Méthode 1, mauvaise : ORDER BY NEWID()
Facile à écrire, mais il fonctionne comme une ordure chaude, chaude parce qu’il scanne l’index clusterisé entier, en calculant NEWID() sur chaque ligne :
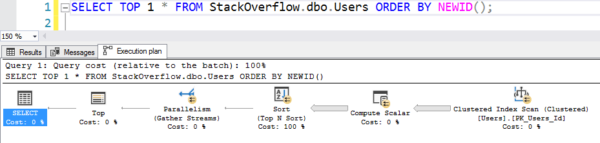
Le plan avec le scan
Cela a pris 6 secondes sur ma machine, allant en parallèle sur plusieurs threads, utilisant des dizaines de secondes de CPU pour tout ce calcul et ce tri. (Et la table Users ne fait même pas 1 Go.)
Méthode 2, meilleure mais étrange : TABLESAMPLE
Cette méthode est sortie en 2005, et a une tonne de gotchas. Il s’agit en quelque sorte de choisir une page aléatoire, puis de retourner un ensemble de lignes de cette page. La première ligne est en quelque sorte aléatoire, mais les autres ne le sont pas.
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 POURCENT) ;
|
Le plan semble faire un balayage de table, mais il ne fait que 7 lectures logiques :
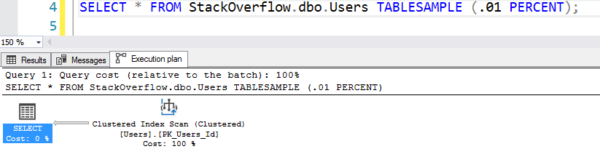
Le plan avec le faux balayage
Mais voici les résultats – vous pouvez voir qu’il saute à une page 8K aléatoire et commence à lire les lignes dans l’ordre. Ce ne sont pas vraiment des lignes aléatoires.
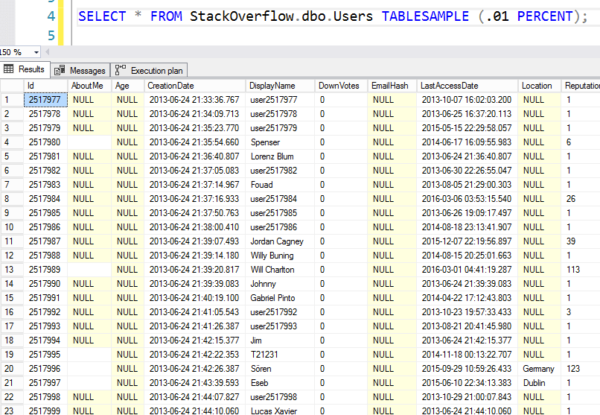
Aléatoire comme les numéros de loterie de la mafia
Vous pouvez utiliser la taille d’échantillon ROWS à la place, mais elle a des résultats plutôt étranges. Par exemple, dans le tableau des utilisateurs de Stack Overflow, lorsque j’ai dit TABLESAMPLE (50 ROWS), j’ai en fait obtenu 75 lignes en retour. C’est parce que SQL Server convertit votre taille de ligne en pourcentage à la place.
Méthode 3, la meilleure mais qui nécessite du code : Clé primaire aléatoire
Ayez le champ d’ID le plus élevé dans la table, générez un nombre aléatoire et recherchez cet ID. Ici, nous trions par l’ID parce que nous voulons trouver l’enregistrement supérieur qui existe réellement (alors qu’un nombre aléatoire pourrait avoir été supprimé.) Assez rapide, mais n’est bon que pour une seule ligne aléatoire. Si vous vouliez 10 lignes, vous devriez appeler un code comme celui-ci 10 fois (ou générer 10 numéros aléatoires et utiliser une clause IN.)
Le plan d’exécution montre un balayage d’index clusterisé, mais il ne saisit qu’une seule ligne – nous parlons seulement de 6 lectures logiques pour tout ce que vous voyez ici, et il se termine presque instantanément :

Le plan qui peut
Il y a un hic : si l’Id a des nombres négatifs, cela ne fonctionnera pas comme prévu. (Par exemple, disons que vous commencez votre champ d’identité à -1 et passez à -1, en vous dirigeant toujours vers le bas, comme ma morale.)
