Metod 1, dåligt: ORDER BY NEWID()
Lätt att skriva, men den fungerar som hett, hett skräp eftersom den skannar hela det klustrade indexet och beräknar NEWID() för varje rad:
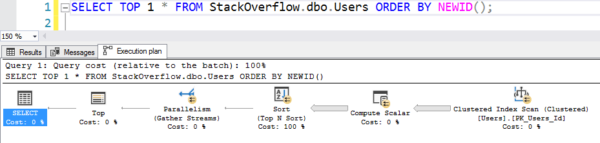
Planen med skanningen
Det tog 6 sekunder på min maskin, parallellt i flera trådar, vilket använde tiotals sekunder av processorn för all beräkning och sortering. (Och tabellen Users är inte ens 1 GB stor.)
Metod 2, bättre men konstig: TABLESAMPLE
Denna metod kom ut 2005 och har en massa problem. Det handlar om att välja en slumpmässig sida och sedan returnera en massa rader från den sidan. Den första raden är ganska slumpmässig, men resten är det inte.
Transact-SQL
|
1
|
SELECT * FROM StackOverflow.dbo.Users TABLESAMPLE (.01 PERCENT);
|
Planen ser ut att göra en tabellskanning, men den gör bara 7 logiska läsningar:
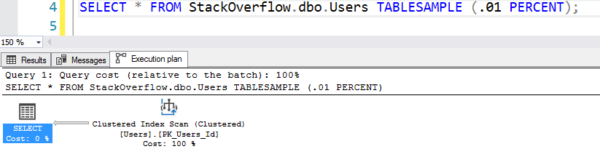
Planen med den falska skanningen
Men här är resultaten – du kan se att den hoppar till en slumpmässig 8K-sida och börjar sedan läsa ut rader i ordning. Det är inte riktigt slumpmässiga rader.
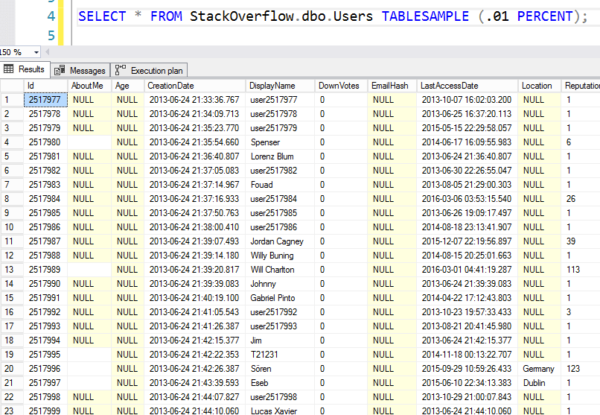
Slumpmässigt som maffialotteriets nummer
Du kan använda ROWS-urvalsstorlek i stället, men det ger några ganska märkliga resultat. I tabellen Stack Overflow Users fick jag till exempel 75 rader tillbaka när jag sa TABLESAMPLE (50 ROWS). Det beror på att SQL Server omvandlar radstorleken till en procentsats istället.
Metod 3, bäst men kräver kod: Random Primary Key
Hämta det översta ID-fältet i tabellen, generera ett slumpmässigt nummer och leta efter detta ID. Här sorterar vi efter ID eftersom vi vill hitta den översta posten som faktiskt finns (medan ett slumpmässigt nummer kan ha raderats.) Ganska snabbt, men är bara bra för en enda slumpmässig rad. Om du vill ha 10 rader måste du anropa kod som denna 10 gånger (eller generera 10 slumpmässiga nummer och använda en IN-klausul).)
Exekveringsplanen visar en klustrad indexavläsning, men den tar bara en rad – vi pratar bara om 6 logiska läsningar för allt du ser här, och den avslutas nästan ögonblickligen:

Planen som kan
Det finns en hake: om Id:et har negativa siffror kommer det inte att fungera som förväntat. (Säg till exempel att du börjar ditt identitetsfält på -1 och tar ett steg på -1 och går nedåt, precis som min moral.)
Metod 4, OFFSET-FETCH (2012+)
Daniel Hutmacher lade till den här i kommentarerna:
Och sa: ”Men det fungerar bara ordentligt med ett klusterindex. Jag gissar att det beror på att den söker efter (@rows) rader i en heap istället för att göra en indexsökning.”
