Reviderad: December 11, 2020
Säger försökspersonerna sanningen?
Pålitligheten hos självrapporterade uppgifter är en akilleshäl för enkätundersökningar. Opinionsundersökningar visade till exempel att mer än 40procent av amerikanerna går i kyrkan varje vecka. Men genom att undersöka register över kyrkobesök drog Hadaway och Marlar (2005) slutsatsen att den faktiska besöksfrekvensen var mindre än 22 procent. I sitt banbrytande verk ”Everybody lies” fann Seth Stephens-Davidowitz (2017) rikligt med bevis för att visa att de flesta människor inte gör vad de säger och inte säger vad de gör. Som svar på opinionsundersökningar förklarade de flesta väljare till exempel att kandidatens etnicitet är oviktig. Men genom att kontrollera söktermer i Google fann Sephens-Davidowitz det motsatta.Särskilt när Google-användare skrev in ordet ”Obama” associerade de alltid hans namn med vissa ord som hade med ras att göra.
För forskning om webbaserad undervisning kan uppgifter om webbanvändning erhållas genom att analysera användarens åtkomstlogg, ställa in cookies eller ladda upp cacheminnet. Dessa alternativ kan dock ha begränsad användbarhet. Till exempel kan användarloggen inte spåra användare som följer länkar till andra webbplatser. Dessutom kan cookies eller cacheminnen ge upphov till problem med integriteten. I dessa situationer används självrapporterade uppgifter som samlas in genom undersökningar. Detta ger upphov till frågan: Hur exakta är de självrapporterade uppgifterna? Cook och Campbell (1979) har påpekat att försökspersonerna (a) tenderar att rapportera vad de tror att forskaren förväntar sig att se, eller (b) rapporterar vad som återspeglar deras egna förmågor, kunskaper, övertygelser eller åsikter på ett positivt sätt. Ett annat problem med sådana uppgifter handlar om huruvida försökspersonerna kan minnas tidigare beteenden på ett korrekt sätt. Psykologer har varnat för att det mänskliga minnet är felfritt (Loftus, 2016; Schacter, 1999). Ibland ”minns” människor händelser som aldrig inträffade. Därför är tillförlitligheten hos självrapporterade uppgifter svag.Och även om statistiska programvarupaket kan beräkna tal med upp till 16-32 decimaler är denna precision meningslös om uppgifterna inte kan vara exakta ens på heltalsnivå. En hel del forskare hade varnat forskare för hur mätfel kan lamslå statistisk analys (Blalock, 1974) och föreslagit att god forskningspraxis kräver granskning av kvaliteten på de insamlade uppgifterna (Fetter, Stowe, & Owings, 1984).
Bias och varians
Mätfel omfattar två komponenter, nämligen bias och variabelt fel.Bias är ett systematiskt fel som tenderar att driva det rapporterade resultatet mot den ena extrema sidan. Till exempel har flera versioner av IQ-tester visat sig vara snedvridna mot icke-vita personer. Det innebär att svarta och latinamerikaner tenderar att få lägre poäng oavsett deras faktiska intelligens. Ett variabelt fel, även kallat varians, tenderar att vara slumpmässigt. Med andra ord kan de rapporterade resultaten vara antingen över eller under de faktiska resultaten (Salvucci, Walter, Conley, Fink, & Saba, 1997).
Fyndet av dessa två typer av mätfel har olika implikationer. I en studie som jämförde självrapporterade uppgifter om längd och vikt med direkt uppmätta uppgifter (Hart & Tomazic, 1999) fann man till exempel att försökspersonerna tenderar att överrapportera sin längd men underrapportera sin vikt. Det är uppenbart att denna typ av felmönster är fördomar snarare än varians. En möjlig förklaring till denna bias är att de flesta människor vill presentera en bättre fysisk bild för andra. Om mätfelet är slumpmässigt kan dock förklaringen vara mer komplicerad.
Man kan hävda att variabla fel, som är slumpmässiga till sin natur, skulle utjämna varandra och därmed inte utgöra något hot mot studien. Exempelvis kan den första användaren överskatta sin Internetaktivitet med 10 %, men den andra användaren kan underskatta sin med 10 %. I detta fall kan medelvärdet fortfarande vara korrekt. Över- och underskattning ökar dock variabiliteten i fördelningen. I många parametriska test används variabiliteten inom gruppen som felterm. En förhöjd variabilitet skulle definitivt påverka testets signifikans. Vissa texter kan förstärka denna missuppfattning. Deese (1972) sade till exempel följande:
Statistisk teori säger oss att sannolikheten för observationer är proportionell mot kvadratroten av deras antal. Ju fler observationer det finns, desto mer slumpmässig påverkan finns det. Och den statistiska teorin säger att ju fler slumpmässiga fel det finns, desto mer är det troligt att de upphäver varandra och ger en normalfördelning (s.55).
