Rivisto: December 11, 2020
I soggetti dicono la verità?
L’affidabilità dei dati auto-riferiti è un tallone d’Achille della ricerca sui sondaggi. Per esempio, i sondaggi di opinione indicavano che più del 40% degli americani frequentano la chiesa ogni settimana. Tuttavia, esaminando i registri delle presenze in chiesa, Hadaway e Marlar (2005) hanno concluso che la frequenza effettiva era meno del 22%. Nel suo lavoro seminale “Everybody lies”, Seth Stephens-Davidowitz (2017) ha trovato ampie prove per dimostrare che la maggior parte delle persone non fa quello che dice e non dice quello che fa. Per esempio, in risposta ai sondaggi la maggior parte degli elettori ha dichiarato che l’etnia del candidato non è importante. Tuttavia, controllando i termini di ricerca in Google Sephens-Davidowitz ha trovato il contrario. In particolare, quando gli utenti di Google hanno inserito la parola “Obama”, hanno sempre associato il suo nome con alcune parole legate alla razza.
Per la ricerca sull’istruzione basata sul web, i dati di utilizzo del web possono essere ottenuti analizzando il registro di accesso dell’utente, impostando i cookie o caricando la cache. Tuttavia, queste opzioni possono avere un’applicabilità limitata. Per esempio, il registro di accesso dell’utente non può tracciare gli utenti che seguono i link ad altri siti web. Inoltre, gli approcci con i cookie o la cache possono sollevare problemi di privacy. In queste situazioni, vengono utilizzati dati auto-dichiarati raccolti tramite sondaggi. Questo dà origine alla domanda: Quanto sono accurati i dati auto-riferiti? Cook e Campbell (1979) hanno sottolineato che i soggetti (a) tendono a riportare ciò che credono che il ricercatore si aspetti di vedere, o (b) riportano ciò che si riflette positivamente sulle loro capacità, conoscenze, credenze o opinioni. Un’altra preoccupazione su tali centri dati riguarda la capacità dei soggetti di ricordare accuratamente i comportamenti passati. Gli psicologi hanno avvertito che la memoria umana è fallibile (Loftus, 2016; Schacter, 1999). A volte le persone “ricordano” eventi che non sono mai accaduti. Così l’affidabilità dei dati auto-riferiti è tenue.Anche se i pacchetti software statistici sono in grado di calcolare numeri fino a 16-32 decimali, questa precisione non ha senso se i dati non possono essere accurati nemmeno a livello di numero intero. Non pochi studiosi hanno messo in guardia i ricercatori su come l’errore di misurazione possa paralizzare l’analisi statistica (Blalock, 1974) e hanno suggerito che una buona pratica di ricerca richieda l’esame della qualità dei dati raccolti (Fetter, Stowe, & Owings, 1984).
Bias e Varianza
Gli errori di misurazione includono due componenti, cioè bias ed errore variabile.Bias è un errore sistematico che tende a spingere i punteggi riportati verso un estremo. Per esempio, diverse versioni di test IQ sono trovate essere bias contro i non-bianchi. Significa che i neri e gli ispanici tendono a ricevere punteggi più bassi indipendentemente dalla loro effettiva intelligenza. Un errore variabile, noto anche come varianza, tende ad essere casuale. In altre parole, i punteggi riportati potrebbero essere sia sopra che sotto i punteggi reali (Salvucci, Walter, Conley, Fink, & Saba, 1997).
I risultati di questi due tipi di errori di misurazione hanno implicazioni diverse. Per esempio, in uno studio che ha confrontato i dati auto-riferiti di altezza e peso con i dati misurati direttamente (Hart & Tomazic, 1999), è stato trovato che i soggetti tendono a riportare in eccesso la loro altezza ma in difetto il loro peso. Ovviamente, questo tipo di errore è una distorsione piuttosto che una varianza. Una possibile spiegazione di questo bias è che la maggior parte delle persone vuole presentare un’immagine fisica migliore agli altri. Tuttavia, se l’errore di misurazione è casuale, la spiegazione può essere più complicata.
