Introduktion Den här handledningen visar hur man hittar och eventuellt tar bort liknande eller dubbla sidor i samma PDF-dokument med hjälp av insticksprogrammet AutoSplit™ för Adobe® Acrobat®. Denna operation upptäcker liknande sidor och presenterar dem för användaren för en granskning. Användaren kan granska resultaten och välja/avmarkera enskilda sidor från listan över dubbletter för att eventuellt radera eller extrahera dem. Du kan utföra följande åtgärder:
- Hitta dubbletter och nära-dubbletter
- Bokmärka dubbletter
- Extrahera dubbletter till ett separat PDF-dokument
- Ta bort dubbletter från dokumentet
- Spara rapport om sidors likhet
Plug-in-modulen tillhandahåller två olika metoder för att upptäcka dubbletter eller nära-dubbletter: Jämför endast sidtext Använd den här metoden för att jämföra sidtexten oberoende av dess visuella utseende. Den beräknar sidans likhet baserat på enbart textinnehåll och ignorerar helt textutseende, layout, bilder och grafik som kan finnas på sidan. Det är den bästa metoden för att upptäcka dubbletter i de flesta dokumenttyper. Jämför sidornas visuella utseende Denna metod jämför sidor ”som bilder” och upptäcker sidor som ser exakt likadana ut. Denna metod jämför inte osynlig text som kan finnas på sidan. Det rekommenderas inte att använda den här metoden på skannade pappersdokument. Användning av skannade pappersdokument Ganska ofta används den här åtgärden för att hitta dubbla sidor i de skannade pappersdokumenten. De skannade dokumenten måste OCR-behandlas innan de används för någon textbaserad behandling. OCR är en process för att känna igen text i skannade dokument och göra dem sökbara. Det är viktigt att förstå att textigenkänning i skannade dokument är känslig för fel och att den sällan är 100 % korrekt. Antalet fel beror på skanningsupplösningen och originaldokumentets kvalitet. I de vanligaste fallen kan en skannad sida innehålla mellan 1 och 10 igenkänningsfel där vissa bokstäver identifieras felaktigt. Beroende på typsnittet kan t.ex. den lilla bokstaven l se ut exakt som siffran 1 . Den stora bokstaven O identifieras ofta felaktigt som siffran 0, eller den stora bokstaven S som siffran 5 osv. Eftersom många alfanumeriska symboler har liknande eller identiska fysiska egenskaper är det ofta svårt att skilja dem åt. Det är därför en likhetsbaserad jämförelse är användbar för att upptäcka små skillnader mellan sidor som produceras av textigenkänningsprocessen. Skannade dokument av låg kvalitet kan innehålla ett stort antal fel som gör dem oanvändbara för en tillförlitlig textbaserad jämförelse. Se följande handledning om hur man kan OCR-skanna dokument och bedöma deras lämplighet för textbaserad behandling. . Förutsättningar Du behöver en kopia av Adobe® Acrobat® tillsammans med insticksprogrammet AutoSplit™ installerat på din dator för att kunna använda den här handledningen. Du kan ladda ner testversioner av både Adobe® Acrobat® och AutoSplit™-plugin. Innehåll
- Genom att jämföra endast sidtext
- Genom att jämföra endast visuellt utseende
- Genom att jämföra flera dokument
Metod 1 – Jämförelse av endast sidtext översikt Med denna metod jämförs sidors likhet endast baserat på deras sidinnehåll. Det visuella utseendet, textens placering och ordningsföljd är irrelevanta. Denna metod ignorerar också eventuella bilder och grafik som finns på sidorna. Den modifierade cosinolikhetsmetoden används för att beräkna hur lika två sidor är varandra på grundval av deras textinnehåll. Steg 1 – Öppna en PDF-fil Starta programmet Adobe® Acrobat® och öppna en PDF-fil med hjälp av menyn ”File > Open…”..PNG) Steg 2 – Öppna dialogrutan ”Find Duplicate Pages” Välj ”Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” för att öppna dialogrutan ”Find Duplicate Pages”.
