L’image ci-dessus pourrait vous avoir donné une idée suffisante de ce dont il s’agit dans ce post.
Ce post couvre certains des algorithmes de correspondance de chaînes de caractères flous importants(pas exactement égaux mais en gros les mêmes chaînes, disons RajKumar & Raj Kumar) qui comprennent :
Distance de Hamming
Distance de Levenstein
Distance de Damerau Levenstein
Correspondance de chaînes basée sur N-Gram
Arbre BK
Algorithme Bitap
Mais nous devons d’abord savoir pourquoi la correspondance floue est importante en considérant un scénario du monde réel. Chaque fois qu’un utilisateur est autorisé à entrer des données, les choses peuvent devenir vraiment désordonnées comme dans le cas ci-dessous ! !!
Let,
- Votre nom est ‘Saurav Kumar Agarwal’.
- Vous avez reçu une carte de bibliothèque (avec un identifiant unique bien sûr) qui est valable pour chaque membre de votre famille.
- Vous allez à une bibliothèque pour délivrer quelques livres chaque semaine. Mais pour cela, vous devez d’abord faire une entrée dans un registre à l’entrée de la bibliothèque où vous entrez votre ID & nom.
Maintenant, les autorités de la bibliothèque décident d’analyser les données dans ce registre de la bibliothèque pour avoir une idée des lecteurs uniques qui visitent chaque mois. Maintenant, cela peut être fait pour de nombreuses raisons (comme aller pour l’expansion du terrain ou non, doit-on augmenter le nombre de livres ? etc).
Ils ont prévu de le faire en comptant (noms uniques, ID de la bibliothèque) les paires enregistrées pour un mois. Donc si nous avons
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Cela devrait nous donner 4 lecteurs uniques.
So far so good
Ils ont estimé ce nombre à environ 10k-10.5k mais les chiffres ont grimpé jusqu’à ~50k après l’analyse par la correspondance exacte des chaînes de noms.
wooohhh!
Pretty mauvaise estimation je dois dire !
Ou ils ont manqué un truc ici?
Après une analyse plus approfondie, un problème majeur est apparu. Rappelez-vous votre nom, « Saurav Agarwal ». Ils ont trouvé des entrées menant à 5 utilisateurs différents à travers votre ID de bibliothèque familiale :
- Saurav K Aggrawal (remarquez le double ‘g’, ‘ra-ar’, Kumar devient K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Il existe quelques ambiguïtés car les autorités de la bibliothèque ne savent pas
- Combien de personnes de votre famille fréquentent la bibliothèque ? si ces 5 noms représentent un seul lecteur, 2 ou 3 lecteurs différents. Appelez cela un problème non supervisé où nous avons une chaîne représentant des noms non standardisés mais leurs noms standardisés ne sont pas connus (c’est-à-dire Saurav Agarwal : Saurav Kumar Agarwal n’est pas connu)
- Doivent-ils tous fusionner en ‘Saurav Kumar Agarwal’ ? ne peut pas dire comme SK Agarwal peut être Shivam Kumar Agarwal (disons le nom de votre Père). En outre, le seul Agarwal peut être n’importe qui de la famille.
Les 2 derniers cas (SK Agarwal & Agarwal) nécessiteraient des informations supplémentaires (comme le sexe, la date de naissance, les livres émis) qui seront alimentées à un certain algorithme ML pour déterminer le nom réel du lecteur & devrait être laissé pour le moment. Mais une chose dont je suis assez sûr, c’est que les 3 premiers noms représentent la même personne & Je ne devrais pas avoir besoin d’informations supplémentaires pour les fusionner en un seul lecteur c’est-à-dire ‘Saurav Kumar Agarwal’.
Comment cela peut-il être fait ?
Voici la correspondance de chaîne fuzz qui signifie une correspondance presque exacte entre des chaînes de caractères qui sont légèrement différentes les unes des autres (principalement en raison de mauvaises orthographes) comme ‘Agarwal’ & ‘Aggarwal’ & ‘Aggrawal’. Si nous obtenons une chaîne avec un taux d’erreur acceptable (disons une lettre erronée ), nous la considérerons comme une correspondance. Explorons donc →
La distance de Hamming est la distance la plus évidente calculée entre deux chaînes de longueur égale qui donne un compte des caractères qui ne correspondent pas correspondant à un indice donné. Par exemple : ‘Bat’ & ‘Bet’ a une distance de hamming de 1 comme à l’indice 1, ‘a’ n’est pas égal à ‘e’
Distance de Levenstein/Distance d’édition
Bien que je suppose que vous êtes à l’aise avec la distance de Levenstein & Récursion. Si ce n’est pas le cas, lisez ceci. L’explication ci-dessous est plus une version résumée de la distance de Levenstein.
