Révisé : 11 décembre 2020
Les sujets disent-ils la vérité ?
La fiabilité des données autodéclarées est un talon d’Achille de la recherche par sondage. Par exemple, les sondages d’opinion indiquent que plus de 40 % des Américains vont à l’église chaque semaine. Cependant, en examinant les registres de fréquentation des églises, Hadaway et Marlar (2005) ont conclu que la fréquentation réelle était inférieure à 22 %. Dans son ouvrage fondamental « Everybody lies », Seth Stephens-Davidowitz (2017) a trouvé de nombreuses preuves montrant que la plupart des gens ne font pas ce qu’ils disent et ne disent pas ce qu’ils font. Par exemple, en réponse à des sondages, la plupart des électeurs déclarent que l’origine ethnique du candidat n’a pas d’importance. Cependant, en vérifiant les termes de recherche dans Google, Sephens-Davidowitz a découvert le contraire.Plus précisément, lorsque les utilisateurs de Google ont saisi le mot « Obama », ils ont toujoursassocié son nom à certains mots liés à la race.
Pour la recherche sur l’enseignement sur le Web, les données d’utilisation du Web peuvent être obtenues en analysant le journal d’accès de l’utilisateur, en installant des cookies ou en téléchargeant le cache. Cependant, ces options peuvent avoir une applicabilité limitée. Par exemple, le journal d’accès de l’utilisateur ne peut pas suivre les utilisateurs qui suivent des liens vers d’autres sites Web. En outre, les approches basées sur les cookies ou le cache peuvent soulever des problèmes de confidentialité. Dans ces situations, les données autodéclarées recueillies par des enquêtes sont utilisées. Cela soulève la question suivante : Quelle est la précision des données autodéclarées ? Cook et Campbell (1979) ont souligné que les sujets (a) ont tendance à déclarer ce qu’ils croient que le chercheur s’attend à voir, ou (b) à déclarer ce qui reflète positivement leurs propres capacités, connaissances, croyances ou opinions. Une autre préoccupation concernant ces données est de savoir si les sujets sont capables de se souvenir avec précision de leurs comportements passés. Les psychologues ont prévenu que la mémoire humaine est faillible (Loftus, 2016 ; Schacter, 1999). Parfois, les gens se « souviennent » d’événements qui n’ont jamais eu lieu. Ainsi, la fiabilité des données autodéclarées est ténue.Bien que les progiciels statistiques soient capables de calculer des nombres jusqu’à 16-32 décimales, cette précision n’a pas de sens si les données ne peuvent pas être exactes même au niveau des nombres entiers. Un bon nombre d’universitaires ont averti les chercheurs de la façon dont l’erreur de mesure pouvait paralyser l’analyse statistique (Blalock, 1974) et ont suggéré que de bonnes pratiques de recherche exigent l’examen de la qualité des données recueillies (Fetter,Stowe, & Owings, 1984).
Bias et variance
Les erreurs de mesure comprennent deux composantes, à savoir le biais et l’erreur variable.Le biais est une erreur systématique qui tend à pousser le score rapporté vers une extrémité extrême. Par exemple, plusieurs versions des tests de QI se révèlent biaisées à l’égard des non-Blancs. Cela signifie que les Noirs et les Hispaniques obtiennent généralement des scores inférieurs, quelle que soit leur intelligence réelle. L’erreur variable, également appelée variance, tend à être aléatoire. En d’autres termes, les scores rapportés peuvent être soit supérieurs, soit inférieurs aux scores réels (Salvucci, Walter, Conley, Fink, & Saba, 1997).
Les résultats de ces deux types d’erreurs de mesure ont des implications différentes. Par exemple, dans une étude comparant des données autodéclarées de taille et de poids avec des données mesurées directement (Hart & Tomazic, 1999),on a constaté que les sujets ont tendance à surdéclarer leur taille mais à sous-déclarer leur poids. De toute évidence, ce type de modèle d’erreur est un biais plutôt qu’une variance. Une explication possible de ce biais est que la plupart des gens veulent présenter une meilleure image physique aux autres. Cependant, si l’erreur de mesure est aléatoire, l’explication peut être plus compliquée.