Steg 2 – Öppna dialogrutan ”Find Duplicate Pages” Välj ”Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” för att öppna dialogrutan ”Find Duplicate Pages”..PNG) Steg 3 – Ange inställningar Markera alternativet ”Compare only page text (ignore visual appearance of the pages)”.
Steg 3 – Ange inställningar Markera alternativet ”Compare only page text (ignore visual appearance of the pages)”..PNG) Användning av fördefinierade inställningar Den textbaserade metoden tillhandahåller ett antal fördefinierade parameteruppsättningar som är lämpliga för att jämföra olika typer av dokument med olika mängd igenkänningsfel. Varje fördefinierad uppsättning parametrar ger olika förutsättningar för likhetsberäkningar:
Användning av fördefinierade inställningar Den textbaserade metoden tillhandahåller ett antal fördefinierade parameteruppsättningar som är lämpliga för att jämföra olika typer av dokument med olika mängd igenkänningsfel. Varje fördefinierad uppsättning parametrar ger olika förutsättningar för likhetsberäkningar:
- Anpassade inställningar – alla inställningar anges av användaren
- Skannat pappersdokument: Hög kvalitet
- Skannat pappersdokument: Medium Quality
- Faxdokument: Low Quality
- Non-scanned PDF: exact match
- Non-scanned PDF: fuzzy match
- Exact match (with text order)- this method does not use cosine similarity
.PNG) Inställningarna visas under menyn efter att ha valt en fördefinierad parameteruppsättning.
Inställningarna visas under menyn efter att ha valt en fördefinierad parameteruppsättning..PNG) Här visas de inställningar som används av de fördefinierade uppsättningarna:
Här visas de inställningar som används av de fördefinierade uppsättningarna:.PNG) Klicka på ”Redigera…” för att anpassa inställningarna för sidans likhet:
Klicka på ”Redigera…” för att anpassa inställningarna för sidans likhet:.PNG) Metoden för textjämförelse använder 3 parametrar för att begränsa hur olika två ”liknande” sidor kan vara. Genom att variera dessa parametrar är det möjligt att upptäcka sidor som har olika grad av likhet.
Metoden för textjämförelse använder 3 parametrar för att begränsa hur olika två ”liknande” sidor kan vara. Genom att variera dessa parametrar är det möjligt att upptäcka sidor som har olika grad av likhet.
- Minimal tillåten textlikhet mellan sidor (i procent) – detta är värdet av cosinuslikhetsmetrin uttryckt i procent. Ange minsta tillåtna sidotextlikhet mellan 70 och 100 (i procent).
- Maximal tillåten skillnad i sidlängd (i tecken).
- Maximal tillåten skillnad i sidtext (i ord).
Använd dessa inställningar för att experimentera med bearbetningsinställningar när det är nödvändigt att justera bearbetningsalgoritmen för ett specifikt dokument..PNG) Använd exempelsidor Klicka valfritt på ”Set From Page Sample…” (Ställ in från sidprov…) för att ange inställningar för sidlikhet baserat på de två exempelsidorna:
Använd exempelsidor Klicka valfritt på ”Set From Page Sample…” (Ställ in från sidprov…) för att ange inställningar för sidlikhet baserat på de två exempelsidorna:
.PNG) Välj två sidor som kan betraktas som identiska. Programvaran beräknar automatiskt sidans likhet och statistiken visas i det vänstra nedre hörnet av dialogrutan. Klicka på ”OK” för att spara de aktuella inställningarna för likhet.
Välj två sidor som kan betraktas som identiska. Programvaran beräknar automatiskt sidans likhet och statistiken visas i det vänstra nedre hörnet av dialogrutan. Klicka på ”OK” för att spara de aktuella inställningarna för likhet..PNG) Ange alternativ för textfiltrering Det finns flera parametrar som styr det sidinnehåll som analyseras av algoritmen för textjämförelse. Använd dessa alternativ när du jämför skannade pappersdokument som kan innehålla olika textigenkänningsfel. Dessa alternativ utesluter vissa typer av tecken från behandling. I många fall kan det hjälpa till att beräkna ett mer exakt likhetsmått.
