Metodo 1, cattivo: ORDER BY NEWID()
Facile da scrivere, ma funziona come spazzatura calda, calda perché scansiona l’intero indice clustered, calcolando NEWID() su ogni riga:
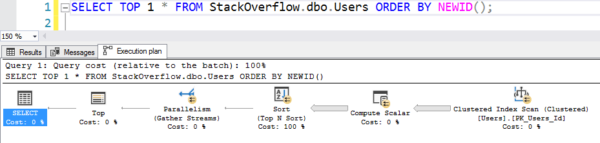
Il piano con la scansione
Ci sono voluti 6 secondi sulla mia macchina, andando in parallelo su più thread, usando decine di secondi di CPU per tutto quel calcolo e ordinamento. (E la tabella degli utenti non è nemmeno 1GB.)
Metodo 2, migliore ma strano: TABLESAMPLE
Questo è uscito nel 2005, e ha un sacco di problemi. È come scegliere una pagina a caso, e poi restituire un mucchio di righe da quella pagina. La prima riga è più o meno casuale, ma il resto no.
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Il piano sembra che stia facendo una scansione della tabella, ma sta facendo solo 7 letture logiche:
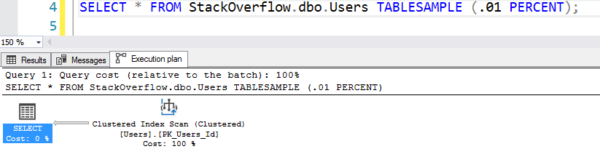
Il piano con la finta scansione
Ma ecco i risultati – si può vedere che salta a una pagina casuale di 8K e poi inizia a leggere le righe in ordine. Non sono davvero righe casuali.
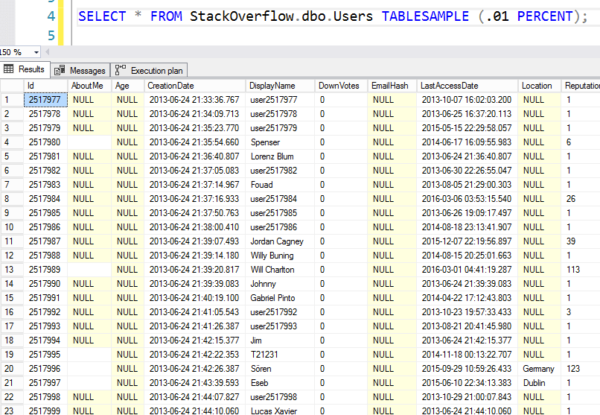
Casuali come i numeri della lotteria mafiosa
Puoi invece usare la dimensione del campione ROWS, ma ha dei risultati piuttosto strani. Per esempio, nella tabella Stack Overflow Users, quando ho detto TABLESAMPLE (50 ROWS), ho effettivamente ottenuto 75 righe. Questo perché SQL Server converte la dimensione della riga in una percentuale.
Metodo 3, migliore ma richiede codice: Chiave primaria casuale
Prendi il campo ID superiore della tabella, genera un numero casuale e cerca quell’ID. Qui, stiamo ordinando in base all’ID perché vogliamo trovare il primo record che esiste effettivamente (mentre un numero casuale potrebbe essere stato cancellato). Se volete 10 righe, dovrete chiamare il codice come questo 10 volte (o generare 10 numeri casuali e usare una clausola IN.)
Il piano di esecuzione mostra una scansione dell’indice clustered, ma sta prendendo solo una riga – stiamo parlando solo di 6 letture logiche per tutto quello che vedi qui, e finisce quasi istantaneamente:

Il piano che può
C’è un intoppo: se l’Id ha numeri negativi, non funzionerà come previsto. (Per esempio, diciamo che inizi il tuo campo di identità a -1 e passi -1, dirigendoti sempre verso il basso, come la mia morale.)
Metodo 4, OFFSET-FETCH (2012+)
Daniel Hutmacher ha aggiunto questo nei commenti:
E ha detto, “Ma funziona correttamente solo con un indice clustered. Immagino che sia perché farà la scansione delle righe (@rows) in un heap invece di fare una ricerca nell’indice.”