Si può sostenere che gli errori variabili, che sono di natura casuale, si annullano a vicenda e quindi non possono essere una minaccia per lo studio. Per esempio, il primo utente potrebbe sovrastimare le sue attività su Internet del 10%, ma il secondo utente potrebbe sottostimare le sue del 10%. In questo caso, la media potrebbe ancora essere corretta. Tuttavia, la sovrastima e la sottostima aumentano la variabilità della distribuzione. In molti test parametrici, la variabilità all’interno del gruppo è usata come termine di errore. Una variabilità gonfiata influenzerebbe sicuramente la significatività del test. Alcuni testi possono rafforzare il concetto di cui sopra. Per esempio, Deese (1972) ha detto:
La teoria statistica ci dice che l’affidabilità delle osservazioni è proporzionale alla radice quadrata del loro numero. Più osservazioni ci sono, più influenza casuale ci sarà. E la teoria statistica sostiene che più errori casuali ci sono, più è probabile che si annullino a vicenda e producano una distribuzione normale (p.55).
In primo luogo, è vero che all’aumentare della dimensione del campione la varianza della distribuzione diminuisce, ma ciò non garantisce che la forma della distribuzione si avvicini alla normalità. In secondo luogo, l’affidabilità (la qualità dei dati) dovrebbe essere legata alla misurazione piuttosto che alla determinazione delle dimensioni del campione. Una grande dimensione del campione con molti errori di misurazione, anche casuali, gonfierebbe il termine di errore per i test parametrici.
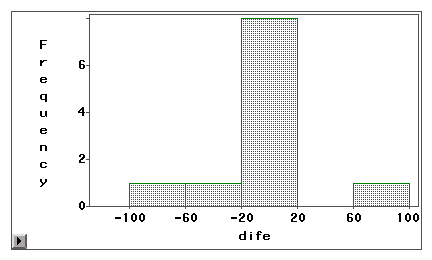
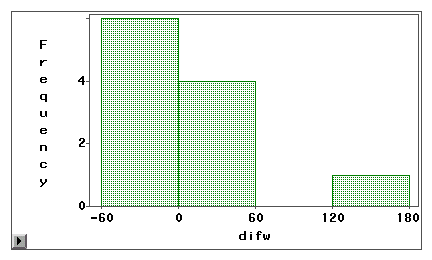
Un diagramma stem-and-leaf o un istogramma può essere usato per esaminare visivamente se un errore di misurazione è dovuto a un bias sistematico o a una varianza casuale. Nell’esempio seguente, due tipi di accesso a Internet (navigazione web e posta elettronica) sono misurati sia da un’indagine autodichiarata che da un registro. I punteggi di differenza (misura 1 – misura 2) sono tracciati nei seguenti istogrammi.
Il primo grafico rivela che la maggior parte dei punteggi di differenza sono centrati intorno allo zero. L’under-reporting e l’over-reporting appaiono vicino ad entrambe le estremità suggeriscono che l’errore di misurazione è un errore casuale piuttosto che un bias sistematico.
Il secondo grafico indica chiaramente che c’è un alto grado di errori di misurazione perché pochissimi punteggi di differenza sono centrati intorno allo zero. Inoltre, la distribuzione è negativamente skewed e l’errore è bias invece che varianza.
Quanto è affidabile la nostra memoria?
Schacter (1999) avverte che la memoria umana è fallibile. Ci sono sette difetti della nostra memoria:
- Transizione: Accessibilità decrescente delle informazioni nel tempo.
- Assenza di pensiero: Elaborazione disattenta o superficiale che contribuisce alla debolezza dei ricordi.
- Blocco: L’inaccessibilità temporanea di informazioni immagazzinate nella memoria.
- Misattribuzione Attribuire un ricordo o un’idea alla fonte sbagliata.
- Suggestionabilità: Ricordi che sono impiantati come risultato di domande o aspettative che conducono.
- Bias: Distorsioni retrospettive e influenze inconsce che sono legate alla conoscenza e alle credenze attuali.
- Persistenza: Ricordi patologici – informazioni o eventi che non possiamo dimenticare, anche se vorremmo farlo.
 |
“Non ho nessun ricordo di questi. Non ricordo di aver firmato il documento perWhitewater. Non ricordo perché il documento è scomparso ma è riapparso dopo. Non ricordo nulla.” “Ricordo di essere atterrato (in Bosnia) sotto il fuoco dei cecchini. Doveva esserci una sorta di cerimonia di saluto all’aeroporto, ma invece abbiamo corso a testa bassa per entrare nei veicoli per raggiungere la nostra base.” Durante l’indagine sull’invio di informazioni classificate tramite un server di posta elettronica personale, la Clinton ha detto all’FBI che non poteva “ricordare” o “ricordare” nulla per 39 volte. Attenzione: Un nuovo virus informatico chiamato “Clinton” è stato scoperto. Se il computer è infettato, apparirà spesso questo messaggio ‘out of memory’, anche se ha una RAM adeguata. |
| D: “Se Vernon Jordon ci ha detto che lei ha una memoria straordinaria, una delle più grandi memorie che abbia mai visto in un politico, sarebbe qualcosa che vorrebbe contestare?”
