Mise à jour 29-Mai-2018 : L’objectif de cet article est triple (1) Montrer que nous aurons toujours besoin d’un modèle de données (soit fait par des humains ou des machines) (2) Montrer que la modélisation physique n’est pas la même chose que la modélisation logique. En fait, elle est très différente et dépend de la technologie sous-jacente. Mais nous avons besoin des deux. J’ai illustré ce point en utilisant Hadoop au niveau de la couche physique (3) Montrer l’impact du concept d’immuabilité sur la modélisation des données.
- La modélisation dimensionnelle est-elle morte ?
- Pourquoi avons-nous besoin de modéliser nos données ?
- Pourquoi avons-nous besoin de modèles dimensionnels ?
- Modélisation des données vs modélisation dimensionnelle
- Alors pourquoi certaines personnes prétendent que la modélisation dimensionnelle est morte ?
- L’entrepôt de données est mort Confusion
- Le schéma sur le malentendu de lecture
- Dénormalisation revisitée. Les aspects physiques du modèle.
- Prendre la dé-normalisation à sa pleine conclusion
- Distribution des données sur une base de données relationnelle distribuée (MPP)
- Data Distribution on Hadoop
- Modèles dimensionnels sur Hadoop
- Hadoop et les dimensions qui changent lentement
- L’évolution du stockage sur Hadoop
- Le verdict. Les modèles dimensionnels et les schémas en étoile sont-ils obsolètes ?
- Lectures complémentaires sur la modélisation dimensionnelle à l’ère du Big Data
La modélisation dimensionnelle est-elle morte ?
Avant de vous donner une réponse à cette question, prenons un peu de recul et regardons d’abord ce que nous entendons par modélisation dimensionnelle des données.
Pourquoi avons-nous besoin de modéliser nos données ?
Contrairement à un malentendu courant, les modèles de données n’ont pas pour seul objectif de servir de diagramme ER pour la conception d’une base de données physique. Les modèles de données représentent la complexité des processus métier d’une entreprise. Ils documentent les règles et les concepts importants de l’entreprise et aident à normaliser la terminologie clé de l’entreprise. Ils apportent de la clarté et permettent de lever le voile sur les idées floues et les ambiguïtés des processus métier. En outre, vous pouvez utiliser les modèles de données pour communiquer avec d’autres parties prenantes. Vous ne construiriez pas une maison ou un pont sans plan. Alors pourquoi construiriez-vous une application de données telle qu’un entrepôt de données sans plan ?
Pourquoi avons-nous besoin de modèles dimensionnels ?
La modélisation dimensionnelle est une approche particulière de la modélisation des données. Nous utilisons également les mots data mart ou schéma en étoile comme synonymes d’un modèle dimensionnel. Les schémas en étoile sont optimisés pour l’analyse des données. Jetez un coup d’œil au modèle dimensionnel ci-dessous. Sa compréhension est assez intuitive. Nous voyons immédiatement comment nous pouvons trancher et découper nos données de commande par client, produit ou date et mesurer la performance du processus métier Commandes en agrégeant et en comparant les métriques.
L’une des idées centrales de la modélisation dimensionnelle est de définir le plus bas niveau de granularité dans un processus métier transactionnel. Lorsque nous découpons et forons les données, il s’agit du niveau de la feuille à partir duquel nous ne pouvons pas forer davantage. Dit autrement, le plus bas niveau de granularité dans un schéma en étoile est une jointure du fait à toutes les tables de dimension sans aucune agrégation.
