- Introduction
- But
- A. Méthodes de filtrage
- Test du chi-deux
- Score de Fisher
- Coefficient de corrélation
- Seuil de variance
- Différence absolue moyenne (MAD)
- Ratio de dispersion
- B. Méthodes d’enveloppement :
- Sélection de caractéristiques vers l’avant
- Élimination rétrospective des caractéristiques
- Sélection exhaustive des caractéristiques
- Élimination récursive de caractéristiques
- C. Méthodes embarquées :
- Régularisation LASSO (L1)
- Importance des forêts aléatoires
- Conclusion
Introduction
Lors de la construction d’un modèle d’apprentissage automatique dans la vie réelle, il est presque rare que toutes les variables de l’ensemble de données soient utiles pour construire un modèle. L’ajout de variables redondantes réduit la capacité de généralisation du modèle et peut également réduire la précision globale d’un classificateur. En outre, l’ajout de plus en plus de variables à un modèle augmente la complexité globale du modèle.
Selon la loi de parcimonie du ‘Rasoir d’Occam’, la meilleure explication à un problème est celle qui implique le moins d’hypothèses possibles. Ainsi, la sélection de caractéristiques devient une partie indispensable de la construction de modèles d’apprentissage automatique.
But
Le but de la sélection de caractéristiques dans l’apprentissage automatique est de trouver le meilleur ensemble de caractéristiques qui permet de construire des modèles utiles des phénomènes étudiés.
Les techniques de sélection de caractéristiques dans l’apprentissage automatique peuvent être largement classées dans les catégories suivantes :
Techniques supervisées : Ces techniques peuvent être utilisées pour les données étiquetées, et sont utilisées pour identifier les caractéristiques pertinentes pour augmenter l’efficacité des modèles supervisés comme la classification et la régression.
Techniques non supervisées : Ces techniques peuvent être utilisées pour les données non étiquetées.
D’un point de vue taxonomique, ces techniques sont classées comme suit :
A. Méthodes de filtrage
B. Méthodes enveloppantes
C. Méthodes embarquées
D. Méthodes hybrides
Dans cet article, nous allons discuter de quelques techniques populaires de sélection de caractéristiques dans l’apprentissage automatique.
A. Méthodes de filtrage
Les méthodes de filtrage reprennent les propriétés intrinsèques des caractéristiques mesurées via des statistiques univariées au lieu des performances de validation croisée. Ces méthodes sont plus rapides et moins coûteuses en calcul que les méthodes enveloppantes. Lorsque l’on traite des données à haute dimension, il est moins coûteux en calcul d’utiliser des méthodes de filtre.
Discutons de certaines de ces techniques :
Gain d’information
Le gain d’information calcule la réduction de l’entropie à partir de la transformation d’un ensemble de données. Il peut être utilisé pour la sélection des caractéristiques en évaluant le gain d’information de chaque variable dans le contexte de la variable cible.
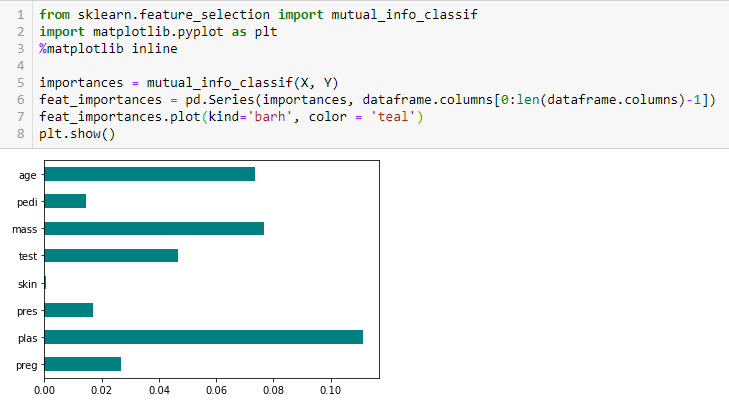
Test du chi-deux
Le test du chi-deux est utilisé pour les caractéristiques catégorielles dans un ensemble de données. Nous calculons le Chi-deux entre chaque caractéristique et la cible et sélectionnons le nombre souhaité de caractéristiques ayant les meilleurs scores de Chi-deux. Pour appliquer correctement le chi-deux afin de tester la relation entre diverses caractéristiques dans l’ensemble de données et la variable cible, les conditions suivantes doivent être remplies : les variables doivent être catégoriques, échantillonnées indépendamment et les valeurs doivent avoir une fréquence attendue supérieure à 5.
