Vous vous demandez ce que sont les schémas Postgresql, pourquoi ils sont importants et comment vous pouvez utiliser les schémas pour rendre vos implémentations de bases de données plus robustes et plus faciles à maintenir ? Cet article présentera les bases des schémas dans Postgresql et vous montrera comment les créer avec quelques exemples de base. Les prochains articles se plongeront dans des exemples de sécurisation et d’utilisation des schémas pour des applications réelles.
Pour commencer, afin de dissiper toute confusion terminologique potentielle, comprenons que dans le monde Postgresql, le terme « schéma » est peut-être un peu malheureusement surchargé. Dans le contexte plus large des systèmes de gestion de bases de données relationnelles (SGBDR), le terme « schéma » peut être compris comme faisant référence à la conception logique ou physique globale de la base de données, c’est-à-dire la définition de toutes les tables, colonnes, vues et autres objets qui constituent la définition de la base de données. Dans ce contexte plus large, un schéma pourrait être exprimé dans un diagramme entité-relation (ER) ou un script d’instructions de langage de définition de données (DDL) utilisé pour instancier la base de données de l’application.
Dans le monde Postgresql, le terme « schéma » pourrait être mieux compris comme un « espace de noms ». En fait, dans les tables du système Postgresql, les schémas sont enregistrés dans des colonnes de table appelées « espace de noms », ce qui, IMHO, est une terminologie plus précise. En pratique, chaque fois que je vois « schéma » dans le contexte de Postgresql, je le réinterprète silencieusement en disant « espace de nom ».
Mais vous pouvez demander : « Qu’est-ce qu’un espace de nom ? ». En général, un espace de noms est un moyen assez flexible d’organiser et d’identifier des informations par leur nom. Par exemple, imaginons deux ménages voisins, les Smith, Alice et Bob, et les Jones, Bob et Cathy (cf. figure 1). Si nous n’utilisions que les prénoms, il pourrait être difficile de savoir de quelle personne nous parlons lorsque nous parlons de Bob. Mais en ajoutant le nom de famille, Smith ou Jones, nous identifions de façon unique la personne dont nous parlons.
Souvent, les espaces de noms sont organisés en une hiérarchie imbriquée. Cela permet de classer efficacement de grandes quantités d’informations dans une structure très fine, comme, par exemple, le système de noms de domaine Internet. Au niveau le plus élevé, « .com », « .net », « .org », « .edu », etc. définissent de vastes espaces de noms au sein desquels sont enregistrés les noms d’entités spécifiques, de sorte que, par exemple, « severalnines.com » et « postgresql.org » sont définis de manière unique. Mais sous chacun d’eux, il y a un certain nombre de sous-domaines communs tels que « www », « mail » et « ftp », par exemple, qui, seuls, sont duplicatifs, mais au sein des espaces de noms respectifs sont uniques.
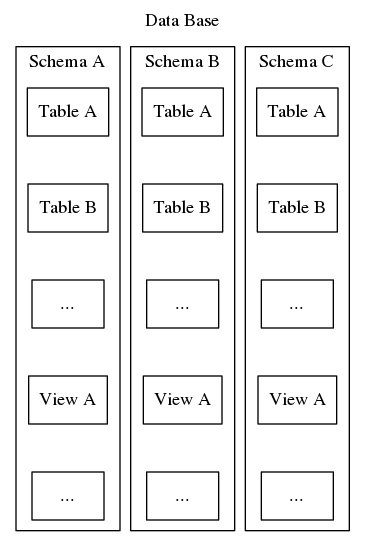
Les schémas Postgresql servent ce même objectif d’organisation et d’identification, cependant, contrairement au deuxième exemple ci-dessus, les schémas Postgresql ne peuvent pas être imbriqués dans une hiérarchie. Bien qu’une base de données puisse contenir de nombreux schémas, il n’y a jamais qu’un seul niveau et donc, dans une base de données, les noms de schémas doivent être uniques. En outre, chaque base de données doit comprendre au moins un schéma. Chaque fois qu’une nouvelle base de données est instanciée, un schéma par défaut nommé « public » est créé. Le contenu d’un schéma comprend tous les autres objets de la base de données tels que les tables, les vues, les procédures stockées, les déclencheurs, etc. Pour visualiser, reportez-vous à la figure 2, qui représente un emboîtement de type poupée matryoshka montrant où les schémas s’intègrent dans la structure d’une base de données Postgresql.
En plus de simplement organiser les objets de la base de données en groupes logiques pour les rendre plus faciles à gérer, les schémas ont pour objectif pratique d’éviter les collisions de noms. Un paradigme opérationnel consiste à définir un schéma pour chaque utilisateur de la base de données afin de fournir un certain degré d’isolation, un espace où les utilisateurs peuvent définir leurs propres tables et vues sans interférer les uns avec les autres. Une autre approche consiste à installer des outils tiers ou des extensions de base de données dans des schémas individuels afin de maintenir logiquement ensemble tous les composants liés. Un article ultérieur de cette série détaillera une nouvelle approche de la conception d’applications robustes, employant des schémas comme moyen d’indirection pour limiter l’exposition de la conception physique de la base de données et présenter plutôt une interface utilisateur qui résout les clés synthétiques et facilite la maintenance à long terme et la gestion de la configuration à mesure que les exigences du système évoluent.
Faisons du code !
