- Funktionen och dess derivat är båda monotona
- Utgången är noll ”centrerad”
- Optimering är lättare
- Derivat /Differential av Tanh-funktionen (f'(x)) kommer att ligga mellan 0 och 1.
Konsekvenser:
- Derivatan av Tanh-funktionen lider av ”Vanishing gradient and Exploding gradient problem”.
- Långsam konvergens – eftersom den är beräkningstung.(Användning av exponentiell matematisk funktion)
”Tanh är att föredra framför sigmoidfunktionen eftersom den är nollcentrerad och gradienterna inte är begränsade till att röra sig i en viss riktning”
3. ReLu-aktiveringsfunktion (ReLu – Rectified Linear Units):


ReLu är en icke-linjär aktiveringsfunktion som har blivit populär inom artificiell intelligens. ReLu-funktionen representeras också som f(x) = max(0,x).
- Funktionen och dess derivat är båda monotona.
- Huvudfördelen med att använda ReLU-funktionen- Den aktiverar inte alla neuroner samtidigt.
- Räkneffektivt
- Derivatan/Differentialen av Tanh-funktionen (f'(x)) blir 1 om f(x) > 0 annars 0.
- Konvergerar mycket snabbt
Konsekvenser:
- ReLu-funktionen är inte ”nollcentrerad”.Detta gör att gradientuppdateringarna går för långt i olika riktningar. 0 < output < 1, och det gör optimeringen svårare.
- Döda neuron är det största problemet.Detta beror på att den inte är differentierbar vid noll.
”Problem med döende neuron/döda neuron: Eftersom ReLu-derivatan f'(x) inte är 0 för neuronens positiva värden (f'(x)=1 för x ≥ 0) mättas ReLu inte (exploderar) och inga döda neuron (Vanishing neuron)rapporteras. Mättnad och försvinnande gradient uppstår endast för negativa värden som, när de ges till ReLu, omvandlas till 0. Detta kallas problemet med döende neuron.”
4. läckande ReLu Aktiveringsfunktion:
Leaky ReLU-funktionen är inget annat än en förbättrad version av ReLU-funktionen med införandet av ”konstant lutning”


- Leaky ReLU definieras för att lösa problemet med döende neuron/döda neuron.
- Problemet med döende neuron/döda neuron behandlas genom att införa en liten lutning där negativa värden skalade med α gör det möjligt för motsvarande neuroner att ”hålla sig vid liv”.
- Funktionen och dess derivat är båda monotona
- Den tillåter negativa värden under bakåtpropagering
- Den är effektiv och enkel att beräkna.
- Derivatan av Leaky är 1 när f(x) > 0 och ligger mellan 0 och 1 när f(x) < 0.
Konsekvenser:
- Leaky ReLU ger inte konsekventa förutsägelser för negativa ingångsvärden.
5. ELU (Exponential Linear Units) Aktiveringsfunktion:

- ELU föreslås också för att lösa problemet med döende neuron.
- Ingen problem med död ReLU
- Zerocentriskt
Konsekvenser:
- Redovisningsintensivt.
- Likt Leaky ReLU, även om det teoretiskt sett är bättre än ReLU, finns det för närvarande inga goda bevis i praktiken för att ELU alltid är bättre än ReLU.
- f(x) är monoton endast om alfa är större än eller lika med 0.
- f'(x) derivatan av ELU är monoton endast om alfa ligger mellan 0 och 1.
- Långsam konvergens på grund av exponentialfunktionen.
6. P ReLu (Parametric ReLU) Aktiveringsfunktion:

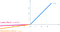
- Idén om leaky ReLU kan utvidgas ytterligare.
- Istället för att multiplicera x med en konstant term kan vi multiplicera den med en ”hyperparameter (en tränbar parameter)”, vilket verkar fungera bättre än leaky ReLU. Denna utvidgning av leaky ReLU kallas Parametric ReLU.
- Parametern α är i allmänhet ett tal mellan 0 och 1, och den är i allmänhet relativt liten.
- Har en liten fördel jämfört med Leaky Relu på grund av den träningsbara parametern.
- Hanterar problemet med döende neuron.
Konsekvenser:
- Samma som leaky Relu.
- f(x) är monoton när a> eller =0 och f'(x) är monoton när a =1
7. Swish (A Self-Gated) Activation Function:(Sigmoid Linear Unit)

