Wprowadzenie Ten samouczek pokazuje, jak znaleźć i opcjonalnie usunąć podobne lub duplikaty stron w tym samym dokumencie PDF przy użyciu wtyczki AutoSplit™ dla Adobe® Acrobat®. Operacja ta wykrywa podobne strony i przedstawia je użytkownikowi do przeglądu. Użytkownik może przejrzeć wyniki i wybrać/odznaczyć poszczególne strony z listy duplikatów do ewentualnego usunięcia lub wyodrębnienia. Można wykonać następujące operacje:
- Znajdowanie zduplikowanych i bliskich duplikatów stron
- Zaznaczanie zduplikowanych stron
- Wyodrębnianie zduplikowanych stron do osobnego dokumentu PDF
- Usuwanie zduplikowanych stron z dokumentu
- Zapisywanie raportu podobieństwa stron
Wtyczka udostępnia dwie różne metody wykrywania zduplikowanych lub bliskich duplikatów stron: Porównaj tylko tekst strony Użyj tej metody, aby porównać tekst strony bez względu na jej wygląd wizualny. Oblicza podobieństwo stron tylko na podstawie zawartości tekstowej i całkowicie ignoruje wygląd tekstu, układ, obrazy i grafikę, które mogą być obecne na stronie. Jest to najlepsza metoda do wykrywania duplikatów w większości typów dokumentów. Porównaj wizualny wygląd stron Ta metoda porównuje strony „jako obrazy” i wykrywa strony, które wyglądają dokładnie tak samo. Metoda ta nie porównuje żadnego niewidocznego tekstu, który może być obecny na stronie. Nie zaleca się stosowania tej metody w przypadku zeskanowanych dokumentów papierowych. Używanie zeskanowanych dokumentów papierowych Dość często ta operacja jest używana do znajdowania duplikatów stron w zeskanowanych dokumentach papierowych. Zeskanowane dokumenty muszą zostać poddane procesowi OCR przed użyciem ich do przetwarzania tekstu. OCR to proces rozpoznawania tekstu w zeskanowanych dokumentach i uczynienia ich możliwymi do przeszukiwania. Istotne jest, aby zrozumieć, że rozpoznawanie tekstu w zeskanowanych dokumentach jest podatne na błędy i rzadko jest w 100% dokładny. Liczba błędów zależy od rozdzielczości skanowania i jakości oryginalnego dokumentu. W najczęstszych przypadkach zeskanowana strona może zawierać od 1 do 10 błędów rozpoznawania, w których pewne litery są nieprawidłowo identyfikowane. Na przykład, w zależności od czcionki, mała litera l może wyglądać dokładnie jak cyfra 1 . Wielka litera O jest często błędnie rozpoznawana jako cyfra 0, a wielka litera S jako cyfra 5 itd. Ponieważ wiele symboli alfanumerycznych ma podobne lub identyczne cechy fizyczne, ich rozróżnienie często stanowi wyzwanie. Dlatego właśnie porównanie oparte na podobieństwie jest przydatne do wykrywania niewielkich różnic pomiędzy stronami, które powstają w procesie rozpoznawania tekstu. Niska jakość zeskanowanych dokumentów może zawierać dużą liczbę błędów, co czyni je bezużytecznymi dla wiarygodnego porównania tekstowego. Zobacz poniższy tutorial jak OCRować zeskanowane dokumenty i ocenić ich przydatność do przetwarzania tekstowego. . Wymagania wstępne Aby móc skorzystać z tego samouczka, na komputerze musi być zainstalowana kopia programu Adobe® Acrobat® wraz z wtyczką AutoSplit™. Można pobrać wersje próbne zarówno programu Adobe® Acrobat®, jak i wtyczki AutoSplit™. Spis treści
- Porównywanie tylko tekstu strony
- Porównywanie tylko wyglądu wizualnego
- Porównywanie wielu dokumentów
Metoda 1 – Porównywanie tylko tekstu strony Przegląd Ta metoda porównuje podobieństwo stron tylko na podstawie ich zawartości. Wygląd wizualny, pozycja i kolejność tekstu są nieistotne. Metoda ta ignoruje również wszelkie obrazy i grafiki obecne na stronach. Zmodyfikowana metryka podobieństwa cosinusowego jest używana do obliczenia podobieństwa dwóch stron na podstawie ich zawartości tekstowej. Krok 1 – Otwórz plik PDF Uruchom aplikację Adobe® Acrobat® i otwórz plik PDF używając menu „Plik > Otwórz…”..PNG) Krok 2 – Otwórz okno dialogowe „Znajdź zduplikowane strony” Wybierz „Plug-Ins > Podziel dokumenty > Znajdź i usuń zduplikowane strony…”, aby otworzyć okno dialogowe „Znajdź zduplikowane strony”.
