Revised: December 11, 2020
Do the subjects tell the truth?
Wiarygodność danych self-report jest piętą achillesową badań ankietowych. Na przykład, badania opinii publicznej wskazały, że więcej niż 40 procent Amerykanów uczęszcza do kościoła co tydzień. Jednak Hadaway i Marlar (2005), badając dane dotyczące frekwencji w kościołach, doszli do wniosku, że faktyczna frekwencja wynosiła mniej niż 22 procent. W swojej przełomowej pracy „Wszyscy kłamią”, Seth Stephens-Davidowitz (2017) znalazł wiele dowodów na to, że większość ludzi nie robi tego, co mówi i nie mówi tego, co robi. Na przykład, w odpowiedzi na sondaże większość wyborców deklaruje, że pochodzenie etniczne kandydata jest nieistotne. Jednak poprzez sprawdzenie wyszukiwanych terminów w Google Sephens-Davidowitz stwierdził, że jest inaczej. Konkretnie, kiedy użytkownicy Google wpisywali słowo „Obama”, zawsze kojarzyli jego nazwisko z jakimiś słowami związanymi z rasą.
Dla badań nad instrukcjami opartymi na sieci Web, dane użytkowania sieci mogą być uzyskane przez parsowanie dziennika dostępu użytkownika, ustawianie plików cookie lub ładowanie pamięci podręcznej. Jednakże, te opcje mogą mieć ograniczone zastosowanie. Na przykład, dziennik dostępu użytkownika nie może śledzić użytkowników, którzy podążają za linkami do innych stron internetowych. Ponadto, podejścia oparte na plikach cookie lub pamięci podręcznej mogą powodować problemy związane z prywatnością. W takich sytuacjach wykorzystuje się dane własne zbierane za pomocą ankiet. W związku z tym pojawia się pytanie: Jak dokładne są dane deklarowane przez samych siebie? | W którym roku [ubiegał się Pan/ubiegała się Pani] o rentę inwalidzką z tytułu niezdolności do pracy lub o dodatek opiekuńczy? | Czy kiedykolwiek [ubiegał się Pan/ubiegała się Pani] o rentę inwalidzką z tytułu niezdolności do pracy lub o dodatek opiekuńczy? Psychologowie ostrzegają, że ludzka pamięć jest zawodna (Loftus, 2016; Schacter, 1999). Czasami ludzie „pamiętają” wydarzenia, które nigdy się nie wydarzyły. W związku z tym wiarygodność danych raportowanych przez samego siebie jest wątpliwa.Chociaż pakiety oprogramowania statystycznego są w stanie obliczyć liczby do 16-32 miejsc po przecinku, ta precyzja jest bez znaczenia, jeśli dane nie mogą być dokładne nawet na poziomie liczby całkowitej. Całkiem sporo uczonych ostrzegało badaczy, jak błąd pomiaru może sparaliżować analizę statystyczną (Blalock, 1974) i sugerowało, że dobra praktyka badawcza wymaga zbadania jakości zebranych danych (Fetter,Stowe, & Owings, 1984).
Bias and Variance
Błędy pomiaru obejmują dwa składniki, mianowicie, błąd systematyczny i błąd zmiennej.Bias jest błędem systematycznym, który ma tendencję do przesuwania zgłoszonego wyniku w kierunku jednego skrajnego końca. Na przykład, kilka wersji testów IQ sąfound być uprzedzenie wobec nie-białych. Oznacza to, że czarni i Latynosi otrzymują niższe wyniki, niezależnie od ich rzeczywistej inteligencji. Błąd zmiennej, znany również jako wariancja, ma tendencję do bycia przypadkowym. W innych słowach, raportowane wyniki mogą być powyżej lub poniżej rzeczywistych wyników (Salvucci, Walter, Conley, Fink, Saba, 1997).
Jeden może argumentować, że zmienne błędy, które są przypadkowe w naturze, wouldcancel out siebie i dlatego może nie być zagrożeniem dla badania. Na przykład, pierwszy użytkownik może przeceniać swoją aktywność w Internecie o 10%, ale drugi użytkownik może niedoceniać swojej o 10%. W tym przypadku średnia może być nadal poprawna. Jednak przeszacowanie i niedoszacowanie zwiększa zmienność rozkładu. W wielu testachparametrycznych zmienność wewnątrzgrupowa jest używana jako składnik błędu. Zawyżona zmienność z pewnością wpłynęłaby na istotność testu. Niektóre teksty mogą wzmacniać powyższe błędne przekonanie. Na przykład Deese (1972) powiedział:
Teoria statystyczna mówi nam, że wiarygodność obserwacji jest proporcjonalna do pierwiastka kwadratowego z ich liczby. Im więcej jest obserwacji, tym większy będzie wpływ losowy. A teoria statystyczna utrzymuje, że im więcej jest błędów losowych, tym bardziej prawdopodobne jest, że zniosą się one nawzajem i stworzą rozkład normalny (str. 55). Po drugie, wiarygodność (jakość danych) powinna być związana raczej z pomiarem niż z określeniem wielkości próby. Duży rozmiar próbki z wieloma błędami pomiaru, nawet przypadkowymi, spowodowałby zawyżenie terminu błędu dla testów parametrycznych.