För det första är det sant att fördelningens varians minskar när urvalsstorleken ökar, men det garanterar inte att fördelningens form närmar sig normalitet. För det andra bör tillförlitligheten (uppgifternas kvalitet) vara knuten till mätning snarare än till bestämning av urvalsstorlek. Ett stort urval med många mätfel, även slumpmässiga fel, skulle blåsa upp feltermen för parametriska tester.
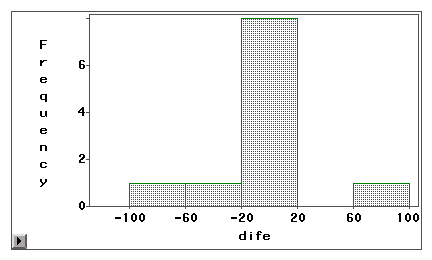
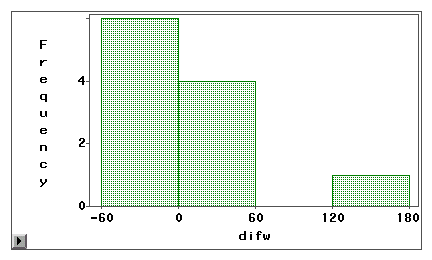
En stam- och bladdiagram eller ett histogram kan användas för att visuellt undersöka om ett mätfel beror på systematisk bias eller slumpmässig varians. I följande exempel mäts två typer av tillgång till Internet (webbsurfning och e-post) med hjälp av både självrapporterad enkät och loggbok. Skillnadsvärdena (mätning 1 – mätning 2) visas i följande histogram.
Det första diagrammet visar att de flesta skillnadsvärdena är centrerade kring noll. Underrapportering och överrapportering förekommer i båda ändarna, vilket tyder på att mätfelet är ett slumpmässigt fel snarare än en systematisk bias.
Den andra grafen visar tydligt att det finns en hög grad av mätfel eftersom mycket få differenspoäng är centrerade kring noll. Dessutom är fördelningen negativt skev och det tyder på att felet är bias istället för varians.
Hur tillförlitligt är vårt minne?
Schacter (1999) varnade för att det mänskliga minnet är felbart. Det finns sju brister i vårt minne:
- Förgänglighet: Minskad tillgänglighet av information med tiden.
- Absent-mindedness: Ouppmärksam eller ytlig bearbetning som bidrar till svaga minnen.
- Blockering: Den tillfälliga otillgängligheten för information som lagras i minnet.
- Felaktig tillskrivning Att tillskriva ett minne eller en idé till fel källa.
- Suggestibilitet: Minnen som implanteras som ett resultat av ledande frågor eller förväntningar.
- Fördomar: Retrospektiva förvrängningar och omedvetna influenser som är relaterade till nuvarande kunskaper och övertygelser.
- Persistens: Patologiska minnen – information eller händelser som vi inte kan glömma, även om vi önskar att vi kunde det.
 |
”I have norecollection of these. Jag minns inte att jag undertecknade dokumentet för Whitewater. Jag minns inte varför dokumentet försvann men återkom senare. Jag minns ingenting.” ”Jag minns att jag landade (i Bosnien) under krypskytteeld. Det var meningen att det skulle vara någon slags hälsningsceremoni på flygplatsen, men i stället sprang vi bara med huvudet nedåt för att komma in i fordonen för att ta oss till vår bas.” Under utredningen av att ha skickat hemlig information via en personlig e-postserver berättade Clinton för FBI att hon inte kunde ”minnas” eller ”minnas” någonting 39 gånger. Försiktighet: Ett nytt datavirus med namnet ”Clinton” har upptäckts. Om datorn är infekterad kommer den ofta att visa meddelandet ”out of memory”, även om den har tillräckligt med RAM-minne. |
| F: ”Om Vernon Jordon har berättat för oss att ni har ett utomordentligt bra minne, ett av de bästa minnen som han någonsin sett hos en politiker, är detta något ni skulle vilja bestrida?”