La commande la plus simple pour créer un schéma dans une base de données est
CREATE SCHEMA hollywood;Cette commande nécessite des privilèges de création dans la base de données, et le schéma nouvellement créé « hollywood » sera la propriété de l’utilisateur invoquant la commande. Une invocation plus complexe peut inclure des éléments optionnels spécifiant un propriétaire différent, et peut même inclure des instructions DDL instanciant des objets de base de données dans le schéma, le tout en une seule commande !
Le format général est
CREATE SCHEMA schemaname ]où « username » est celui qui sera propriétaire du schéma et « schema_element » peut être une de certaines commandes DDL (se référer à la documentation Postgresql pour les spécificités). Les privilèges de superutilisateur sont nécessaires pour utiliser l’option AUTHORIZATION.
Donc, par exemple, pour créer un schéma nommé « hollywood » contenant une table nommée « films » et une vue nommée « winners » en une seule commande, vous pourriez faire
CREATE SCHEMA hollywood CREATE TABLE films (title text, release date, awards text) CREATE VIEW winners AS SELECT title, release FROM films WHERE awards IS NOT NULL;Des objets de base de données supplémentaires peuvent être créés directement par la suite, par exemple une table supplémentaire serait ajoutée au schéma avec
CREATE TABLE hollywood.actors (name text, dob date, gender text);Notez dans l’exemple ci-dessus le préfixe du nom de la table avec le nom du schéma. Ceci est nécessaire parce que par défaut, c’est-à-dire sans spécification explicite du schéma, les nouveaux objets de base de données sont créés dans ce qui est le schéma actuel, que nous couvrirons ensuite.
Rappellez-vous comment dans le premier exemple d’espace de nom ci-dessus, nous avions deux personnes nommées Bob, et nous avons décrit comment les déconfondre ou les distinguer en incluant le nom de famille. Mais au sein de chacun des ménages Smith et Jones séparément, chaque famille comprend « Bob » pour se référer à celui qui va avec ce ménage particulier. Ainsi, par exemple, dans le contexte de chaque ménage respectif, Alice n’a pas besoin de s’adresser à son mari en tant que Bob Jones, et Cathy n’a pas besoin de se référer à son mari en tant que Bob Smith : elles peuvent chacune simplement dire « Bob ».
Le schéma courant de Postgresql est un peu comme le ménage dans l’exemple ci-dessus. Les objets du schéma courant peuvent être référencés sans qualification, mais la référence à des objets au nom similaire dans d’autres schémas nécessite de qualifier le nom en préfixant le nom du schéma comme ci-dessus.
Le schéma courant est dérivé du paramètre de configuration « search_path ». Ce paramètre stocke une liste de noms de schémas séparés par des virgules et peut être examiné avec la commande
SHOW search_path;ou défini à une nouvelle valeur avec
SET search_path TO schema ;Le premier nom de schéma dans la liste est le « schéma actuel » et c’est là que les nouveaux objets sont créés s’ils sont spécifiés sans qualification de nom de schéma.
La liste de noms de schémas séparés par des virgules sert également à déterminer l’ordre de recherche par lequel le système localise les objets nommés non qualifiés existants. Par exemple, pour en revenir au quartier de Smith et Jones, une livraison de colis adressée uniquement à « Bob » nécessiterait de visiter chaque foyer jusqu’à ce que le premier résident nommé « Bob » soit trouvé. Notez que ce n’est peut-être pas le destinataire prévu. La même logique s’applique à Postgresql. Le système recherche les tables, les vues et d’autres objets dans les schémas dans l’ordre du chemin de recherche (search_path), puis le premier objet correspondant au nom trouvé est utilisé. Les objets nommés qualifiés de schéma sont utilisés directement sans référence au search_path.
Dans la configuration par défaut, l’interrogation de la variable de configuration search_path révèle cette valeur
SHOW search_path; Search_path-------------- "$user", publicLe système interprète la première valeur indiquée ci-dessus comme le nom de l’utilisateur actuellement connecté et prend en compte le cas d’utilisation mentionné précédemment où chaque utilisateur se voit attribuer un schéma nommé par l’utilisateur pour un espace de travail distinct des autres utilisateurs. Si aucun schéma de ce type portant un nom d’utilisateur n’a été créé, cette entrée est ignorée et le schéma « public » devient le schéma actuel où les nouveaux objets sont créés.
Donc, pour revenir à notre exemple précédent de création de la table « hollywood.actors », si nous n’avions pas qualifié le nom de la table avec le nom du schéma, alors la table aurait été créée dans le schéma public. Si nous prévoyons de créer tous les objets dans un schéma spécifique, alors il pourrait être pratique de définir la variable search_path comme
SET search_path TO hollywood,public;facilitant le raccourci de taper des noms non qualifiés pour créer ou accéder aux objets de la base de données.
Il existe également une fonction d’information système qui renvoie le schéma actuel avec une requête
select current_schema();En cas de fat-fingering de l’orthographe, le propriétaire d’un schéma peut changer le nom, à condition que l’utilisateur ait également des privilèges de création pour la base de données, avec la
ALTER SCHEMA old_name RENAME TO new_name;Et enfin, pour supprimer un schéma d’une base de données, il existe une commande drop
DROP SCHEMA schema_name;La commande DROP échouera si le schéma contient des objets, ils doivent donc être supprimés en premier, ou vous pouvez éventuellement supprimer récursivement un schéma tout son contenu avec l’option CASCADE
DROP SCHEMA schema_name CASCADE;Ces bases vous permettront de commencer à comprendre les schémas !