Krok 2 – Otwórz okno dialogowe „Znajdź zduplikowane strony” Wybierz „Plug-Ins > Podziel dokumenty > Znajdź i usuń zduplikowane strony…”, aby otworzyć okno dialogowe „Znajdź zduplikowane strony”..PNG) Krok 3 – Określ ustawienia Zaznacz opcję „Porównaj tylko tekst strony (zignoruj wizualny wygląd stron)”.
Krok 3 – Określ ustawienia Zaznacz opcję „Porównaj tylko tekst strony (zignoruj wizualny wygląd stron)”..PNG) Korzystanie z ustawień predefiniowanych Metoda tekstowa udostępnia szereg predefiniowanych zestawów parametrów, które są odpowiednie do porównywania różnych rodzajów dokumentów z różną ilością błędów rozpoznawania. Każdy predefiniowany zestaw parametrów zapewnia inne warunki dla obliczeń podobieństwa:
Korzystanie z ustawień predefiniowanych Metoda tekstowa udostępnia szereg predefiniowanych zestawów parametrów, które są odpowiednie do porównywania różnych rodzajów dokumentów z różną ilością błędów rozpoznawania. Każdy predefiniowany zestaw parametrów zapewnia inne warunki dla obliczeń podobieństwa:
- Ustawienia niestandardowe – wszystkie ustawienia są określane przez użytkownika
- Skanowany dokument papierowy: High Quality
- Scanned Paper Document: Medium Quality
- Fax Document: Niska jakość
- Niezeskanowany plik PDF: dopasowanie dokładne
- Niezeskanowany plik PDF: dopasowanie rozmyte
- Dokładne dopasowanie (z kolejnością tekstu) – ta metoda nie wykorzystuje podobieństwa kosinusowego
.PNG) Ustawienia pojawiają się poniżej menu po wybraniu wstępnie zdefiniowanego zestawu parametrów.
Ustawienia pojawiają się poniżej menu po wybraniu wstępnie zdefiniowanego zestawu parametrów..PNG) Tutaj są ustawienia używane przez predefiniowane zestawy:
Tutaj są ustawienia używane przez predefiniowane zestawy:.PNG) Kliknij „Edytuj…”, aby dostosować ustawienia podobieństwa stron:
Kliknij „Edytuj…”, aby dostosować ustawienia podobieństwa stron:.PNG) Metoda porównywania tekstu używa 3 parametrów, aby ograniczyć, jak różne mogą być dwie „podobne” strony. Zmieniając te parametry, możliwe jest wykrycie stron, które mają inny stopień podobieństwa.
Metoda porównywania tekstu używa 3 parametrów, aby ograniczyć, jak różne mogą być dwie „podobne” strony. Zmieniając te parametry, możliwe jest wykrycie stron, które mają inny stopień podobieństwa.
- Minimalne dopuszczalne podobieństwo tekstu strony (w procentach) – jest to wartość metryki podobieństwa cosinusowego wyrażona w procentach. Określ minimalne dozwolone podobieństwo tekstu strony w zakresie od 70 do 100 (w procentach).
- Maksymalna dozwolona różnica długości strony (w znakach).
- Maksymalna dozwolona różnica tekstu strony (w słowach).
