Introduction Ce tutoriel montre comment trouver et éventuellement supprimer les pages similaires ou en double dans un même document PDF à l’aide du plug-in AutoSplit™ pour le logiciel Adobe® Acrobat®. Cette opération détecte les pages similaires et les présente à l’utilisateur pour qu’il les examine. L’utilisateur peut examiner les résultats et sélectionner/désélectionner des pages individuelles dans la liste des doublons pour une éventuelle suppression ou extraction. Vous pouvez effectuer les opérations suivantes :
- Détecter les pages en double et les pages quasi-doubles
- Signaler les pages en double
- Extraire les pages en double dans un document PDF séparé
- Supprimer les pages en double du document
- Enregistrer le rapport de similarité des pages
Le plug-in fournit deux méthodes différentes pour détecter les pages en double ou quasi-doubles : Comparer le texte de la page uniquement Utilisez cette méthode pour comparer le texte de la page indépendamment de son aspect visuel. Elle calcule la similarité de la page en se basant uniquement sur le contenu du texte et ignore complètement l’apparence du texte, la mise en page, les images et les graphiques qui pourraient être présents sur la page. C’est la meilleure méthode pour détecter les doublons dans la plupart des types de documents. Comparer l’apparence visuelle des pages Cette méthode compare les pages « en tant qu’images » et détecte les pages qui ont exactement la même apparence. Cette méthode ne compare pas le texte invisible qui peut être présent sur la page. Il est déconseillé d’utiliser cette méthode sur des documents papier numérisés. Utilisation de documents papier numérisés Très souvent, cette opération est utilisée pour trouver les pages en double dans les documents papier numérisés. Les documents numérisés doivent être OCRés avant d’être utilisés pour tout traitement de texte. L’OCR est un processus qui permet de reconnaître le texte dans les documents numérisés et de les rendre consultables. Il est essentiel de comprendre que la reconnaissance de texte dans les documents numérisés est sujette à des erreurs et qu’elle est rarement précise à 100 %. Le nombre d’erreurs dépend de la résolution de numérisation et de la qualité du document original. Dans la plupart des cas, une page numérisée peut contenir entre 1 et 10 erreurs de reconnaissance où certaines lettres sont mal identifiées. Par exemple, selon la police utilisée, la lettre minuscule l peut ressembler exactement au chiffre 1 . La lettre majuscule O est souvent identifiée à tort comme le chiffre 0, ou la lettre majuscule S comme le chiffre 5, etc. Étant donné que de nombreux symboles alphanumériques partagent des caractéristiques physiques similaires, voire identiques, la différenciation représente souvent un défi. C’est pourquoi une comparaison basée sur la similarité s’avère utile pour détecter les petites différences entre les pages produites par le processus de reconnaissance de texte. Les documents numérisés de mauvaise qualité peuvent contenir un grand nombre d’erreurs, ce qui les rend inutilisables pour toute comparaison textuelle fiable. Consultez le tutoriel suivant pour savoir comment reconnaître par OCR des documents numérisés et déterminer s’ils conviennent au traitement textuel. . Conditions préalables Pour pouvoir utiliser ce tutoriel, vous devez disposer d’une copie d’Adobe® Acrobat® et du plug-in AutoSplit™ installés sur votre ordinateur. Vous pouvez télécharger des versions d’essai de l’Adobe® Acrobat® et du plug-in AutoSplit™. Sommaire
- Comparaison du texte des pages uniquement
- Comparaison de l’apparence visuelle uniquement
- Comparaison de plusieurs documents
Méthode 1 – Comparaison du texte des pages uniquement aperçu Cette méthode compare la similitude des pages uniquement sur la base de leur contenu. L’aspect visuel, la position et l’ordre du texte ne sont pas pertinents. Cette méthode ignore également les images et les graphiques présents sur les pages. La métrique de similarité en cosinus modifiée est utilisée pour calculer la similarité de deux pages sur la base de leur contenu textuel. Étape 1 – Ouvrir un fichier PDF Démarrez l’application Adobe® Acrobat® et ouvrez un fichier PDF à l’aide du menu « Fichier > Ouvrir… »..PNG) Étape 2 – Ouvrir la boîte de dialogue « Trouver les pages en double » Sélectionnez « Plug-Ins > Diviser les documents > Trouver et supprimer les pages en double… » pour ouvrir la boîte de dialogue « Trouver les pages en double ».