A: ”Jag har ett bra minne … Men jag minns inte om jag var ensam med Monica Lewinsky eller inte. Hur skulle jag kunna hålla reda på så många kvinnor i mitt liv?” Q: Varför rekommenderade Clinton Lewinsky för ett jobb på Revlon? A: Han visste att hon skulle vara bra på att hitta på saker. |
 |
Det är viktigt att notera att ibland är tillförlitligheten i vårt minne knutet till önskvärdheten av resultatet. När en medicinsk forskare till exempel försöker samla in relevanta uppgifter från mödrar vars barn är friska och mödrar vars barn är missbildade, är uppgifterna från de sistnämnda vanligtvis mer exakta än från de förstnämnda. Detta beror på att mödrar till missbildade barn noggrant har gått igenom varje sjukdom som inträffat under graviditeten, varje läkemedel som tagits, varje detalj som direkt eller på avstånd är relaterad till tragedin i ett försök att hitta en förklaring. Mammor till friska spädbarn ägnar däremot inte mycket uppmärksamhet åt den föregående informationen (Aschengrau & SeageIII, 2008). Att blåsa upp GPA är ett annat exempel på hur önskvärdhet påverkar minnesnoggrannheten och dataintegriteten. I vissa situationer finns det en könsskillnad när det gäller uppblåsning av GPA. I en studie utförd av Caskie etal. (2014) fann att inom gruppen av studenter med lägre GPA på grundnivå var det mer sannolikt att kvinnor än män rapporterade ett högre GPA än det faktiska än män.
För att motverka problemet med minnesfel föreslog vissa forskare att man skulle samla in data som rörde deltagarens ögonblickliga tankar eller känslor i stället för att be honom eller henne att minnas avlägsna händelser (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Följande exempel är enkätfrågor i 2018 Programme forInternational Student Assessment: ”Blev du behandlad med respekt hela dagen igår?” ”Leende eller skrattade du mycket igår?” ”Lärde du dig eller gjorde du något intressant igår?” (Organisationen för ekonomiskt samarbete och utveckling, 2017). Svaret beror dock på vad som hände med deltagaren i just det ögonblicket, vilket kanske inte är typiskt. Även om den svarande inte log eller skrattade mycket igår innebär det inte nödvändigtvis att den svarande alltid är olycklig.
Vad ska vi göra?
En del forskare förkastar användningen av självrapporterade uppgifter på grund av deras påstått dåliga kvalitet. När en grupp forskare till exempel undersökte om hög religiositet ledde till mindre följsamhet till skyddsrumsdirektiv i USA under COVID19-pandemin, använde de sig av antalet församlingar per 10 000 invånare som ett proxymått för regionens religiositet, i stället för självrapporterad religiositet, som tenderar att återspegla social önskvärdhet (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
Chan (2009) hävdade dock att den så kallade dåliga kvaliteten på självrapporterade uppgifter inte är något annat än en urban legend. Drivna av social önskvärdhet kan respondenterna ge forskarna felaktiga uppgifter vid vissa tillfällen, men det händer inte hela tiden. Det är till exempel osannolikt att respondenterna skulle ljuga om sina demografiska uppgifter, såsom kön och etnicitet. För det andra är det sant att respondenterna tenderar att förvränga sina svar i experimentella studier, men detta problem är mindre allvarligt när det gäller åtgärder som används i fältstudier och naturalistiska miljöer. Det finns dessutom ett stort antal väletablerade självrapporterade mått på olika psykologiska konstruktioner som har fått bevis för konstruktionsvaliditet genom både konvergent och diskriminerande validering. Till exempel Big-five personlighetsdrag, proaktiv personlighet, affektivitetsdisposition, self-efficacy, målinriktning, upplevt organisatoriskt stöd och många andra.Inom området epidemiologi hävdade Khoury, James och Erickson (1994) att effekten av minnesbias överskattas. Men deras slutsats kanske inte kan tillämpas väl på andra områden, t.ex. utbildning och psykologi.Trots hotet om felaktiga uppgifter är det omöjligt för forskaren att följa varje försöksperson med en videokamera och spela in allt de gör. Forskaren kan dock använda sig av en delmängd av försökspersonerna för att få observerade data, t.ex. användarloggar eller dagliga pappersloggar över webbåtkomst. Resultaten kan sedan jämföras med resultatet av alla försökspersoners självrapporterade uppgifter för en uppskattning av mätfelet.
