L’immagine sopra potrebbe avervi dato un’idea sufficiente di cosa tratta questo post.
Questo post copre alcuni degli importanti algoritmi di corrispondenza delle stringhe fuzzy (non esattamente uguali, ma con le stesse stringhe, diciamo RajKumar & Raj Kumar) che includono:
Hamming Distance
Levenstein Distance
Damerau Levenstein Distance
N-Gram based string matching
BK Tree
Bitap algorithm
Ma dovremmo prima sapere perché la corrispondenza fuzzy è importante considerando uno scenario reale. Ogni volta che un utente è autorizzato a inserire dei dati, le cose possono diventare davvero incasinate come nel caso seguente!
Lascia che,
- Il tuo nome è ‘Saurav Kumar Agarwal’.
- Ti è stata data una tessera della biblioteca (con un ID unico, naturalmente) che è valida per ogni membro della tua famiglia.
- Tu vai in una biblioteca per rilasciare alcuni libri ogni settimana. Ma per questo, devi prima fare una registrazione in un registro all’ingresso della biblioteca dove inserisci il tuo ID & nome.
Ora, le autorità della biblioteca decidono di analizzare i dati in questo registro della biblioteca per avere un’idea dei lettori unici che visitano ogni mese. Ora, questo può essere fatto per molte ragioni (come se andare per l’espansione del terreno o no, se il numero di libri dovrebbe essere aumentato? ecc).
Hanno pianificato di fare questo contando (nomi unici, ID della biblioteca) le coppie registrate per un mese. Quindi se abbiamo
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Questo dovrebbe darci 4 lettori unici.
Finora tutto bene
Hanno stimato questo numero in circa 10k-10.5k ma i numeri sono aumentati fino a ~50k dopo l’analisi della corrispondenza esatta delle stringhe dei nomi.
wooohhh!!!
Perfetta stima devo dire!!
Oppure hanno perso un trucco qui?
Dopo un’analisi più profonda, è venuto fuori un problema importante. Ricorda il tuo nome, ‘Saurav Agarwal’. Hanno trovato alcune voci che portano a 5 diversi utenti attraverso l’ID della tua biblioteca di famiglia:
- Saurav K Aggrawal (nota la doppia ‘g’, ‘ra-ar’, Kumar diventa K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Ci sono alcune ambiguità perché le autorità della biblioteca non sanno
- Quante persone della tua famiglia visitano la biblioteca? se questi 5 nomi rappresentano un unico lettore, 2 o 3 lettori diversi. Chiamiamolo un problema non supervisionato dove abbiamo una stringa che rappresenta nomi non standardizzati ma i loro nomi standardizzati non sono noti (es. Saurav Agarwal: Saurav Kumar Agarwal non è noto)
- Dovrebbero tutti fondersi in ‘Saurav Kumar Agarwal’? non può dire come SK Agarwal può essere Shivam Kumar Agarwal (diciamo il nome di tuo padre). Inoltre, l’unico Agarwal può essere chiunque della famiglia.
Gli ultimi 2 casi (SK Agarwal & Agarwal) richiederebbero alcune informazioni extra (come il sesso, la data di nascita, i libri emessi) che saranno alimentati a qualche algoritmo ML per determinare il nome effettivo del lettore & dovrebbe essere lasciato per ora. Ma una cosa di cui sono abbastanza sicuro è che i primi 3 nomi rappresentano la stessa persona & Non dovrei avere bisogno di informazioni aggiuntive per unirli a un unico lettore, cioè ‘Saurav Kumar Agarwal’.
Come può essere fatto?
Ecco che arriva il fuzz string matching che significa una corrispondenza quasi esatta tra stringhe che sono leggermente diverse l’una dall’altra (principalmente a causa di ortografie errate) come ‘Agarwal’ & ‘Aggarwal’ & ‘Aggrawal’. Se otteniamo una stringa con un tasso di errore accettabile (diciamo una lettera sbagliata), la considereremo come una corrispondenza. Quindi esploriamo →
La distanza di Hamming è la distanza più ovvia calcolata tra due stringhe di uguale lunghezza che dà un conteggio dei caratteri che non corrispondono a un dato indice. Per esempio: ‘Bat’ & ‘Bet’ ha distanza di Hamming 1 in quanto all’indice 1, ‘a’ non è uguale a ‘e’
Distanza di Levenstein/ Distanza di modifica
Perché presumo che siate a vostro agio con la distanza di Levenstein & Ricorsione. In caso contrario, leggete questo. La spiegazione che segue è più una versione riassuntiva della distanza di Levenstein.