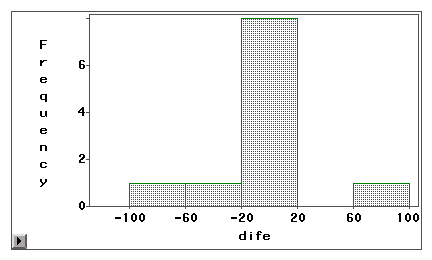
Do wizualnego zbadania, czy błąd pomiaru jest spowodowany systematyczną tendencyjnością czy przypadkową wariancją, można użyć wykresu łodygi i liści lub histogramu. W poniższym przykładzie, dwa rodzaje dostępu do Internetu (przeglądanie stron WWW i poczta elektroniczna) są mierzone zarówno przez ankietę, jak i dziennik. | W którym roku [ubiegał się Pan/ubiegała się Pani] o rentę inwalidzką z tytułu niezdolności do pracy lub o dodatek opiekuńczy? Niedoszacowanie i przeszacowanie pojawia się w pobliżu obu końców, co sugeruje, że błąd pomiaru jest raczej błędem losowym niż systematyczną stronniczością.
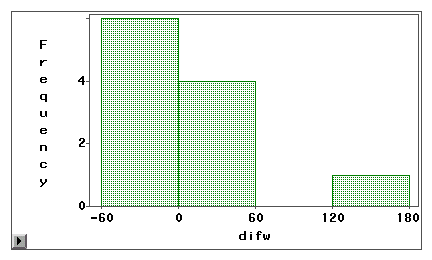
Drugi wykres wyraźnie wskazuje, że istnieje wysoki stopień błędów pomiaru, ponieważ bardzo niewiele wyników różnic jest wyśrodkowanych wokół zera. Co więcej, rozkład jest ujemnie skośny i dlatego błąd jest błędem systematycznym, a nie wariancją.
Jak wiarygodna jest nasza pamięć?
Schacter (1999) ostrzegł, że ludzka pamięć jest zawodna. Istnieje siedem wad naszej pamięci:
- Przemijalność: Zmniejszająca się dostępność informacji w czasie.
- Absent-mindedness: Nieuważne lub płytkie przetwarzanie, które przyczynia się do słabych wspomnień.
- Blokowanie: Czasowa niedostępność informacji, które są przechowywane w pamięci.
- Błędna atrybucja Przypisywanie wspomnienia lub idei do niewłaściwego źródła.
- Sugestywność: Wspomnienia, które są wszczepiane w wyniku wiodących pytań lub oczekiwań.
- Uprzedzenia: Retrospektywne zniekształcenia i nieświadome wpływy, które są związane z aktualną wiedzą i przekonaniami.
- Uporczywość: Patologiczne wspomnienia-informacje lub wydarzenia, których nie możemy zapomnieć, mimo że bardzo byśmy tego chcieli.
„Nie mam żadnych wspomnień na ten temat. Nie przypominam sobie, żebym podpisał dokument dlaWhitewater. Nie pamiętam, dlaczego ten dokument zniknął, ale pojawił się później. Nic nie pamiętam.”
„Pamiętam, że lądowałem (w Bośni) pod ostrzałem snajperów. Na lotnisku miała się odbyć jakaś ceremonia powitalna, ale zamiast tego biegliśmy ze spuszczonymi głowami, aby wsiąść do pojazdów i dotrzeć do naszej bazy.”
Podczas śledztwa w sprawie przesyłania informacji niejawnych za pośrednictwem prywatnego serwera e-mail, Clinton powiedziała FBI, że 39 razy nie może sobie niczego „przypomnieć” lub „przypomnieć”.Uwaga: Odkryty zostaje nowy wirus komputerowy o nazwie „Clinton”. Jeśli komputer jest zainfekowany, będzie często wyskakiwał ten komunikat „brak pamięci”, nawet jeśli ma wystarczającą ilość pamięci RAM.