On peut faire valoir que les erreurs variables, qui sont de nature aléatoire, s’annuleraient les unes les autres et ne constitueraient donc pas une menace pour l’étude. Par exemple, le premier utilisateur peut surestimer ses activités sur Internet de 10 %, mais le second utilisateur peut sous-estimer les siennes de 10 %. Dans ce cas, la moyenne peut encore être correcte. Cependant, la surestimation et la sous-estimation augmentent la variabilité de la distribution. Dans de nombreux tests paramétriques, la variabilité au sein du groupe est utilisée comme terme d’erreur. Une variabilité gonflée affecterait certainement la signification du test. Certains textes peuvent renforcer l’idée fausse ci-dessus. Par exemple, Deese (1972) dit,
La théorie statistique nous dit que la vraisemblance des observations est proportionnelle à la racine carrée de leur nombre. Plus il y a d’observations, plus il y aura d’influence aléatoire. Et la théorie statistique soutient que plus il y a d’erreurs aléatoires, plus elles sont susceptibles de s’annuler et de produire une distribution normale (p.55).
Premièrement, il est vrai que lorsque la taille de l’échantillon augmente, la variance de la distribution diminue, cela ne garantit pas que la forme de la distribution se rapprocherait de la normalité. Deuxièmement, la fiabilité (la qualité des données) devrait être liée à la mesure plutôt qu’à la détermination de la taille de l’échantillon. Une grande taille d’échantillon avec beaucoup d’erreurs de mesure,même des erreurs aléatoires, gonflerait le terme d’erreur pour les tests paramétriques.
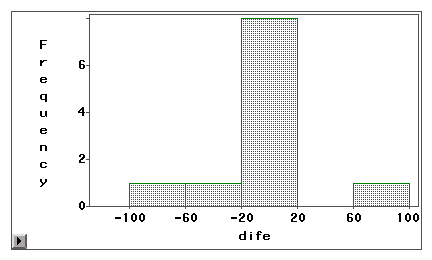
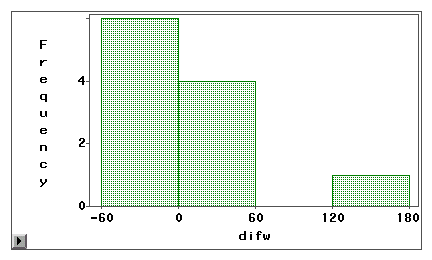
Un diagramme à tige et feuille ou un histogramme peut être utilisé pour examiner visuellement si une erreur de mesure est due à un biais systématique ou à une variance aléatoire. Dans l’exemple suivant, deux types d’accès à Internet (navigation sur le Web et courrier électronique) sont mesurés à la fois par une enquête autodéclarée et un journal de bord. Les scores de différence (mesure 1 – mesure 2) sont tracés dans les histogrammes suivants.
Le premier graphique révèle que la plupart des scores de différence sont centrés autour de zéro. La sous-déclaration et la surdéclaration apparaissent près des deux extrémités, ce qui suggère que l’erreur de mesure est une erreur aléatoire plutôt qu’un biais systématique.
Le deuxième graphique indique clairement qu’il y a un degré élevé d’erreurs de mesure car très peu de scores de différence sont centrés autour de zéro. De plus, la distribution est négativement asymétrique et l’erreur est un biais plutôt qu’une variance.
À quel point notre mémoire est-elle fiable ?
Schacter (1999) a averti que la mémoire humaine est faillible. Il existe sept défauts de notre mémoire :
- Fugacité : Diminution de l’accessibilité de l’information au fil du temps.
- Absence d’attention : Traitement inattentif ou superficiel qui contribue à la faiblesse des souvenirs.
- Blocage : L’inaccessibilité temporaire d’une information stockée dans la mémoire.
- Mauvaise attribution Attribuer un souvenir ou une idée à la mauvaise source.
- Suggestibilité : Souvenirs qui sont implantés à la suite de questions ou d’attentes suggestives.
