Bilden ovan kanske har gett dig en tillräcklig uppfattning om vad det här inlägget handlar om.
Det här inlägget täcker några av de viktiga fuzzy-algoritmerna (inte exakt lika men samma strängar, till exempel RajKumar & Raj Kumar) för strängmatchning, som inkluderar:
Hamming Distance
Levenstein Distance
Damerau Levenstein Distance
N-Gram baserad strängmatchning
BK Tree
Bitap-algoritm
Men vi bör först veta varför fuzzy matchning är viktigt med tanke på ett verkligt scenario. När en användare tillåts skriva in uppgifter kan det bli riktigt rörigt som i nedanstående fall!
Låt,
- Ditt namn är ”Saurav Kumar Agarwal”.
- Du har fått ett bibliotekskort (med ett unikt ID förstås) som är giltigt för alla familjemedlemmar.
- Du går till biblioteket för att ge ut några böcker varje vecka. Men för detta måste du först göra en anteckning i ett register vid bibliotekets ingång där du skriver in ditt ID &namn.
Nu bestämmer sig biblioteksmyndigheterna för att analysera data i detta biblioteksregister för att få en uppfattning om unika läsare som besöker biblioteket varje månad. Detta kan göras av många anledningar (t.ex. om man ska utöka markytan eller inte, om antalet böcker ska ökas etc.).
De planerade att göra detta genom att räkna (unika namn, biblioteks-ID) par som registrerats under en månad. Så om vi har
123 Mehul
123 Rajesh
123 Mehul
133 Rajesh
133 Sandesh
Detta borde ge oss 4 unika läsare.
Så långt så bra
De uppskattade att detta antal skulle ligga runt 10k-10.5k men siffrorna steg till ~50k efter en analys med exakt strängmatchning av namn.
wooohhh!!
En ganska dålig uppskattning måste jag säga!!
Och de missade ett trick här?
Efter en djupare analys dök det upp ett stort problem. Kom ihåg ditt namn, Saurav Agarwal. De hittade några poster som ledde till fem olika användare i ditt familjebiblioteks-ID:
- Saurav K Aggrawal (lägg märke till det dubbla ”g”, ”ra-ar”, Kumar blir K)
- Saurav Kumar Agarwal
- Sourav Aggarwal
- SK Agarwal
- Agarwal
Det finns en del oklarheter eftersom biblioteksmyndigheterna inte vet
- Hur många personer från din familj besöker biblioteket? om dessa fem namn representerar en enda läsare, två eller tre olika läsare. Kalla det ett oövervakat problem där vi har en sträng som representerar ostandardiserade namn men deras standardiserade namn är inte kända (dvs. Saurav Agarwal: Saurav Kumar Agarwal är inte känt)
- Bör alla dessa namn slås samman till ”Saurav Kumar Agarwal”? kan inte säga det eftersom SK Agarwal kan vara Shivam Kumar Agarwal (säg din fars namn). Dessutom kan den enda Agarwal vara vem som helst i familjen.
De två sista fallen (SK Agarwal & Agarwal) skulle kräva ytterligare information (t.ex. kön, födelsedatum, utgivna böcker) som kommer att matas in i en ML-algoritm för att fastställa läsarens faktiska namn.& bör lämnas kvar för tillfället. Men en sak som jag är ganska säker på är att de tre första namnen representerar samma person & Jag borde inte behöva extra information för att slå ihop dem till en enda läsare, dvs. ”Saurav Kumar Agarwal”.
Hur detta kan göras?
Här kommer fuzz strängmatchning, vilket innebär en nästan exakt matchning mellan strängar som skiljer sig något från varandra (oftast på grund av felaktiga stavningar), som ”Agarwal” & ”Aggarwal” & ”Aggarwal” & ”Aggrawal”. Om vi får en sträng med en acceptabel felprocent (t.ex. en bokstav fel), skulle vi betrakta den som en matchning. Så låt oss utforska →
Hammingavståndet är det mest uppenbara avståndet som beräknas mellan två strängar av samma längd och som ger ett antal tecken som inte matchar motsvarande ett givet index. Till exempel: ”Bat” & ”Bet” har hammingavstånd 1 som vid index 1, ”a” är inte lika med ”e”
Levensteindistans/redigeringsavstånd
Tyvärr antar jag att du är bekant med Levensteindistans & Rekursion. Om inte, läs det här. Nedanstående förklaring är mer en sammanfattad version av Levensteins avstånd.