- När forskaren har tillgång till användarloggen kan han be försökspersonerna att rapportera hur ofta de går in på webbservern.Försökspersonerna bör inte informeras om att deras Internetaktiviteter har loggats av webbansvarig, eftersom detta kan påverka deltagarnas beteende.
- Forskaren kan be en delmängd användare att föra en loggbok över sina internetaktiviteter under en månad. Därefter ombeds sammaanvändare att fylla i en enkät om sin internetanvändning.
Någon kan hävda att loggboksmetoden är alltför krävande. I många vetenskapliga forskningsstudier frågas försökspersonerna faktiskt efter mycket mer än så. När forskarna till exempel studerade hur djup sömn under långväga rymdresor skulle påverka människors hälsa, ombads deltagarna att ligga i sängen i en månad. I en studie om hur en sluten miljö påverkar människans psykologi under rymdresor låstes försökspersonerna också in i ett rum enskilt i en månad. Det kostar mycket att söka efter vetenskapliga sanningar.
När olika datakällor har samlats in kan diskrepansen mellan loggboken och de självrapporterade uppgifterna analyseras för att uppskatta uppgifternas tillförlitlighet. Vid första anblicken ser detta tillvägagångssätt ut som en test-retestreliabilitet, men det är det inte. För det första ska det instrument som används i två eller flera situationer vara detsamma som vid test-retest reliabilitet. För det andra, när test-retest-tillförlitligheten är låg är felkällan inom instrumentet. När felkällan är extern till instrumentet, t.ex. mänskliga fel, är dock interbedömarreliabilitet mer lämplig.
Det ovan föreslagna förfarandet kan konceptualiseras som en mätning av interdata-reliabilitet, som liknar den för interbedömarreliabilitet och upprepade åtgärder. Det finns fyra sätt att uppskatta interbedömarreliabiliteten, nämligen Kappa-koefficienten, indexet för inkonsekvens, ANOVA för upprepade åtgärder och regressionsanalys. I följande avsnitt beskrivs hur dessa mätningar av tillförlitligheten mellan olika bedömare kan användas som mätningar av tillförlitligheten mellan data.
Kappakoefficient
I psykologisk och pedagogisk forskning är det inte ovanligt att använda två eller flera bedömare i mätningsprocessen när bedömningen inbegriper subjektiva bedömningar (t.ex. betygsättning av uppsatser). Tillförlitligheten mellan bedömare, som mäts med Kappa-koefficienten, används för att ange uppgifternas tillförlitlighet.Till exempel betygsätts deltagarnas prestationer av två eller flera bedömare som ”mästare” eller ”icke-mästare” (1 eller 0). Därför beräknas detta mått vanligtvis i kategoriska dataanalysförfaranden som PROC FREQ i SAS, ”measurement of agreement” i SPSS eller en Kappa-kalkylator online (Lowry, 2016). Bilden nedan är en skärmdump av Vassarstats online-kalkylator.
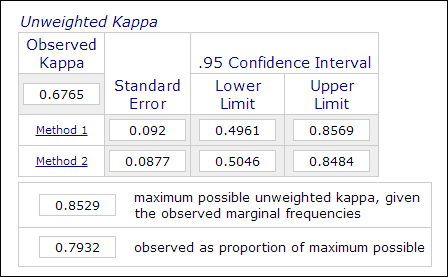
Det är viktigt att notera att även om 60 procent av två datamängder överensstämmer med varandra betyder det inte att mätningarna är tillförlitliga.Eftersom utfallet är dikotomt finns det en 50-procentig chans att de två mätningarna överensstämmer. Kappa-koefficienten tar hänsyn till detta och kräver en högre grad av överensstämmelse för att uppnå konsistens.
I samband med webbaserad undervisning kan varje kategori av självrapporterad webbplatsanvändning omkodas till en binär variabel. Till exempel, när fråga ett är ”hur ofta använder du telnet” är de möjliga kategoriska svaren ”a: dagligen”, ”b: tre till fem gånger per vecka”, ”c: tre till fem gånger per månad”, ”d: sällan” och ”e: aldrig”. I detta fall kan de fem kategorierna kodas om till fem variabler: Q1A, Q1B, Q1C, Q1D och Q1E. Sedan kan alla dessa binära variabler läggas till för att bilda en R X 2-tabell enligt följande tabell: Med denna datastruktur kan svaren kodas som ”1” eller ”0”, vilket gör det möjligt att mäta klassificeringsöverensstämmelsen. Överensstämmelsen kan beräknas med hjälp av Kappa-koefficienten och därmed kan uppgifternas tillförlitlighet uppskattas.