Laissez ‘x’=longueur(Str1) &’y’=longueur(Str2) pour tout ce post.
La distance de Levenstein calcule le nombre minimum d’éditions nécessaires pour convertir ‘Str1’ en ‘Str2’ en effectuant soit des caractères d’addition, de suppression ou de remplacement. Par conséquent, ‘Cat’ & ‘Bat’ a une distance d’édition ‘1’ (Remplacer ‘C’ par ‘B’) alors que pour ‘Ceat’ & ‘Bat’, elle serait de 2 (Remplacer ‘C’ par ‘B’ ; Supprimer ‘e’).
Pour parler de l’algorithme, il comporte majoritairement 5 étapes
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Ce que nous faisons, c’est commencer à lire les chaînes de caractères à partir du 1er caractère
- Si le caractère à l’indice ‘x’ de str1 correspond au caractère à l’indice ‘y’ de str2, aucune édition nécessaire & calculer la distance d’édition en appelant
LevensteinDistance(str1,str2)
- S’ils ne correspondent pas, nous savons qu’une édition est nécessaire. On ajoute donc +1 à la distance d’édition actuelle & calcule récursivement la distance d’édition pour 3 conditions & prend le minimum parmi les trois:
Levenstein(str1,str2) →insertion dans str2.
Levenstein(str1,str2) →suppression dans str2
Levenstein(str1,str2)→remplacement dans str2
- Si l’une des chaînes manque de caractères pendant la récursion, la longueur des caractères restants dans l’autre chaîne sont ajoutés à la distance d’édition (les 2 premières instructions if)
Demerau-Levenstein Distance
Considérer ‘abcd’ & ‘acbd’. Si nous allons par la distance de Levenstein, ce serait (remplacer ‘b’-‘c’ & ‘c’-‘b’ aux positions d’index 2 & 3 dans str2) Mais si vous regardez de près, les deux caractères ont été échangés comme dans str1 & si nous introduisons une nouvelle opération ‘Swap’ à côté de ‘addition’, ‘suppression’ & ‘remplacement’, ce problème peut être résolu. Cette introduction peut nous aider à résoudre des problèmes comme ‘Agarwal’ & ‘Agrawal’.
Cette opération est ajoutée par le pseudocode ci-dessous
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Exécutons l’opération ci-dessus pour ‘abcd’ & ‘acbd’ où l’on suppose
initial_x=1 & initial_y=1 (Démarrage de l’indexation à partir de 1 & et non de 0 pour les deux chaînes de caractères).
courant x=3 &y=3 d’où str1 & str2 à ‘c’ (abcd) & ‘b’ (acbd) respectivement.
Limites supérieures incluses dans l’opération de tranchage mentionnée ci-dessous. Par conséquent, ‘qwerty’ signifiera ‘qwer’.
- last_matching_index_y sera le dernier_index dans str2 qui correspond à str1, c’est-à-dire 2 comme ‘c’ dans ‘acbd’ (indice 2)correspondant à ‘c’ dans ‘abcd’.
- last_matching_index_x sera le dernier_index dans str1 qui correspond à str2, c’est-à-dire 2 comme ‘b’ dans ‘acbd’ (indice 2)correspondant à ‘c’ dans ‘abcd’.e 2 car ‘b’ dans ‘abcd’ (index 2)correspondait à ‘b’ dans ‘acbd’.
- Donc, en suivant le pseudocode ci-dessus, DemarauLevenstein(‘abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(‘a’,’a’)=1+0+0+0=1. Cela aurait été 2 si nous avions suivi la distance de Levenstein
N-Gram
N-gramme n’est fondamentalement rien d’autre qu’un ensemble de valeurs générées à partir d’une chaîne de caractères en appariant des caractères/mots ‘n’ apparaissant séquentiellement. Par exemple : le n-gramme avec n=2 pour ‘abcd’ sera ‘ab’, ‘bc’, ‘cd’.
Maintenant, ces n-grammes peuvent être générés pour des chaînes de caractères dont la similarité doit être mesurée & différentes métriques peuvent être utilisées pour mesurer la similarité.