- Biais : Distorsions rétrospectives et influences inconscientes qui sont liées aux connaissances et aux croyances actuelles.
- Persistance : Souvenirs pathologiques – informations ou événements que nous ne pouvons pas oublier, même si nous souhaiterions le faire.
 |
« Je n’ai aucun souvenir de ceux-ci. Je ne me souviens pas d’avoir signé le document pourWhitewater. Je ne me souviens pas pourquoi le document a disparu mais est réapparu plus tard. Je ne me souviens de rien. » « Je me souviens d’avoir atterri (en Bosnie) sous le feu de snipers. Il était censé y avoir une sorte de cérémonie d’accueil à l’aéroport, mais au lieu de cela, nous avons simplement couru la tête baissée pour monter dans les véhicules afin de rejoindre notrebase. » Pendant l’enquête sur l’envoi d’informations classifiées via un serveur de messagerie personnel, Clinton a déclaré au FBI qu’elle ne pouvait pas « se rappeler » ou « se souvenir » de quoi que ce soit 39 fois. Caution : Un nouveau virus informatique nommé « Clinton » est découvert. Si l’ordinateur est infecté, il affichera fréquemment ce message ‘out of memory’, même s’il possède uneRAM adéquate. |
| Q : « Si Vernon Jordon nous a dit que vous avez une mémoire extraordinaire, l’une des plus grandes mémoires qu’il ait jamais vues chez un politicien, est-ce que ce serait quelque chose que vous voudriez contester ? »
A : « J’ai effectivement une bonne mémoire…Mais je ne me souviens pas si j’étais seul avec Monica Lewinsky ou non. Comment pourrais-je garder la trace de tant de femmes dans ma vie ? » Q : Pourquoi Clinton a-t-il recommandé Lewinsky pour un emploi chez Revlon ? A : Il savait qu’elle serait bonne pour inventer des choses. |
 |
Il est important de noter que parfois la fiabilité de notre mémoire est liée à la désirabilité du résultat. Par exemple, lorsqu’un chercheur en médecine tente de recueillir des données pertinentes auprès de mères dont les bébés sont en bonne santé et de mères dont les enfants sont malformés, les données des secondes sont généralement plus précises que celles des premières. Cela s’explique par le fait que les mères de bébés malformés ont soigneusement passé en revue toutes les maladies survenues pendant la grossesse, tous les médicaments pris, tous les détails directement ou indirectement liés à la tragédie pour tenter de trouver une explication. Au contraire, les mères de bébés en bonne santé ne prêtent pas beaucoup d’attention aux informations précédentes (Aschengrau & SeageIII, 2008). Le gonflement de la moyenne générale est un autre exemple de la façon dont la désirabilité affecte la précision de la mémoire et l’intégrité des données. Dans certaines situations, il existe une différence entre les sexes dans l’inflation de la moyenne. Une étude menée par Caskie etal. (2014) a révélé que dans le groupe des étudiants de premier cycle ayant une faible moyenne, les femmes étaient plus susceptibles de déclarer une moyenne supérieure à la réalité que les hommes.
Pour contrer le problème des erreurs de mémoire, certains chercheurs ont suggéré de recueillir des données liées à la pensée ou au sentiment momentané du participant, plutôt que de lui demander de se rappeler des événements lointains (Csikszentmihalyi & Larson, 1987 ; Finnigan & Vazire,2018). Les exemples suivants sont des éléments d’enquête du Programme international pour le suivi des acquis des élèves 2018 : » Avez-vous été traité avec respect toute la journée d’hier ? « . « Avez-vous beaucoup souri ou ri hier ? » « Avez-vous appris ou fait quelque chose d’intéressant hier ? ». (Organisation de coopération et de développement économiques, 2017). Cependant, la réponse dépend de ce qui est arrivé au participant à ce moment précis, ce qui peut ne pas être typique. Plus précisément, même si le répondant n’a pas beaucoup souri ou ri hier, cela n’implique pas nécessairement qu’il est toujours malheureux.
Que faire ?