Subjekt Loggboksdata Själv-rapportdata Föremål 1 1 1 1 Föremål 2 0 0 Subjekt 3 1 0 0 Subjekt 4 0 1 Index för inkonsekvens
Ett annat sätt att beräkna ovannämnda kategoriska data är index för inkonsekvens (IOI). Eftersom det i exemplet ovan finns två mätningar (loggboksdata och självrapporterade data) och fem svarsalternativ, bildas en 4 x 4 tabell. Det första steget för att beräkna IOI är att dela upp RXC-tabellen i flera 2X2-undertabeller. Till exempel behandlas det sista alternativet ”aldrig” som en kategori och alla övriga alternativ sammanfattas i en annan kategori som ”inte aldrig”, vilket visas i följande tabell.
Själv-rapporterade uppgifter Log Ingen Inte aldrig Total Ingen a b a+b Inte aldrig c d c+d Total a+c b+d n=Summa(a-d) Den procentuella andelen IOI beräknas enligt följande formel:
IOI% = 100*(b+c)/ där p = (a+c)/n
När IOI har beräknats för varje 2X2-deltabell används ett genomsnitt av alla index som en indikator på åtgärdens inkonsekvens. Kriteriet för att bedöma om uppgifterna är konsekventa är följande:
- En IOI på mindre än 20 är låg varians
- En IOI mellan 20 och 50 är måttlig varians
- En IOI över 50 är hög varians
Dataens tillförlitlighet uttrycks i denna ekvation: r = 1 – IOI
Intraklass korrelationskoefficient
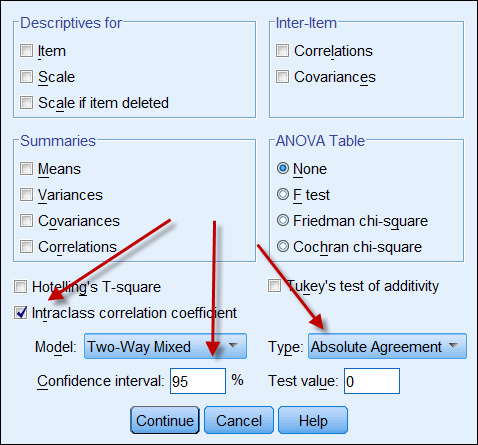
Om båda datakällorna ger kontinuerliga uppgifter kan man beräkna intraklass korrelationskoefficienten för att ange uppgifternas tillförlitlighet. Följande är en skärmdump av SPSS alternativ för ICC. I Typ finns två alternativ: ”konsistens” och ”absolut överensstämmelse”. Om ”konsistens” väljs, även om en uppsättning siffror har hög konsistens (t.ex. 9, 8, 9, 8, 8, 7…) och den andra har låg konsistens (t.ex. 4, 3, 4, 3, 2…), innebär deras starka korrelation felaktigt att uppgifterna stämmer överens med varandra. Det är därför lämpligt att välja ”absolut överensstämmelse”.
Repeterade åtgärder
Mätningen av tillförlitligheten mellan data kan också konceptualiseras och proceduraliseras som enANOVA med upprepade åtgärder. I en ANOVA med upprepade åtgärder ges mätningar till samma försökspersoner flera gånger, t.ex. förtest, halvtid och eftertest. I det här sammanhanget mäts försökspersonerna också upprepade gånger med hjälp av webbanvändarloggen, loggboken och den självrapporterade undersökningen. Följande är SAS-koden för en ANOVA med upprepade åtgärder:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
I ovanstående program registreras antalet besökta webbplatser av nio frivilliga i loggboken, den personliga loggboken och den självrapporterade undersökningen. Användarna behandlas som en faktor mellan subjekten medan de tre åtgärderna betraktas som en faktor mellan åtgärderna. Följande är ett komprimerat resultat:
Variationskälla DF Medelkvadrat Between-subject (user) 8 10442.50 Mellan-mått (tid) 2 488.93 Residual 16 454.80 Baserat på ovanstående information kan tillförlitlighetskoefficienten beräknas med hjälp av denna formel (Fisher, 1946; Horst, 1949):
r = MSbetween-measure – MSresidual ————————————————————– MSbetween-measure + (dfbetween-people X MSresidual) Låt oss sätta in siffran i formeln:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) Säkerheten är cirka 0,0008, vilket är extremt lågt. Därför kan vi gå hem och glömma uppgifterna. Lyckligtvis är det bara en hypotetisk datamängd. Men vad händer om det är en riktig datamängd? Man måste vara tillräckligt tuff för att ge upp dåliga data i stället för att publicera resultat som är helt opålitliga.