Étape 2 – Ouvrir la boîte de dialogue « Trouver les pages en double » Sélectionnez « Plug-Ins > Diviser les documents > Trouver et supprimer les pages en double… » pour ouvrir la boîte de dialogue « Trouver les pages en double »..PNG) Étape 3 – Spécifier les paramètres Cochez l’option « Comparer uniquement le texte des pages (ignorer l’aspect visuel des pages) ».
Étape 3 – Spécifier les paramètres Cochez l’option « Comparer uniquement le texte des pages (ignorer l’aspect visuel des pages) »..PNG) Utilisation des paramètres prédéfinis La méthode basée sur le texte fournit un certain nombre de jeux de paramètres prédéfinis qui conviennent à la comparaison de différents types de documents avec une quantité différente d’erreurs de reconnaissance. Chaque ensemble de paramètres prédéfinis fournit des conditions différentes pour les calculs de similarité :
Utilisation des paramètres prédéfinis La méthode basée sur le texte fournit un certain nombre de jeux de paramètres prédéfinis qui conviennent à la comparaison de différents types de documents avec une quantité différente d’erreurs de reconnaissance. Chaque ensemble de paramètres prédéfinis fournit des conditions différentes pour les calculs de similarité :
- Paramètres personnalisés – tous les paramètres sont spécifiés par l’utilisateur
- Document papier numérisé : Haute qualité
- Document papier numérisé : Qualité moyenne
- Document de télécopie : Basse qualité
- Document PDF non numérisé : correspondance exacte
- Document PDF non numérisé : correspondance floue
- Correspondance exacte (avec ordre du texte) – cette méthode n’utilise pas la similarité cosinus
.PNG) Les paramètres apparaissent sous le menu après avoir sélectionné un ensemble de paramètres prédéfinis.
Les paramètres apparaissent sous le menu après avoir sélectionné un ensemble de paramètres prédéfinis..PNG) Voici les paramètres utilisés par les ensembles prédéfinis :
Voici les paramètres utilisés par les ensembles prédéfinis :.PNG) Cliquez sur « Modifier… » pour personnaliser les paramètres de similarité des pages :
Cliquez sur « Modifier… » pour personnaliser les paramètres de similarité des pages :.PNG) La méthode de comparaison de texte utilise 3 paramètres pour limiter la différence entre deux pages « similaires ». En faisant varier ces paramètres, il est possible de détecter des pages qui ont un degré de similarité différent.
La méthode de comparaison de texte utilise 3 paramètres pour limiter la différence entre deux pages « similaires ». En faisant varier ces paramètres, il est possible de détecter des pages qui ont un degré de similarité différent.
- Similitude minimale autorisée du texte de la page (en pourcentage) – il s’agit de la valeur de la métrique de similarité cosinus exprimée en pourcentage. Spécifiez la similarité minimale autorisée du texte de la page entre 70 et 100 (en pourcentage).
- Différence maximale autorisée de la longueur de la page (en caractères).
- Différence maximale autorisée du texte de la page (en mots).
Utilisez ces paramètres pour expérimenter les paramètres de traitement lorsqu’il est nécessaire d’ajuster l’algorithme de traitement pour un document spécifique..PNG) Utiliser des pages échantillons En option, cliquez sur « Définir à partir de l’échantillon de page… » pour spécifier les paramètres de similarité de page basés sur les deux pages échantillons :
Utiliser des pages échantillons En option, cliquez sur « Définir à partir de l’échantillon de page… » pour spécifier les paramètres de similarité de page basés sur les deux pages échantillons :.PNG) Sélectionnez deux pages qui peuvent être considérées comme identiques. Le logiciel calculera automatiquement la similarité des pages et les statistiques apparaîtront dans le coin inférieur gauche du dialogue. Cliquez sur « OK » pour enregistrer les paramètres de similarité actuels.
Sélectionnez deux pages qui peuvent être considérées comme identiques. Le logiciel calculera automatiquement la similarité des pages et les statistiques apparaîtront dans le coin inférieur gauche du dialogue. Cliquez sur « OK » pour enregistrer les paramètres de similarité actuels..PNG) Spécifier les options de filtrage du texte Il existe plusieurs paramètres qui contrôlent le contenu de la page qui est analysé par l’algorithme de comparaison de texte. Utilisez ces options lorsque vous comparez des documents papier numérisés qui peuvent contenir diverses erreurs de reconnaissance de texte. Ces options permettent d’exclure certains types de caractères du traitement. Dans de nombreux cas, cela peut aider à calculer une métrique de similarité plus précise.