Certains chercheurs rejettent l’utilisation des données autodéclarées en raison de leur qualité supposée médiocre. Par exemple, lorsqu’un groupe de chercheurs a cherché à savoir si une religiosité élevée conduisait à une moindre adhésion aux directives de mise à l’abri aux États-Unis pendant la pandémie de COVID19, ils ont utilisé le nombre de congrégations pour 10 000 résidents comme mesure approximative de la religiosité de la région, au lieu de la religiosité autodéclarée, qui a tendance à refléter la désirabilité sociale (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Cependant, Chan (2009) a fait valoir que la soi-disant mauvaise qualité des données autodéclarées n’est rien de plus qu’une légende urbaine. Poussés par la désirabilité sociale, les répondants pourraient fournir aux chercheurs des données inexactes à certaines occasions, mais cela ne se produit pas tout le temps. Par exemple, il est peu probable que les répondants mentent sur leurs données démographiques, telles que le sexe et l’origine ethnique. Deuxièmement, s’il est vrai que les répondants ont tendance à truquer leurs réponses dans les études expérimentales, ce problème est moins grave dans les mesures utilisées dans les études de terrain et les milieux naturels. En outre, il existe de nombreuses mesures autodéclarées bien établies de différentes constructions psychologiques, qui ont obtenu des preuves de validité de construction par validation convergente et discriminante. Par exemple, les traits de personnalité des Big Five, la personnalité proactive, la disposition à l’affectivité, l’auto-efficacité, l’orientation des objectifs, le soutien organisationnel perçu, et bien d’autres.Dans le domaine de l’épidémiologie, Khoury, James et Erickson (1994) ont affirmé que l’effet du biais de rappel est surévalué. Malgré le risque d’inexactitude des données, il est impossible pour le chercheur de suivre chaque sujet avec un caméscope et d’enregistrer tout ce qu’il fait. Malgré le risque d’inexactitude des données, il est impossible pour le chercheur de suivre chaque sujet avec un caméscope et d’enregistrer tous ses faits et gestes. Les résultats seraient alors comparés au résultat des données autodéclarées par tous les sujets pour une estimation de l’erreur de mesure.Par exemple,
- Lorsque le journal d’accès de l’utilisateur est à la disposition du chercheur, il peut demander aux sujets de signaler la fréquence de leur accès au serveur web.Les sujets ne doivent pas être informés que leurs activités sur Internet ont été enregistrées par le webmaster car cela peut affecter le comportement des participants.
- Le chercheur peut demander à un sous-ensemble d’utilisateurs de tenir un journal de bord de leurs activités Internet pendant un mois. Ensuite, les mêmes utilisateurs sont invités à remplir une enquête concernant leur utilisation du web.
Quelqu’un pourrait arguer que l’approche du journal de bord est trop exigeante. En effet, dans de nombreuses études de recherche scientifique, on demande aux sujets bien plus que cela. Par exemple, lorsque des scientifiques ont étudié comment le sommeil profond pendant un voyage spatial à longue distance affecterait la santé humaine, on a demandé aux participants de rester couchés pendant un mois. Dans une étude portant sur l’influence d’un environnement fermé sur la psychologie humaine pendant un voyage dans l’espace, les sujets ont également été enfermés individuellement dans une pièce pendant un mois. La recherche de vérités scientifiques coûte cher.
Après avoir recueilli différentes sources de données, on peut analyser l’écart entre le journal et les données déclarées par les sujets pour estimer la fiabilité des données. À première vue, cette approche ressemble à une fiabilité test-retest, mais elle ne l’est pas. Premièrement, dans la fiabilité test-retest, l’instrument utilisé dans deux ou plusieurs situations doit être le même. Deuxièmement, lorsque la fiabilité test-retest est faible, la source des erreurs se trouve dans l’instrument. Cependant, lorsque la source des erreurs est externe à l’instrument, comme les erreurs humaines, la fiabilité inter-évaluateurs est plus appropriée.