Lasciate ‘x’= lunghezza(Str1) & ‘y’=lunghezza(Str2) per tutto questo post.
La distanza di Levenstein calcola il numero minimo di modifiche necessarie per convertire ‘Str1’ in ‘Str2’ eseguendo caratteri di aggiunta, rimozione o sostituzione. Quindi ‘Cat’ & ‘Bat’ ha distanza di modifica ‘1’ (Sostituisci ‘C’ con ‘B’) mentre per ‘Ceat’ & ‘Bat’, sarebbe 2 (Sostituisci ‘C’ con ‘B’; Cancella ‘e’).
Parlando dell’algoritmo, ha principalmente 5 passi
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Quello che stiamo facendo è iniziare a leggere le stringhe dal 1° carattere
- Se il carattere all’indice ‘x’ di str1 corrisponde al carattere all’indice ‘y’ di str2, nessuna modifica richiesta & calcola la distanza di modifica chiamando
LevensteinDistance(str1,str2)
- Se non corrispondono, sappiamo che è necessaria una modifica. Quindi aggiungiamo +1 alla edit_distance corrente & calcola ricorsivamente la edit_distance per 3 condizioni & prende la minima delle tre:
Levenstein(str1,str2) →inserimento in str2.
Levenstein(str1,str2) →eliminazione in str2
Levenstein(str1,str2)→sostituzione in str2
- Se una delle stringhe finisce i caratteri durante la ricorsione, la lunghezza dei caratteri rimanenti nell’altra stringa sono aggiunti alla distanza di modifica (le prime due dichiarazioni if)
Demerau-Levenstein Distance
Considera ‘abcd’ & ‘acbd’. Se andiamo per distanza Levenstein, questo sarebbe (sostituire ‘b’-‘c’ & ‘c’-‘b’ alle posizioni di indice 2 & 3 in str2) Ma se guardate da vicino, entrambi i caratteri sono stati scambiati come in str1 & se introduciamo una nuova operazione ‘Swap’ accanto a ‘aggiunta’, ‘cancellazione’ & ‘sostituzione’, questo problema può essere risolto. Questa introduzione può aiutarci a risolvere problemi come ‘Agarwal’ & ‘Agrawal’.
Questa operazione viene aggiunta dal seguente pseudocodice
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Eseguiamo l’operazione di cui sopra per ‘abcd’ & ‘acbd’ dove assumiamo
initial_x=1 & initial_y=1 (Inizio indicizzazione da 1 & non da 0 per entrambe le stringhe).
corrente x=3 & y=3 quindi str1 & str2 a ‘c’ (abcd) & ‘b’ (acbd) rispettivamente. Quindi ‘qwerty’ significherà ‘qwer’.
- last_matching_index_y sarà l’ultimo_indice in str2 che corrisponde a str1 cioè 2 come ‘c’ in ‘acbd’ (indice 2) corrisponde a ‘c’ in ‘abcd’.
- last_matching_index_x sarà l’ultimo_indice in str1 che corrisponde a str2 i.e 2 come ‘b’ in ‘abcd’ (indice 2)corrisponde a ‘b’ in ‘acbd’.
- Quindi, seguendo lo pseudocodice sopra, DemarauLevenstein(‘abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‘a’,’a’)=1+0+0+0=1. Questo sarebbe stato 2 se avessimo seguito la distanza di Levenstein
N-Gram
N-gram non è altro che un insieme di valori generati da una stringa accoppiando ‘n’ caratteri/parole in sequenza. Per esempio: n-gram con n=2 per ‘abcd’ sarà ‘ab’,’bc’,’cd’.
Ora, questi n-grammi possono essere generati per stringhe la cui somiglianza deve essere misurata & diverse metriche possono essere utilizzate per misurare la somiglianza.