Ange alternativ för textfiltrering Det finns flera parametrar som styr det sidinnehåll som analyseras av algoritmen för textjämförelse. Använd dessa alternativ när du jämför skannade pappersdokument som kan innehålla olika textigenkänningsfel. Dessa alternativ utesluter vissa typer av tecken från behandling. I många fall kan det hjälpa till att beräkna ett mer exakt likhetsmått.
- Ignore text case – det här alternativet ignorerar textcase vid jämförelse av text.
- Ignore punctuation (,.!?-) – det här alternativet utesluter alla skiljetecken från jämförelsen.
- Ignore non-alphanumeric characters – det här alternativet ignorerar alla tecken utom bokstäver och siffror.
Klicka på ”OK” för att spara inställningarna för sidlikhet..PNG) Klicka på ”OK” för att börja söka efter dubbla sidor i det aktuella PDF-dokumentet:
Klicka på ”OK” för att börja söka efter dubbla sidor i det aktuella PDF-dokumentet:.PNG) Steg 4 – Inspektera dubbla sidor Dialogrutan ”Ta bort dubbla sidor” visar en lista över dubbla eller nästan dubbla sidor. Klicka på en sidpost för att visa motsvarande sida i visaren. Undersök sidorna och välj/avmarkera sidor för radering. Du kan också klicka på ”Save Report…” för att skapa en rapport om sidlikheter i HTML-format. Eller klicka på ”Bookmark Pages” för att skapa bokmärken i PDF för valda dubbelsidor.
Steg 4 – Inspektera dubbla sidor Dialogrutan ”Ta bort dubbla sidor” visar en lista över dubbla eller nästan dubbla sidor. Klicka på en sidpost för att visa motsvarande sida i visaren. Undersök sidorna och välj/avmarkera sidor för radering. Du kan också klicka på ”Save Report…” för att skapa en rapport om sidlikheter i HTML-format. Eller klicka på ”Bookmark Pages” för att skapa bokmärken i PDF för valda dubbelsidor..PNG) Plugin-modulen gör det möjligt att förhandsgranska/jämföra de hittade dubbla eller nästan dubbla sidorna. Sidans likhet (i %) och antalet ord som inte stämmer överens visas för varje par sidor. Här är de exempel som beräknats för paret av de skannade pappersdokumenten:
Plugin-modulen gör det möjligt att förhandsgranska/jämföra de hittade dubbla eller nästan dubbla sidorna. Sidans likhet (i %) och antalet ord som inte stämmer överens visas för varje par sidor. Här är de exempel som beräknats för paret av de skannade pappersdokumenten:.PNG)
.PNG) Observera att textens utseende och placering inte påverkar resultaten. Dessa två sidor anses vara identiska trots skillnaden i textfärg:
Observera att textens utseende och placering inte påverkar resultaten. Dessa två sidor anses vara identiska trots skillnaden i textfärg:.PNG) Dessa två sidor anses vara identiska trots skillnaden i innehållets layout:
Dessa två sidor anses vara identiska trots skillnaden i innehållets layout:.PNG) De här två sidorna anses vara 94 % lika trots skillnader i textordning, layout och avsaknad av bild:
De här två sidorna anses vara 94 % lika trots skillnader i textordning, layout och avsaknad av bild:.PNG) Steg 5 – Extrahera eller bokmärka dubbla sidor Du kan också använda knappen ”Bookmark Pages” för att bokmärka alla markerade sidor. Detta är användbart om du inte planerar att ta bort de hittade dubbla sidorna från dokumentet. Använd kryssrutorna framför sidorna för att välja/avmarkera dem från bearbetningsuppsättningen. Använd knappen ”Extract Pages….” för att extrahera alla markerade sidor till ett separat PDF-dokument. Denna operation tar inte bort sidor från det aktuella dokumentet.