Użyj tych ustawień do eksperymentowania z ustawieniami przetwarzania, gdy konieczne jest dostosowanie algorytmu przetwarzania dla określonego dokumentu.
.PNG) Użyj przykładowych stron Opcjonalnie kliknij przycisk „Ustaw z przykładowej strony…”, aby określić ustawienia podobieństwa stron na podstawie dwóch przykładowych stron:
Użyj przykładowych stron Opcjonalnie kliknij przycisk „Ustaw z przykładowej strony…”, aby określić ustawienia podobieństwa stron na podstawie dwóch przykładowych stron:.PNG) Wybierz dwie strony, które można uznać za identyczne. Program automatycznie obliczy podobieństwo stron, a statystyka pojawi się w lewym dolnym rogu okna dialogowego. Kliknij „OK”, aby zapisać bieżące ustawienia podobieństwa.
Wybierz dwie strony, które można uznać za identyczne. Program automatycznie obliczy podobieństwo stron, a statystyka pojawi się w lewym dolnym rogu okna dialogowego. Kliknij „OK”, aby zapisać bieżące ustawienia podobieństwa..PNG) Określanie opcji filtrowania tekstu Istnieje kilka parametrów, które kontrolują zawartość strony analizowaną przez algorytm porównywania tekstu. Użyj tych opcji podczas porównywania zeskanowanych dokumentów papierowych, które mogą zawierać różne błędy rozpoznawania tekstu. Opcje te wykluczają z przetwarzania określone rodzaje znaków. W wielu przypadkach może to pomóc w obliczeniu dokładniejszej metryki podobieństwa.
Określanie opcji filtrowania tekstu Istnieje kilka parametrów, które kontrolują zawartość strony analizowaną przez algorytm porównywania tekstu. Użyj tych opcji podczas porównywania zeskanowanych dokumentów papierowych, które mogą zawierać różne błędy rozpoznawania tekstu. Opcje te wykluczają z przetwarzania określone rodzaje znaków. W wielu przypadkach może to pomóc w obliczeniu dokładniejszej metryki podobieństwa.
- Ignoruj wielkość liter w tekście – ta opcja ignoruje wielkość liter podczas porównywania tekstu.
- Ignoruj znaki interpunkcyjne (,.!?-) – ta opcja wyklucza wszystkie znaki interpunkcyjne z porównania.
- Ignoruj znaki niealfanumeryczne – ta opcja ignoruje wszystkie znaki oprócz liter i cyfr.
Kliknij przycisk „OK”, aby zapisać ustawienia podobieństwa stron..PNG) Kliknij przycisk „OK”, aby rozpocząć wyszukiwanie bieżącego dokumentu PDF dla zduplikowanych stron:
Kliknij przycisk „OK”, aby rozpocząć wyszukiwanie bieżącego dokumentu PDF dla zduplikowanych stron:.PNG) Krok 4 – Sprawdzanie zduplikowanych stron W oknie dialogowym „Usuń zduplikowane strony” wyświetlana jest lista zduplikowanych lub prawie zduplikowanych stron. Kliknij rekord strony, aby wyświetlić odpowiednią stronę w przeglądarce. Przejrzyj strony i zaznacz/odznacz strony do usunięcia. Opcjonalnie kliknij „Zapisz raport…”, aby utworzyć raport podobieństwa stron w formacie HTML. Lub kliknij „Zakładki stron”, aby utworzyć zakładki w PDF dla wybranych zduplikowanych stron.