A: “Ho una buona memoria…Ma non ricordo se ero solo con Monica Lewinsky o no. Come potrei tenere traccia di così tante donne nella mia vita?” Q: Perché Clinton raccomandò la Lewinsky per un lavoro alla Revlon? A: Sapeva che sarebbe stata brava a inventare le cose. |
 |
È importante notare che a volte l’affidabilità della nostra memoria è legata alla desiderabilità del risultato. Per esempio, quando un ricercatore medico cerca di raccogliere dati rilevanti da madri i cui bambini sono sani e madri i cui bambini sono malformati, i dati di queste ultime sono solitamente più accurati di quelli delle prime. Questo perché le madri di bambini malformati hanno esaminato attentamente ogni malattia che si è verificata durante la gravidanza, ogni farmaco preso, ogni dettaglio direttamente o remotamente collegato alla tragedia nel tentativo di trovare una spiegazione. Al contrario, le madri di bambini sani non prestano molta attenzione alle informazioni precedenti (Aschengrau & SeageIII, 2008). Gonfiare la GPA è un altro esempio di come la desiderabilità influenza l’accuratezza della memoria e l’integrità dei dati. In alcune situazioni c’è una differenza di genere nell’inflazione della GPA. Uno studio condotto da Caskie etal. (2014) ha trovato che all’interno del gruppo di studenti universitari con GPA più basso, le femmine avevano più probabilità di riportare un GPA più alto di quello effettivo rispetto ai maschi.
Per contrastare il problema degli errori di memoria, alcuni ricercatori hanno suggerito di raccogliere dati relativi al pensiero o alla sensazione momentanea del partecipante, piuttosto che chiedergli di ricordare eventi remoti (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). I seguenti esempi sono voci del sondaggio del 2018 Programme forInternational Student Assessment: “Sei stato trattato con rispetto tutto il giorno ieri?” “Hai sorriso o riso molto ieri?” “Hai imparato o fatto qualcosa di interessante ieri?” (Organizzazione per la cooperazione e lo sviluppo economico, 2017). Tuttavia, la risposta dipende da ciò che è successo al partecipante in quel particolare momento, che potrebbe non essere tipico. In particolare, anche se l’intervistato non ha sorriso o riso molto ieri, ciò non implica necessariamente che l’intervistato sia sempre infelice.
Cosa dobbiamo fare?
Alcuni ricercatori rifiutano l’uso dei dati auto-riportati a causa della loro presunta scarsa qualità. Per esempio, quando un gruppo di ricercatori ha studiato se un’alta religiosità portasse a una minore adesione alle direttive di rifugio negli Stati Uniti durante la pandemia di COVID19, hanno usato il numero di congregazioni per 10.000 residenti come misura proxy della religiosità della regione, invece della religiosità auto-riferita, che tende a riflettere la desiderabilità sociale (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Tuttavia, Chan (2009) ha sostenuto che la cosiddetta scarsa qualità dei dati auto-riferiti non è altro che una leggenda metropolitana. Guidati dalla desiderabilità sociale, gli intervistati potrebbero fornire ai ricercatori dati imprecisi in alcune occasioni, ma non succede sempre. Per esempio, è improbabile che gli intervistati mentano sui loro dati demografici, come il sesso e l’etnia. In secondo luogo, se è vero che gli intervistati tendono a falsificare le loro risposte negli studi sperimentali, questo problema è meno grave nelle misure utilizzate negli studi sul campo e negli ambienti naturalistici. Inoltre, ci sono numerose misure auto-riferite ben consolidate di diversi costrutti psicologici, che hanno ottenuto prove di validità del costrutto attraverso la validazione sia convergente che discriminante. Per esempio, i tratti di personalità Big-five, la personalità proattiva, la disposizione affettiva, l’autoefficacia, l’orientamento agli obiettivi, il supporto organizzativo percepito e molti altri.Nel campo dell’epidemiologia, Khoury, James e Erickson (1994) hanno affermato che l’effetto del recall bias è sopravvalutato. Ma la loro conclusione potrebbe non essere ben applicata ad altri campi, come l’educazione e la psicologia. Nonostante la minaccia di imprecisione dei dati, è impossibile per il ricercatore seguire ogni soggetto con una videocamera e registrare tutto quello che fa. Tuttavia, il ricercatore può utilizzare un sottoinsieme di soggetti per ottenere dati osservati come l’accesso al log dell’utente o il logo cartaceo giornaliero dell’accesso al web. I risultati verrebbero poi confrontati con il risultato di tutti i soggetti¹ dati auto-riferiti per una stima dell’errore di misura.Per esempio,
- Quando il registro di accesso dell’utente è disponibile al ricercatore, egli può chiedere ai soggetti di riferire la frequenza del loro accesso al server web.I soggetti non dovrebbero essere informati che le loro attività su Internet sono state registrate dal webmaster in quanto ciò potrebbe influenzare il comportamento dei partecipanti.
