Uppdatering 29-maj-2018: Syftet med den här artikeln är trefaldigt (1) Visa att vi alltid kommer att behöva en datamodell (antingen gjord av människor eller maskiner) (2) Visa att fysisk modellering inte är samma sak som logisk modellering. I själva verket är det mycket olika och beror på den underliggande tekniken. Vi behöver dock båda. Jag illustrerade detta med hjälp av Hadoop på det fysiska lagret (3) Visa hur begreppet oföränderlighet påverkar datamodellering.
- Är dimensionell modellering död?
- Varför behöver vi modellera våra data?
- Varför behöver vi dimensionella modeller?
- Datamodellering vs. dimensionell modellering
- Så varför hävdar vissa att dimensionell modellering är död?
- Data Warehouse is dead Förvirring
- Missförståndet Schema on Read
- Denormalisering återigen. Modellens fysiska aspekter.
- Tagning av de-normalisering till sin fulla rätt
- Datadistribution på en distribuerad relationsdatabas (MPP)
- Datadistribution på Hadoop
- Dimensionella modeller på Hadoop
- Hadoop och sakta föränderliga dimensioner
- Lagringsutveckling på Hadoop
- Domen. Är dimensionella modeller och stjärnscheman föråldrade?
- Kompletterande läsning om dimensionell modellering i Big Data-eran
Är dimensionell modellering död?
Innan jag ger dig ett svar på denna fråga ska vi ta ett steg tillbaka och först titta på vad vi menar med dimensionell datamodellering.
Varför behöver vi modellera våra data?
I motsats till ett vanligt missförstånd är det inte det enda syftet med datamodeller att fungera som ett ER-diagram för att utforma en fysisk databas. Datamodeller representerar komplexiteten hos affärsprocesserna i ett företag. De dokumenterar viktiga affärsregler och begrepp och hjälper till att standardisera viktig företagsterminologi. De ger klarhet och hjälper till att avslöja oklarheter och tvetydigheter om affärsprocesser. Dessutom kan du använda datamodeller för att kommunicera med andra intressenter. Du skulle inte bygga ett hus eller en bro utan en ritning. Så varför skulle du bygga en dataapplikation som ett datalager utan en plan?
Varför behöver vi dimensionella modeller?
Dimensionell modellering är ett särskilt tillvägagångssätt för att modellera data. Vi använder också orden data mart eller star schema som synonymer för en dimensionell modell. Stjärnscheman är optimerade för dataanalys. Ta en titt på den dimensionella modellen nedan. Den är ganska intuitiv att förstå. Vi ser omedelbart hur vi kan dela upp våra beställningsdata efter kund, produkt eller datum och mäta prestandan i affärsprocessen Beställningar genom att aggregera och jämföra mätvärden.
En av de centrala idéerna med dimensionell modellering är att definiera den lägsta granularitetsnivån i en transaktionell affärsprocess. När vi skär ut och borrar i data är detta den bladnivå från vilken vi inte kan borra längre ner. Uttryckt på ett annat sätt är den lägsta granularitetsnivån i ett stjärnschema en sammanfogning av fakta till alla dimensionstabeller utan några aggregeringar.
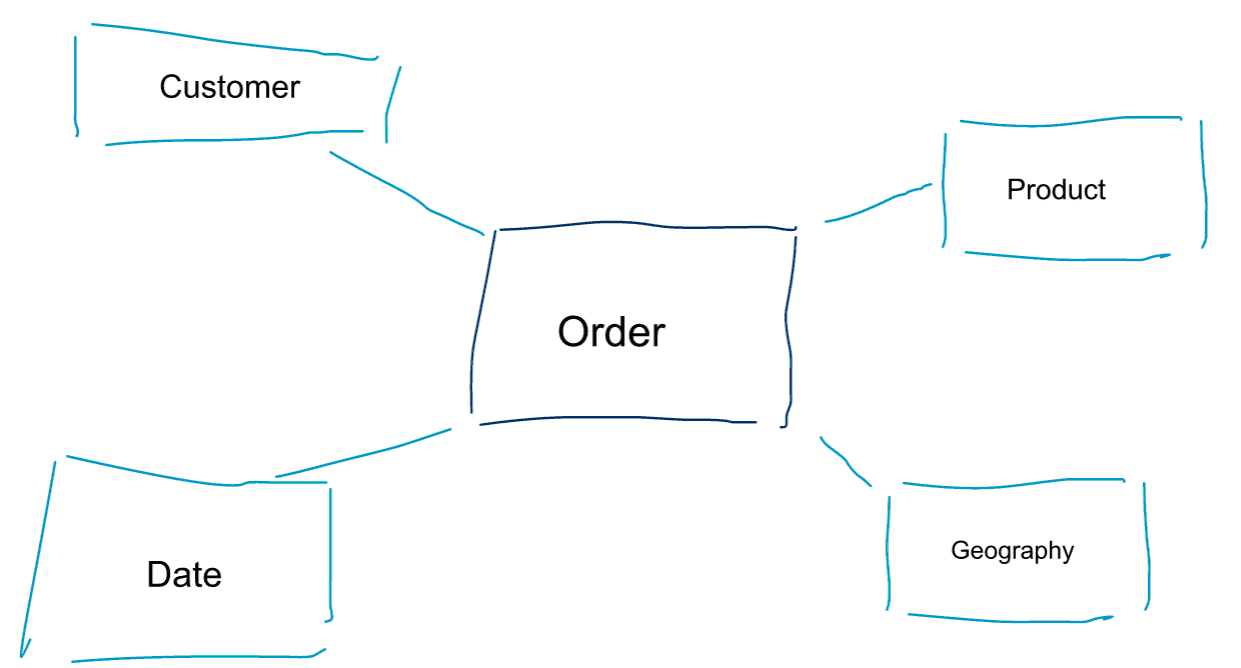
Datamodellering vs. dimensionell modellering