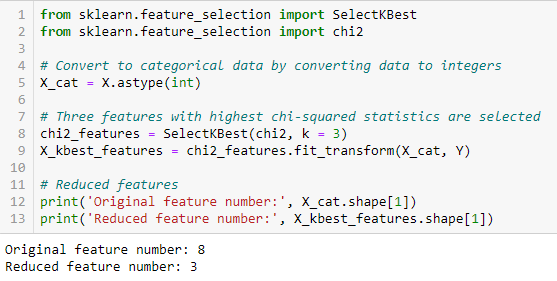
Score de Fisher
Le score de Fisher est l’une des méthodes de sélection supervisée de caractéristiques les plus utilisées. L’algorithme que nous allons utiliser renvoie les rangs des variables en fonction du score de fisher par ordre décroissant. Nous pouvons alors sélectionner les variables en fonction du cas.
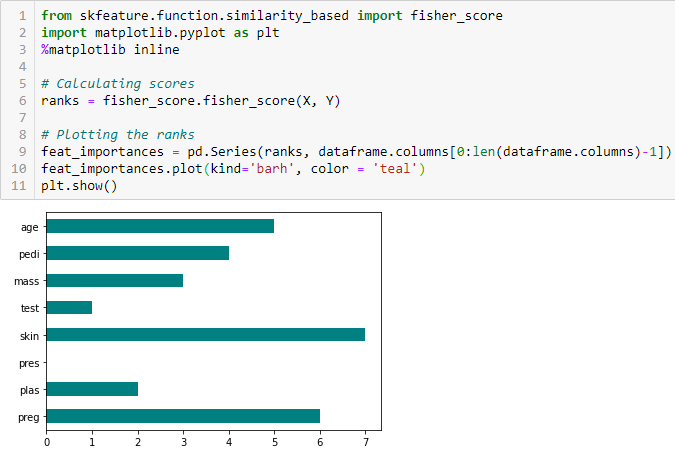
Coefficient de corrélation
La corrélation est une mesure de la relation linéaire de 2 ou plusieurs variables. Grâce à la corrélation, nous pouvons prédire une variable à partir d’une autre. La logique derrière l’utilisation de la corrélation pour la sélection des caractéristiques est que les bonnes variables sont fortement corrélées avec la cible. De plus, les variables doivent être corrélées avec la cible mais doivent être non corrélées entre elles.
Si deux variables sont corrélées, nous pouvons prédire l’une à partir de l’autre. Par conséquent, si deux caractéristiques sont corrélées, le modèle n’a réellement besoin que de l’une d’entre elles, car la seconde n’apporte pas d’information supplémentaire. Nous utiliserons ici la corrélation de Pearson.
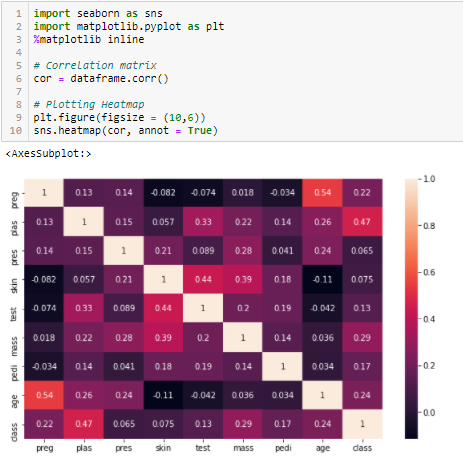
Nous devons fixer une valeur absolue, disons 0,5 comme seuil de sélection des variables. Si nous constatons que les variables prédictives sont corrélées entre elles, nous pouvons abandonner la variable qui a une valeur de coefficient de corrélation plus faible avec la variable cible. Nous pouvons également calculer des coefficients de corrélation multiples pour vérifier si plus de deux variables sont corrélées entre elles. Ce phénomène est connu sous le nom de multicollinéarité.