Steg 5 – Extrahera eller bokmärka dubbla sidor Du kan också använda knappen ”Bookmark Pages” för att bokmärka alla markerade sidor. Detta är användbart om du inte planerar att ta bort de hittade dubbla sidorna från dokumentet. Använd kryssrutorna framför sidorna för att välja/avmarkera dem från bearbetningsuppsättningen. Använd knappen ”Extract Pages….” för att extrahera alla markerade sidor till ett separat PDF-dokument. Denna operation tar inte bort sidor från det aktuella dokumentet.
.PNG) Använd knappen ”Save Report…” (Spara rapport…) för att spara rapporten om beräkning av sidlikhet i en HTML-fil. Den innehåller detaljer om sidans likhet, visar skillnader mellan sidor och listar saknade ord. Den kan vara mycket användbar för den djupgående analysen.
Använd knappen ”Save Report…” (Spara rapport…) för att spara rapporten om beräkning av sidlikhet i en HTML-fil. Den innehåller detaljer om sidans likhet, visar skillnader mellan sidor och listar saknade ord. Den kan vara mycket användbar för den djupgående analysen.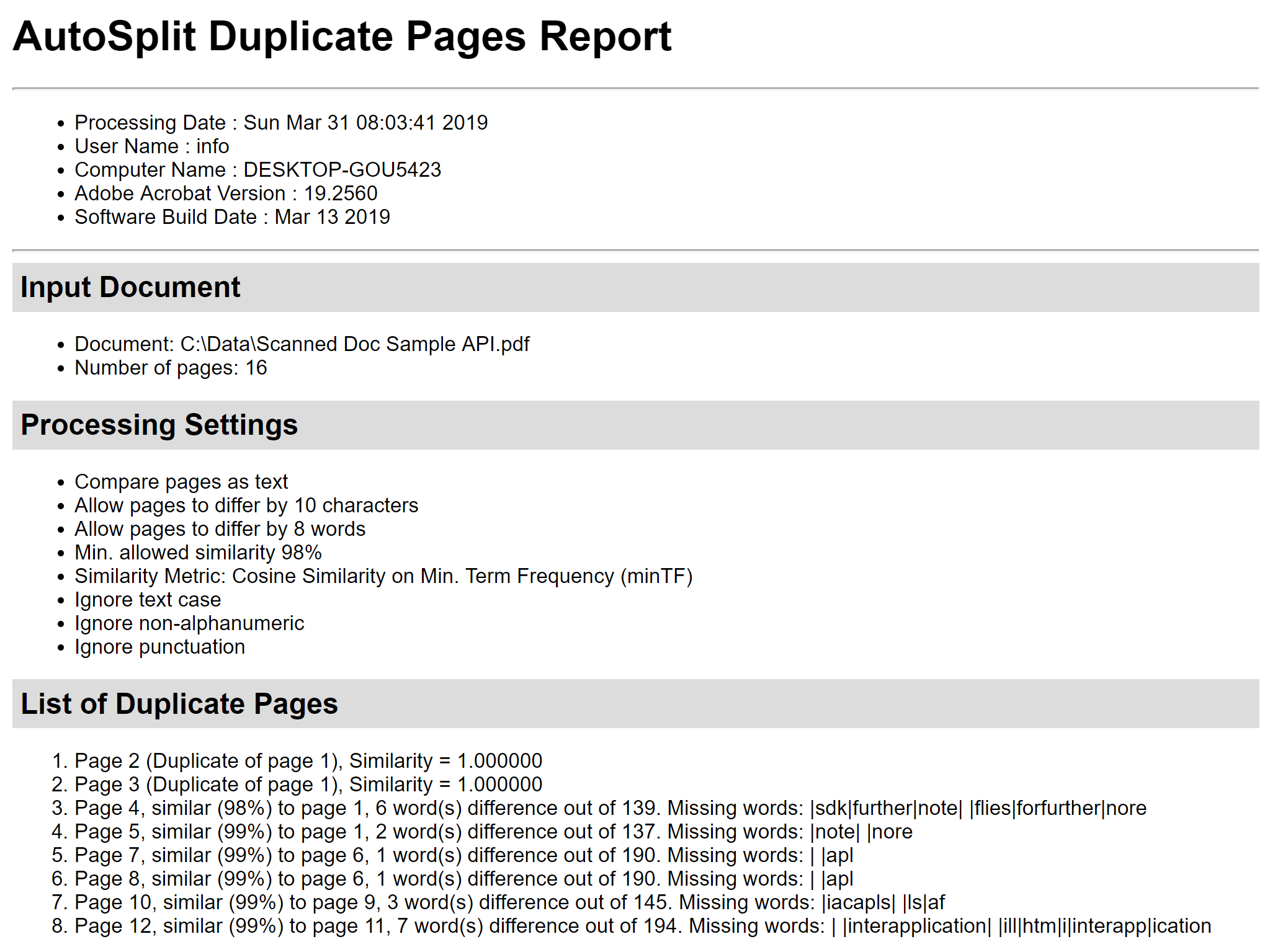 Steg 6 – Ta bort dubbla sidor Använd kryssrutorna framför sidorna för att välja/avmarkera sidor från att tas bort. Tryck på knappen ”Delete Pages” i dialogrutan ”Delete Duplicate Pages” för att ta bort alla markerade sidor från det aktuella PDF-dokumentet:
Steg 6 – Ta bort dubbla sidor Använd kryssrutorna framför sidorna för att välja/avmarkera sidor från att tas bort. Tryck på knappen ”Delete Pages” i dialogrutan ”Delete Duplicate Pages” för att ta bort alla markerade sidor från det aktuella PDF-dokumentet:.PNG) Klicka på knappen ”OK” för att bekräfta. Sidorna kommer att tas bort permanent.