Bonus Track #1: Guardaci mentre discutiamo di questo
Vi siete mai chiesti com’è essere nella chat room della nostra azienda? Questa discussione di 10 minuti su Slack ti darà un’idea abbastanza buona:
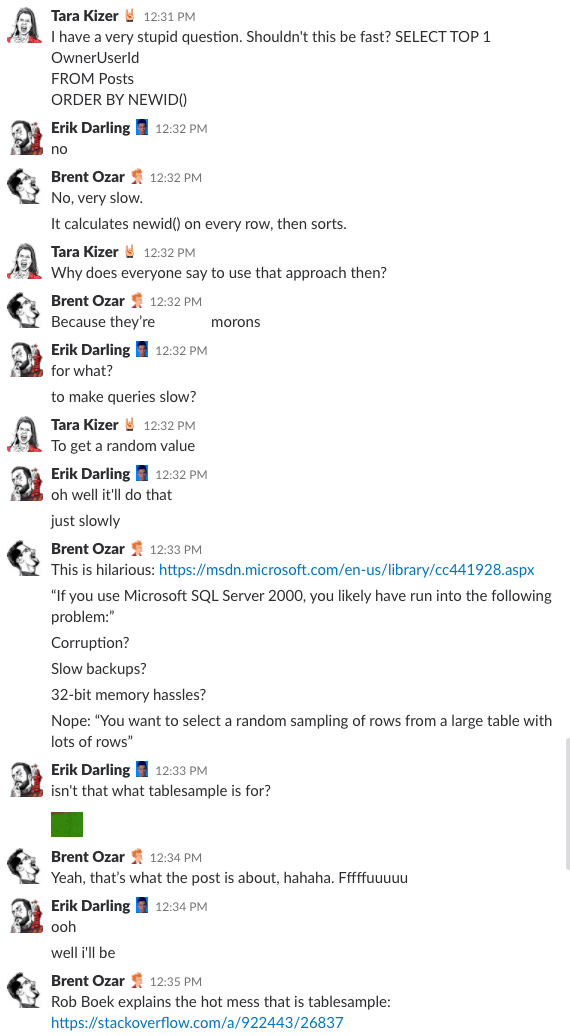
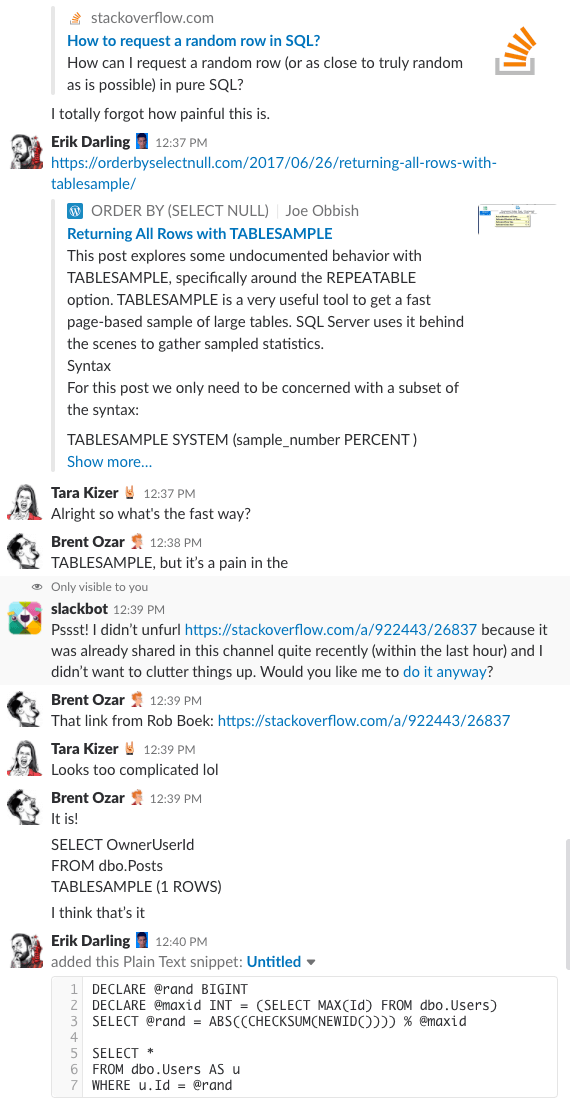
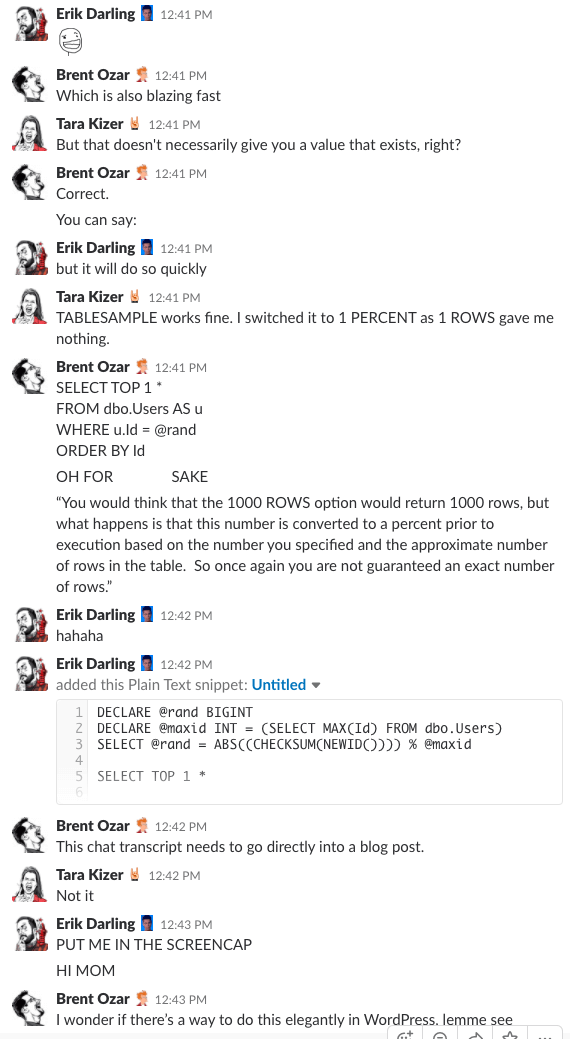
Allarme spoiler: non c’era. Ho solo fatto degli screenshot.
Bonus Track #2: Mitch Wheat Digs Deeper
Vuoi un’analisi approfondita della casualità di diverse tecniche? Mitch Wheat scava molto in profondità, completo di grafici!