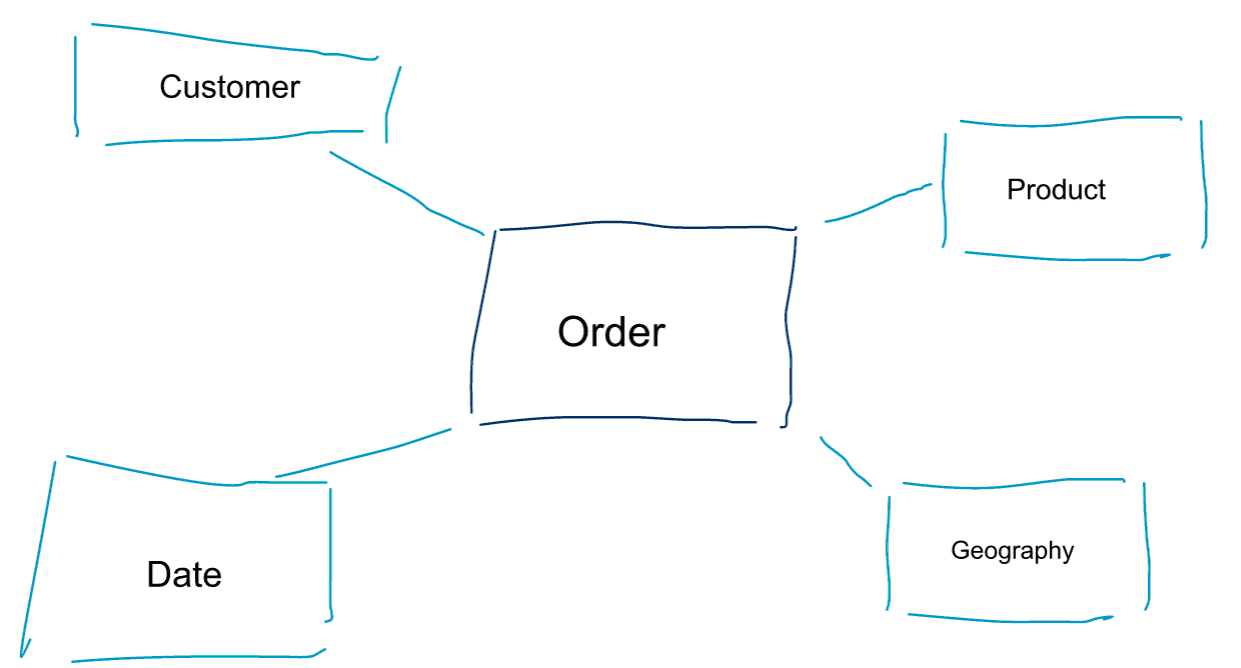
Modélisation des données vs modélisation dimensionnelle
Dans la modélisation standard des données, nous visons à éliminer la répétition et la redondance des données. Lorsqu’un changement survient dans les données, nous ne devons le modifier qu’à un seul endroit. Cela contribue également à la qualité des données. Les valeurs ne sont pas désynchronisées à plusieurs endroits. Jetez un coup d’œil au modèle ci-dessous. Il contient plusieurs tableaux qui représentent des concepts géographiques. Dans un modèle normalisé, nous avons une table séparée pour chaque entité. Dans un modèle dimensionnel, nous n’avons qu’une seule table : géographie. Dans cette table, les villes seront répétées plusieurs fois. Une fois pour chaque ville. Si le pays change de nom, nous devons mettre à jour le pays à de nombreux endroits
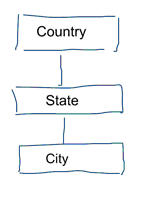
Note : la modélisation standard des données est également appelée modélisation 3NF.
L’approche standard de la modélisation des données n’est pas adaptée aux charges de travail de la Business Intelligence. Un grand nombre de tables entraîne un grand nombre de jointures. Les jointures ralentissent les choses. Dans l’analyse des données, nous les évitons autant que possible. Dans les modèles dimensionnels, nous dé-normalisons plusieurs tables liées en une seule table, par exemple, les différentes tables de notre exemple précédent peuvent être pré-jointées en une seule table : géographie.
Alors pourquoi certaines personnes prétendent que la modélisation dimensionnelle est morte ?
Je pense que vous serez d’accord pour dire que la modélisation des données en général et la modélisation dimensionnelle en particulier est un exercice assez utile. Alors pourquoi certaines personnes prétendent que la modélisation dimensionnelle n’est pas utile à l’ère du big data et de Hadoop ?
Comme vous pouvez l’imaginer, il y a plusieurs raisons à cela.