Klicka på knappen ”OK” för att bekräfta. Sidorna kommer att tas bort permanent..PNG) Metod 2 – Jämförelse av visuellt utseende Endast översikt Den här metoden jämför sidor ”som bilder” och upptäcker sidor som ser exakt likadana ut. Denna metod jämför inte osynlig text som kan finnas på sidan. Det rekommenderas inte att använda den här metoden på skannade pappersdokument. Steg 1 – Öppna en PDF-fil Starta programmet Adobe® Acrobat® och öppna en PDF-fil med hjälp av menyn ”File > Open…”.Steg 2 – Öppna dialogrutan ”Find Duplicate Pages” Välj ”Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” för att öppna dialogrutan ”Find Duplicate Pages”.Steg 3 – Ange inställningar Markera alternativet ”Compare visual appearance for exact match (can be used to compare images)”.
Metod 2 – Jämförelse av visuellt utseende Endast översikt Den här metoden jämför sidor ”som bilder” och upptäcker sidor som ser exakt likadana ut. Denna metod jämför inte osynlig text som kan finnas på sidan. Det rekommenderas inte att använda den här metoden på skannade pappersdokument. Steg 1 – Öppna en PDF-fil Starta programmet Adobe® Acrobat® och öppna en PDF-fil med hjälp av menyn ”File > Open…”.Steg 2 – Öppna dialogrutan ”Find Duplicate Pages” Välj ”Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” för att öppna dialogrutan ”Find Duplicate Pages”.Steg 3 – Ange inställningar Markera alternativet ”Compare visual appearance for exact match (can be used to compare images)”..PNG) Klicka på ”OK” för att börja söka efter dubbla sidor. Steg 4 – Inspektera dubbla sidor Dialogrutan ”Delete Duplicate Pages” visar en lista över dubbla eller nästan dubbla sidor. Klicka på en sidpost för att visa motsvarande sida i sidovyn. Undersök sidorna och markera/avmarkera sidor för eventuell radering.