Méthode 4, OFFSET-FETCH (2012+)
Daniel Hutmacher a ajouté celui-ci dans les commentaires :
Et a dit : « Mais il ne fonctionne correctement qu’avec un index clusterisé. Je suppose que c’est parce qu’il va scanner pour (@rows) les lignes dans un tas au lieu de faire une recherche d’index. »
Piste bonus #1 : Regardez-nous discuter de ceci
Vous vous êtes déjà demandé ce que c’est que d’être dans le salon de discussion de notre entreprise ? Cette discussion Slack de 10 minutes vous en donnera une assez bonne idée :
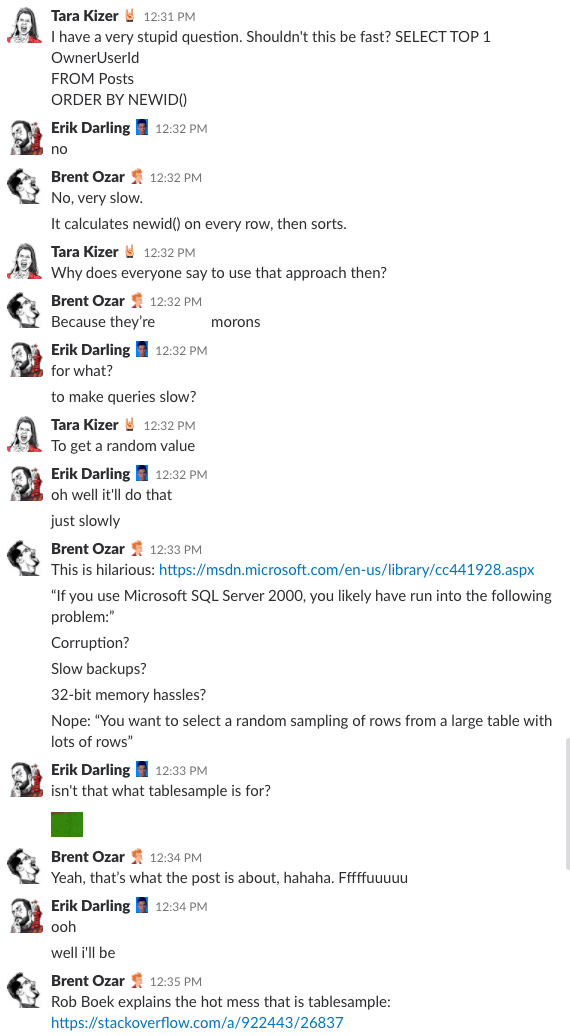
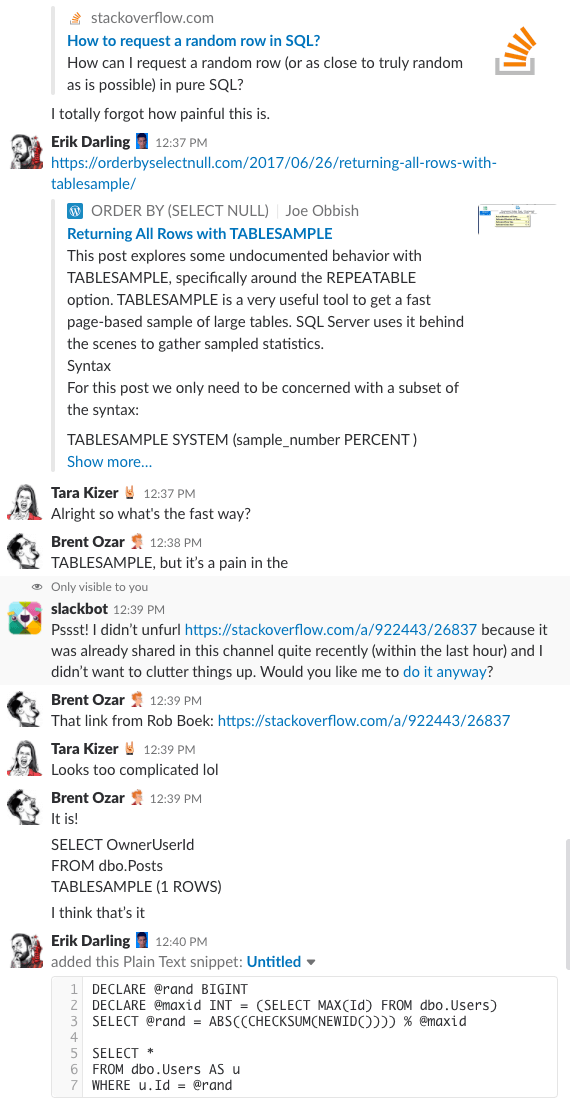
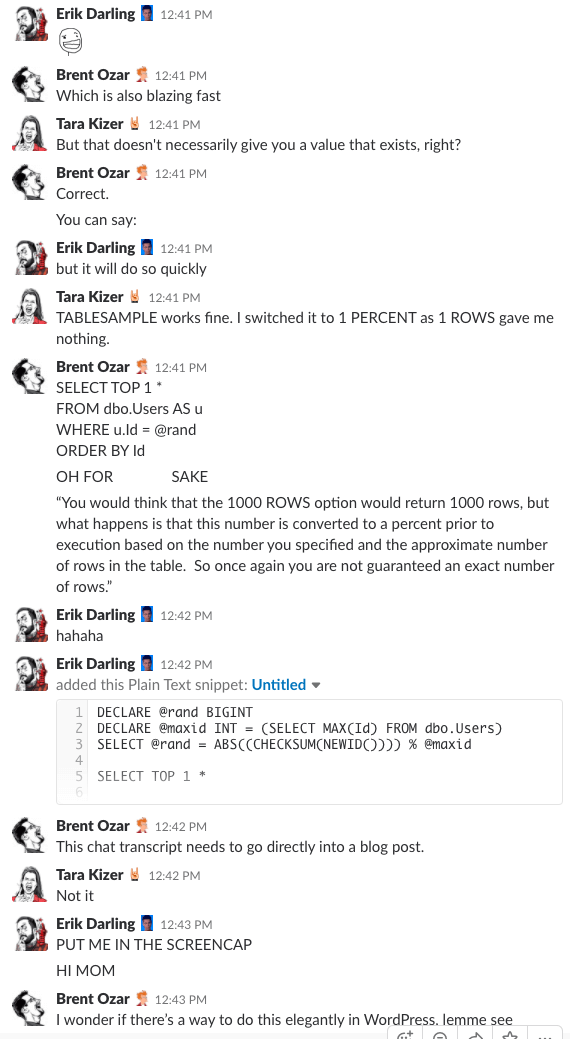
Alerte spoiler : il n’y en avait pas. J’ai juste fait des captures d’écran.
Piste bonus n°2 : Mitch Wheat creuse plus profondément
Vous voulez une analyse approfondie du caractère aléatoire de plusieurs techniques différentes ? Mitch Wheat plonge vraiment en profondeur, avec des graphiques à l’appui !
.