L’entrepôt de données est mort Confusion
Tout d’abord, certaines personnes confondent la modélisation dimensionnelle avec l’entreposage de données. Ils prétendent que l’entrepôt de données est mort et que, par conséquent, la modélisation dimensionnelle peut également être reléguée dans les poubelles de l’histoire. Il s’agit d’un argument logiquement cohérent. Cependant, le concept d’entrepôt de données est loin d’être obsolète. Nous avons toujours besoin de données intégrées et fiables pour alimenter nos tableaux de bord de BI. Si vous voulez en savoir plus, je vous recommande notre cours de formation « Big Data for Data Warehouse Professionals ». Dans ce cours, j’entre dans les détails et j’explique pourquoi l’entrepôt de données est toujours aussi pertinent. Je montrerai également comment les outils et technologies big data émergents sont utiles pour l’entreposage de données.

Le schéma sur le malentendu de lecture
Le deuxième argument que j’entends fréquemment est le suivant . ‘Nous suivons une approche schema on read et n’avons plus besoin de modéliser nos données’. À mon avis, le concept de schéma sur lecture est l’un des plus grands malentendus dans l’analyse des données. Je conviens qu’il est utile de stocker initialement vos données brutes dans un vidage de données qui est léger en termes de schéma. Toutefois, cet argument ne doit pas servir d’excuse pour ne pas modéliser vos données. L’approche « schema on read » ne fait que renvoyer la balle et la responsabilité aux processus en aval. Quelqu’un doit toujours se charger de définir les types de données. Chaque processus qui accède à la décharge de données sans schéma doit comprendre par lui-même ce qui se passe. Ce type de travail s’additionne, est complètement redondant, et peut être facilement évité en définissant des types de données et un schéma approprié.
Dénormalisation revisitée. Les aspects physiques du modèle.
Y a-t-il réellement des arguments valables pour déclarer les modèles dimensionnels obsolètes ? Il y a effectivement quelques meilleurs arguments que les deux que j’ai énumérés ci-dessus. Ils nécessitent une certaine compréhension de la modélisation physique des données et de la façon dont Hadoop fonctionne. Soyez indulgent avec moi.
Plus tôt, j’ai brièvement mentionné l’une des raisons pour lesquelles nous modélisons nos données de manière dimensionnelle. C’est en relation avec la façon dont les données sont stockées physiquement dans notre magasin de données. Dans la modélisation standard des données, chaque entité du monde réel obtient sa propre table. Nous faisons cela pour éviter la redondance des données et le risque que des problèmes de qualité des données se glissent dans nos données. Plus nous avons de tables, plus nous avons besoin de jointures. C’est là l’inconvénient. Les jointures de tables sont coûteuses, surtout lorsque nous joignons un grand nombre d’enregistrements de nos ensembles de données. Lorsque nous modélisons les données de manière dimensionnelle, nous consolidons plusieurs tables en une seule. Nous disons que nous pré-joignons ou dé-normalisons les données. Nous avons maintenant moins de tables, moins de jointures et, par conséquent, une latence plus faible et de meilleures performances de requête.
Participez à la discussion de cet article sur LinkedIn
Prendre la dé-normalisation à sa pleine conclusion
Pourquoi ne pas prendre la dé-normalisation à sa pleine conclusion ? Se débarrasser de toutes les jointures et n’avoir qu’une seule table de faits ? En effet, cela éliminerait complètement le besoin de toute jointure. Cependant, comme vous pouvez l’imaginer, cela a quelques effets secondaires. Tout d’abord, cela augmente la quantité de stockage nécessaire. Nous devons maintenant stocker un grand nombre de données redondantes. Avec l’avènement des formats de stockage en colonnes pour l’analyse des données, ce problème est moins préoccupant aujourd’hui. Le plus gros problème de la dé-normalisation est le fait que chaque fois que la valeur de l’un des attributs change, nous devons mettre à jour la valeur à plusieurs endroits – peut-être des milliers ou des millions de mises à jour. Une façon de contourner ce problème est de recharger entièrement nos modèles chaque nuit. Souvent, cela sera beaucoup plus rapide et facile que d’appliquer un grand nombre de mises à jour. Les bases de données colonnaires adoptent généralement l’approche suivante. Elles stockent d’abord les mises à jour des données en mémoire et les écrivent de manière asynchrone sur le disque.