Seuil de variance
Le seuil de variance est une approche de base simple pour la sélection des caractéristiques. Il supprime toutes les caractéristiques dont la variance n’atteint pas un certain seuil. Par défaut, il supprime toutes les caractéristiques à variance nulle, c’est-à-dire les caractéristiques qui ont la même valeur dans tous les échantillons. Nous supposons que les caractéristiques avec une variance plus élevée peuvent contenir plus d’informations utiles, mais notez que nous ne prenons pas en compte la relation entre les variables des caractéristiques ou les variables des caractéristiques et de la cible, ce qui est l’un des inconvénients des méthodes de filtrage.

Le get_support renvoie un vecteur booléen où True signifie que la variable n’a pas une variance nulle.
Différence absolue moyenne (MAD)
‘La différence absolue moyenne (MAD) calcule la différence absolue par rapport à la valeur moyenne. La principale différence entre les mesures de la variance et de la MAD est l’absence du carré dans cette dernière. La MAD, comme la variance, est également une variante d’échelle. » Cela signifie que plus le MAD est élevé, plus le pouvoir discriminatoire est élevé.
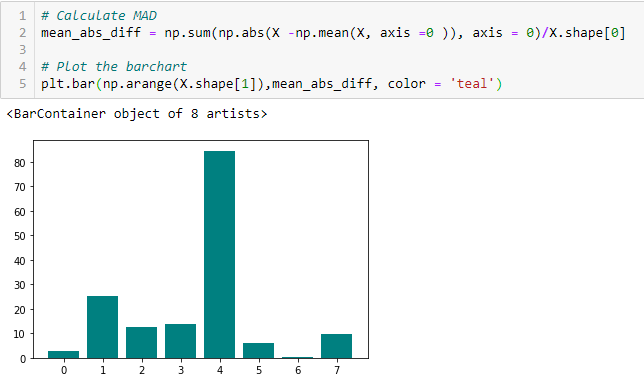
Ratio de dispersion
‘Une autre mesure de dispersion applique la moyenne arithmétique (AM) et la moyenne géométrique (GM). Pour une caractéristique (positive) donnée Xi sur n motifs, l’AM et la GM sont données par
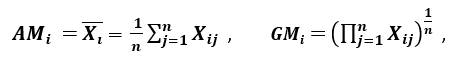
respectivement ; puisque AMi ≥ GMi, l’égalité tenant si et seulement si Xi1 = Xi2 = …. = Xin, alors le rapport
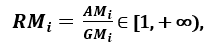
peut être utilisé comme mesure de dispersion. Une dispersion plus élevée implique une valeur plus élevée de Ri, donc une caractéristique plus pertinente. À l’inverse, lorsque tous les échantillons de caractéristiques ont (à peu près) la même valeur, Ri est proche de 1, ce qui indique une caractéristique peu pertinente. »

 ‘
‘
B. Méthodes d’enveloppement :
Les wrappers nécessitent une méthode pour rechercher l’espace de tous les sous-ensembles possibles de caractéristiques, en évaluant leur qualité par l’apprentissage et l’évaluation d’un classificateur avec ce sous-ensemble de caractéristiques. Le processus de sélection des caractéristiques est basé sur un algorithme spécifique d’apprentissage automatique que nous essayons d’adapter à un ensemble de données donné. Il suit une approche de recherche gloutonne en évaluant toutes les combinaisons possibles de caractéristiques par rapport au critère d’évaluation. Les méthodes d’enveloppement donnent généralement une meilleure précision prédictive que les méthodes de filtrage.