Spécifier les options de filtrage du texte Il existe plusieurs paramètres qui contrôlent le contenu de la page qui est analysé par l’algorithme de comparaison de texte. Utilisez ces options lorsque vous comparez des documents papier numérisés qui peuvent contenir diverses erreurs de reconnaissance de texte. Ces options permettent d’exclure certains types de caractères du traitement. Dans de nombreux cas, cela peut aider à calculer une métrique de similarité plus précise.
- Ignorer la casse du texte – cette option ignore la casse du texte lors de la comparaison du texte.
- Ignorer la ponctuation (,.!?-) – cette option exclut tous les caractères de ponctuation de la comparaison.
- Ignorer les caractères non alphanumériques – cette option ignore tous les caractères sauf les lettres et les chiffres.
Cliquez sur « OK » pour enregistrer les paramètres de similarité des pages..PNG) Cliquez sur « OK » pour commencer à rechercher les pages dupliquées dans le document PDF actuel :
Cliquez sur « OK » pour commencer à rechercher les pages dupliquées dans le document PDF actuel :.PNG) Étape 4 – Inspecter les pages dupliquées La boîte de dialogue « Supprimer les pages dupliquées » affiche une liste des pages dupliquées ou presque dupliquées. Cliquez sur un enregistrement de page pour afficher une page correspondante dans la visionneuse. Examinez les pages et sélectionnez/désélectionnez les pages à supprimer. En option, cliquez sur « Enregistrer le rapport… » pour créer un rapport de similarité de pages au format HTML. Ou cliquez sur « Bookmark Pages » pour créer des signets en PDF pour les pages dupliquées sélectionnées.
Étape 4 – Inspecter les pages dupliquées La boîte de dialogue « Supprimer les pages dupliquées » affiche une liste des pages dupliquées ou presque dupliquées. Cliquez sur un enregistrement de page pour afficher une page correspondante dans la visionneuse. Examinez les pages et sélectionnez/désélectionnez les pages à supprimer. En option, cliquez sur « Enregistrer le rapport… » pour créer un rapport de similarité de pages au format HTML. Ou cliquez sur « Bookmark Pages » pour créer des signets en PDF pour les pages dupliquées sélectionnées..PNG) Le plug-in permet de prévisualiser/comparer les pages dupliquées ou quasi-dupliquées trouvées. La similarité des pages (en %) et le nombre de mots non concordants sont affichés pour chaque paire de pages. Voici les exemples calculés pour la paire de documents papier numérisés :
Le plug-in permet de prévisualiser/comparer les pages dupliquées ou quasi-dupliquées trouvées. La similarité des pages (en %) et le nombre de mots non concordants sont affichés pour chaque paire de pages. Voici les exemples calculés pour la paire de documents papier numérisés :.PNG)
.PNG) Notez que l’apparence et l’emplacement du texte n’affectent pas les résultats. Ces deux pages sont considérées comme identiques malgré la différence dans la couleur du texte :
Notez que l’apparence et l’emplacement du texte n’affectent pas les résultats. Ces deux pages sont considérées comme identiques malgré la différence dans la couleur du texte :
.PNG) Ces deux pages sont considérées comme identiques malgré la différence dans la mise en page du contenu :
Ces deux pages sont considérées comme identiques malgré la différence dans la mise en page du contenu :.PNG) Ces deux pages sont considérées comme similaires à 94% malgré la différence dans l’ordre du texte, la mise en page et l’absence de l’image :
Ces deux pages sont considérées comme similaires à 94% malgré la différence dans l’ordre du texte, la mise en page et l’absence de l’image :.PNG) Étape 5 – Extraire ou mettre en signet les pages dupliquées En option, utilisez le bouton « Signet Pages » pour mettre en signet toutes les pages cochées. Cette option est utile si vous n’avez pas l’intention de supprimer du document les pages dupliquées trouvées. Utilisez les cases à cocher situées devant les pages pour les sélectionner/désélectionner dans l’ensemble de traitement. Utilisez le bouton « Extraire les pages…. » pour extraire toutes les pages cochées dans un document PDF distinct. Cette opération ne supprimera pas les pages du document actuel.