Distribution des données sur une base de données relationnelle distribuée (MPP)
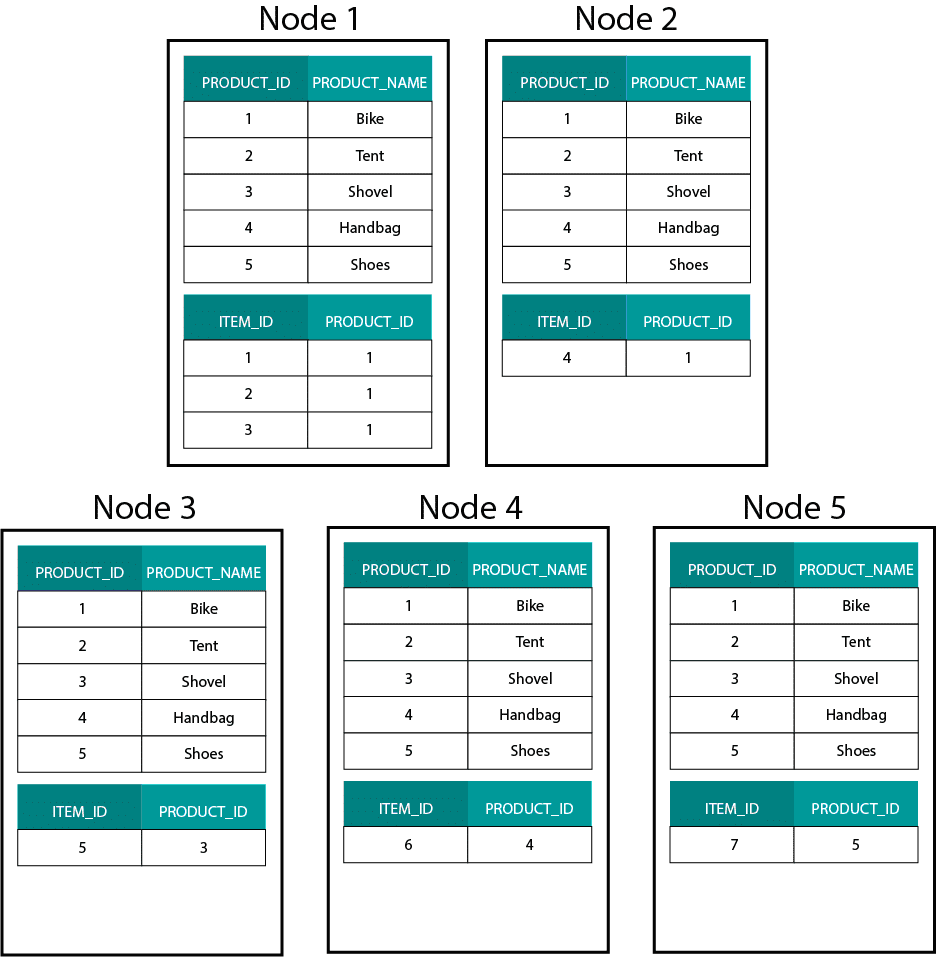
Lorsque nous créons des modèles dimensionnels sur Hadoop, par exemple Hive, SparkSQL, etc. nous devons mieux comprendre une caractéristique essentielle de la technologie qui la distingue d’une base de données relationnelle distribuée (MPP) telle que Teradata, etc. Lors de la distribution des données sur les nœuds d’une MPP, nous avons le contrôle du placement des enregistrements. En fonction de notre stratégie de partitionnement (par exemple, hachage, liste, plage, etc.), nous pouvons placer les clés des enregistrements individuels sur plusieurs onglets d’un même nœud. La co-localité des données étant garantie, nos jointures sont super rapides car nous n’avons pas besoin d’envoyer de données sur le réseau. Regardez l’exemple ci-dessous. Les enregistrements avec le même ORDER_ID des tables ORDER et ORDER_ITEM se retrouvent sur le même nœud.