Discutons de certaines de ces techniques :
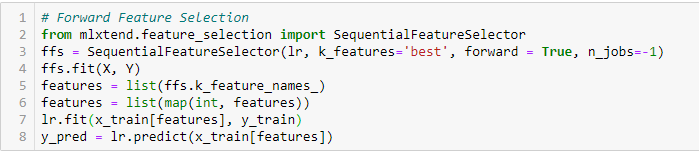
Sélection de caractéristiques vers l’avant
Il s’agit d’une méthode itérative dans laquelle nous commençons par la variable la plus performante par rapport à la cible. Ensuite, on sélectionne une autre variable qui donne la meilleure performance en combinaison avec la première variable sélectionnée. Ce processus se poursuit jusqu’à ce que le critère préétabli soit atteint.
Élimination rétrospective des caractéristiques
Cette méthode fonctionne exactement à l’opposé de la méthode de sélection prospective des caractéristiques. Ici, nous commençons avec toutes les caractéristiques disponibles et construisons un modèle. Ensuite, on extrait du modèle la variable qui donne la meilleure valeur de mesure d’évaluation. Ce processus est poursuivi jusqu’à ce que le critère prédéfini soit atteint.
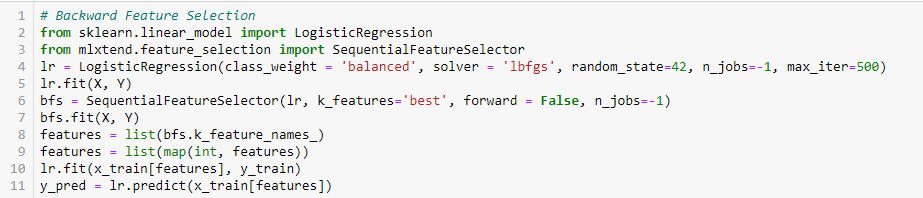
Cette méthode ainsi que celle discutée ci-dessus est également connue sous le nom de méthode de sélection séquentielle des caractéristiques.
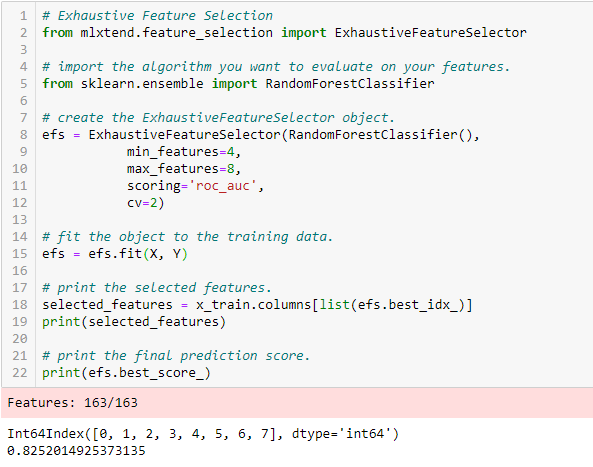
Sélection exhaustive des caractéristiques
C’est la méthode de sélection des caractéristiques la plus robuste couverte jusqu’à présent. Il s’agit d’une évaluation par force brute de chaque sous-ensemble de caractéristiques. Cela signifie qu’elle essaie toutes les combinaisons possibles des variables et renvoie le sous-ensemble le plus performant.
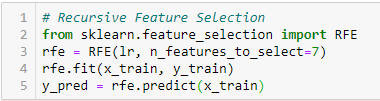
Élimination récursive de caractéristiques
‘Étant donné un estimateur externe qui attribue des poids aux caractéristiques (par exemple, les coefficients d’un modèle linéaire), l’objectif de l’élimination récursive de caractéristiques (RFE) est de sélectionner des caractéristiques en considérant de manière récursive des ensembles de caractéristiques de plus en plus petits. Tout d’abord, l’estimateur est entraîné sur l’ensemble initial de caractéristiques et l’importance de chaque caractéristique est obtenue soit par un attribut coef_, soit par un attribut feature_importances_.
Puis, les caractéristiques les moins importantes sont élaguées de l’ensemble actuel de caractéristiques. Cette procédure est répétée de manière récursive sur l’ensemble élagué jusqu’à ce que le nombre souhaité de caractéristiques à sélectionner soit finalement atteint.’