Krok 4 – Sprawdzanie zduplikowanych stron W oknie dialogowym „Usuń zduplikowane strony” wyświetlana jest lista zduplikowanych lub prawie zduplikowanych stron. Kliknij rekord strony, aby wyświetlić odpowiednią stronę w przeglądarce. Przejrzyj strony i zaznacz/odznacz strony do usunięcia. Opcjonalnie kliknij „Zapisz raport…”, aby utworzyć raport podobieństwa stron w formacie HTML. Lub kliknij „Zakładki stron”, aby utworzyć zakładki w PDF dla wybranych zduplikowanych stron..PNG) Wtyczka pozwala na podgląd/porównanie znalezionych zduplikowanych lub prawie zduplikowanych stron. Podobieństwo stron (w %) i liczba niedopasowanych słów jest wyświetlana dla każdej pary stron. Oto przykłady obliczone dla pary zeskanowanych dokumentów papierowych:
Wtyczka pozwala na podgląd/porównanie znalezionych zduplikowanych lub prawie zduplikowanych stron. Podobieństwo stron (w %) i liczba niedopasowanych słów jest wyświetlana dla każdej pary stron. Oto przykłady obliczone dla pary zeskanowanych dokumentów papierowych:.PNG)
.PNG) Zwróć uwagę, że wygląd i położenie tekstu nie mają wpływu na wyniki. Te dwie strony są uważane za identyczne pomimo różnicy w kolorze tekstu:
Zwróć uwagę, że wygląd i położenie tekstu nie mają wpływu na wyniki. Te dwie strony są uważane za identyczne pomimo różnicy w kolorze tekstu:.PNG) Te dwie strony są uważane za identyczne pomimo różnicy w układzie treści:
Te dwie strony są uważane za identyczne pomimo różnicy w układzie treści:.PNG) Te dwie strony są uważane za w 94% podobne pomimo różnicy w kolejności tekstu, układzie i braku obrazu:
Te dwie strony są uważane za w 94% podobne pomimo różnicy w kolejności tekstu, układzie i braku obrazu:.PNG) Krok 5 – Extract or Bookmark Duplicate Pages Opcjonalnie użyj przycisku „Bookmark Pages”, aby dodać do zakładek wszystkie sprawdzone strony. Jest to przydatne, jeśli nie planujesz usuwać znalezionych duplikatów stron z dokumentu. Użyj pól wyboru przed stronami, aby zaznaczyć/odznaczyć je z zestawu przetwarzania. Użyj przycisku „Wyodrębnij strony….”, aby wyodrębnić wszystkie zaznaczone strony do osobnego dokumentu PDF. Ta operacja nie spowoduje usunięcia stron z bieżącego dokumentu.
Krok 5 – Extract or Bookmark Duplicate Pages Opcjonalnie użyj przycisku „Bookmark Pages”, aby dodać do zakładek wszystkie sprawdzone strony. Jest to przydatne, jeśli nie planujesz usuwać znalezionych duplikatów stron z dokumentu. Użyj pól wyboru przed stronami, aby zaznaczyć/odznaczyć je z zestawu przetwarzania. Użyj przycisku „Wyodrębnij strony….”, aby wyodrębnić wszystkie zaznaczone strony do osobnego dokumentu PDF. Ta operacja nie spowoduje usunięcia stron z bieżącego dokumentu.
.PNG) Użyj przycisku „Zapisz raport…”, aby zapisać raport z obliczeń podobieństwa stron do pliku HTML. Zawiera on szczegóły podobieństwa stron, pokazuje różnice między stronami i listę brakujących słów. To może być bardzo przydatne dla dogłębnej analizy.
