När vi diskuterar modellförutsägelser är det viktigt att förstå förutsägelsefel (bias och varians). Det finns en kompromiss mellan en modells förmåga att minimera bias och varians. Att få en ordentlig förståelse för dessa fel skulle hjälpa oss inte bara att bygga korrekta modeller utan också att undvika misstaget med överanpassning och underanpassning.
Så låt oss börja med grunderna och se hur de gör skillnad för våra modeller för maskininlärning.
Vad är bias?
Bias är skillnaden mellan vår modells genomsnittliga prediktion och det korrekta värdet som vi försöker att förutsäga. Modell med hög bias ägnar mycket lite uppmärksamhet åt träningsdata och förenklar modellen alltför mycket. Den leder alltid till höga fel på tränings- och testdata.
Vad är varians?
Varians är variabiliteten i modellens prediktion för en given datapunkt eller ett värde som berättar om spridningen av våra data. En modell med hög varians ägnar mycket uppmärksamhet åt träningsdata och generaliserar inte på data som den inte har sett tidigare. Som ett resultat av detta presterar sådana modeller mycket bra på träningsdata men har hög felprocent på testdata.
Matematiskt
Låt variabeln vi försöker förutsäga vara Y och andra kovarianter vara X. Vi antar att det finns ett samband mellan de två så att
Y=f(X) + e
Varvid e är feltermen och den är normalfördelad med ett medelvärde på 0.
Vi kommer att göra en modell f^(X) av f(X) med hjälp av linjär regression eller någon annan modelleringsteknik.
Så det förväntade kvadratiska felet vid en punkt x är
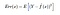
Den Err(x) kan delas upp ytterligare som

Err(x) är summan av Bias², varians och det irreducerbara felet.
Irreducerbart fel är det fel som inte kan minskas genom att skapa bra modeller. Det är ett mått på mängden brus i våra data. Här är det viktigt att förstå att oavsett hur bra vi gör vår modell kommer våra data att ha en viss mängd brus eller irreducerbart fel som inte kan avlägsnas.
Bias och varians med hjälp av bulls-eye-diagrammet

I diagrammet ovan är målets centrum en modell som perfekt förutsäger korrekta värden. När vi rör oss bort från måltavlan blir våra förutsägelser sämre och sämre. Vi kan upprepa vår process för modellbygge för att få separata träffar på målet.
I övervakad inlärning sker underanpassning när en modell inte kan fånga det underliggande mönstret i data. Dessa modeller har vanligtvis hög bias och låg varians. Det händer när vi har mycket få data för att bygga en korrekt modell eller när vi försöker bygga en linjär modell med icke-linjära data. Dessa modeller är också mycket enkla att fånga komplexa mönster i data som linjär och logistisk regression.
I övervakad inlärning sker överanpassning när vår modell fångar bruset tillsammans med det underliggande mönstret i data. Det händer när vi tränar vår modell mycket på bullriga dataset. Dessa modeller har låg bias och hög varians. Dessa modeller är mycket komplexa som beslutsträd som är benägna att överanpassas.

Varför finns det en bias-varians-avvägning?
Om vår modell är för enkel och har väldigt få parametrar kan den ha hög bias och låg varians. Om vår modell å andra sidan har ett stort antal parametrar kommer den att ha hög varians och låg bias. Så vi måste hitta den rätta/bra balansen utan att överanpassa och underanpassa data.
Denna avvägning i komplexitet är anledningen till att det finns en avvägning mellan bias och varians. En algoritm kan inte vara mer komplex och mindre komplex på samma gång.
Totalfel
För att bygga en bra modell måste vi hitta en bra balans mellan bias och varians så att det totala felet minimeras.

En optimal balans mellan bias och varians skulle aldrig över- eller underanpassa modellen.
Det är därför viktigt att förstå bias och varians för att förstå beteendet hos prognosmodeller.
Tack för att du läste!