C. Méthodes embarquées :
Ces méthodes englobent les avantages des méthodes enveloppantes et filtrantes, en incluant les interactions des caractéristiques mais aussi en maintenant un coût de calcul raisonnable. Les méthodes embarquées sont itératives dans le sens où elles prennent en charge chaque itération du processus de formation du modèle et extraient soigneusement les caractéristiques qui contribuent le plus à la formation pour une itération particulière.
Discutons, de certaines de ces techniques cliquez ici :
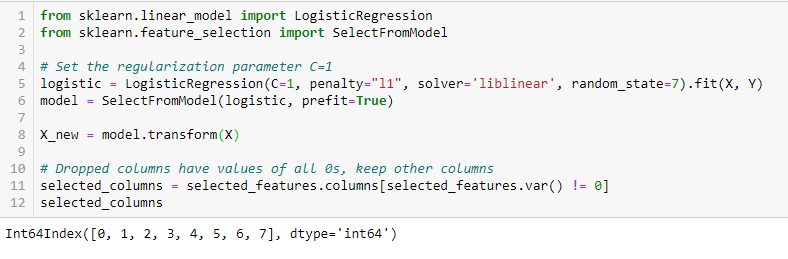
Régularisation LASSO (L1)
La régularisation consiste à ajouter une pénalité aux différents paramètres du modèle d’apprentissage automatique pour réduire la liberté du modèle, c’est-à-dire pour éviter le surajustement. Dans la régularisation des modèles linéaires, la pénalité est appliquée sur les coefficients qui multiplient chacun des prédicteurs. Parmi les différents types de régularisation, le Lasso ou L1 a la propriété de réduire à zéro certains des coefficients. Par conséquent, cette caractéristique peut être supprimée du modèle.
Importance des forêts aléatoires
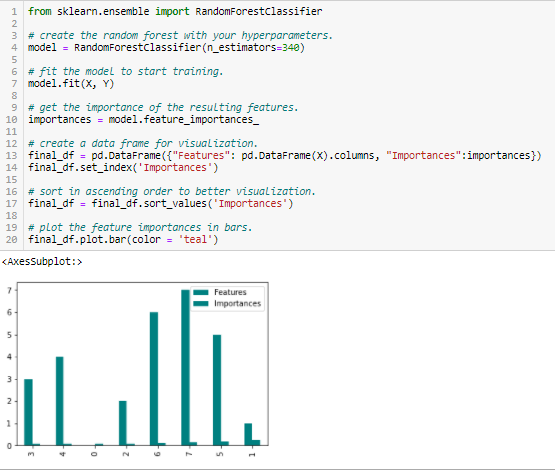
Les forêts aléatoires sont une sorte d’algorithme de mise en sac qui agrège un nombre spécifié d’arbres de décision. Les stratégies arborescentes utilisées par les forêts aléatoires sont naturellement classées en fonction de la façon dont elles améliorent la pureté du nœud, ou en d’autres termes la diminution de l’impureté (impureté de Gini) sur tous les arbres. Les nœuds dont l’impureté diminue le plus se trouvent au début des arbres, tandis que les notes dont l’impureté diminue le moins se trouvent à la fin des arbres. Ainsi, en élaguant les arbres sous un nœud particulier, nous pouvons créer un sous-ensemble des caractéristiques les plus importantes.
Conclusion
Nous avons discuté de quelques techniques de sélection de caractéristiques. Nous avons à dessein laissé les techniques d’extraction de caractéristiques comme l’analyse en composantes principales, la décomposition en valeurs singulières, l’analyse discriminante linéaire, etc. Ces méthodes permettent de réduire la dimensionnalité des données ou de réduire le nombre de variables tout en préservant la variance des données.
En dehors des méthodes abordées ci-dessus, il existe de nombreuses autres méthodes de sélection de caractéristiques. Il existe également des méthodes hybrides qui utilisent à la fois des techniques de filtrage et d’enveloppement. Si vous souhaitez explorer davantage les techniques de sélection de caractéristiques, un grand matériel de lecture complet à mon avis serait ‘Feature Selection for Data and Pattern Recognition’ par Urszula Stańczyk et Lakhmi C. Jain.