P: „Skoro Vernon Jordon powiedział nam, że ma pan niezwykłą pamięć, jedną z najlepszych, jakie kiedykolwiek widział u polityka, czy zechciałby pan z tym polemizować?” A: „Mam dobrą pamięć…Ale nie pamiętam, czy byłem sam na sam z Moniką Lewinsky, czy nie. Jak mógłbym śledzić tak wiele kobiet w moim życiu?”
Q: Dlaczego Clinton polecił Lewinsky do pracy w Revlon?
A: Wiedział, że będzie dobra w zmyślaniu rzeczy.
Należy zauważyć, że czasami wiarygodność naszej pamięci jest związana z pożądanym wynikiem. Na przykład, gdy medicalresearcher próbuje zebrać odpowiednie dane od matek, których dzieci są zdrowe i matek, których dzieci są malformed, dane z tych ostatnich jest zazwyczaj bardziej dokładne niż te z pierwszej. Dzieje się tak dlatego, że matki zdeformowanych dzieci dokładnie analizują każdą chorobę, która wystąpiła w czasie ciąży, każdy przyjmowany lek, każdy szczegół bezpośrednio lub zdalnie związany z tragedią, próbując znaleźć wyjaśnienie. Wręcz przeciwnie, matki zdrowych niemowląt nie przywiązują dużej wagi do poprzednich informacji (Aschengrau & SeageIII, 2008). Zawyżanie GPA to kolejny przykład tego, jak desperackość wpływa na dokładność pamięci i integralność danych. W niektórych sytuacjach istnieje różnica między płciami w zawyżaniu GPA. Badanie przeprowadzone przez Caskie etal. (2014) wykazało, że w grupie studentów studiów licencjackich o niższym GPA kobiety częściej zgłaszały wyższe niż rzeczywiste GPA niż mężczyźni.
Aby przeciwdziałać problemowi błędów pamięci, niektórzy badacze sugerowali zbieranie danych związanych z chwilową myślą lub odczuciem uczestnika, zamiast proszenia go o przypomnienie sobie odległych wydarzeń (Csikszentmihalyi & Larson, 1987; Finnigan & Vazire,2018). Poniższe przykłady są pozycjami ankiety w 2018 Programme forInternational Student Assessment: „Czy wczoraj byłeś traktowany z szacunkiem przez cały dzień?”. „Did you smile or laugh a lot yesterday?” (Czy dużo się wczoraj uśmiechałeś lub śmiałeś?). „Did youlearn or do something interesting yesterday?” (Organisation forEconomic Cooperation and Development, 2017). Odpowiedź zależy jednak od tego, co działo się z uczestnikiem w danym momencie, co może nie być typowe. W szczególności, nawet jeśli respondent nie uśmiechał się lub nie śmiał się wczoraj, nie musi to oznaczać, że respondent jest zawsze nieszczęśliwy.
Co powinniśmy zrobić?
Niektórzy badacze odrzucają wykorzystanie danych z raportów własnych z powodu ich rzekomej niskiej jakości. Na przykład, kiedy grupa naukowców badała, czy wysoka religijność doprowadziła do mniejszego przestrzegania dyrektyw „shelter-in-placed” w Stanach Zjednoczonych podczas pandemii COVID19, użyli oni liczby kongregacji na 10 000 mieszkańców jako przybliżonej miary religijności regionu, zamiast samoreprezentacji religijności, która ma tendencję do odzwierciedlania pożądania społecznego (DeFranza, Lindow, Harrison, Mishra, &Mishra, 2020).
- Gdy log dostępu użytkownika jest dostępny dla badacza, może on poprosić badanych o raportowanie częstotliwości ich dostępu do serwera WWW.Badani nie powinni być poinformowani, że ich aktywność internetowa została zarejestrowana przez webmastera, ponieważ może to wpłynąć na zachowanie uczestnika.
- Badacz może poprosić podzbiór użytkowników o prowadzenie dziennika ich aktywności internetowej przez miesiąc. Po tym czasie, ci sami użytkownicy są proszeni o wypełnienie ankiety dotyczącej ich korzystania z sieci.