Klicka på ”OK” för att börja söka efter dubbla sidor. Steg 4 – Inspektera dubbla sidor Dialogrutan ”Delete Duplicate Pages” visar en lista över dubbla eller nästan dubbla sidor. Klicka på en sidpost för att visa motsvarande sida i sidovyn. Undersök sidorna och markera/avmarkera sidor för eventuell radering..PNG) Som ett alternativ kan du klicka på ”Save Report…” för att skapa en rapport om sidlikhet i HTML-format. Eller klicka på ”Bookmark Pages” för att skapa bokmärken i PDF för valda dubbelsidor. Den här metoden bygger på att man skapar mindre (samplade) kopior av sidorna och jämför dem ”som bilder”. Följande exempel visar två identiska sidor som endast innehåller grafik och ingen sökbar text:
Som ett alternativ kan du klicka på ”Save Report…” för att skapa en rapport om sidlikhet i HTML-format. Eller klicka på ”Bookmark Pages” för att skapa bokmärken i PDF för valda dubbelsidor. Den här metoden bygger på att man skapar mindre (samplade) kopior av sidorna och jämför dem ”som bilder”. Följande exempel visar två identiska sidor som endast innehåller grafik och ingen sökbar text:.PNG) Om sidorna är visuellt identiska upptäcker programmet dem som dubbletter:
Om sidorna är visuellt identiska upptäcker programmet dem som dubbletter:.PNG) Dessa två sidor anses vara olika på grund av stämpeln ”Godkänd” på en av sidorna:
Dessa två sidor anses vara olika på grund av stämpeln ”Godkänd” på en av sidorna:.PNG) Dessa två sidor betraktas som identiska med denna metod:
Dessa två sidor betraktas som identiska med denna metod:.PNG) Till skillnad från den textbaserade jämförelsemetoden anses sidorna inte vara identiska om färgen eller stilen på texten skiljer sig åt:
Till skillnad från den textbaserade jämförelsemetoden anses sidorna inte vara identiska om färgen eller stilen på texten skiljer sig åt:.PNG) Steg 5 – Ta bort dubbla sidor Klicka på ”Ta bort sidor” i dialogrutan ”Ta bort dubbla sidor” för att fortsätta. Klicka på knappen ”OK” för att radera sidor från de aktuella PDF-dokumenten. Sidorna kommer att tas bort permanent.Jämförelse av flera PDF-dokument Den här åtgärden kan användas för att hitta och ta bort dubbla sidor från flera PDF-dokument. Tillvägagångssättet är att kombinera ett eller flera dokument till en enda PDF-fil och köra operationen ”Hitta och ta bort dubbla sidor” på den resulterande filen. Detta kommer i huvudsak att ge ett enda dokument utan några dubbletter. Som ett alternativ är det möjligt att extrahera alla upptäckta dubbla sidor till ett separat PDF-dokument. Steg 1 – Kombinera flera PDF-dokument översikt Starta programmet Adobe® Acrobat® och välj ”Verktyg” från menyn. Välj ikonen ”Combine Files” (kombinera filer) i listan Verktyg.
Steg 5 – Ta bort dubbla sidor Klicka på ”Ta bort sidor” i dialogrutan ”Ta bort dubbla sidor” för att fortsätta. Klicka på knappen ”OK” för att radera sidor från de aktuella PDF-dokumenten. Sidorna kommer att tas bort permanent.Jämförelse av flera PDF-dokument Den här åtgärden kan användas för att hitta och ta bort dubbla sidor från flera PDF-dokument. Tillvägagångssättet är att kombinera ett eller flera dokument till en enda PDF-fil och köra operationen ”Hitta och ta bort dubbla sidor” på den resulterande filen. Detta kommer i huvudsak att ge ett enda dokument utan några dubbletter. Som ett alternativ är det möjligt att extrahera alla upptäckta dubbla sidor till ett separat PDF-dokument. Steg 1 – Kombinera flera PDF-dokument översikt Starta programmet Adobe® Acrobat® och välj ”Verktyg” från menyn. Välj ikonen ”Combine Files” (kombinera filer) i listan Verktyg..PNG) Klicka på ”Add Files…” i menyn ”Combine Files” och välj PDF-filer som ska sammanföras för jämförelse.
