- Introduktion
- Mål
- A. Filtermetoder
- Chi-kvadrat-test
- Fisher’s Score
- Korrelationskoefficient
- Varianströskel
- Mean Absolute Difference (MAD)
- Spridningskvot
- B. Wrappermetoder:
- Forward Feature Selection
- Backward Feature Elimination
- Exhaustive Feature Selection
- Recursive Feature Elimination
- C. Inbäddade metoder:
- LASSO Regularization (L1)
- Random Forest Importance
- Slutsats
Introduktion
När man bygger en modell för maskininlärning i verkligheten är det nästan ovanligt att alla variabler i datamängden är användbara för att bygga en modell. Att lägga till redundanta variabler minskar modellens generaliseringsförmåga och kan också minska den totala noggrannheten hos en klassificerare. Att dessutom lägga till fler och fler variabler till en modell ökar modellens totala komplexitet.
Enligt lagen om parsimoni i ”Occams raseri” är den bästa förklaringen till ett problem den som innefattar så få möjliga antaganden som möjligt. Därför blir urvalet av funktioner en oumbärlig del av byggandet av modeller för maskininlärning.
Mål
Målet med urvalet av funktioner vid maskininlärning är att hitta den bästa uppsättningen funktioner som gör det möjligt att bygga användbara modeller av studerade fenomen.
Teknikerna för urval av funktioner vid maskininlärning kan i stort sett delas in i följande kategorier:
Superviserade tekniker: Dessa tekniker kan användas för märkta data och används för att identifiera relevanta funktioner för att öka effektiviteten hos övervakade modeller som klassificering och regression.
Oövervakade tekniker: Dessa tekniker används för att identifiera relevanta funktioner för att öka effektiviteten hos övervakade modeller som klassificering och regression:
Från en taxonomisk synvinkel klassificeras dessa tekniker enligt följande:
A. Filtermetoder
B. Wrapper-metoder
C. Inbäddade metoder
D. Hybridmetoder
I den här artikeln kommer vi att diskutera några populära tekniker för funktionsval inom maskininlärning.
A. Filtermetoder
Filtermetoder plockar upp funktionernas inneboende egenskaper som mäts via univariat statistik istället för korsvalideringsprestanda. Dessa metoder är snabbare och mindre beräkningskrävande än omslagsmetoder. Vid hantering av högdimensionella data är det beräkningsmässigt billigare att använda filtermetoder.
Låt oss, diskutera några av dessa tekniker:
Informationsvinst
Informationsvinst beräknar minskningen av entropin från transformationen av en datamängd. Den kan användas för val av funktioner genom att utvärdera informationsvinsten för varje variabel i samband med målvariabeln.
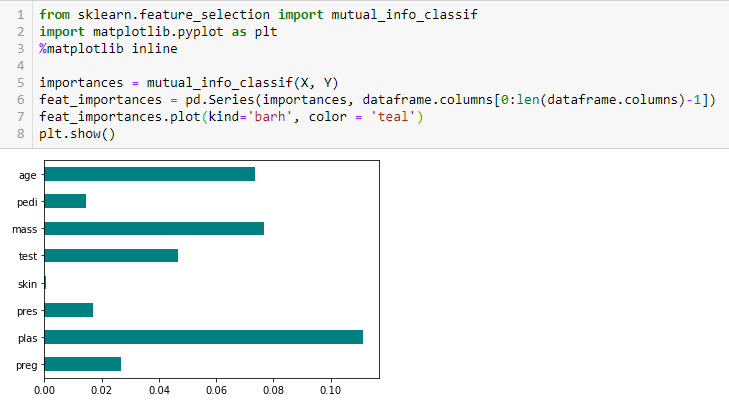
Chi-kvadrat-test
Chi-kvadrat-testet används för kategoriska funktioner i en datamängd. Vi beräknar Chi-square mellan varje funktion och målet och väljer det önskade antalet funktioner med de bästa Chi-square-resultaten. För att korrekt tillämpa chi-kvadrat för att testa sambandet mellan olika funktioner i datamängden och målvariabeln måste följande villkor vara uppfyllda: variablerna måste vara kategoriska, samplade oberoende av varandra och värdena bör ha en förväntad frekvens som är större än 5.