- Il ricercatore può chiedere a un sottoinsieme di utenti di tenere un registro delle loro attività su Internet per un mese. In seguito, agli stessi utenti viene chiesto di compilare un sondaggio sul loro uso del web.
Qualcuno potrebbe obiettare che l’approccio del registro è troppo esigente. Infatti, in molti studi di ricerca scientifica, ai soggetti viene chiesto molto di più di questo. Per esempio, quando gli scienziati hanno studiato come il sonno profondo durante i viaggi spaziali a lungo raggio avrebbe influenzato la salute umana, ai partecipanti è stato chiesto di stare a letto per un mese. In uno studio su come un ambiente chiuso influenza la psicologia umana durante il viaggio nello spazio, i soggetti sono stati chiusi in una stanza individualmente per un mese. Ci vuole un costo elevato per cercare verità scientifiche.
Dopo aver raccolto diverse fonti di dati, la discrepanza tra il registro e i dati auto-riferiti può essere analizzata per stimare l’affidabilità dei dati. A prima vista, questo approccio sembra un test-retest reliability, ma non lo è. Primo, nell’affidabilità test-retest lo strumento usato in due o più situazioni dovrebbe essere lo stesso. In secondo luogo, quando l’affidabilità test-retest è bassa, la fonte degli errori è all’interno dello strumento. Tuttavia, quando la fonte degli errori è esterna allo strumento come gli errori umani, l’affidabilità inter-rater è più appropriata.
La procedura sopra suggerita può essere concettualizzata come una misurazione dell’affidabilità inter-data, che assomiglia a quella dell’affidabilità inter-rater e delle misure ripetute. Ci sono quattro modi per stimare l’affidabilità inter-rater, cioè il coefficiente Kappa, l’indice di incoerenza, l’ANOVA a misure ripetute e l’analisi di regressione. La sezione seguente descrive come queste misure di affidabilità tra i revisori possono essere usate come misure di affidabilità tra i dati.
Coefficiente Kappa
Nella ricerca psicologica ed educativa, non è insolito impiegare due o più revisori nel processo di misurazione quando la valutazione coinvolge giudizi soggettivi (ad esempio la valutazione dei saggi). L’affidabilità inter-rater, che è misurata dal coefficiente Kappa, è usata per indicare l’affidabilità dei dati. Per esempio, le prestazioni dei partecipanti sono classificate da due o più classificatori come “maestro” o “non maestro” (1 o 0). Così, questa misura è di solito calcolata in procedure di analisi dei dati categorici come PROC FREQ in SAS, “misura dell’accordo” in SPSS, o il calcolatore Kappa online (Lowry, 2016). L’immagine qui sotto è una schermata del calcolatore online Vassarstats.
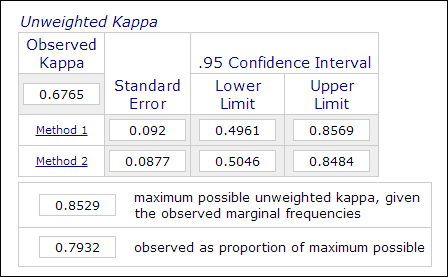
È importante notare che anche se il 60% di due serie di dati concordano tra loro, non significa che le misure siano affidabili. Il coefficiente Kappa tiene conto di questo e richiede un più alto grado di corrispondenza per raggiungere la coerenza.
