Kiedy dyskutujemy o predykcji modelu, ważne jest zrozumienie błędów predykcji (błędu systematycznego i wariancji). Istnieje kompromis pomiędzy zdolnością modelu do minimalizowania błędu systematycznego i wariancji. Uzyskanie właściwego zrozumienia tych błędów pomoże nam nie tylko budować dokładne modele, ale także uniknąć błędów przepasowania i niedopasowania.
Zacznijmy więc od podstaw i zobaczmy, jak one wpływają na nasze modele uczenia maszynowego.
Co to jest błąd systematyczny?
Bias jest różnicą pomiędzy średnim przewidywaniem naszego modelu a prawidłową wartością, którą próbujemy przewidzieć. Model z wysokim biasem zwraca bardzo mało uwagi na dane treningowe i nadmiernie upraszcza model. To zawsze prowadzi do wysokiego błędu na danych treningowych i testowych.
Co to jest wariancja?
Wariancja jest zmiennością przewidywań modelu dla danego punktu danych lub wartości, która mówi nam o rozrzucie naszych danych. Model z wysoką wariancją zwraca dużą uwagę na dane treningowe i nie generalizuje na dane, których wcześniej nie widział. W rezultacie, takie modele radzą sobie bardzo dobrze na danych treningowych, ale mają wysoki poziom błędów na danych testowych.
Matematycznie
Zmieńmy zmienną, którą próbujemy przewidzieć jako Y i inne zmienne jako X. Zakładamy, że istnieje związek między nimi taki, że
Y=f(X) + e
Gdzie e jest składnikiem błędu i jest normalnie rozłożone ze średnią 0.
Zrobimy model f^(X) z f(X) używając regresji liniowej lub jakiejkolwiek innej techniki modelowania.
Więc oczekiwany błąd kwadratowy w punkcie x wynosi
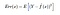
Przykładowo. Err(x) może być dalej zdekomponowany jako

Err(x) jest sumą Bias², wariancji i błędu nieredukowalnego.
Błąd nieredukowalny to błąd, którego nie można zmniejszyć poprzez tworzenie dobrych modeli. Jest to miara ilości szumu w naszych danych. Tutaj ważne jest, aby zrozumieć, że bez względu na to, jak dobry zrobimy nasz model, nasze dane będą miały pewną ilość szumu lub nieredukowalny błąd, który nie może być usunięty.
Bias i wariancja przy użyciu wykresu bulls-eye

W powyższym diagramie, środek celu jest model, który doskonale przewiduje prawidłowe wartości. W miarę oddalania się od celu nasze przewidywania stają się coraz gorsze. Możemy powtórzyć nasz proces budowania modelu, aby uzyskać kolejne trafienia w cel.
W nadzorowanym uczeniu się, niedopasowanie ma miejsce, gdy model nie jest w stanie uchwycić podstawowego wzorca danych. Modele te zazwyczaj mają wysoką skośność i niską wariancję. Dzieje się tak, gdy mamy bardzo mało danych, aby zbudować dokładny model lub gdy próbujemy zbudować model liniowy z nieliniowymi danymi. Ponadto, tego rodzaju modele są bardzo proste do uchwycenia złożonych wzorców w danych, takich jak regresja liniowa i logistyczna.
W nadzorowanym uczenia, overfitting dzieje się, gdy nasz model przechwytuje szum wraz z podstawowym wzorem w danych. Zdarza się to, gdy trenujemy nasz model dużo nad hałaśliwym zbiorem danych. Modele te mają niską skośność i wysoką wariancję. Modele te są bardzo złożone, jak drzewa decyzyjne, które są podatne na przepasowanie.

Dlaczego Bias Variance Tradeoff?
Jeśli nasz model jest zbyt prosty i ma bardzo mało parametrów, może mieć wysoką skośność i niską wariancję. Z drugiej strony, jeśli nasz model ma dużą liczbę parametrów, to będzie miał wysoką wariancję i niską skośność. Więc musimy znaleźć właściwą/dobrą równowagę bez przepasowania i niedopasowania danych.
Ten kompromis w złożoności jest dlaczego istnieje kompromis między uprzedzeniem a wariancją. Algorytm nie może być bardziej złożony i mniej złożony w tym samym czasie.
Błąd całkowity
Aby zbudować dobry model, musimy znaleźć dobrą równowagę między skośnością i wariancją, tak aby zminimalizować błąd całkowity.


Optymalna równowaga między skośnością i wariancją nigdy nie doprowadzi do przepełnienia lub niedostosowania modelu.
Dlatego zrozumienie skośności i wariancji jest krytyczne dla zrozumienia zachowania modeli predykcyjnych.
Dziękuję za przeczytanie!
.