Étape 5 – Extraire ou mettre en signet les pages dupliquées En option, utilisez le bouton « Signet Pages » pour mettre en signet toutes les pages cochées. Cette option est utile si vous n’avez pas l’intention de supprimer du document les pages dupliquées trouvées. Utilisez les cases à cocher situées devant les pages pour les sélectionner/désélectionner dans l’ensemble de traitement. Utilisez le bouton « Extraire les pages…. » pour extraire toutes les pages cochées dans un document PDF distinct. Cette opération ne supprimera pas les pages du document actuel..PNG) Utilisez le bouton « Enregistrer le rapport… » pour enregistrer le rapport de calcul de similarité des pages dans un fichier HTML. Il contient les détails de la similarité des pages, montre les différences entre les pages et liste les mots manquants. Il peut être très utile pour l’analyse approfondie.
Utilisez le bouton « Enregistrer le rapport… » pour enregistrer le rapport de calcul de similarité des pages dans un fichier HTML. Il contient les détails de la similarité des pages, montre les différences entre les pages et liste les mots manquants. Il peut être très utile pour l’analyse approfondie.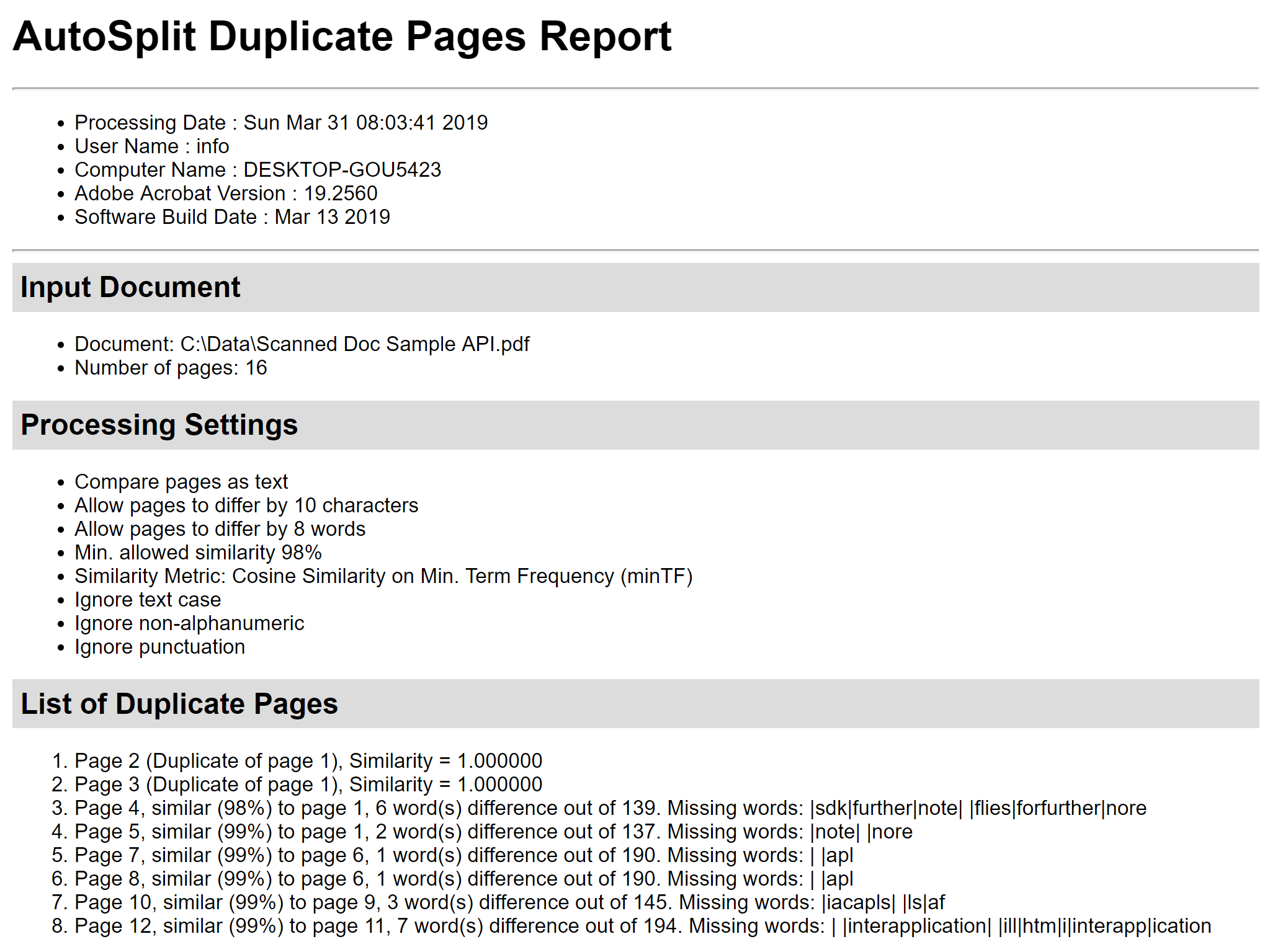 Étape 6 – Supprimer les pages en double Utilisez les cases à cocher devant les pages pour sélectionner/désélectionner les pages à supprimer. Appuyez sur le bouton « Delete Pages » dans la boîte de dialogue « Delete Duplicate Pages » pour supprimer toutes les pages cochées du document PDF actuel :
Étape 6 – Supprimer les pages en double Utilisez les cases à cocher devant les pages pour sélectionner/désélectionner les pages à supprimer. Appuyez sur le bouton « Delete Pages » dans la boîte de dialogue « Delete Duplicate Pages » pour supprimer toutes les pages cochées du document PDF actuel :.PNG) Cliquez sur le bouton « OK » pour confirmer. Les pages seront définitivement supprimées.