La procédure suggérée ci-dessus peut être conceptualisée comme une mesure de la fiabilité inter-données, qui ressemble à celle de la fiabilité inter-évaluateurs et des mesures répétées. Il existe quatre façons d’estimer la fiabilité inter-évaluateurs, à savoir le coefficient Kappa, l’indice d’incohérence, l’analyse de variance à mesures répétées et l’analyse de régression. La section suivante décrit comment ces mesures de fiabilité inter-évaluateurs peuvent être utilisées comme mesures de fiabilité inter-données.
Coefficient Kappa
Dans la recherche psychologique et éducative, il n’est pas rare d’employer deux évaluateurs ou plus dans le processus de mesure lorsque l’évaluation implique des jugements subjectifs (par exemple, la notation de dissertations). La fiabilité inter-évaluateurs, qui est mesurée par le coefficient Kappa, est utilisée pour indiquer la fiabilité des données. Par exemple, les performances des participants sont notées par deux ou plusieurs évaluateurs comme « maître » ou « non maître » (1 ou 0). Ainsi, cette mesure est généralement calculée dans des procédures d’analyse de données catégorielles telles que PROC FREQ dans SAS, la « mesure de l’accord » dans SPSS, ou un calculateur Kappa en ligne (Lowry, 2016). L’image ci-dessous est une capture d’écrandu calculateur en ligne de Vassarstats.
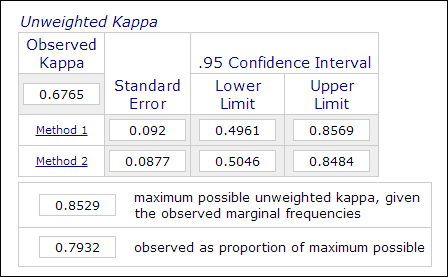
Il est important de noter que même si 60 % de deux ensembles de données concordent entre eux, cela ne signifie pas que les mesures sont fiables.Comme le résultat est dichotomique, il y a 50 % de chances que les deux mesures concordent. Le coefficient Kappa tient compte de ce facteur et exige un degré de concordance plus élevé pour atteindre la cohérence.
Dans le contexte de l’enseignement sur le Web, chaque catégorie d’utilisation autodéclarée du site Web peut être recodée comme une variable binaire. Par exemple, lorsque la première question est » à quelle fréquence utilisez-vous telnet ? « , les réponses catégoriques possibles sont » a : tous les jours « , » b : trois à cinq fois par semaine « , » c : trois à cinq fois par mois « , » d : rarement » et » e : jamais « . Dans ce cas, les cinq catégories peuvent être recodées en cinq variables : Q1A, Q1B, Q1C, Q1D et Q1E. Ensuite, toutes ces variables binaires peuvent être ajoutées pour former un tableau R X 2, comme le montre le tableau suivant. Avec cette structure de données, les réponses peuvent être codées comme « 1 » ou « 0 », ce qui permet de mesurer l’accord de classification. L’accord peut être calculé en utilisant le coefficient de Kappa et ainsi la fiabilité des données peut être estimée.
Sujets Données du journal de bord Données d’autodéclaration .rapport de données Sujet 1 1 1 Sujet 2 0 0 Sujet 3 1 0 Sujet 4 0 1 Index d’incohérence
Une autre façon de calculer les données catégorielles susmentionnées est l’indice d’incohérence (IOI). Dans l’exemple ci-dessus, étant donné qu’il y a deux mesures (données logarithmiques et données autodéclarées) et cinq options dans la réponse, un tableau 4 X 4 est formé. La première étape pour calculer l’IOI consiste à diviser le tableau RXC en plusieurs sous-tableaux 2X2. Par exemple, la dernière option « jamais » est traitée comme une catégorie et toutes les autres sont regroupées dans une autre catégorie comme « pas jamais », comme le montre le tableau suivant.