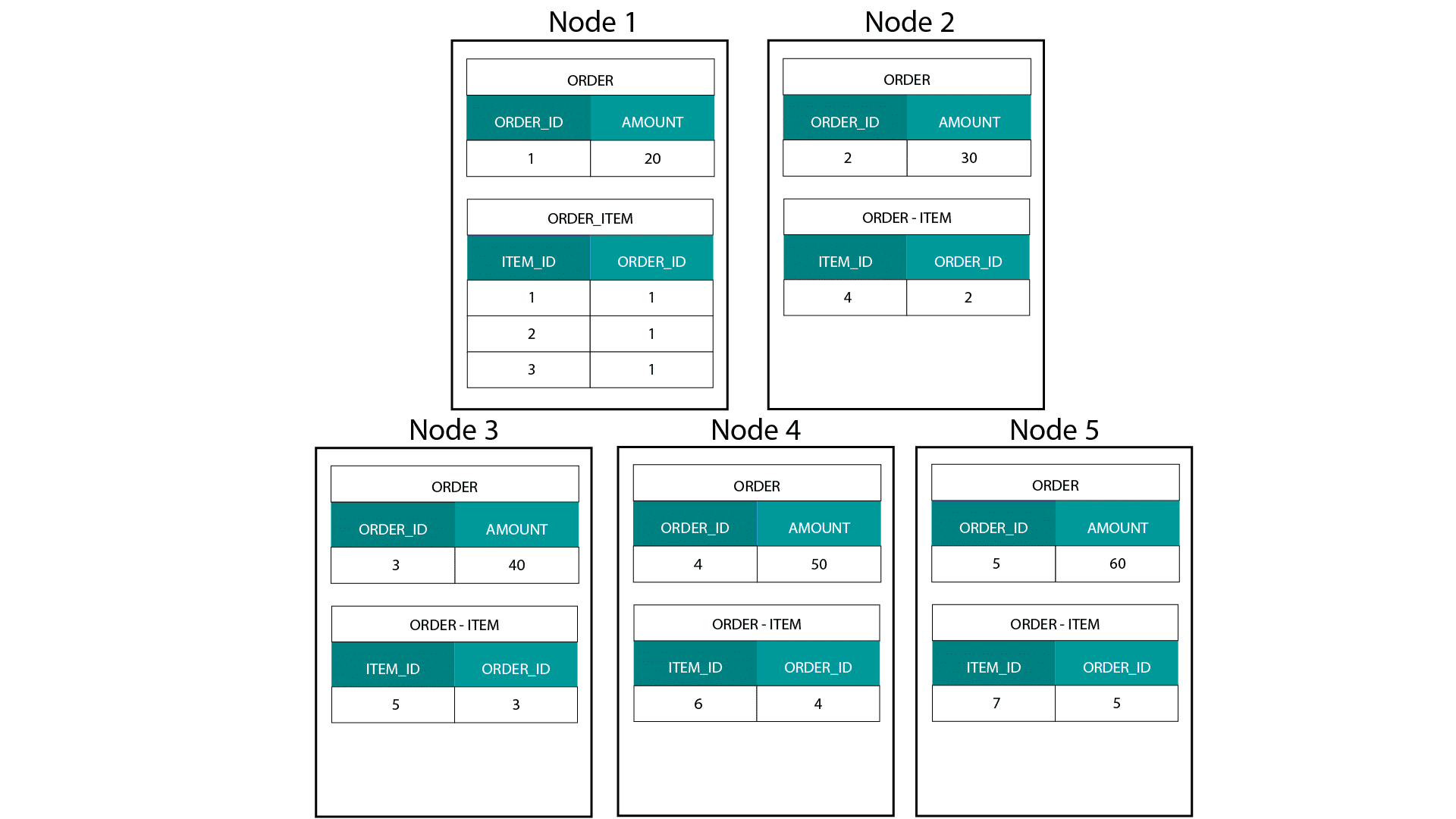
Les clés pour order_id de la table order et order_item sont colocalisées sur les mêmes nœuds.