I vanlig datamodellering strävar vi efter att eliminera upprepning och redundans av data. När en ändring sker i data behöver vi bara ändra den på ett ställe. Detta bidrar också till datakvaliteten. Värden blir inte osynkroniserade på flera ställen. Ta en titt på modellen nedan. Den innehåller olika tabeller som representerar geografiska begrepp. I en normaliserad modell har vi en separat tabell för varje enhet. I en dimensionell modell har vi bara en tabell: geografi. I den här tabellen kommer städer att upprepas flera gånger. En gång för varje stad. Om landet byter namn måste vi uppdatera landet på många ställen
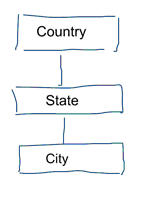
Notera: Standardiserad datamodellering kallas också för 3NF-modellering.
Den standardiserade metoden för datamodellering är inte lämplig för arbetsbelastningar inom Business Intelligence. Många tabeller resulterar i många sammanfogningar. Joiner gör saker och ting långsammare. I dataanalyser undviker vi dem i möjligaste mån. I dimensionella modeller de-normaliserar vi flera relaterade tabeller till en tabell, t.ex. kan de olika tabellerna i vårt tidigare exempel för-jointas till bara en tabell: geografi.
Så varför hävdar vissa att dimensionell modellering är död?
Jag tror att du håller med om att datamodellering i allmänhet och dimensionell modellering i synnerhet är en ganska användbar övning. Så varför hävdar vissa människor att dimensionell modellering inte är användbar i en tid av stora data och Hadoop?
Som ni kan föreställa er finns det olika skäl till detta.
Data Warehouse is dead Förvirring
För det första förväxlar vissa människor dimensionell modellering med data warehousing. De hävdar att datalagring är död och att dimensionell modellering därför också kan förpassas till historiens soptunna. Detta är ett logiskt sammanhängande argument. Begreppet datalager är dock långt ifrån föråldrat. Vi behöver alltid integrerade och tillförlitliga data för att fylla våra BI-dashboards. Om du vill veta mer rekommenderar jag vår utbildning Big Data for Data Warehouse Professionals. I kursen går jag in på detaljerna och förklarar hur datalagret är lika relevant som någonsin. Jag kommer också att visa hur nya verktyg och tekniker för big data är användbara för datalagret.

Missförståndet Schema on Read
Det andra argumentet som jag ofta hör går så här. ”Vi följer ett schema vid läsning och behöver inte modellera våra data längre”. Enligt min mening är begreppet schema on read ett av de största missförstånden inom dataanalys. Jag håller med om att det är användbart att inledningsvis lagra dina rådata i en datadump som är lätt på schema. Detta argument bör dock inte användas som en ursäkt för att inte modellera dina data helt och hållet. Schema on read-metoden är bara att sparka ner burken och ansvaret till processer i efterföljande led. Någon måste fortfarande bita i det sura äpplet och definiera datatyperna. Varje process som får tillgång till den schemafria datadumpningen måste själv ta reda på vad som händer. Den här typen av arbete blir allt större, är helt överflödigt och kan lätt undvikas genom att definiera datatyper och ett korrekt schema.