Klicka på ”Add Files…” i menyn ”Combine Files” och välj PDF-filer som ska sammanföras för jämförelse..PNG) Klicka på knappen ”Combine” i menyn för att slå ihop valda PDF-filer.
Klicka på knappen ”Combine” i menyn för att slå ihop valda PDF-filer..PNG) Steg 2 – Hitta dubbla sidor Den kombinerade PDF-filen för utdata visas på skärmen. Om inte, öppna den kombinerade PDF-filen. Välj ”Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” för att öppna dialogrutan ”Find Duplicate Pages”.Markera alternativet ”Jämför visuellt utseende för exakt matchning (kan användas för att jämföra bilder)”. Klicka på ”OK” för att börja söka efter dubbla sidor.
Steg 2 – Hitta dubbla sidor Den kombinerade PDF-filen för utdata visas på skärmen. Om inte, öppna den kombinerade PDF-filen. Välj ”Plug-Ins > Split Documents > Find and Delete Duplicate Pages…” för att öppna dialogrutan ”Find Duplicate Pages”.Markera alternativet ”Jämför visuellt utseende för exakt matchning (kan användas för att jämföra bilder)”. Klicka på ”OK” för att börja söka efter dubbla sidor..PNG) Steg 3 – Extrahera dubbla sidor Dialogrutan ”Delete Duplicate Pages” visar en lista över dubbla eller nästan dubbla sidor. Klicka på en sidpost för att visa motsvarande sida i visaren. Undersök sidorna och välj/avmarkera sidor. Klicka på ”Extract Pages…” för att extrahera valda dubbla sidor till ett nytt PDF-dokument.
Steg 3 – Extrahera dubbla sidor Dialogrutan ”Delete Duplicate Pages” visar en lista över dubbla eller nästan dubbla sidor. Klicka på en sidpost för att visa motsvarande sida i visaren. Undersök sidorna och välj/avmarkera sidor. Klicka på ”Extract Pages…” för att extrahera valda dubbla sidor till ett nytt PDF-dokument..PNG) Ange en utdatamapp och ett filnamn. Klicka på ”Spara” när du är klar.
Ange en utdatamapp och ett filnamn. Klicka på ”Spara” när du är klar..PNG) Dialogrutan visas och visar antalet sidor som har extraherats till ett separat dokument. Nu har du sparat alla dubbelsidor i den separata PDF-filen innan du raderar dem. Du kan undersöka dessa sidor och använda dem senare vid behov. Klicka på ”OK” för att stänga dialogrutan.
Dialogrutan visas och visar antalet sidor som har extraherats till ett separat dokument. Nu har du sparat alla dubbelsidor i den separata PDF-filen innan du raderar dem. Du kan undersöka dessa sidor och använda dem senare vid behov. Klicka på ”OK” för att stänga dialogrutan..png) Steg 4 – Ta bort dubbla sidor Klicka på ”Delete Pages” i dialogrutan ”Delete Duplicate Pages” för att fortsätta.
Steg 4 – Ta bort dubbla sidor Klicka på ”Delete Pages” i dialogrutan ”Delete Duplicate Pages” för att fortsätta..PNG) Klicka på ”OK” i dialogrutan för att ta bort valda dubbla sidor från det aktuella PDF-dokumentet.
Klicka på ”OK” i dialogrutan för att ta bort valda dubbla sidor från det aktuella PDF-dokumentet..PNG) De valda dubbla sidorna kommer att tas bort permanent från PDF-dokumentet. Du måste använda menyn ”File > Save” för att spara det ändrade dokumentet på disk. Klicka här för en lista över alla tillgängliga steg-för-steg-handledningar.
De valda dubbla sidorna kommer att tas bort permanent från PDF-dokumentet. Du måste använda menyn ”File > Save” för att spara det ändrade dokumentet på disk. Klicka här för en lista över alla tillgängliga steg-för-steg-handledningar.