Data Distribution on Hadoop
C’est très différent des systèmes basés sur Hadoop. Là, nous divisons nos données en morceaux de grande taille et nous les distribuons et répliquons à travers nos nœuds sur le système de fichiers distribués Hadoop (HDFS). Avec cette stratégie de distribution des données, nous ne pouvons pas garantir la co-localité des données. Regardez l’exemple ci-dessous. Les enregistrements pour la clé ORDER_ID se retrouvent sur différents nœuds.
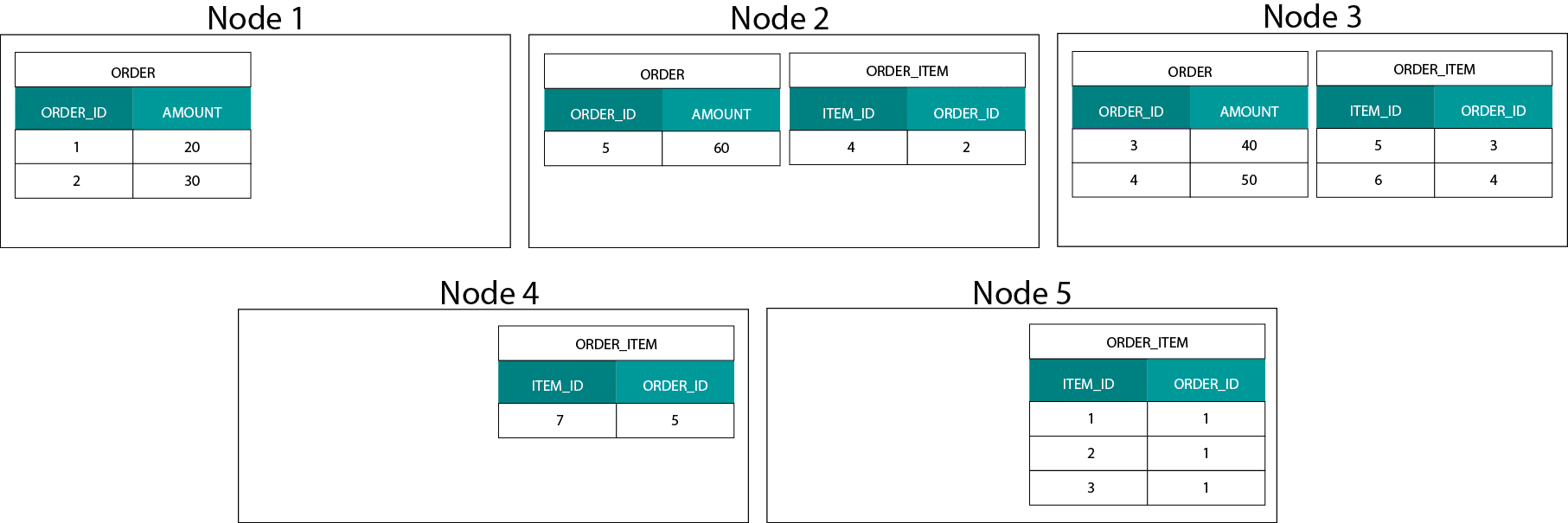
Pour effectuer une jointure, nous devons envoyer des données sur le réseau, ce qui a un impact sur les performances.
Une stratégie pour traiter ce problème consiste à répliquer l’une des tables de jointure sur tous les nœuds du cluster. Cela s’appelle une jointure de diffusion et nous utilisons la même stratégie sur un MPP. Comme vous pouvez l’imaginer, cela ne fonctionne que pour les petites tables de consultation ou de dimension.
Alors, que faisons-nous lorsque nous avons une grande table de faits et une grande table de dimension, par exemple client ou produit ? Ou même lorsque nous avons deux grandes tables de faits.
Modèles dimensionnels sur Hadoop
Pour contourner ce problème de performance, nous pouvons dé-normaliser les grandes tables de dimensions dans notre table de faits pour garantir que les données sont colocalisées. Nous pouvons diffuser les tables de dimension plus petites à travers tous nos nœuds.