Nel contesto dell’istruzione basata sul web, ogni categoria di utilizzo del sito web auto-riferito può essere ricodificata come una variabile binaria. Per esempio, quando la prima domanda è “quanto spesso usi telnet”, le possibili risposte categoriche sono “a: ogni giorno”, “b: da tre a cinque volte al mese”, “c: tre-cinque volte al mese”, “d: raramente” ed “e: mai”. In questo caso, le cinque categorie possono essere ricodificate in cinque variabili: Q1A, Q1B, Q1C, Q1D e Q1E. Con questa struttura di dati, le risposte possono essere codificate come “1” o “0” e quindi è possibile misurare l’accordo di classificazione. L’accordo può essere calcolato utilizzando il coefficiente Kappa e quindi l’affidabilità dei dati può essere stimata.
Soggetti Dati del registro Self-rapporto dati Soggetto 1 1 1 Soggetto 2 0 0 Soggetto 3 1 0 Soggetto 4 0 1 Index of Inconsistency
Un altro modo di calcolare i dati categorici di cui sopra è Index ofInconsistency (IOI). Nell’esempio precedente, poiché ci sono due misure (log e dati auto-riferiti) e cinque opzioni nella risposta, si forma una tabella 4 X 4. Il primo passo per calcolare l’IOI è quello di dividere la tabella RXC in diverse sottotabelle 2X2. Per esempio, l’ultima opzione “mai” è trattata come una categoria e tutto il resto è collocato in un’altra categoria come “non mai”, come mostrato nella tabella seguente.
Self-dati riportati Log mai non mai Totale mai a b a+b Non mai c d c+d Totale a+c b+d n=Somma(a-d) La percentuale di IOI è calcolata dalla seguente formula:
IoI% = 100*(b+c)/ dove p = (a+c)/n
Dopo che l’Ieo è stato calcolato per ogni sottotabella 2X2, una media di tutti gli indici è usata come indicatore dell’inconsistenza della misura. Il criterio per giudicare se i dati sono coerenti è il seguente:
- Un IOI inferiore a 20 è bassa varianza
- Un IOI tra 20 e 50 è varianza moderata
- Un IOI superiore a 50 è alta varianza
L’affidabilità dei dati è espressa in questa equazione: r = 1 – IOI
Coefficiente di correlazione intraclasse
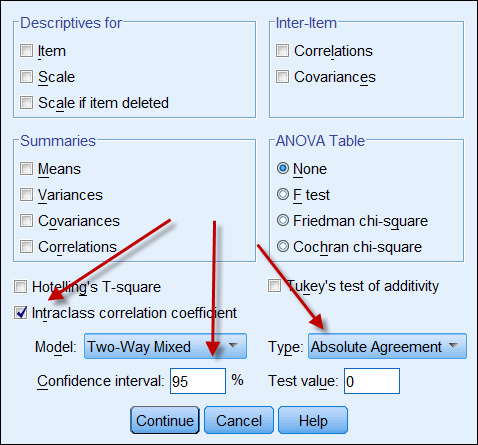
Se entrambe le fonti di dati forniscono dati continui, allora si può calcolare il coefficiente di correlazione intraclasse per indicare l’affidabilità dei dati. La seguente è una schermata delle opzioni ICC di SPSS. In Typethere ci sono due opzioni: “consistenza” e “accordo assoluto”. Se si sceglie “consistenza”, anche se una serie di numeri ha una consistenza alta (es. 9, 8, 9, 8, 7…) e l’altra ha una consistenza bassa (es. 4,3, 4, 3, 2…), la loro forte correlazione implica erroneamente che i dati sono allineati tra loro. Quindi, è consigliabile scegliere “accordo assoluto”.
Misure ripetute
La misura dell’affidabilità tra i dati può anche essere concettualizzata e proceduralizzata come una ANOVA a misure ripetute. In un’ANOVA a misure ripetute, le misure sono date agli stessi soggetti più volte, come pretest, midterm e posttest. In questo contesto, i soggetti sono anche misurati ripetutamente tramite il registro utente web, il registro e l’indagine auto-riferita. Il seguente è il codice SAS per un’ANOVA a misure ripetute:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
Nel programma di cui sopra, il numero di siti web visitati da nove volontari sono registrati nel registro di accesso dell’utente, il registro personale e l’indagine auto-riferita. Gli utenti sono trattati come un fattore intersoggetto mentre le tre misure sono considerate come fattore intermisura. Il seguente è un output condensato:
Fonte di variazione DF Mean Square Between-subject (user) 8 10442.50 Tra-misura (tempo) 2 488.93 Residuo 16 454.80 In base alle informazioni di cui sopra, il coefficiente di affidabilità può essere calcolato utilizzando questa formula (Fisher, 1946; Horst, 1949):
r = MSbetween-measure – MSresidual ————————————————————– MSbetween-measure + (dfbetween-people X MSresidual) Inseriamo il numero nella formula:
r = 488.93 – 454.80 ————————————— 488.93 + ( 8 X 454.80) L’affidabilità è circa .0008, che è estremamente bassa. Pertanto, possiamo andare a casa e dimenticare i dati. Fortunatamente, si tratta solo di una serie di dati ipotetici. Ma se si trattasse di una serie di dati reali? Bisogna essere abbastanza duri da rinunciare a dati scadenti piuttosto che pubblicare risultati totalmente inaffidabili.