Données auto.données déclarées Log Jamais Pas jamais Total Jamais a .
b a+b Non jamais c d c+d Total a+c b+d n=Somme(a-d) Le pourcentage d’IOI est calculé par la formule suivante :
IOI% = 100*(b+c)/ où p = (a+c)/n
Après le calcul de l’IOI pour chaque sous-tableau 2X2, une moyenne de tous les indices est utilisée comme indicateur de l’incohérence de la mesure. Lecritère permettant de juger si les données sont cohérentes est le suivant :
- Un IOI inférieur à 20 est une variance faible
- Un IOI compris entre 20 et 50 est une variance modérée
- Un IOI supérieur à 50 est une variance élevée
La fiabilité des données est exprimée par cette équation : r = 1 – IOI
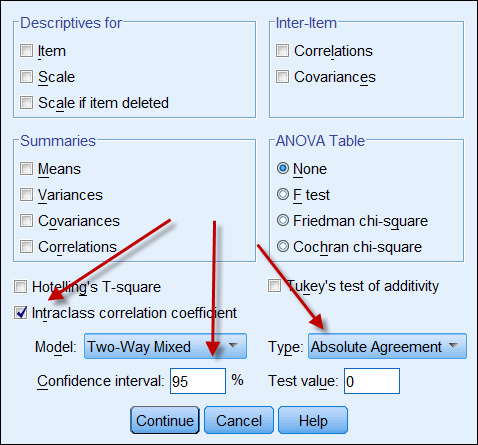
Coefficient de corrélation intraclasse
Si les deux sources de données produisent des données continues, alors on peut calculer le coefficient de corrélation intraclasse pour indiquer la fiabilité des données. Voici une capture d’écran des options ICC de SPSS. Dans Type, il y a deux options : « cohérence » et « accord absolu ». Si l’option « cohérence » est choisie, même si un ensemble de chiffres a une cohérence élevée (par exemple 9, 8, 9, 8, 7…) et l’autre une cohérence faible (par exemple 4, 3, 4, 3, 2…), leur forte corrélation implique à tort que les données sont alignées les unes avec les autres. Par conséquent, il est conseillé de choisir « accord absolu ».
Mesures répétées
La mesure de la fiabilité inter-données peut également être conceptualisée et procédurée comme une ANOVA à mesures répétées. Dans une ANOVA à mesures répétées, les mesures sont données aux mêmes sujets plusieurs fois, comme le prétest, le mi-parcours et le post-test. Dans ce contexte, les sujets sont également mesurés à plusieurs reprises par le journal des utilisateurs du Web, le journal de bord et l’enquête autodéclarée. Voici le code SAS pour une ANOVA à mesures répétées :
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
Dans le programme ci-dessus, le nombre de sites Web visités par neuf volontaires sont enregistrés dans le journal des accès des utilisateurs, le journal personnel et l’enquête autodéclarée. Les utilisateurs sont traités comme un facteur inter-sujet tandis que les trois mesures sont considérées comme un facteur inter-mesure. Voici un résultat condensé:
Source de variation DF Moyen carré Entre-sujet (utilisateur) 8 10442.50 Entre-mesure (temps) 2 488,93 Résiduel 16 454.80 Sur la base des informations ci-dessus, le coefficient de fiabilité peut être calculé à l’aide de cette formule (Fisher, 1946 ; Horst, 1949) :
r = MSentre-mesure – MSrésiduel —————————————————-.———- MSbetween-measure + (dfbetween-people X MSresidual) Plongeons le nombre dans la formule :
r = 488.93 – 454.80 ————————————— 488.93 + ( 8 X 454.80) La fiabilité est d’environ .0008, ce qui est extrêmement faible. Par conséquent, nous pouvons rentrer chez nous et oublier ces données. Heureusement, ce n’est qu’un ensemble de données hypothétiques. Mais, que se passe-t-il si c’est un ensemble de données réel ? Vous devez être assez dur pour abandonner des données médiocres plutôt que de publier certains résultats qui ne sont absolument pas fiables.