Bonusspår #1:
Har du någonsin undrat hur det är att vara i vårt företags chattrum? Den här 10 minuter långa Slack-diskussionen ger dig en ganska bra uppfattning:
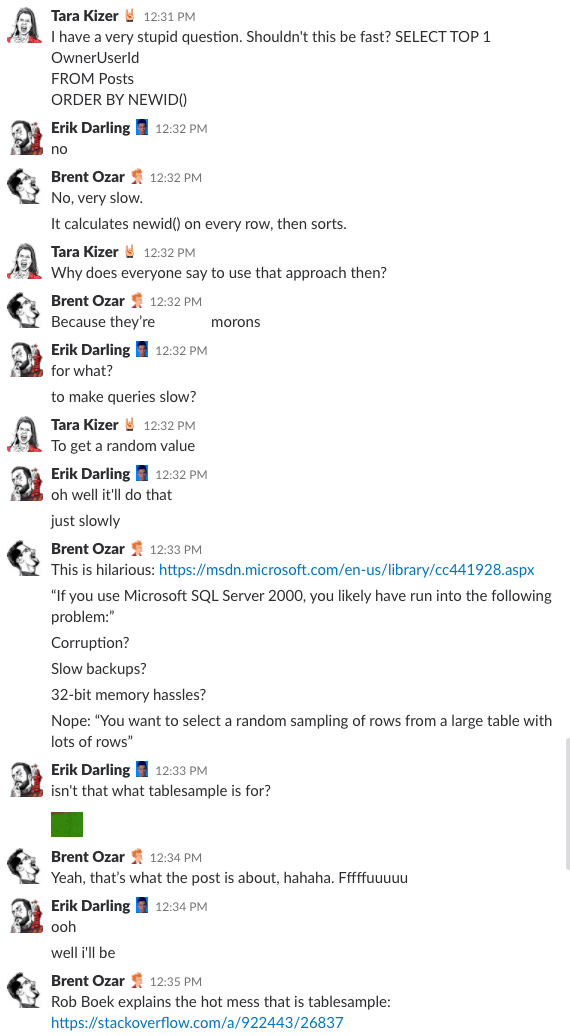
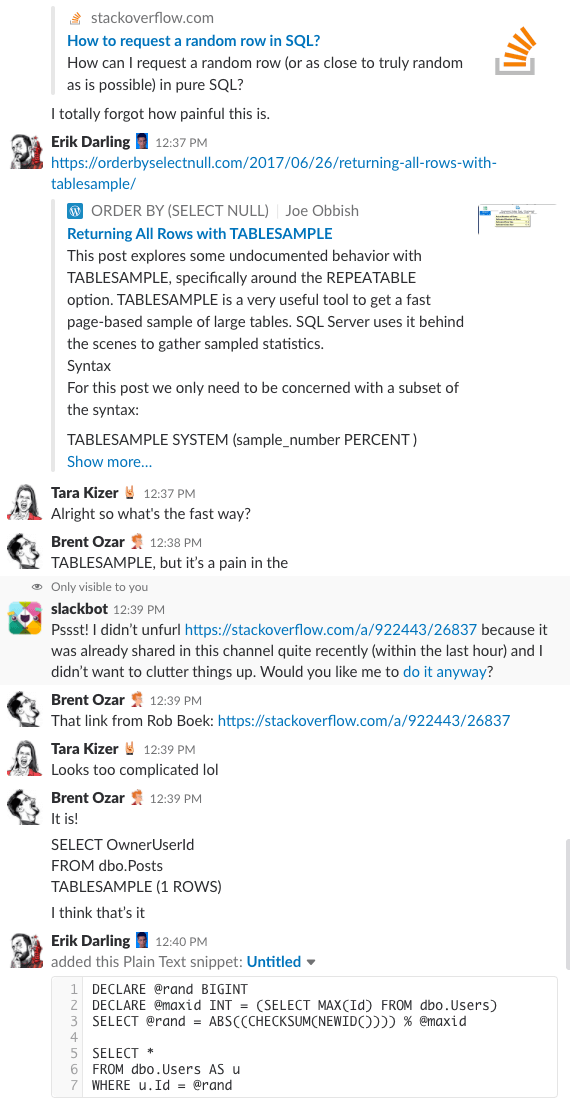
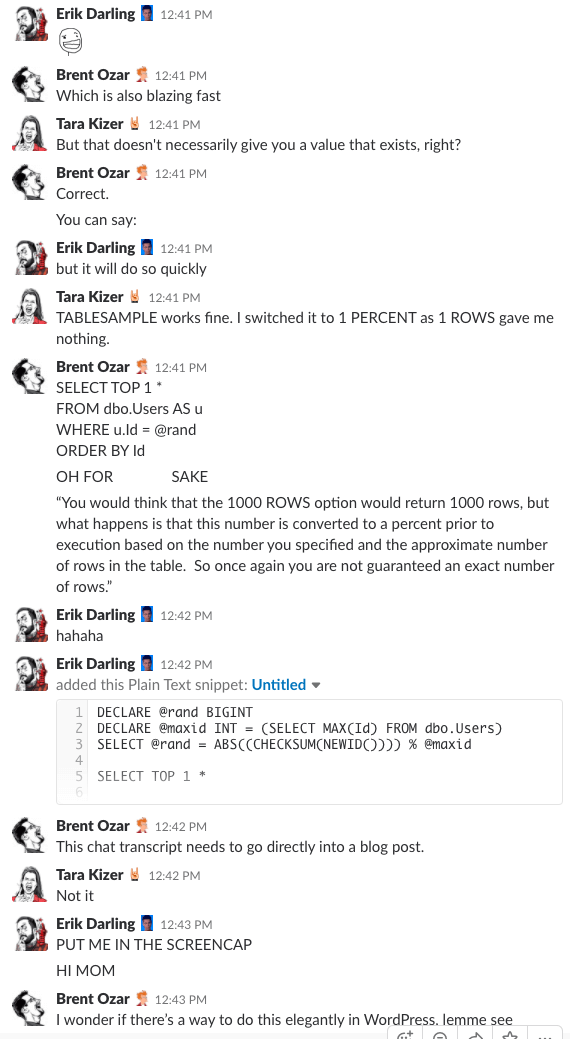
Spoiler alert: det fanns inte. Jag tog bara skärmdumpar.
Bonus Track #2: Mitch Wheat Digs Deeper
Vill du ha en djupgående analys av slumpmässigheten i flera olika tekniker? Mitch Wheat dyker riktigt djupt, komplett med grafer!