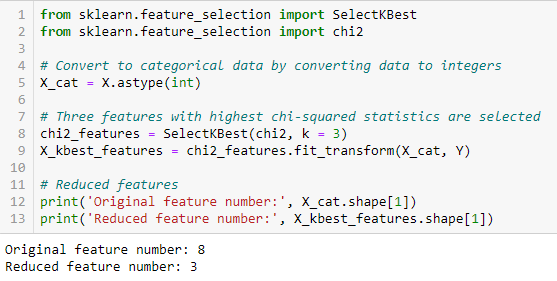
Fisher’s Score
Fisher’s Score är en av de mest använda övervakade metoderna för urval av funktioner. Algoritmen som vi kommer att använda returnerar rankningen av variablerna baserat på Fisher’s score i fallande ordning. Vi kan sedan välja variablerna i enlighet med fallet.
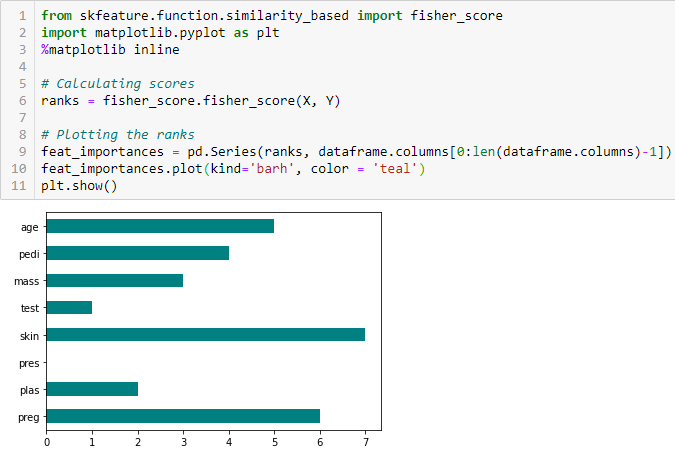
Korrelationskoefficient
Korrelation är ett mått på det linjära sambandet mellan 2 eller flera variabler. Genom korrelation kan vi förutsäga en variabel utifrån den andra. Logiken bakom att använda korrelation för funktionsval är att de bra variablerna är starkt korrelerade med målet. Dessutom bör variablerna vara korrelerade med målet men bör vara okorrelerade sinsemellan.
Om två variabler är korrelerade kan vi förutsäga den ena från den andra. Om två egenskaper är korrelerade behöver modellen därför egentligen bara en av dem, eftersom den andra inte tillför ytterligare information. Vi kommer att använda Pearsonkorrelationen här.
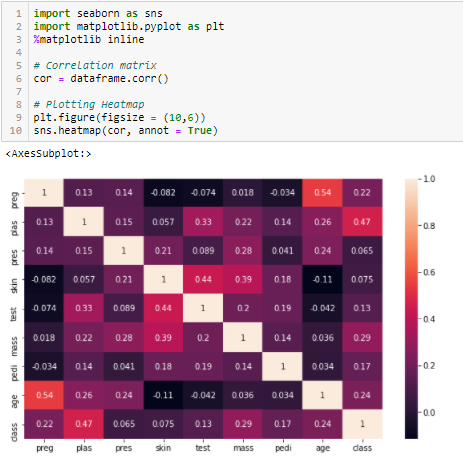
Vi måste fastställa ett absolut värde, till exempel 0,5 som tröskelvärde för att välja variablerna. Om vi finner att prediktorvariablerna är korrelerade sinsemellan kan vi släppa den variabel som har ett lägre värde för korrelationskoefficienten med målvariabeln. Vi kan också beräkna flera korrelationskoefficienter för att kontrollera om fler än två variabler är korrelerade med varandra. Detta fenomen kallas multikollinearitet.
Varianströskel
Varianströskeln är en enkel grundmetod för urval av funktioner. Den tar bort alla funktioner vars varians inte uppfyller ett visst tröskelvärde. Som standard tar den bort alla funktioner med nollvarians, dvs. funktioner som har samma värde i alla prover. Vi antar att funktioner med högre varians kan innehålla mer användbar information, men observera att vi inte tar hänsyn till förhållandet mellan funktionsvariabler eller funktions- och målvariabler, vilket är en av nackdelarna med filtermetoder.

Get_support returnerar en boolesk vektor där True betyder att variabeln inte har nollvarians.