Użyj przycisku „Zapisz raport…”, aby zapisać raport z obliczeń podobieństwa stron do pliku HTML. Zawiera on szczegóły podobieństwa stron, pokazuje różnice między stronami i listę brakujących słów. To może być bardzo przydatne dla dogłębnej analizy.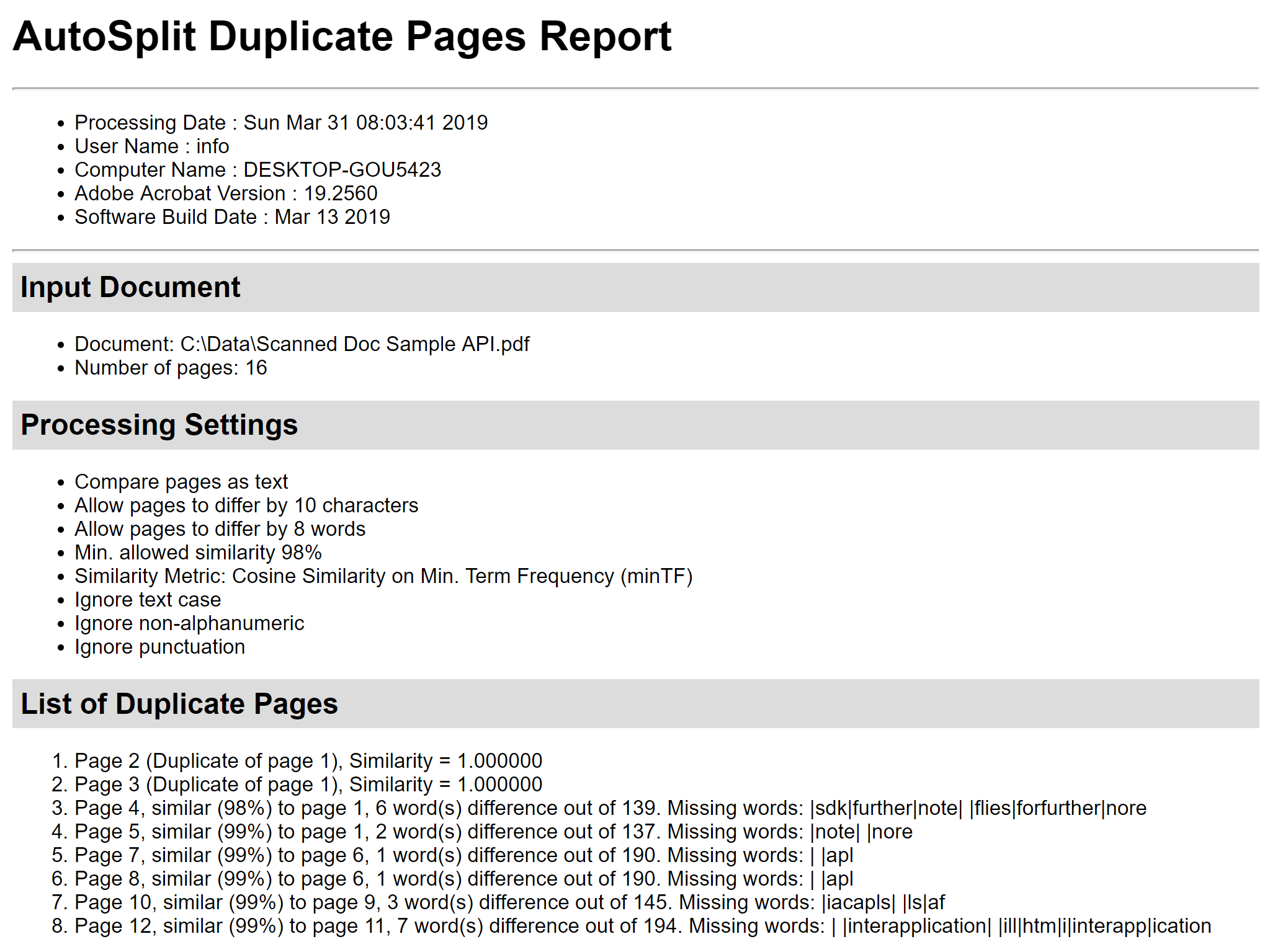 Krok 6 – Usuń zduplikowane strony Użyj pól wyboru przed stronami, aby zaznaczyć/odznaczyć strony, które mają być usunięte. Naciśnij przycisk „Usuń strony” w oknie dialogowym „Usuń duplikaty stron”, aby usunąć wszystkie zaznaczone strony z bieżącego dokumentu PDF:
Krok 6 – Usuń zduplikowane strony Użyj pól wyboru przed stronami, aby zaznaczyć/odznaczyć strony, które mają być usunięte. Naciśnij przycisk „Usuń strony” w oknie dialogowym „Usuń duplikaty stron”, aby usunąć wszystkie zaznaczone strony z bieżącego dokumentu PDF:.PNG) Kliknij przycisk „OK”, aby potwierdzić. Strony zostaną trwale usunięte.