Låt ’x’=längd(Str1) & ’y’=längd(Str2) för hela det här inlägget.
Levensteins avstånd beräknar det minsta antalet redigeringar som krävs för att omvandla ’Str1’ till ’Str2’ genom att utföra antingen tillägg, borttagning eller ersättande tecken. Därför har ”Cat” & ”Bat” redigeringsavståndet ”1” (Ersätt ”C” med ”B”) medan det för ”Ceat” & ”Bat” skulle vara 2 (Ersätt ”C” till ”B”; ta bort ”e”).
Om vi talar om algoritmen har den huvudsakligen 5 steg
int LevensteinDistance(string str1, string str2, int x, int y){if (x == len(str1)+1) return len(str2)-y+1;if (y == len(str2)+1) return len(str1)-x+1;if (str1 == str2)
return LevensteinDistance(str1, str2, x+ 1, y+ 1);return 1 + min(LevensteinDistance(str1, str2, x, y+ 1), #insert LevensteinDistance(str1, str2, x+ 1, y), #remove LevensteinDistance(str1, str2, x+ 1, y+ 1) #replace
}
LevenesteinDistance('abcd','abbd',1,1)
Vad vi gör är att börja läsa strängar från det första tecknet
- Om tecknet vid index ’x’ i str1 stämmer överens med tecknet vid index ’y’ i str2, krävs ingen redigering &beräkna redigeringsavståndet genom att ringa
LevensteinDistance(str1,str2)
- Om de inte stämmer överens vet vi att en redigering krävs. Så vi lägger till +1 till det aktuella edit_distance & beräknar rekursivt edit_distance för 3 villkor & tar det minsta av de tre:
Levenstein(str1,str2) →insättning i str2.
Levenstein(str1,str2) →deletning i str2
Levenstein(str1,str2)→ersättning i str2
- Om någon av strängen får slut på tecken under rekursionen, Längden på de återstående tecknen i den andra strängen läggs till i redigeringsavståndet (de två första if-satserna)
Demerau-Levenstein-avstånd
Konsiderar ’abcd’ & ’acbd’. Om vi följer Levensteins avstånd skulle detta vara (replace ’b’-’c’ & ’c’-’b’ at index positions 2 & 3 in str2) Men om man tittar noga så har båda tecknen bytts ut som i str1 & Om vi introducerar en ny operation ’Swap’ vid sidan av ’addition’, ’ deletion’ & ’replace’, kan detta problem lösas. Denna introduktion kan hjälpa oss att lösa problem som ’Agarwal’ & ’Agrawal’.
Denna operation läggs till genom nedanstående pseudokod
1 +
(x - last_matching_index_y - 1 ) +
(y - last_matching_index_x - 1 ) +
LevinsteinDistance(str1, str2)
Låt oss köra ovanstående operation för ’abcd’ & ’acbd’ där man antar
initial_x=1 & initial_y=1 (Startar indexering från 1 & inte från 0 för båda strängarna).
kurrent x=3 & y=3 och därmed str1 & str2 vid ”c” (abcd) & ”b” (acbd) respektive.
Övre gränser som ingår i den skivning som nämns nedan. Därför kommer ”qwerty” att betyda ”qwer”.
- last_matching_index_y kommer att vara det sista indexet i str2 som matchar str1, dvs. 2 eftersom ”c” i ”acbd” (index 2) matchar ”c” i ”abcd”.
- last_matching_index_x kommer att vara det sista indexet i str1 som matchar str2 i.e 2 som ”b” i ”abcd” (index 2)matchade med ”b” i ”acbd”.
- Därmed, enligt pseudokoden ovan, DemarauLevenstein(’abc’,’acb’)=
1+(4-3-1) + (4-3-1)+LevensteinDistance(’a’,’a’)=1+0+0+0+0=1. Detta skulle ha blivit 2 om vi följt Levenstein Distance
N-Gram
N-gram är i princip inget annat än en uppsättning värden som genereras från en sträng genom att para ihop sekventiellt förekommande ”n” tecken/ord. Till exempel: n-gram med n=2 för ”abcd” blir ”ab”, ”bc”, ”cd”.
Nu kan dessa n-gram genereras för strängar vars likhet måste mätas & olika mått kan användas för att mäta likheten.