Pour joindre deux grandes tables de faits, nous pouvons imbriquer la table avec la granularité inférieure à l’intérieur de la table avec la granularité supérieure, par exemple une grande table ORDER_ITEM imbriquée dans la table ORDER. Les moteurs de requêtes modernes tels que Impala ou Drill nous permettent d’aplanir ces données

Cette stratégie d’imbrication des données est également utile pour les concepts douloureux de Kimball tels que les tables de pont pour représenter les relations M:N dans un modèle dimensionnel.
Hadoop et les dimensions qui changent lentement
Le stockage sur le système de fichiers Hadoop est immuable. En d’autres termes, vous pouvez seulement insérer et ajouter des enregistrements. Vous ne pouvez pas modifier les données. Si vous venez d’un environnement d’entrepôt de données relationnel, cela peut sembler un peu étrange au début. Cependant, sous le capot, les bases de données fonctionnent de manière similaire. Elles stockent toutes les modifications apportées aux données dans un journal immuable en écriture (connu sous le nom de redo log dans Oracle) avant qu’un processus ne mette à jour de manière asynchrone les données dans les fichiers de données.
Quel est l’impact de l’immuabilité sur nos modèles dimensionnels ? Vous vous souvenez peut-être du concept de dimensions à évolution lente (SCD) dans votre cours de modélisation dimensionnelle. Les SCDs préservent facultativement l’historique des modifications apportées aux attributs. Ils nous permettent de rapporter des métriques par rapport à la valeur d’un attribut à un moment donné dans le temps. Ce n’est cependant pas le comportement par défaut. Par défaut, nous mettons à jour les tables de dimension avec les dernières valeurs. Quelles sont donc nos options sur Hadoop ? N’oubliez pas ! Nous ne pouvons pas mettre à jour les données. Nous pouvons simplement faire de SCD le comportement par défaut et auditer tout changement. Si nous voulons exécuter des rapports sur les valeurs actuelles, nous pouvons créer une vue au-dessus du SCD qui ne récupère que la dernière valeur. Cela peut facilement être fait en utilisant les fonctions de fenêtrage. Alternativement, nous pouvons exécuter un service dit de compactage qui crée physiquement une version séparée de la table de dimension avec seulement les dernières valeurs.
L’évolution du stockage sur Hadoop
Ces limitations d’Hadoop ne sont pas passées inaperçues par les vendeurs des plateformes Hadoop. Dans Hive, nous avons maintenant des transactions ACID et des tables actualisables. D’après le nombre de problèmes majeurs ouverts et ma propre expérience, cette fonctionnalité ne semble pas encore prête pour la production. Cloudera a adopté une approche différente. Avec Kudu, ils ont créé un nouveau format de stockage actualisable qui ne repose pas sur HDFS mais sur le système de fichiers du système d’exploitation local. Il se débarrasse complètement des limitations d’Hadoop et est similaire à la couche de stockage traditionnelle dans un MPP en colonne. D’une manière générale, il est probablement préférable d’exécuter tous les cas d’utilisation de la BI et des tableaux de bord sur un MPP, par exemple Impala + Kudu, plutôt que sur Hadoop. Cela dit, les MPP ont leurs propres limites en matière de résilience, de concurrence et d’évolutivité. Lorsque vous rencontrez ces limites, Hadoop et son proche cousin Spark sont de bonnes options pour les charges de travail de BI. Nous couvrons toutes ces limitations dans notre cours de formation Big Data for Data Warehouse Professionals et faisons des recommandations quand utiliser un SGBDR et quand utiliser SQL sur Hadoop/Spark.
Le verdict. Les modèles dimensionnels et les schémas en étoile sont-ils obsolètes ?
Nous savons tous que Ralph Kimball a pris sa retraite. Mais ses idées et concepts de principe sont toujours valables et perdurent. Nous devons les adapter aux nouvelles technologies et aux nouveaux types de stockage, mais ils apportent toujours une valeur ajoutée.
Enseignez-moi le Big Data pour faire progresser ma carrière
Lectures complémentaires sur la modélisation dimensionnelle à l’ère du Big Data
Tom Breur : Le passé et l’avenir de la modélisation dimensionnelle
Edosa Odaro : 5 conseils radicaux pour une intégration rapide des Big Data – Le modèle anti entrepôt de données
.