Lasciamo che ‘abcd’ & ‘acbd’ siano 2 stringhe da abbinare.
n-grammi con n=2 per
‘abcd’=ab,bc,cd
‘acbd’=ac,cb,bd
Component match (qgrammi)
Conto degli n-grammi abbinati esattamente per le due stringhe. Qui, sarebbe 0
Similitudine del coseno
Calcolo del prodotto di punti dopo aver convertito gli n-grammi generati per le stringhe in vettori
Convergenza di componenti (nessun ordine considerato)
Convergenza di n-grammi ignorando l’ordine degli elementi all’interno, cioè bc=cb.
Esistono molte altre metriche come la distanza Jaccard, l’indice Tversky, ecc. che non sono state discusse qui.
BK Tree
BK tree è tra gli algoritmi più veloci per trovare stringhe simili (da un pool di stringhe) per una data stringa. L’albero BK usa una
- distanza di Levenstein
- disuguaglianza del triangolo (che coprirà entro la fine di questa sezione)
per capire le stringhe simili (& non solo una stringa migliore).
Un albero BK è creato usando un pool di parole da un dizionario disponibile. Diciamo che abbiamo un dizionario D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart}
Un albero BK viene creato da
- Selezionare un nodo radice (può essere qualsiasi parola). Sia ‘Books’
- Passa attraverso ogni parola W nel dizionario D, calcola la sua distanza Levenstein con il nodo radice, e rendi la parola W figlia della radice se non esiste un figlio con la stessa distanza Levenstein per il genitore. Inserendo Books & Cake.
Levenstein(Books,Book)=1 & Levenstein(Books,Cake)=4. Poiché nessun figlio con la stessa distanza trovato per ‘Book’, li rende nuovi figli per la radice.
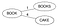
- Se esiste un figlio con la stessa distanza Levenstein per il padre P, ora considera quel figlio come un genitore P1 per quella parola W, calcola Levenstein(genitore, parola) e se non esiste un figlio con la stessa distanza per il genitore P1, fai la parola W un nuovo figlio per P1 altrimenti continua a scendere lungo l’albero.
Considera l’inserimento di Boo. Levenstein(Libro, Boo)=1 ma esiste già un figlio con lo stesso nome, cioè Libri. Quindi, ora calcola Levenstein(Libri, Boo)=2. Poiché non esiste un figlio con la stessa distanza per Libri, rendiamo Boo figlio di Libri.

Similmente, inserire tutte le parole del dizionario in BK Tree

Una volta preparato BK Tree, per cercare parole simili per una data parola (Query word) abbiamo bisogno di impostare una soglia di tolleranza, diciamo ‘t’.
- Questa è la massima edit_distance che considereremo per la similarità tra qualsiasi nodo & query_word. Tutto ciò che supera questo valore viene rifiutato.
- Inoltre, considereremo solo i figli di un nodo padre per il confronto con Query dove il Levenstein(Child, Parent) è entro
perché? ne parleremo tra poco
- Se questa condizione è vera per un figlio, allora calcoleremo solo Levenstein(Bambino, Query) che sarà considerato simile a Query se
Levenshtein(Bambino, Query)≤t.
- Quindi, non calcoleremo la distanza Levenstein per tutti i nodi/parole nel dizionario con la parola query &quindi risparmieremo molto tempo quando il pool di parole è enorme
Quindi, perché un figlio sia simile alla domanda se
- Levenstein(Genitore, Domanda)-t ≤ Levenstein(Bambino, Genitore) ≤ Levenstein(Genitore, Domanda)+t
- Levenstein(Bambino, Domanda)≤t
Facciamo un esempio veloce. Lasciamo che ‘t’=1
Lasciamo che la parola di cui abbiamo bisogno per trovare parole simili sia ‘Cura’ (parola di interrogazione)
- Levenstein(Libro,Cura)=4. Poiché 4>1, ‘Libro’ è rifiutato. Ora considereremo solo i figli di ‘Book’ che hanno una LevisteinDistance(Child,’Book’) tra 3(4-1) & 5(4+1). Quindi, rifiuteremmo ‘Libri’ & tutti i suoi figli perché 1 non si trova nei limiti fissati
- Come Levenstein(Torta, Libro)=4 che si trova tra 3 & 5, controlleremo Levenstein(Torta, Cura)=1 che è ≤1 quindi una parola simile.
