Questo significa che il valore della funzione può diminuire anche quando i valori di input sono in aumento.
- La funzione è unbounded sopra e bounded sotto.
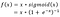
“Swish tende a eguagliare o superare continuamente il ReLu”
Nota che l’output della funzione swish può diminuire anche quando l’input aumenta. Questa è una caratteristica interessante e specifica di swish.(A causa del carattere non monotono)
f(x)=2x*sigmoide(beta*x)
Se pensiamo che beta=0 sia una versione semplice di Swish, che è un parametro imparabile, allora la parte sigmoide è sempre 1/2 e f (x) è lineare. D’altra parte, se il beta è un valore molto grande, la sigmoide diventa una funzione quasi a due cifre (0 per x<0,1 per x>0). Così f (x) converge alla funzione ReLU. Pertanto, la funzione standard Swish è selezionata come beta = 1. In questo modo, viene fornita un’interpolazione morbida (associando gli insiemi di valori variabili con una funzione nell’intervallo dato e la precisione desiderata). Eccellente! È stata trovata una soluzione al problema della scomparsa dei gradienti.
8.Softplus
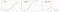
La funzione softplus è simile alla funzione ReLU, ma è relativamente più liscia.Funzione di Softplus o SmoothRelu f(x) = ln(1+exp x).
Derivata della funzione Softplus è f'(x) è funzione logistica (1/(1+exp x)).
Il valore della funzione va da (0, + inf).Sia f(x) che f'(x) sono monotonici.
9.Softmax o funzione esponenziale normalizzata:

La funzione “softmax” è anche un tipo di funzione sigmoide ma è molto utile per gestire problemi di classificazione multiclasse.
“Softmax può essere descritto come la combinazione di più funzioni sigmoidi.”
“La funzione Softmax restituisce la probabilità che un punto dati appartenga ad ogni singola classe.”
Costruendo una rete per un problema multiclasse, lo strato di output avrebbe tanti neuroni quante sono le classi dell’obiettivo.
Per esempio se hai tre classi, ci sarebbero tre neuroni nello strato di output. Supponiamo di avere l’output dei neuroni come .Applicando la funzione softmax su questi valori, si ottiene il seguente risultato – . Questi rappresentano la probabilità che il punto dei dati appartenga ad ogni classe. Dal risultato possiamo che l’input appartiene alla classe A.
“Nota che la somma di tutti i valori è 1.”
Quale è meglio usare? Come scegliere quella giusta?
Per essere onesti non c’è una regola dura e veloce per scegliere la funzione di attivazione.Non possiamo differenziare tra le funzioni di attivazione.Ogni funzione di attivazione ha i suoi pro e contro.Tutto il bene e il male sarà deciso in base alla traccia.
Ma in base alle proprietà del problema potremmo essere in grado di fare una scelta migliore per una facile e più rapida convergenza della rete.
- Le funzioni sigmoidi e le loro combinazioni generalmente funzionano meglio nel caso di problemi di classificazione
- Le funzioni sigmoidi e tanh sono talvolta evitate a causa del problema del gradiente che svanisce
- La funzione di attivazione ReLU è ampiamente usata nell’era moderna.
- In caso di neuroni morti nelle nostre reti a causa di ReLu, la funzione leaky ReLU è la scelta migliore
- La funzione ReLU dovrebbe essere usata solo negli strati nascosti
“Come regola generale, si può iniziare con l’uso della funzione ReLU e poi passare ad altre funzioni di attivazione nel caso in cui ReLU non dia risultati ottimali”
.