Låt ’abcd’ & ’acbd’ vara 2 strängar som ska matchas.
n-gram med n=2 för
’abcd’=ab,bc,cd
’acbd’=ac,cb,bd
Komponentmatchning (qgrams)
Antal n-gram som matchar exakt för de två strängarna. Här skulle det vara 0
Cosine Similarity
Beräkning av punktprodukten efter konvertering av n-gram som genererats för strängar till vektorer
Komponentmatchning (ingen ordning beaktas)
Matchning av n-gramkomponenter som ignorerar ordningen på elementen inom t.ex. bc=cb.
Det finns många andra sådana mått som Jaccard-avstånd, Tversky-index osv. som inte har diskuterats här.
BK Tree
BK Tree är en av de snabbaste algoritmerna för att hitta liknande strängar (från en pool av strängar) för en given sträng. BK tree använder en
- Levenstein Distance
- Triangle inequality (kommer att behandla detta i slutet av detta avsnitt)
för att ta reda på liknande strängar (& inte bara en bästa sträng).
Ett BK tree skapas med hjälp av en pool av ord från en tillgänglig ordbok. Säg att vi har en ordbok D={Book, Books, Cake, Boo, Boon, Cook, Cape, Cart}
Ett BK-träd skapas genom
- Välj en rotnod (kan vara vilket ord som helst). Låt det vara ”Books”
- Gå igenom varje ord W i Dictionary D, beräkna dess Levenstein-avstånd till rotnoden och gör ordet W till ett barn till roten om det inte finns något barn med samma Levenstein-avstånd till föräldern. Infoga böcker & Cake.
Levenstein(Books,Book)=1 & Levenstein(Books,Cake)=4. Eftersom inget barn med samma avstånd har hittats för ”Book”, gör du dem till nya barn för roten.
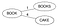
- Om det finns ett barn med samma Levensteinavstånd för föräldern P, betrakta nu det barnet som en förälder P1 för ordet W, beräkna Levenstein(förälder, ord) och om det inte finns något barn med samma avstånd till föräldern P1, gör ordet W till ett nytt barn till P1, annars fortsätter du neråt i trädet.
Överväg att infoga Boo. Levenstein(Book, Boo)=1 men det finns redan ett barn med samma avstånd dvs Books. Beräkna därför nu Levenstein(Books, Boo)=2. Eftersom det inte finns något barn med samma avstånd till Books, gör Boo till ett barn till Books.

Samma sak, infoga alla ord från ordboken i BK Tree

När BK Tree väl är förberett måste vi för att söka efter liknande ord för ett givet ord (frågeord) ställa in ett toleranströskelvärde, till exempel ”t”.
- Detta är det maximala edit_distance som vi kommer att beakta för likheten mellan varje nod & query_word. Allt som överstiger detta förkastas.
- Också, vi kommer endast att beakta de barn till en överordnad nod för jämförelse med Query där Levenstein(Child, Parent) är inom
varför? kommer att diskutera detta inom kort
- Om detta villkor är sant för ett barn kommer vi endast att beräkna Levenstein(Child, Query) som kommer att anses likna Query om
Levenshtein(Child, Query)≤t.
- Därmed beräknar vi inte Levenstein-avståndet för alla noder/ord i ordboken med sökordet & och sparar därmed mycket tid när det finns många ord
Därmed, för att ett barn ska vara likt Query om
- Levenstein(Parent, Query)-t ≤ Levenstein(Child,Parent) ≤ Levenstein(Parent,Query)+t
- Levenstein(Child,Query)≤t
Låt oss gå igenom ett exempel snabbt. Låt ”t”=1
Låt ordet vi behöver hitta liknande ord för vara ”Care” (sökord)
- Levenstein(Book,Care)=4. Eftersom 4>1, förkastas ”Book”. Nu tar vi endast hänsyn till de barn till ”Book” som har ett LevisteinDistance(Child,’Book’) mellan 3(4-1) & 5(4+1). Vi skulle alltså förkasta ’Books’ & alla dess barn eftersom 1 inte ligger inom de fastställda gränserna
- Som Levenstein(Cake, Book)=4 som ligger mellan 3 & 5, kommer vi att kontrollera Levenstein(Cake, Care)=1 som är ≤1 och därmed ett liknande ord.
- Om vi justerar gränserna blir gränserna för Kakas barn 0(1-1) & 2(1+1)
- Då både Cape & Cart har Levenstein(Barn, Förälder)=1 & 2 respektive är båda berättigade att bli testade med ”Care”.
- Då Levenstein(Cape,Care)=1 ≤1& Levenstein(Cart,Care)=2>1, är det bara Cape som anses vara ett liknande ord som ’Care’.