Analyse corrélationnelle et de régression
L’analyse corrélationnelle, qui utilise le coefficient du moment produit de Pearson, est très simple et particulièrement utile lorsque les échelles de deux mesures ne sont pas les mêmes. Par exemple, le journal du serveur Web peut suivre le nombre d’accès aux pages alors que les données autodéclarées sont à l’échelle du Likert (par exemple, à quelle fréquence naviguez-vous sur Internet ? 5=très souvent, 4=souvent, 3=parfois, 2=rarement, 5=jamais). Dans ce cas, les scores autodéclarés peuvent être utilisés comme un prédicteur pour régresser contre l’accès aux pages.
Une approche similaire est l’analyse de régression, dans laquelle un ensemble de scores (par exemple, les données d’enquête) est traité comme le prédicteur tandis qu’un autre ensemble de scores (par exemple, le journal quotidien de l’utilisateur) est considéré comme la variable dépendante. Si plus de deux mesures sont employées, un modèle de régression multiple peut être appliqué, c’est-à-dire que celle qui donne un résultat plus précis (par exemple le journal des accès des utilisateurs Web) est considérée comme la variable dépendante et toutes les autres mesures (par exemple le journal quotidien des utilisateurs, les données d’enquête) sont traitées comme des variables indépendantes.
Référence
- Aschengrau, A., & Seage III, G. (2008). Essentiels de l’épidémiologie en santé publique. Boston, MA : Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) La mesure dans les sciences sociales : Théories et stratégies. Chicago, Illinois : Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Exactitude de l’autodéclaration de la moyenne générale des collèges : Gender-moderateddifferences by achievement level and academic self-efficacy. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). So why ask me ? Les données d’auto-évaluation sont-elles vraiment si mauvaises ? Dans Charles E. Lance et Robert J. Vandenberg (Eds.), Statistical and methodological myths and urban legends : Doctrine, vérité et fable dans les sciences organisationnelles et sociales (pp309-335). New York, NY : Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-expérimentation : Questions de conception et d’analyse. Boston, MA : Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validité et fiabilité de la méthode d’échantillonnage par l’expérience. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). La psychologie en tant que science et art. New York, NY : Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, 10 août). La religion et la réactivité aux directives de COVID-19mitigation. American Psychologist. Publication anticipée en ligne. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). L’école secondaire et au-delà. Une étude longitudinale nationale pour les années 1980, qualité des réponses des lycéens aux items du questionnaire. (NCES 84-216).Washington, D. C. : Département de l’éducation des États-Unis. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). La validité incrémentale des auto-évaluations de l’état moyen par rapport aux auto-évaluations globales de la personnalité. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Méthodes statistiques pour les chercheurs (10e éd.). Edinburgh, UK : Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Combien d’Américains participent au culte chaque semaine ? Une approche alternative à la mesure ? Journal for the Scientific Study of Religion, 44, 307-322. DOI : 10.1111/j.1468-5906.2005.00288.x
- Hart, W. ; & Tomazic, T. (août 1999). Comparaison des distributions de percentiles pour les mesures anthropométriques entre trois ensembles de données. Document présenté au Annual Joint Statistical Meeting, Baltimore, MD.
- Horst, P. (1949). Une expression généralisée pour la fiabilité des mesures. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). On theuse of affected controls to address recall bias in case-control studiesof birth defects. Teratology, 49, 273-281.
- Loftus, E. (2016, avril). La fiction de la mémoire. Document présenté à la convention de la Western Psychological Association. Long Beach, CA.
- Lowry, R. (2016). Kappa comme mesure de la concordance dans le tri catégoriel. Récupéré de http://vassarstats.net/kappa.html
- Organisation de coopération et de développement économiques. (2017). Questionnaire sur le bien-être pour PISA 2018. Paris : Auteur. Consulté le https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Les sept péchés de la mémoire : Insights from psychology and cognitive neuroscience. Psychologie américaine, 54, 182-203.
- Salvucci, S. ; Walter, E., Conley, V ; Fink, S ; & Saba, M. (1997). Études sur les erreurs de mesure au National Center for Education Statistics. Washington D. C. : U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Tout le monde ment : Big data, new data, and what the Internet can tell us about who we really are. New York, NY : Dey Street Books.
 Remonter au menu principal
Remonter au menu principal Autres coursMoteur de recherche
|

Contactez-moi
|