Kliknij przycisk „OK”, aby potwierdzić. Strony zostaną trwale usunięte..PNG) Metoda 2 – Porównywanie tylko wyglądu wizualnego przegląd Ta metoda porównuje strony „jako obrazy” i wykrywa strony, które wyglądają dokładnie tak samo. Ta metoda nie porównuje żadnego niewidocznego tekstu, który może znajdować się na stronie. Nie zaleca się stosowania tej metody w przypadku zeskanowanych dokumentów papierowych. Krok 1 – Otwórz plik PDF Uruchom aplikację Adobe® Acrobat® i otwórz plik PDF za pomocą menu „Plik > Otwórz…”.Krok 2 – Otwórz okno dialogowe „Znajdź zduplikowane strony” Wybierz „Plug-Ins > Podziel dokumenty > Znajdź i usuń zduplikowane strony…”, aby otworzyć okno dialogowe „Znajdź zduplikowane strony”.Krok 3 – Określ ustawienia Zaznacz opcję „Porównaj wygląd wizualny dla dokładnego dopasowania (może być używany do porównywania obrazów)”.
Metoda 2 – Porównywanie tylko wyglądu wizualnego przegląd Ta metoda porównuje strony „jako obrazy” i wykrywa strony, które wyglądają dokładnie tak samo. Ta metoda nie porównuje żadnego niewidocznego tekstu, który może znajdować się na stronie. Nie zaleca się stosowania tej metody w przypadku zeskanowanych dokumentów papierowych. Krok 1 – Otwórz plik PDF Uruchom aplikację Adobe® Acrobat® i otwórz plik PDF za pomocą menu „Plik > Otwórz…”.Krok 2 – Otwórz okno dialogowe „Znajdź zduplikowane strony” Wybierz „Plug-Ins > Podziel dokumenty > Znajdź i usuń zduplikowane strony…”, aby otworzyć okno dialogowe „Znajdź zduplikowane strony”.Krok 3 – Określ ustawienia Zaznacz opcję „Porównaj wygląd wizualny dla dokładnego dopasowania (może być używany do porównywania obrazów)”..PNG) Kliknij „OK”, aby rozpocząć wyszukiwanie duplikatów stron. Krok 4 – Sprawdzanie zduplikowanych stron Okno dialogowe „Usuń zduplikowane strony” pokazuje listę zduplikowanych lub prawie zduplikowanych stron. Kliknij na rekord strony, aby wyświetlić odpowiadającą mu stronę w widoku obok siebie. Przeanalizuj strony i zaznacz/odznacz strony do ewentualnego usunięcia.
Kliknij „OK”, aby rozpocząć wyszukiwanie duplikatów stron. Krok 4 – Sprawdzanie zduplikowanych stron Okno dialogowe „Usuń zduplikowane strony” pokazuje listę zduplikowanych lub prawie zduplikowanych stron. Kliknij na rekord strony, aby wyświetlić odpowiadającą mu stronę w widoku obok siebie. Przeanalizuj strony i zaznacz/odznacz strony do ewentualnego usunięcia..PNG) Opcjonalnie kliknij „Zapisz raport…”, aby utworzyć raport podobieństwa stron w formacie HTML. Lub kliknij „Zakładka Strony”, aby utworzyć zakładki w PDF dla wybranych zduplikowanych stron. Metoda ta opiera się na tworzeniu mniejszych (próbkowanych) kopii stron i porównywaniu ich „jako obrazów”. Poniższy przykład pokazuje dwie identyczne strony, które zawierają tylko grafikę, a nie zawierają tekstu do przeszukiwania:
Opcjonalnie kliknij „Zapisz raport…”, aby utworzyć raport podobieństwa stron w formacie HTML. Lub kliknij „Zakładka Strony”, aby utworzyć zakładki w PDF dla wybranych zduplikowanych stron. Metoda ta opiera się na tworzeniu mniejszych (próbkowanych) kopii stron i porównywaniu ich „jako obrazów”. Poniższy przykład pokazuje dwie identyczne strony, które zawierają tylko grafikę, a nie zawierają tekstu do przeszukiwania:.PNG) Jeśli strony są wizualnie identyczne, to oprogramowanie wykrywa je jako duplikaty:
Jeśli strony są wizualnie identyczne, to oprogramowanie wykrywa je jako duplikaty:.PNG) Te dwie strony są uważane za różne ze względu na znaczek „Approved” na jednej ze stron:
Te dwie strony są uważane za różne ze względu na znaczek „Approved” na jednej ze stron:.PNG) Te dwie strony są uważane za identyczne przy użyciu tej metody:
Te dwie strony są uważane za identyczne przy użyciu tej metody:.PNG) W przeciwieństwie do metody porównywania na podstawie tekstu, jeśli kolor lub styl tekstu jest inny, to strony nie są uważane za identyczne:
W przeciwieństwie do metody porównywania na podstawie tekstu, jeśli kolor lub styl tekstu jest inny, to strony nie są uważane za identyczne:
.PNG) Krok 5 – Usuń zduplikowane strony Kliknij „Usuń strony” w oknie dialogowym „Usuń zduplikowane strony”, aby kontynuować. Kliknij przycisk „OK”, aby usunąć strony z bieżących dokumentów PDF. Strony zostaną usunięte na stałe.Porównywanie wielu dokumentów PDF Ta operacja może być użyta do znalezienia i usunięcia duplikatów stron z wielu dokumentów PDF. Podejście polega na połączeniu jednego lub więcej dokumentów w jeden plik PDF i uruchomieniu operacji „Znajdź i usuń duplikaty stron” na pliku wynikowym. W ten sposób powstanie pojedynczy dokument bez żadnych duplikatów. Opcjonalnie, możliwe jest wyodrębnienie wszystkich wykrytych duplikatów stron do osobnego dokumentu PDF. Krok 1 – Przegląd operacji łączenia wielu dokumentów PDF Uruchom aplikację Adobe® Acrobat® i wybierz „Narzędzia” z menu. Wybierz ikonę „Połącz pliki” z listy narzędzi.
Krok 5 – Usuń zduplikowane strony Kliknij „Usuń strony” w oknie dialogowym „Usuń zduplikowane strony”, aby kontynuować. Kliknij przycisk „OK”, aby usunąć strony z bieżących dokumentów PDF. Strony zostaną usunięte na stałe.Porównywanie wielu dokumentów PDF Ta operacja może być użyta do znalezienia i usunięcia duplikatów stron z wielu dokumentów PDF. Podejście polega na połączeniu jednego lub więcej dokumentów w jeden plik PDF i uruchomieniu operacji „Znajdź i usuń duplikaty stron” na pliku wynikowym. W ten sposób powstanie pojedynczy dokument bez żadnych duplikatów. Opcjonalnie, możliwe jest wyodrębnienie wszystkich wykrytych duplikatów stron do osobnego dokumentu PDF. Krok 1 – Przegląd operacji łączenia wielu dokumentów PDF Uruchom aplikację Adobe® Acrobat® i wybierz „Narzędzia” z menu. Wybierz ikonę „Połącz pliki” z listy narzędzi..PNG) Kliknij „Add Files…” w menu „Combine Files” i wybierz pliki PDF do połączenia w celu porównania.
Kliknij „Add Files…” w menu „Combine Files” i wybierz pliki PDF do połączenia w celu porównania..PNG) Kliknij przycisk „Combine” w menu, aby połączyć wybrane pliki PDF.
Kliknij przycisk „Combine” w menu, aby połączyć wybrane pliki PDF..PNG) Krok 2 – Znajdź duplikaty stron Połączony wyjściowy plik PDF pojawi się na ekranie. Jeśli nie, otwórz połączony plik PDF. Wybierz „Plug-Ins > Dzielenie dokumentów > Znajdź i usuń duplikaty stron…”, aby otworzyć okno dialogowe „Znajdź duplikaty stron”.Zaznacz opcję „Porównaj wygląd wizualny dla dokładnego dopasowania (można użyć do porównania obrazów)”. Kliknij „OK”, aby rozpocząć wyszukiwanie zduplikowanych stron.