Därmed hittade vi 2 ord som liknar ’Care’ som är: Cake & Cape
Men på vilken grund bestämmer vi gränserna
Levenstein(Parent,Query)-t, Levenstein(Parent,Query)+t.
för varje barnnod?
Detta följer av Triangle Inequality som säger
Distance (A,B) + Distance(B,C)≥Distance(A,C) där A,B,C är sidorna i en triangel.
Hur denna idé hjälper oss att komma fram till dessa gränser, låt oss se:
Let Query,=Q Parent=P & Child=C bildar en triangel med Levenstein-avstånd som kantlängd. Låt ”t” vara toleransgränsen. Då, Genom ovanstående ojämlikhet
Levenstein(P,C) + Levenstein(P,Q)≥Levenstein(C,Q)as Levenstein(C, Q) can't exceed 't'(threshold set earlier for C to be similar to Q), HenceLevenstein(P,C) + Levenstein(P,Q)≥ t
OrLevenstein(P,C)≥|Levenstein(P,Q)-t| i.e the lower limit is set
Återigen, genom Triangle Inequality,
Levenstein(P,Q) + Levenstein(C,Q) ≥ Levenstein(P,C) or
Levenstein(P,Q) + t ≥ Levenstein(P,C) or the upper limit is set
Bitap-algoritmen
Det är också en mycket snabb algoritm som kan användas för fuzzy strängmatchning ganska effektivt. Detta beror på att den använder bitvisa operationer & eftersom de är ganska snabba, algoritmen är känd för sin snabbhet. Utan att slösa bort något, låt oss börja:
Låt S0=’ababc’ vara mönstret som ska matchas med strängen S1=’abdabababc’.
Först av allt,
- Finn ut alla unika tecken i S1 & S0 som är a,b,c,d
- Förbered bitmönster för varje tecken. Hur?

- Vänd mönstret S0 för att söka
- För bitmönstret för tecken x, placera 0 där det förekommer i mönstret annars 1. I T förekommer ”a” på 3:e & 5:e plats, vi placerade 0 på dessa positioner & resten 1.
Förbered på samma sätt alla andra bitmönster för olika tecken i ordboken.
S0=ababababc S1=abdababababc
- Förbered dig på ett inledande tillstånd för ett bitmönster av längden(S0) med alla 1:or. I vårt fall skulle det vara 11111 (tillstånd S).
- När vi börjar söka i S1 och passerar ett tecken,
skifta ett 0 på den nedersta biten, dvs. femte biten från höger i S &
OR-operation på S med T.
När vi kommer att stöta på det första ”a” i S1, kommer vi
- Vänsterförskjuta ett 0 i S vid den nedersta biten för att bilda 11111 →11110
- 11010 | 11110=11110
När vi nu går över till det andra tecknet ”b”
- förskjuter 0 till S i.e för att bilda 11110 →11100
- S |T=11100 | 10101=11101
När ’d’ påträffas
- Skifta 0 till S för att bilda 11101 →11010
- S |T=11010 |11111=11111
Observera att eftersom ’d’ inte finns i S0, återställs tillståndet S. När du har gått igenom hela S1 får du nedanstående tillstånd vid varje tecken

Hur vet jag om jag har hittat någon fuzz/full match?
- Om en 0 når den översta biten i bitmönstret i State S (som i det sista tecknet ”c”) har du en fullständig matchning
- För fuzz-matchning, observera 0 på olika positioner i State S. Om 0 står på fjärde plats har vi hittat 4/5 tecken i samma sekvens som i S0. På samma sätt för 0 på andra platser.
En sak du kanske har observerat är att alla dessa algoritmer arbetar med stavningslikhet mellan strängar. Kan det finnas några andra kriterier för fuzzy matching? Ja,
Fonetik
Vi kommer att ta upp fonetikbaserade (ljudbaserade, som Saurav & Sourav, bör ha en exakt matchning i fonetik) fuzzmatchningsalgoritmer härnäst !!!
- Dimension Reduction (3 delar)
- NLP Algorithms(5 delar)
- Reinforcement Learning Basics (5 delar)
- Starting off with Time-Series (7 delar)
- Object Detection using YOLO (3 delar)
- Tensorflow for beginners (concepts + Examples) (4 delar)
- Preprocessing Time Series (with codes)
- Data Analytics for beginners
- Statistics for beginners (4 delar)