Cliquez sur le bouton « OK » pour confirmer. Les pages seront définitivement supprimées..PNG) Méthode 2 – Comparaison de l’apparence visuelle uniquement aperçu Cette méthode compare les pages « en tant qu’images » et détecte les pages qui ont exactement la même apparence. Cette méthode ne compare pas le texte invisible qui peut être présent sur la page. Il est déconseillé d’utiliser cette méthode sur des documents papier numérisés. Étape 1 – Ouvrir un fichier PDF Démarrez l’application Adobe® Acrobat® et ouvrez un fichier PDF à l’aide du menu « Fichier > Ouvrir… ».Étape 2 – Ouvrir la boîte de dialogue « Rechercher les pages en double » Sélectionnez « Plug-Ins > Diviser les documents > Rechercher et supprimer les pages en double… » pour ouvrir la boîte de dialogue « Rechercher les pages en double ».Étape 3 – Spécifier les paramètres Cochez l’option « Comparer l’aspect visuel pour une correspondance exacte (peut être utilisé pour comparer des images) ».
Méthode 2 – Comparaison de l’apparence visuelle uniquement aperçu Cette méthode compare les pages « en tant qu’images » et détecte les pages qui ont exactement la même apparence. Cette méthode ne compare pas le texte invisible qui peut être présent sur la page. Il est déconseillé d’utiliser cette méthode sur des documents papier numérisés. Étape 1 – Ouvrir un fichier PDF Démarrez l’application Adobe® Acrobat® et ouvrez un fichier PDF à l’aide du menu « Fichier > Ouvrir… ».Étape 2 – Ouvrir la boîte de dialogue « Rechercher les pages en double » Sélectionnez « Plug-Ins > Diviser les documents > Rechercher et supprimer les pages en double… » pour ouvrir la boîte de dialogue « Rechercher les pages en double ».Étape 3 – Spécifier les paramètres Cochez l’option « Comparer l’aspect visuel pour une correspondance exacte (peut être utilisé pour comparer des images) »..PNG) Cliquez sur « OK » pour lancer la recherche de pages en double. Étape 4 – Inspecter les pages dupliquées La boîte de dialogue « Supprimer les pages dupliquées » affiche une liste de pages dupliquées ou quasi dupliquées. Cliquez sur un enregistrement de page pour afficher la page correspondante dans la vue côte à côte. Examinez les pages et sélectionnez/désélectionnez les pages pour une éventuelle suppression.