Mean Absolute Difference (MAD)
’Mean Absolute Difference (MAD) beräknar den absoluta skillnaden från medelvärdet. Den största skillnaden mellan variansmåttet och MAD-måttet är avsaknaden av kvadraten i det senare. MAD, liksom variansen, är också en skalvariant. Detta innebär att högre MAD, högre diskriminerande effekt.
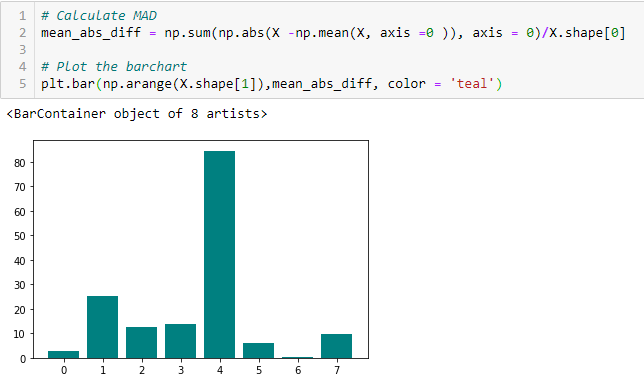
Spridningskvot
’Ett annat spridningsmått tillämpar det aritmetiska medelvärdet (AM) och det geometriska medelvärdet (GM). För en given (positiv) funktion Xi på n mönster ges AM och GM av
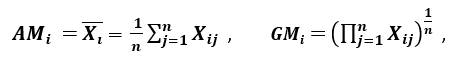
respektive; eftersom AMi ≥ GMi, med jämlikhet som gäller om och endast om Xi1 = Xi2 = …. = Xin, kan förhållandet
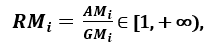
användas som ett spridningsmått. Högre spridning innebär ett högre värde på Ri, alltså en mer relevant egenskap. Omvänt gäller att när alla funktionsprover har (ungefär) samma värde är Ri nära 1, vilket tyder på en funktion med låg relevans.

 ’
’
B. Wrappermetoder:
Varumärken kräver någon metod för att söka i alla möjliga delmängder av funktioner och bedöma deras kvalitet genom att lära sig och utvärdera en klassificerare med den delmängden av funktioner. Processen för val av funktioner baseras på en specifik algoritm för maskininlärning som vi försöker anpassa till en given datamängd. Den följer en greedy search-metod genom att utvärdera alla möjliga kombinationer av funktioner mot utvärderingskriteriet. Inkapslingsmetoderna resulterar vanligtvis i bättre prediktiv noggrannhet än filtermetoder.
Låt oss, diskutera några av dessa tekniker:
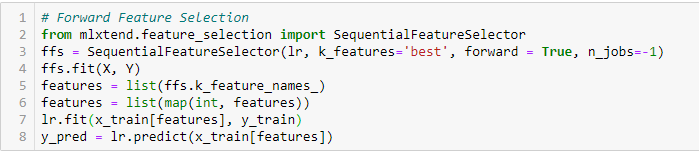
Forward Feature Selection
Detta är en iterativ metod där vi börjar med den bäst presterande variabeln mot målet. Därefter väljer vi en annan variabel som ger den bästa prestandan i kombination med den först valda variabeln. Denna process fortsätter tills det förinställda kriteriet uppnås.
Backward Feature Elimination
Denna metod fungerar precis tvärtemot Forward Feature Selection-metoden. Här börjar vi med alla tillgängliga funktioner och bygger en modell. Därefter väljer vi den variabel från modellen som ger det bästa värdet för utvärderingsmåttet. Denna process fortsätter tills det förinställda kriteriet är uppnått.
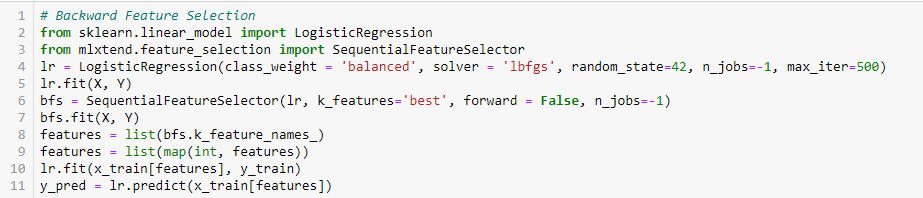
Denna metod tillsammans med den som diskuteras ovan kallas också för Sequential Feature Selection-metoden.