Korrelations- och regressionsanalys
Korrelationsanalys, som använder Pearsons produktmomentkoefficient, är mycket enkel och särskilt användbar när skalorna för två mätningar inte är desamma. Till exempel kan webbserverloggen spåra antalet sidtillträden medan de självrapporterade uppgifterna har en stegskala (t.ex. hur ofta surfar du på Internet? 5 = mycket ofta, 4 = ofta, 3 = ibland, 2 = sällan, 5 = aldrig). I detta fall kan de självrapporterade värdena användas som en prediktor för att regressera mot sidtillgång.
En liknande metod är regressionsanalys, där en uppsättning poäng (t.ex. enkätdata) behandlas som prediktor medan en annan uppsättning poäng (t.ex. användarens dagliga logg) betraktas som den beroende variabeln. Om fler än två mått används kan en multipel regressionsmodell tillämpas, dvs. det mått som ger ett mer exakt resultat (t.ex. loggbok för webbanvändare) betraktas som den beroende variabeln och alla andra mått (t.ex. daglig loggbok för användare, enkätdata) behandlas som oberoende variabler.
Referens
- Aschengrau, A., & Seage III, G. (2008). Epidemiologi inom folkhälsan. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Red.) Measurement in the social sciences: Theories and strategies. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Noggrannhet av självrapporterat college GPA: Gender-moderateddifferences by achievement level and academic self-efficacy. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Så varför frågar du mig? Är självrapporteringsuppgifter verkligen så dåliga? I Charles E. Lance och Robert J. Vandenberg (red.), Statistical and methodological myths and urban legends: Doktrin, sanning och fabler inom organisations- och samhällsvetenskaperna (s. 309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasiexperiment: Design and analysis issues. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validitet och tillförlitlighet hos metoden för erfarenhetsurval. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psykologi som vetenskap och konst. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, 10 augusti). Religion och reaktion på COVID-19mitigationsriktlinjer. American Psychologist. Förhands publicering online. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). High School and Beyond. A national longitudinal study for the 1980s, quality of responses of high school students to questionnaire items. (NCES 84-216).Washington, D.C.: U.S. Department of Education. Office of EducationalResearch and Improvement (kontor för utbildningsforskning och förbättring). National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). Den inkrementella validiteten av genomsnittliga självrapporteringar av tillstånd över globala självrapporteringar av personlighet. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistical methods for research workers (10th ed.). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Hur mångaAmerikaner deltar i gudstjänst varje vecka? Ett alternativt tillvägagångssätt för mätning? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 August). Jämförelse av percentilfördelningar för antropometriska mått mellan tre dataset. Konferensbidrag vid Annual Joint Statistical Meeting, Baltimore, MD.
- Horst, P. (1949). Ett generaliserat uttryck för tillförlitligheten hos mått. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). Om användningen av påverkade kontroller för att hantera minnesbias i fall-kontrollstudier av fosterskador. Teratology, 49, 273-281.
- Loftus, E. (2016, april). Minnets fiktion. Konferensbidrag presenterat vid Western Psychological Association Convention. Long Beach, CA.
- Lowry, R. (2016). Kappa som ett mått på överensstämmelse vid kategorisk sortering. Hämtad från http://vassarstats.net/kappa.html
- Organisationen för ekonomiskt samarbete och utveckling. (2017). Frågeformulär om välbefinnande för PISA 2018. Paris: Författare. Hämtad från https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Minnets sju synder: Insights from psychology and cognitive neuroscience. American Psychology, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Studier av mätfel vid National Center for Education Statistics. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Everybody lies: Big data, new data, and what the Internet can tell us about who we really are. New York, NY: Dey Street Books.
 Gå upp till huvudmenyn
Gå upp till huvudmenyn Andra kurserSökmotor
|

Kontakta mig
|