Cliquez sur « OK » pour lancer la recherche de pages en double. Étape 4 – Inspecter les pages dupliquées La boîte de dialogue « Supprimer les pages dupliquées » affiche une liste de pages dupliquées ou quasi dupliquées. Cliquez sur un enregistrement de page pour afficher la page correspondante dans la vue côte à côte. Examinez les pages et sélectionnez/désélectionnez les pages pour une éventuelle suppression.
.PNG) En option, cliquez sur « Enregistrer le rapport… » pour créer un rapport de similarité de pages au format HTML. Ou cliquez sur « Bookmark Pages » pour créer des signets en PDF pour les pages dupliquées sélectionnées. Cette méthode est basée sur la création de petites copies (échantillonnées) des pages et leur comparaison « en tant qu’images ». L’exemple suivant montre deux pages identiques qui ne contiennent que des graphiques et aucun texte consultable :
En option, cliquez sur « Enregistrer le rapport… » pour créer un rapport de similarité de pages au format HTML. Ou cliquez sur « Bookmark Pages » pour créer des signets en PDF pour les pages dupliquées sélectionnées. Cette méthode est basée sur la création de petites copies (échantillonnées) des pages et leur comparaison « en tant qu’images ». L’exemple suivant montre deux pages identiques qui ne contiennent que des graphiques et aucun texte consultable :.PNG) Si les pages sont visuellement identiques, alors le logiciel les détecte comme des doublons :
Si les pages sont visuellement identiques, alors le logiciel les détecte comme des doublons :.PNG) Ces deux pages sont considérées comme différentes en raison du tampon « Approuvé » sur l’une des pages :
Ces deux pages sont considérées comme différentes en raison du tampon « Approuvé » sur l’une des pages :.PNG) Ces deux pages sont considérées comme identiques par cette méthode :
Ces deux pages sont considérées comme identiques par cette méthode :.PNG) Contrairement à la méthode de comparaison basée sur le texte, si la couleur ou le style du texte est différent, alors les pages ne sont pas considérées comme identiques :
Contrairement à la méthode de comparaison basée sur le texte, si la couleur ou le style du texte est différent, alors les pages ne sont pas considérées comme identiques :.PNG) Étape 5 – Supprimer les pages dupliquées Cliquez sur « Supprimer les pages » dans la boîte de dialogue « Supprimer les pages dupliquées » pour continuer. Cliquez sur le bouton « OK » pour supprimer les pages des documents PDF actuels. Les pages seront définitivement supprimées.Comparaison de documents PDF multiples Cette opération peut être utilisée pour trouver et supprimer les pages en double des documents PDF multiples. L’approche consiste à combiner un ou plusieurs documents dans un seul fichier PDF et à exécuter l’opération « Trouver et supprimer les pages en double » sur le fichier résultant. Cela produira essentiellement un document unique sans aucun doublon. En option, il est possible d’extraire toutes les pages en double détectées dans un document PDF distinct. Étape 1 – Aperçu de la combinaison de plusieurs documents PDF Démarrez l’application Adobe® Acrobat® et sélectionnez « Outils » dans le menu. Sélectionnez l’icône « Combiner des fichiers » dans la liste des outils.
Étape 5 – Supprimer les pages dupliquées Cliquez sur « Supprimer les pages » dans la boîte de dialogue « Supprimer les pages dupliquées » pour continuer. Cliquez sur le bouton « OK » pour supprimer les pages des documents PDF actuels. Les pages seront définitivement supprimées.Comparaison de documents PDF multiples Cette opération peut être utilisée pour trouver et supprimer les pages en double des documents PDF multiples. L’approche consiste à combiner un ou plusieurs documents dans un seul fichier PDF et à exécuter l’opération « Trouver et supprimer les pages en double » sur le fichier résultant. Cela produira essentiellement un document unique sans aucun doublon. En option, il est possible d’extraire toutes les pages en double détectées dans un document PDF distinct. Étape 1 – Aperçu de la combinaison de plusieurs documents PDF Démarrez l’application Adobe® Acrobat® et sélectionnez « Outils » dans le menu. Sélectionnez l’icône « Combiner des fichiers » dans la liste des outils..PNG) Cliquez sur « Ajouter des fichiers… » dans le menu « Combiner des fichiers » et sélectionnez les fichiers PDF à fusionner pour les comparer.