Krok 2 – Znajdź duplikaty stron Połączony wyjściowy plik PDF pojawi się na ekranie. Jeśli nie, otwórz połączony plik PDF. Wybierz „Plug-Ins > Dzielenie dokumentów > Znajdź i usuń duplikaty stron…”, aby otworzyć okno dialogowe „Znajdź duplikaty stron”.Zaznacz opcję „Porównaj wygląd wizualny dla dokładnego dopasowania (można użyć do porównania obrazów)”. Kliknij „OK”, aby rozpocząć wyszukiwanie zduplikowanych stron..PNG) Krok 3 – Wyodrębnij zduplikowane strony W oknie dialogowym „Usuń zduplikowane strony” zostanie wyświetlona lista zduplikowanych lub prawie zduplikowanych stron. Kliknij na rekord strony, aby wyświetlić odpowiednią stronę w przeglądarce. Przejrzyj strony i zaznacz/odznacz strony. Kliknij „Wyodrębnij strony…”, aby wyodrębnić wybrane zduplikowane strony do nowego dokumentu PDF.
Krok 3 – Wyodrębnij zduplikowane strony W oknie dialogowym „Usuń zduplikowane strony” zostanie wyświetlona lista zduplikowanych lub prawie zduplikowanych stron. Kliknij na rekord strony, aby wyświetlić odpowiednią stronę w przeglądarce. Przejrzyj strony i zaznacz/odznacz strony. Kliknij „Wyodrębnij strony…”, aby wyodrębnić wybrane zduplikowane strony do nowego dokumentu PDF..PNG) Określ folder wyjściowy i nazwę pliku. Kliknij „Zapisz” po zakończeniu.
Określ folder wyjściowy i nazwę pliku. Kliknij „Zapisz” po zakończeniu..PNG) Pojawi się okno dialogowe pokazujące liczbę stron, które zostały wyodrębnione do osobnego dokumentu. Teraz masz zapisane wszystkie zduplikowane strony do oddzielnego pliku PDF przed ich usunięciem. Możesz sprawdzić te strony i użyć ich później w razie potrzeby. Kliknij „OK”, aby zamknąć okno dialogowe.
Pojawi się okno dialogowe pokazujące liczbę stron, które zostały wyodrębnione do osobnego dokumentu. Teraz masz zapisane wszystkie zduplikowane strony do oddzielnego pliku PDF przed ich usunięciem. Możesz sprawdzić te strony i użyć ich później w razie potrzeby. Kliknij „OK”, aby zamknąć okno dialogowe..png) Krok 4 – Usuń zduplikowane strony Kliknij „Usuń strony” w oknie dialogowym „Usuń zduplikowane strony”, aby kontynuować.
Krok 4 – Usuń zduplikowane strony Kliknij „Usuń strony” w oknie dialogowym „Usuń zduplikowane strony”, aby kontynuować..PNG) Kliknij „OK” w oknie dialogowym, aby usunąć wybrane duplikaty stron z bieżącego dokumentu PDF.
Kliknij „OK” w oknie dialogowym, aby usunąć wybrane duplikaty stron z bieżącego dokumentu PDF..PNG) Wybrane duplikaty stron zostaną trwale usunięte z dokumentu PDF. Musiałbyś użyć menu „Plik > Zapisz”, aby zapisać zmodyfikowany dokument na dysku. Kliknij tutaj, aby uzyskać listę wszystkich dostępnych samouczków krok po kroku.
Wybrane duplikaty stron zostaną trwale usunięte z dokumentu PDF. Musiałbyś użyć menu „Plik > Zapisz”, aby zapisać zmodyfikowany dokument na dysku. Kliknij tutaj, aby uzyskać listę wszystkich dostępnych samouczków krok po kroku.