Disons que ‘abcd’ & ‘acbd’ sont 2 chaînes de caractères à faire correspondre.
n-grammes avec n=2 pour
‘abcd’=ab,bc,cd
‘acbd’=ac,cb,bd
Correspondance des composants (qgrammes)
Compte des n-grammes correspondant exactement aux deux chaînes de caractères. Ici, ce serait 0
Similarité du cosinus
Calcul du produit scalaire après avoir converti les n-grammes pour les chaînes de caractères en vecteurs
Concordance des composantes (aucun ordre pris en compte)
Concordance des composantes des n-grammes en ignorant l’ordre des éléments à l’intérieur c’est-à-dire bc=cb.
Il existe de nombreuses autres métriques de ce type comme la distance de Jaccard, l’indice de Tversky, etc. qui n’ont pas été abordées ici.
BK Tree
BK tree est parmi les algorithmes les plus rapides pour trouver des chaînes similaires (à partir d’un pool de chaînes) pour une chaîne donnée. L’arbre BK utilise une
- Distance de Levenstein
- Inégalité de triangle (nous couvrirons cela à la fin de cette section)
pour déterminer les chaînes similaires(& pas seulement une meilleure chaîne).
Un arbre BK est créé en utilisant un pool de mots d’un dictionnaire disponible. Disons que nous avons un dictionnaire D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart}
Un arbre BK est créé par
- Sélectionner un nœud racine (peut être n’importe quel mot). Soit ‘Livres’
- Passer en revue chaque mot W dans le dictionnaire D, calculer sa distance de Levenstein avec le nœud racine, et faire du mot W un enfant de la racine si aucun enfant avec la même distance de Levenstein n’existe pour le parent. Insertion de Livres & Gâteau.
Levenstein(Livres,Livre)=1 & Levenstein(Livres,Gâteau)=4. Comme aucun enfant avec la même distance n’a été trouvé pour ‘Livre’, faites-en de nouveaux enfants pour la racine.
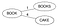
- Si un enfant avec la même distance de Levenstein existe pour le parent P, maintenant considérer cet enfant comme un parent P1 pour ce mot W, calculer Levenstein(parent, mot) et si aucun enfant avec la même distance n’existe pour le parent P1, faire du mot W un nouvel enfant pour P1 sinon continuer à descendre dans l’arbre.
Envisager l’insertion de Boo. Levenstein(Livre, Boo)=1 mais il existe déjà un enfant avec le même c’est-à-dire Livres. Donc, calculez maintenant Levenstein(Livres, Boo)=2. Comme il n’existe pas d’enfant avec la même distance pour Books, on fait de Boo un enfant de Books.

De même, insérer tous les mots du dictionnaire dans l’Arbre BK

Une fois que l’Arbre BK est préparé, pour rechercher des mots similaires pour un mot donné (mot de requête), nous devons définir un seuil de tolérance dit ‘t’.
- C’est la edit_distance maximale que nous allons considérer pour la similarité entre tout nœud & mot_requête. Tout ce qui dépasse cette distance est rejeté.
- De plus, nous ne considérerons que les enfants d’un nœud parent pour la comparaison avec Query où le Levenstein(Child, Parent) est dans
pourquoi ? Nous en discuterons prochainement
- Si cette condition est vraie pour un enfant, alors seulement nous calculerons Levenstein(Enfant, Requête) qui sera considéré comme similaire à la requête si
Levenshtein(Enfant, Requête)≤t.
- Hence, Nous ne calculerons pas la distance de Levenstein pour tous les nœuds/mots dans le dictionnaire avec le mot requête & donc gagner beaucoup de temps lorsque le pool de mots est énorme
Hence, pour qu’un Enfant soit similaire à Requête si
- Levenstein(Parent, Requête)-t ≤ Levenstein(Enfant,Parent) ≤ Levenstein(Parent,Requête)+t
- Levenstein(Enfant,Requête)≤t
Passons rapidement en revue un exemple. Soit ‘t’=1
Let le mot pour lequel nous devons trouver des mots similaires est ‘Care’ (mot de requête)
- Levenstein(Livre,Care)=4. Comme 4>1, ‘Livre’ est rejeté. Maintenant, nous allons considérer seulement les enfants de ‘Livre’ qui ont une LevisteinDistance(Enfant, ‘Livre’) entre 3(4-1) & 5(4+1). Par conséquent, nous rejetterions ‘Livres’ & tous ses enfants car 1 ne se trouve pas dans les limites fixées
- Comme Levenstein(Gâteau, Livre)=4 qui se trouve entre 3 & 5, nous allons vérifier Levenstein(Gâteau, Soin)=1 qui est ≤1 donc un mot similaire.