- Google Brain Team har föreslagit en ny aktiveringsfunktion, kallad Swish, som helt enkelt är f(x) = x – sigmoid(x).
- I sina experiment visar de att Swish tenderar att fungera bättre än ReLU på djupare modeller i ett antal utmanande datamängder.
- Kurvan för Swish-funktionen är jämn och funktionen är differentierbar i alla punkter. Detta är till hjälp under modelloptimeringsprocessen och anses vara en av anledningarna till att swish presterar bättre än ReLU.
- Swish-funktionen är ”inte monoton”. Detta innebär att funktionens värde kan minska även när ingångsvärdena ökar.
- Funktionen är obunden ovanför och bunden nedanför.
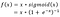
”Swish tenderar att kontinuerligt matcha eller överträffa ReLu”
Notera att utfallet av swish-funktionen kan sjunka även när ingångsvärdena ökar. Detta är en intressant och swish-specifik egenskap.(På grund av icke-monotonisk karaktär)
f(x)=2x*sigmoid(beta*x)
Om vi tror att beta=0 är en enkel version av Swish, som är en inlärningsbar parameter, är sigmoiddelen alltid 1/2 och f (x) är linjär. Om beta däremot är ett mycket stort värde blir sigmoiddelen en nästan tvåsiffrig funktion (0 för x<0,1 för x>0). Således konvergerar f (x) mot ReLU-funktionen. Därför väljs den vanliga Swish-funktionen med beta = 1. På detta sätt tillhandahålls en mjuk interpolering (som associerar de variabla värdeuppsättningarna med en funktion inom det givna intervallet och den önskade precisionen). Utmärkt! En lösning på problemet med att gradienterna försvinner har hittats.
8.Softplus
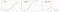
Softplus-funktionen liknar ReLU-funktionen, men är relativt sett mjukare.Funktionen Softplus eller SmoothRelu f(x) = ln(1+exp x).
Derivatan av Softplus-funktionen är f'(x) är logistisk funktion (1/(1+exp x)).
Funktionsvärdet sträcker sig från (0, + inf).Både f(x) och f'(x) är monotona.
9.Softmax eller normaliserad exponentialfunktion:

Funktionen ”softmax” är också en typ av sigmoidfunktion, men den är mycket användbar för att hantera klassificeringsproblem med flera klasser.
”Softmax kan beskrivas som en kombination av flera sigmoidfunktioner.”
”Softmax-funktionen returnerar sannolikheten för att en datapunkt tillhör varje enskild klass.”
När man bygger upp ett nätverk för ett problem med flera klasser skulle utdataskiktet ha lika många neuroner som antalet klasser i målet.
Till exempel, om man har tre klasser skulle det finnas tre neuroner i utdataskiktet. Anta att du får utdata från neuronerna som .Genom att tillämpa softmax-funktionen på dessa värden får du följande resultat – . Dessa representerar sannolikheten för att datapunkten tillhör varje klass. Av resultatet kan vi utläsa att dataintyget tillhör klass A.
”Observera att summan av alla värden är 1.”
Vilken av dem är bäst att använda? Hur väljer man rätt?
För att vara ärlig finns det ingen fast regel för att välja aktiveringsfunktion.Vi kan inte skilja mellan olika aktiveringsfunktioner.Varje aktiveringsfunktion har sina egna för- och nackdelar.Alla bra och dåliga beslut kommer att fattas baserat på spåren.
Men baserat på problemets egenskaper kan vi kanske göra ett bättre val för att nätverket ska kunna konvergera lättare och snabbare.
- Sigmoidfunktioner och deras kombinationer fungerar i allmänhet bättre när det gäller klassificeringsproblem
- Sigmoider och tanh-funktioner undviks ibland på grund av problemet med försvinnande gradient
- ReLU-aktiveringsfunktion används ofta i modern tid.
- Om det finns döda neuroner i våra nätverk på grund av ReLU är läckande ReLU-funktion det bästa valet
- ReLU-funktionen bör endast användas i de dolda lagren
”Som en tumregel kan man börja med att använda ReLU-funktionen och sedan gå över till andra aktiveringsfunktioner om ReLU inte ger optimala resultat”