Analisi di correlazione e regressione
L’analisi di correlazione, che utilizza il coefficiente di momento prodotto di Pearson, è molto semplice e particolarmente utile quando le scale di due misure non sono le stesse. Per esempio, il log del server web può tracciare il numero di accessi alle pagine mentre i dati auto-riferiti sono a scala Likert (ad esempio, quanto spesso naviga in Internet? 5=molto spesso, 4=spesso, 3=a volte, 2=di rado, 5=mai). In questo caso, i punteggi auto-riferiti possono essere utilizzati come un predittore per regredire rispetto all’accesso alla pagina.
Un approccio simile è l’analisi di regressione, in cui una serie di punteggi (ad esempio i dati del sondaggio) è trattata come il predittore mentre un’altra serie di punteggi (ad esempio il registro giornaliero dell’utente) è considerata la variabile dipendente. Se vengono impiegate più di due misure, si può applicare un modello di regressione multipla, cioè quella che produce un risultato più accurato (ad esempio il registro degli accessi degli utenti al web) viene considerata la variabile dipendente e tutte le altre misure (ad esempio il registro giornaliero degli utenti, i dati del sondaggio) vengono trattate come variabili indipendenti.
Riferimento
- Aschengrau, A., & Seage III, G. (2008). Elementi essenziali di epidemiologia nella salute pubblica. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) La misurazione nelle scienze sociali: Teorie e strategie. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Accuratezza dell’autodichiarazione del GPA del college: Differenze di genere-moderate dal livello di realizzazione e dall’autoefficacia accademica. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Allora perché chiedermelo? I dati del self report sono davvero così male? In Charles E. Lance e Robert J. Vandenberg (Eds.), Miti statistici e metodologici e leggende urbane: Doctrine, verity and fable in the organizational and social sciences (pp309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-sperimentazione: Problemi di progettazione e analisi. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validità e affidabilità del metodo del campionamento dell’esperienza. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). La psicologia come scienza e arte. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, August 10). Religione e reattività alle linee guida di COVID-19mitigazione. Psicologo americano. Pubblicazione online anticipata. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). La scuola superiore e oltre. Uno studio longitudinale nazionale per gli anni ’80, qualità delle risposte degli studenti delle scuole superiori alle voci del questionario. (NCES 84-216).Washington, D. C.: U.S. Department of Education. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). L’incrementalevalidità degli auto-rapporti di stato medio rispetto agli auto-rapporti globali dipersonalità. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistical methods for research workers (10th ed.). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Quanti americani assistono al culto ogni settimana? Un approccio alternativo alla misurazione? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 agosto). Confronto delle distribuzioni percentili per le misure antropometriche tra tre serie di dati. Documento presentato all’Annual Joint Statistical Meeting, Baltimora, MD.
- Horst, P. (1949). Un’espressione generalizzata per l’affidabilità delle misure. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). Sull’uso di controlli affetti per affrontare il recall bias negli studi caso-controllo sui difetti di nascita. Teratologia, 49, 273-281.
- Loftus, E. (2016, aprile). La finzione della memoria. Paper presentato alla Western Psychological Association Convention. Long Beach, CA.
- Lowry, R. (2016). Kappa come misura della concordanza nell’ordinamento categorico. Recuperato da http://vassarstats.net/kappa.html
- Organizzazione per la cooperazione e lo sviluppo economico. (2017). Questionario sul benessere per PISA 2018. Parigi: Autore. Retrieved from https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). I sette peccati della memoria: Approfondimenti dalla psicologia e dalle neuroscienze cognitive. Psicologia americana, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Studi sugli errori di misura al Centro Nazionale per le Statistiche dell’Educazione. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Tutti mentono: Big data, nuovi dati, e ciò che Internet può dirci su chi siamo veramente. New York, NY: Dey Street Books.
 Vai al menu principale
Vai al menu principale Altri corsiMotore di ricerca
|

Contattami
|