- En réajustant les limites, pour les enfants de Cake, deviennent 0(1-1) & 2(1+1)
- Comme les deux Cap & Cart a Levenstein(Enfant, Parent)=1 & 2 respectivement, les deux sont éligibles pour être testés avec ‘Care’.
- Comme Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, seul Cape est considéré comme un mot similaire à ‘Care’.
Hence, nous avons trouvé 2 mots similaires à ‘Care’ qui sont : Gâteau & Cap
Mais sur quelle base décidons-nous des limites
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
pour tout nœud enfant ?
Cela découle de l’inégalité des triangles qui stipule
Distance (A,B) + Distance(B,C)≥Distance(A,C) où A,B,C sont les côtés d’un triangle.
Comment cette idée nous aide à atteindre ces limites, voyons:
Laissez Query,=Q Parent=P & Child=C former un triangle avec la distance de Levenstein comme longueur d’arête. Soit ‘t’ le seuil de tolérance. Alors, Par l’inégalité ci-dessus
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Encore, par l’inégalité du triangle,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Algorithme Bitap
C’est aussi un algorithme très rapide qui peut être utilisé pour la correspondance de chaînes floues assez efficacement. C’est parce qu’il utilise des opérations bit à bit & car elles sont assez rapides, l’algorithme est connu pour sa rapidité. Sans perdre un instant, commençons :
Disons que S0=’ababc’ est le motif à faire correspondre avec la chaîne de caractères S1=’abdabababc’.
D’abord,
- Déterminez tous les caractères uniques dans S1 & S0 qui sont a,b,c,d
- Formez des motifs de bits pour chaque caractère. Comment ?

- Inverser le motif S0 à rechercher
- Pour le motif binaire du caractère x, placer 0 là où il apparaît dans le motif sinon 1. Dans T, ‘a’ apparaît à la 3ème & 5ème place, nous avons placé 0 à ces positions & reste 1.
De la même manière, former tous les autres motifs binaires pour les différents caractères du dictionnaire.
S0=ababc S1=abdabababc
- Prendre un état initial d’un motif binaire de longueur(S0) avec tous les 1. Dans notre cas, ce serait 11111 (état S).
- Au fur et à mesure que nous commençons à chercher dans S1 et que nous passons par n’importe quel caractère,
déplacer un 0 au bit le plus bas, c’est-à-dire le 5e bit à partir de la droite dans S &
opération OU sur S avec T.
Donc, comme nous rencontrerons le 1er ‘a’ dans S1, nous allons
- déplacer à gauche un 0 dans S au bit le plus bas pour former 11111 →11110
- 11010 | 11110=11110
Maintenant, comme nous passons au 2ème caractère ‘b’
- déplacer un 0 dans S i.e pour former 11110 →11100
- S |T=11100 | 10101=11101
Comme ‘d’ est rencontré
- Déplacez 0 vers S pour former 11101 →11010
- S |T=11010 |11111=11111
Observez que comme ‘d’ n’est pas dans S0, l’état S est réinitialisé. Une fois que vous avez parcouru la totalité de S1, vous obtenez les états ci-dessous à chaque caractère

Comment puis-je savoir si j’ai trouvé une correspondance fuzz/complète ?
- Si un 0 atteint le bit le plus haut dans le motif de bits de State S(comme dans le dernier caractère ‘c’), vous avez une correspondance complète
- Pour une correspondance fuzz, observez des 0 à différentes positions de State S. Si 0 est à la 4e place, nous avons trouvé 4/5 caractères dans la même séquence que dans S0. De même pour 0 aux autres places.
Une chose que vous avez pu observer, c’est que tous ces algorithmes fonctionnent sur la similarité orthographique des chaînes de caractères. Peut-il y avoir d’autres critères de correspondance floue ? Oui,
Phonétique
Je couvrirai prochainement les algorithmes de correspondance floue basés sur la phonétique(basée sur le son, comme Saurav & Sourav, devrait avoir une correspondance exacte en phonétique) ! !!
- Réduction de dimension (3 parties)
- Algorithmes NLP(5 parties)
- Bases de l’apprentissage par renforcement (5 parties)
- Démarrer avec le temps-.Series (7 parties)
- Détection d’objets à l’aide de YOLO (3 parties)
- Tensorflow pour débutants (concepts + exemples) (4 parties)
- Prétraitement des séries temporelles (avec codes)
- Analyse de données pour débutants
- Statistiques pour débutants (4 parties)
.