Denormalisering återigen. Modellens fysiska aspekter.
Är det faktiskt några giltiga argument för att förklara dimensionella modeller föråldrade? Det finns faktiskt några bättre argument än de två som jag har räknat upp ovan. De kräver en viss förståelse för fysisk datamodellering och hur Hadoop fungerar. Jag har tidigare kortfattat nämnt ett av skälen till varför vi modellerar våra data dimensionellt. Det har att göra med hur data lagras fysiskt i vårt datalager. I vanlig datamodellering får varje enhet i den verkliga världen en egen tabell. Vi gör detta för att undvika dataredundans och risken för att datakvalitetsproblem smyger sig in i våra data. Ju fler tabeller vi har, desto fler joins behöver vi. Det är nackdelen. Tabellfogningar är kostsamma, särskilt när vi fogar samman ett stort antal poster från våra datamängder. När vi modellerar data dimensionellt konsoliderar vi flera tabeller till en. Vi säger att vi pre-joinar eller de-normaliserar data. Vi har nu färre tabeller, färre joins och som ett resultat lägre latenstid och bättre prestanda för förfrågningar.
Deltag i diskussionen om det här inlägget på LinkedIn
Tagning av de-normalisering till sin fulla rätt
Varför inte ta de-normalisering till sin fulla rätt? Bli av med alla joins och bara ha en enda faktatabell? Detta skulle i själva verket eliminera behovet av alla sammanfogningar helt och hållet. Som ni kan föreställa er har det dock vissa bieffekter. För det första ökar den mängden lagringsutrymme som krävs. Vi måste nu lagra en massa redundanta uppgifter. Med framväxten av kolumnformade lagringsformat för dataanalys är detta ett mindre problem nuförtiden. Det större problemet med de-normalisering är att varje gång ett värde på ett av attributen ändras måste vi uppdatera värdet på flera ställen – kanske tusentals eller miljoner uppdateringar. Ett sätt att komma runt detta problem är att helt ladda om våra modeller varje natt. Ofta är detta mycket snabbare och enklare än att tillämpa ett stort antal uppdateringar. Kolonnära databaser har vanligtvis följande tillvägagångssätt. De lagrar först uppdateringar av data i minnet och skriver dem asynkront till disken.
Datadistribution på en distribuerad relationsdatabas (MPP)
När vi skapar dimensionella modeller på Hadoop, t.ex. Hive, SparkSQL etc. måste vi bättre förstå en kärnfunktion hos tekniken som skiljer den från en distribuerad relationsdatabas (MPP) som Teradata etc. När vi distribuerar data över noderna i en MPP har vi kontroll över postens placering. Baserat på vår partitioneringsstrategi, t.ex. hash, lista, intervall etc., kan