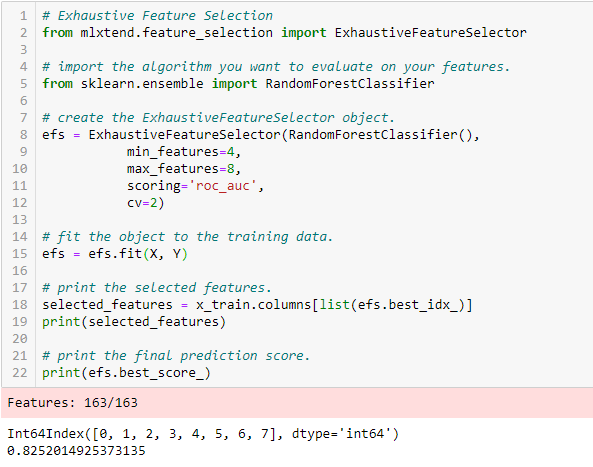
Exhaustive Feature Selection
Detta är den mest robusta feature selection-metoden som behandlats hittills. Detta är en brutal utvärdering av varje delmängd av funktioner. Det innebär att den prövar alla möjliga kombinationer av variablerna och returnerar den bäst presterande delmängden.
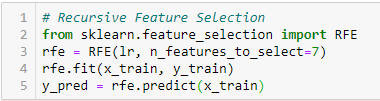
Recursive Feature Elimination
”Givet en extern estimator som tilldelar vikter till funktioner (t.ex. koefficienterna i en linjär modell) är målet för recursive feature elimination (RFE) att välja funktioner genom att rekursivt överväga allt mindre och mindre uppsättningar av funktioner. Först tränas estimatorn på den ursprungliga uppsättningen funktioner och vikten av varje funktion erhålls antingen genom ett coef_-attribut eller genom ett feature_importances_-attribut.
Därefter rensas de minst viktiga funktionerna bort från den aktuella uppsättningen funktioner. Detta förfarande upprepas rekursivt på den rensade uppsättningen tills det önskade antalet egenskaper som ska väljas slutligen uppnås.”
C. Inbäddade metoder:
Dessa metoder omfattar fördelarna med både wrapper- och filtermetoderna, genom att inkludera interaktioner mellan funktioner men också behålla en rimlig beräkningskostnad. Inbäddade metoder är iterativa i den meningen att de tar hand om varje iteration av modellträningsprocessen och noggrant extraherar de funktioner som bidrar mest till träningen för en viss iteration.
Låt oss diskutera några av dessa tekniker klicka här:
LASSO Regularization (L1)
Regularization består av att lägga till en straffavgift till de olika parametrarna i modellen för maskininlärning för att minska modellens frihet, dvs. för att undvika överanpassning. I regulering av linjära modeller tillämpas straffet på de koefficienter som multiplicerar var och en av prediktorerna. Av de olika typerna av reglering har Lasso eller L1 den egenskapen att den kan krympa några av koefficienterna till noll. Därför kan den funktionen tas bort från modellen.
Random Forest Importance
Random Forests är ett slags Bagging-algoritm som aggregerar ett visst antal beslutsträd. De trädbaserade strategier som används av slumpmässiga skogar rangordnas naturligtvis efter hur väl de förbättrar nodens renhet, eller med andra ord en minskning av orenheten (Ginis orenhet) över alla träd. Noder med den största minskningen av orenhet inträffar i början av träden, medan noder med den minsta minskningen av orenhet inträffar i slutet av träden. Genom att beskära träd under en viss nod kan vi alltså skapa en delmängd av de viktigaste funktionerna.
Slutsats
Vi har diskuterat några tekniker för val av funktioner. Vi har med flit lämnat de tekniker för utvinning av funktioner som Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis, etc. Dessa metoder hjälper till att reducera datans dimensionalitet eller minska antalet variabler samtidigt som datans varians bevaras.
Bortsett från de metoder som diskuterats ovan finns det många andra metoder för funktionsurval. Det finns också hybridmetoder som använder både filtrerings- och omslagstekniker. Om du vill utforska mer om tekniker för funktionsurval kan du enligt min mening läsa ”Feature Selection for Data and Pattern Recognition” av Urszula Stańczyk och Lakhmi C. Jain.