- Regolando i limiti, per i figli di Cake, diventano 0(1-1) & 2(1+1)
- Come entrambi Capo & Cart ha Levenstein(Bambino, Genitore)=1 & 2 rispettivamente, entrambi sono idonei ad essere testati con ‘Cura’.
- Come Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, solo Cape è considerata una parola simile a ‘Care’.
Quindi, abbiamo trovato 2 parole simili a ‘Care’ che sono: Cake & Cape
Ma su quale base stiamo decidendo i limiti
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
per qualsiasi nodo figlio?
Questo segue dalla disuguaglianza del triangolo che afferma
Distanza (A,B) + Distanza(B,C)≥Distanza(A,C) dove A,B,C sono lati di un triangolo.
Come questa idea ci aiuta a raggiungere questi limiti, vediamo:
Lasciamo che Query,=Q Parent=P & Child=C formi un triangolo con distanza Levenstein come lunghezza del bordo. Sia ‘t’ la soglia di tolleranza. Allora, per la disuguaglianza di cui sopra
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Anche per la disuguaglianza del triangolo,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Algoritmo Bitap
È anche un algoritmo molto veloce che può essere usato per la corrispondenza di stringhe fuzzy in modo abbastanza efficiente. Questo perché utilizza le operazioni bitwise & che sono piuttosto veloci, l’algoritmo è noto per la sua velocità. Senza perdere un po’ di tempo, cominciamo:
Lascia che S0=’ababc’ sia il modello da abbinare alla stringa S1=’abdabababc’.
Prima di tutto,
- Cerca tutti i caratteri unici in S1 & S0 che sono a,b,c,d
- Forma modelli bit per ogni carattere. Come?

- Invertire il modello S0 da cercare
- Per il modello di bit per il carattere x, mettere 0 dove si verifica nel modello altrimenti 1. In T, ‘a’ si verifica al 3° & 5° posto, abbiamo messo 0 in quelle posizioni & resto 1.
Similmente, formare tutti gli altri modelli di bit per diversi caratteri nel dizionario.
S0=ababc S1=abdabababc
- Prendere uno stato iniziale di un modello di bit di lunghezza(S0) con tutti 1. Nel nostro caso, sarebbe 11111 (Stato S).
- Quando iniziamo la ricerca in S1 e passiamo attraverso qualsiasi carattere,
spostare uno 0 al bit più basso, cioè il 5° bit da destra in S &
Operazione OR su S con T.
Quindi, come incontreremo la prima ‘a’ in S1, noi
- Sposteremo uno 0 in S al bit più basso per formare 11111 →11110
- 11010 | 11110=11110
Ora, come ci spostiamo al 2° carattere ‘b’
- Sposteremo 0 in S i.e per formare 11110 →11100
- S |T=11100 | 10101=11101
Quando si incontra la ‘d’
- Sposta 0 a S per formare 11101 →11010
- S |T=11010 |11111=11111
Osserva che siccome ‘d’ non è in S0, lo stato S viene resettato. Una volta che si attraversa l’intero S1, si avranno i seguenti stati ad ogni carattere

Come faccio a sapere se ho trovato qualche fuzz/full match?
- Se uno 0 raggiunge il bit più in alto nel modello di bit dello Stato S (come nell’ultimo carattere ‘c’), hai una corrispondenza completa
- Per la corrispondenza fuzz, osserva 0 in diverse posizioni dello Stato S. Se 0 è al 4° posto, abbiamo trovato 4/5 caratteri nella stessa sequenza di S0. Similmente per 0 in altri posti.
Una cosa che potreste aver osservato è che tutti questi algoritmi lavorano sulla somiglianza ortografica delle stringhe. Ci possono essere altri criteri per la corrispondenza fuzzy? Sì,
Fonetica
Copriremo gli algoritmi di fuzz match basati sulla fonetica (basati sul suono, come Saurav & Sourav, dovrebbe avere una corrispondenza esatta nella fonetica) prossimamente!
- Riduzione delle dimensioni (3 parti)
- Algoritmi NLP (5 parti)
- Fondamenti di apprendimento per rinforzo (5 parti)
- Partendo da Time-Series (7 parti)
- Rilevamento di oggetti usando YOLO (3 parti)
- Tensorflow per principianti (concetti + esempi) (4 parti)
- Preelaborazione di serie temporali (con codici)
- Data Analytics per principianti
- Statistica per principianti (4 parti)