vi placera nycklarna till enskilda poster i olika flikar på samma nod. Med garanterad samlokalisering av data är våra anslutningar supersnabba eftersom vi inte behöver skicka några data över nätverket. Ta en titt på exemplet nedan. Poster med samma ORDER_ID från tabellerna ORDER och ORDER_ITEM hamnar på samma nod.
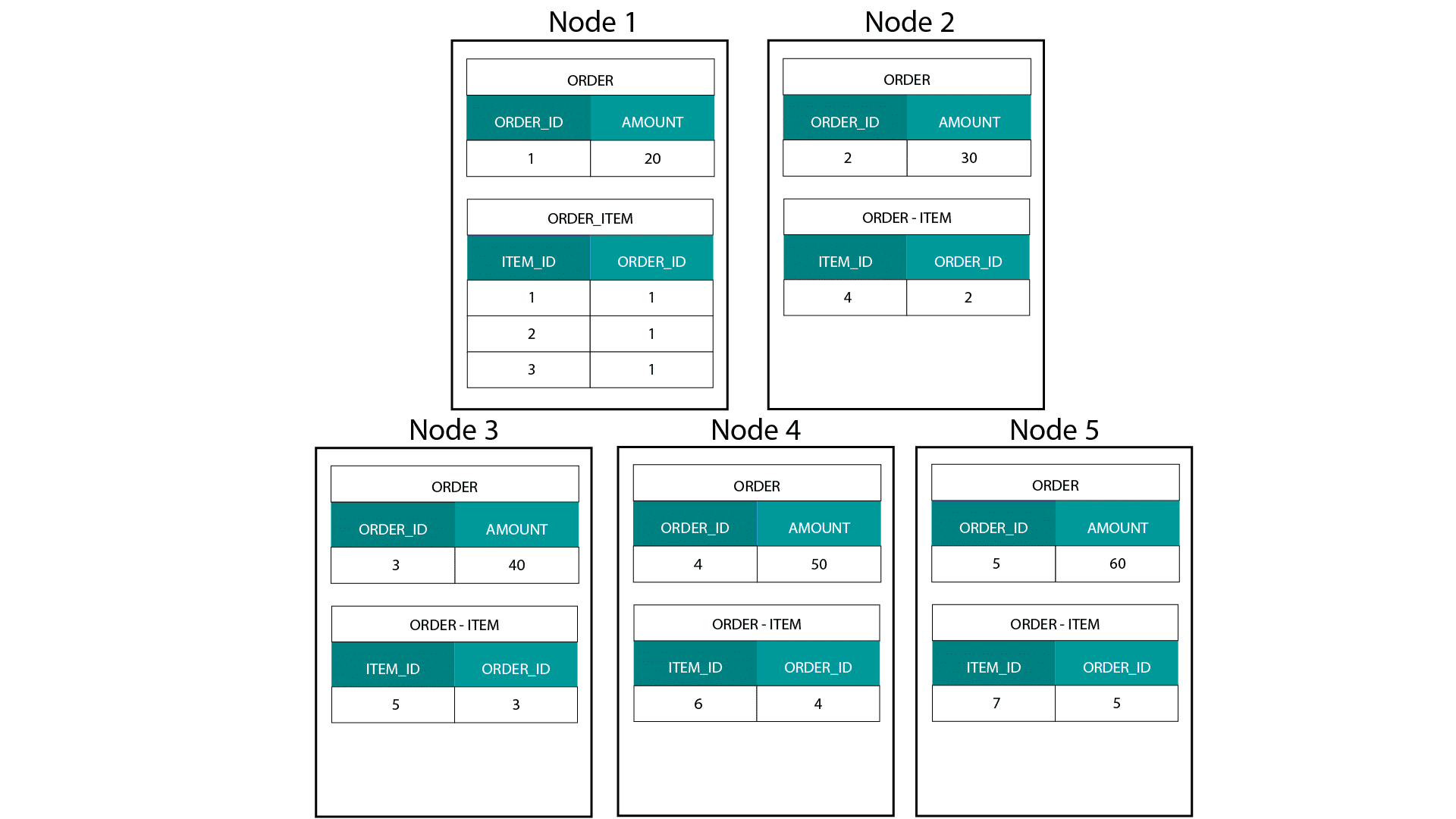
Nycklar för order_id i tabellerna ORDER och ORDER_ITEM är samlokaliserade på samma noder.
Datadistribution på Hadoop
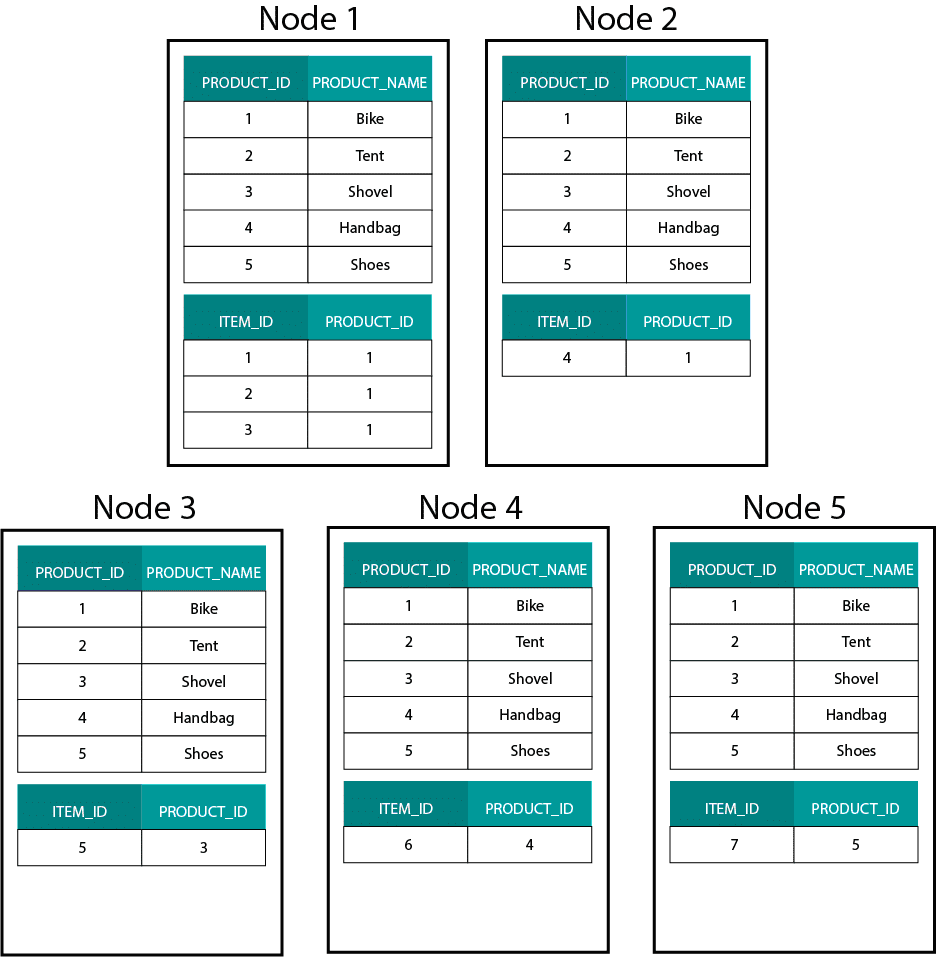
Det här skiljer sig mycket från Hadoopbaserade system. Där delar vi upp våra data i stora bitar och distribuerar och replikerar dem över våra noder på Hadoop Distributed File System (HDFS). Med denna datafördelningsstrategi kan vi inte garantera att data är samlokaliserade. Ta en titt på exemplet nedan. Posterna för ORDER_ID-nyckeln hamnar på olika noder.
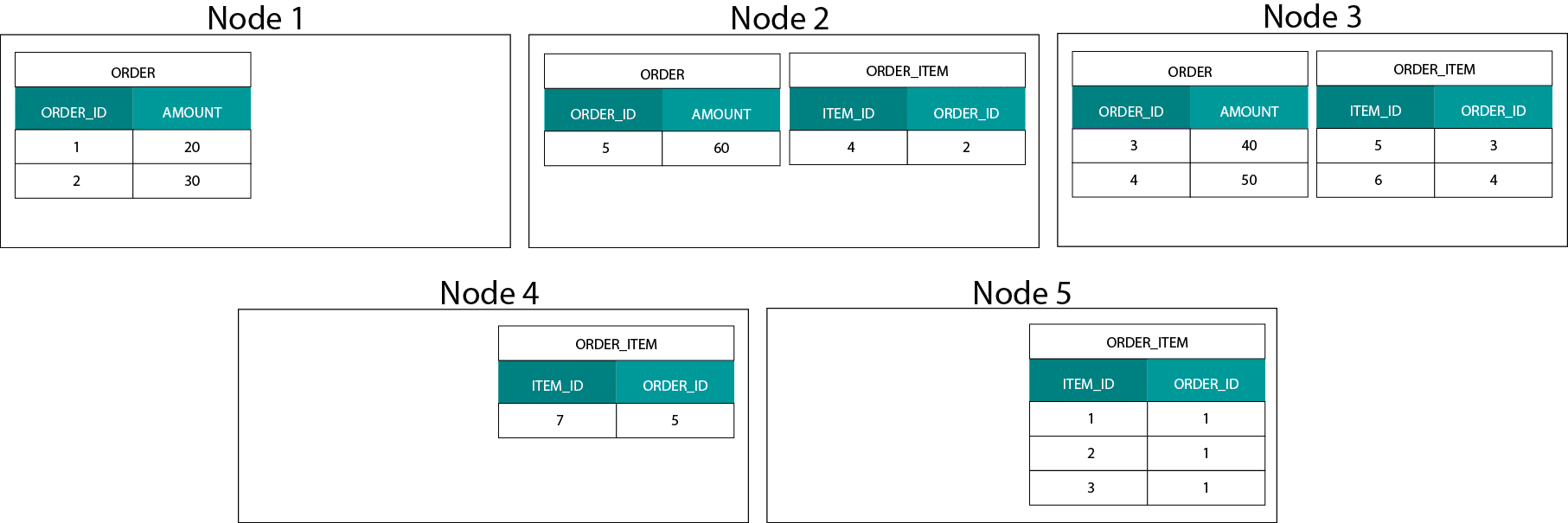
För att kunna göra en sammanfogning måste vi skicka data över nätverket, vilket påverkar prestandan.
En strategi för att hantera detta problem är att replikera en av sammanfogningstabellerna över alla noder i klustret. Detta kallas broadcast join och vi använder samma strategi på en MPP. Som du kan föreställa dig fungerar det bara för små uppslags- eller dimensionstabeller.