Cliquez sur « Ajouter des fichiers… » dans le menu « Combiner des fichiers » et sélectionnez les fichiers PDF à fusionner pour les comparer..PNG) Cliquez sur le bouton « Combiner » dans le menu pour fusionner les fichiers PDF sélectionnés.
Cliquez sur le bouton « Combiner » dans le menu pour fusionner les fichiers PDF sélectionnés..PNG) Étape 2 – Trouver les pages en double Le fichier PDF de sortie combiné apparaîtrait à l’écran. Si ce n’est pas le cas, ouvrez le fichier PDF combiné. Sélectionnez « Plug-Ins > Diviser les documents > Rechercher et supprimer les pages en double… » pour ouvrir la boîte de dialogue « Rechercher les pages en double ».Cochez l’option « Comparer l’aspect visuel pour une correspondance exacte (peut être utilisé pour comparer des images) ». Cliquez sur « OK » pour lancer la recherche de pages en double.
Étape 2 – Trouver les pages en double Le fichier PDF de sortie combiné apparaîtrait à l’écran. Si ce n’est pas le cas, ouvrez le fichier PDF combiné. Sélectionnez « Plug-Ins > Diviser les documents > Rechercher et supprimer les pages en double… » pour ouvrir la boîte de dialogue « Rechercher les pages en double ».Cochez l’option « Comparer l’aspect visuel pour une correspondance exacte (peut être utilisé pour comparer des images) ». Cliquez sur « OK » pour lancer la recherche de pages en double..PNG) Étape 3 – Extraire les pages en double La boîte de dialogue « Supprimer les pages en double » affichera une liste de pages en double ou quasi-doubles. Cliquez sur un enregistrement de page pour afficher une page correspondante dans le visualiseur. Examinez les pages et sélectionnez/désélectionnez les pages. Cliquez sur « Extraire les pages… » pour extraire les pages dupliquées sélectionnées dans un nouveau document PDF.
Étape 3 – Extraire les pages en double La boîte de dialogue « Supprimer les pages en double » affichera une liste de pages en double ou quasi-doubles. Cliquez sur un enregistrement de page pour afficher une page correspondante dans le visualiseur. Examinez les pages et sélectionnez/désélectionnez les pages. Cliquez sur « Extraire les pages… » pour extraire les pages dupliquées sélectionnées dans un nouveau document PDF..PNG) Spécifiez un dossier de sortie et un nom de fichier. Cliquez sur « Enregistrer » une fois terminé.
Spécifiez un dossier de sortie et un nom de fichier. Cliquez sur « Enregistrer » une fois terminé..PNG) Le dialogue apparaîtrait montrant le nombre de pages qui ont été extraites dans un document séparé. Maintenant, vous avez enregistré toutes les pages en double dans le fichier PDF séparé avant de les supprimer. Vous pouvez examiner ces pages et les utiliser plus tard si nécessaire. Cliquez sur « OK » pour fermer la boîte de dialogue.
Le dialogue apparaîtrait montrant le nombre de pages qui ont été extraites dans un document séparé. Maintenant, vous avez enregistré toutes les pages en double dans le fichier PDF séparé avant de les supprimer. Vous pouvez examiner ces pages et les utiliser plus tard si nécessaire. Cliquez sur « OK » pour fermer la boîte de dialogue..png) Étape 4 – Supprimer les pages en double Cliquez sur « Supprimer les pages » dans le dialogue « Supprimer les pages en double » pour continuer.
Étape 4 – Supprimer les pages en double Cliquez sur « Supprimer les pages » dans le dialogue « Supprimer les pages en double » pour continuer..PNG) Cliquez sur « OK » dans la boîte de dialogue pour supprimer les pages en double sélectionnées dans le document PDF actuel.
Cliquez sur « OK » dans la boîte de dialogue pour supprimer les pages en double sélectionnées dans le document PDF actuel..PNG) Les pages en double sélectionnées seraient définitivement supprimées du document PDF. Vous auriez besoin d’utiliser le menu « File > Save » pour enregistrer le document modifié sur le disque. Cliquez ici pour obtenir la liste de tous les tutoriels pas à pas disponibles.
Les pages en double sélectionnées seraient définitivement supprimées du document PDF. Vous auriez besoin d’utiliser le menu « File > Save » pour enregistrer le document modifié sur le disque. Cliquez ici pour obtenir la liste de tous les tutoriels pas à pas disponibles.