Vad gör vi då när vi har en stor faktatabell och en stor dimensionstabell, t.ex. kund eller produkt? Eller faktiskt när vi har två stora faktatabeller.
Dimensionella modeller på Hadoop
För att komma runt detta prestandaproblem kan vi avnormalisera stora dimensionstabeller till vår faktatabell för att garantera att data är samlokaliserade. Vi kan sända de mindre dimensionstabellerna över alla våra noder.
För att sammanfoga två stora faktatabeller kan vi nästla in tabellen med den lägre granulariteten i tabellen med den högre granulariteten, t.ex. en stor ORDER_ITEM-tabell som är nästlad i ORDER-tabellen. Moderna frågemotorer som Impala eller Drill gör det möjligt för oss att platta ut dessa data

Denna strategi för att nästla in data är också användbar för smärtsamma Kimballkoncept, t.ex. bryggtabeller, för att representera M:N-relationer i en dimensionell modell.
Hadoop och sakta föränderliga dimensioner
Lagring på Hadoops filsystem är oföränderlig. Med andra ord kan du bara lägga in och lägga till poster. Du kan inte ändra data. Om du kommer från en bakgrund med relationella datalager kan detta först verka lite märkligt. Men under huven fungerar databaser på ett liknande sätt. De lagrar alla ändringar av data i en oföränderlig write ahead log (känd i Oracle som redo log) innan en process asynkront uppdaterar data i datafiler.
Hur påverkar oföränderligheten våra dimensionella modeller? Du kanske minns begreppet Slowly Changing Dimensions (SCD) från din kurs i dimensionell modellering. SCD:er kan valfritt bevara historiken över ändringar av attribut. De gör det möjligt för oss att rapportera mätvärden mot värdet av ett attribut vid en viss tidpunkt. Detta är dock inte standardbeteendet. Som standard uppdaterar vi dimensionstabellerna med de senaste värdena. Vilka alternativ har vi då på Hadoop? Kom ihåg! Vi kan inte uppdatera data. Vi kan helt enkelt göra SCD till standardbeteende och granska alla ändringar. Om vi vill köra rapporter mot de aktuella värdena kan vi skapa en vy ovanpå SCD som endast hämtar det senaste värdet. Detta kan enkelt göras med hjälp av fönsterfunktioner. Alternativt kan vi köra en så kallad komprimeringstjänst som fysiskt skapar en separat version av dimensionstabellen med bara de senaste värdena.
Lagringsutveckling på Hadoop
Dessa Hadoop-begränsningar har inte gått obemärkt förbi av leverantörerna av Hadoop-plattformarna. I Hive har vi nu ACID-transaktioner och uppdaterbara tabeller. Baserat på antalet öppna större problem och min egen erfarenhet verkar denna funktion dock inte vara produktionsklar ännu . Cloudera har valt ett annat tillvägagångssätt. Med Kudu har de skapat ett nytt uppdaterbart lagringsformat som inte ligger i HDFS utan i det lokala operativsystems filsystem. Det gör sig helt och hållet av med Hadoops begränsningar och liknar det traditionella lagringslagret i en kolonnformad MPP. Generellt sett är det förmodligen bättre att köra BI och instrumentpaneler på en MPP, t.ex. Impala + Kudu, än på Hadoop. Med detta sagt har MPP:s egna begränsningar när det gäller motståndskraft, samtidighet och skalbarhet. När du stöter på dessa begränsningar är Hadoop och dess nära kusin Spark bra alternativ för BI-arbetsbelastningar. Vi tar upp alla dessa begränsningar i vår utbildning Big Data for Data Warehouse Professionals och ger rekommendationer om när man ska använda ett RDBMS och när man ska använda SQL på Hadoop/Spark.
Domen. Är dimensionella modeller och stjärnscheman föråldrade?
Vi vet alla att Ralph Kimball har gått i pension. Men hans principiella idéer och koncept är fortfarande giltiga och lever vidare. Vi måste anpassa dem till ny teknik och nya lagringstyper, men de ger fortfarande ett mervärde.
Lär mig Big Data för att främja min karriär
Kompletterande läsning om dimensionell modellering i Big Data-eran
Tom Breur: Det är en av de viktigaste frågorna för en snabb integrering av stora datamängder – det anti-datalager-mönstret
Edosa Odaro: 5 radikala tips för snabb integrering av stora datamängder – det anti-datalager-mönstret