Ktoś może argumentować, że podejście z dziennikiem jest zbyt wymagające. W rzeczywistości, w wielu badaniach naukowych, badani są proszeni o znacznie więcej niż to. Na przykład, kiedy naukowcy badali, jak głęboki sen podczas podróży kosmicznych dalekiego zasięgu wpłynie na ludzkie zdrowie, uczestnicy zostali poproszeni o leżenie w łóżku przez miesiąc. W badaniu dotyczącym tego, jak zamknięte środowisko wpływa na ludzką psychologię podczas podróży kosmicznych, badani byli zamknięci w pokoju indywidualnie przez miesiąc, zbyt. Po zebraniu danych z różnych źródeł można przeanalizować rozbieżności między dziennikiem a danymi podawanymi przez samych siebie, aby oszacować wiarygodność danych. Na pierwszy rzut oka, to podejście wygląda jak wiarygodność test-retest, ale nią nie jest. Po pierwsze, w wiarygodności test-retest narzędzie użyte w dwóch lub więcej sytuacjach powinno być takie samo. Po drugie, kiedy wiarygodność test-retest jest niska, źródło błędów znajduje się wewnątrz instrumentu. Jednakże, kiedy źródło błędów jest zewnętrzne w stosunku do instrumentu, takie jak błędy ludzkie, rzetelność międzykontrolna jest bardziej odpowiednia.
Powyższa sugerowana procedura może być skonceptualizowana jako pomiar rzetelności między danymi, która przypomina pomiar rzetelności międzykontrolnej i powtarzanych pomiarów. Istnieją cztery sposoby szacowania wiarygodności międzylaboratoryjnej, a mianowicie współczynnik Kappa, wskaźnik niespójności, ANOVA i analiza regresji. W następnej części opisano, w jaki sposób te pomiary wiarygodności międzyosobowej mogą być wykorzystywane jako pomiary wiarygodności danych wewnętrznych.
Współczynnik Kappa
W badaniach psychologicznych i edukacyjnych, nie jest niczym niezwykłym zatrudnianie dwóch lub więcej oceniających w procesie pomiaru, gdy ocena obejmuje subiektywne osądy (np. ocenianie esejów). Wiarygodność międzyosobnicza, mierzona współczynnikiem Kappa, jest używana do wskazania wiarygodności danych. Na przykład, wyniki uczestników są oceniane przez dwóch lub więcej oceniających jako „mistrzowskie” lub „nie-mistrzowskie” (1 lub 0). Tak więc, ten pomiar jest zwykle obliczany w procedurach analizy danych kategorycznych, takich jak PROC FREQ w SAS, „pomiar porozumienia” w SPSS lub kalkulator Kappa online (Lowry, 2016). Poniższy obrazek to zrzut ekranu kalkulatora online Vassarstats.
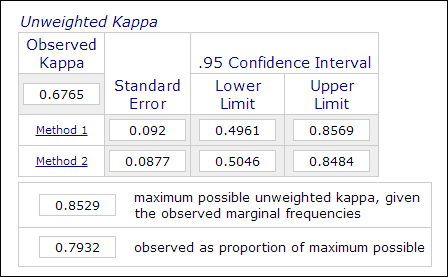
Należy zauważyć, że nawet jeśli 60 procent dwóch zestawów danych zgadza się ze sobą, nie oznacza to, że pomiary są wiarygodne.Ponieważ wynik jest dychotomiczny, istnieje 50 procent szans, że dwa pomiary się zgadzają. Współczynnik Kappa bierze to pod uwagę i wymaga wyższego stopnia dopasowania, aby osiągnąć spójność.
W kontekście instrukcji internetowych, każda kategoria samodzielnie zgłoszonego korzystania z witryny internetowej może być przekodowana jako zmienna binarna. Na przykład, kiedy pytanie pierwsze brzmi „jak często używasz telnetu”, możliwe odpowiedzi kategoryczne to „a: codziennie”, „b: trzy do pięciu razy na tydzień”, „c: trzy do pięciu razy na miesiąc”, „d: rzadko” i „e: nigdy”. W tym przypadku, pięć kategorii można przekodować na pięć zmiennych: Q1A, Q1B, Q1C, Q1D i Q1E. Następnie wszystkie te zmienne binarne mogą być dołączone w celu utworzenia tabeli R X 2, jak pokazano w poniższej tabeli.z tej struktury danych, odpowiedzi mogą być kodowane jako „1” lub „0”, a zatem pomiar porozumienia klasyfikacyjnego jest możliwe. Zgodność może być obliczona przy użyciu współczynnika Kappa, a tym samym wiarygodność danych może być oszacowana.
Przedmioty Dane z dziennika Dane z raportu własnegodane z raportu Przedmiot 1 1 1 Przedmiot 2 0 0 Podmiot 3 1 0 Podmiot>. Przedmiot 4 0 1 Indeks niespójności
Innym sposobem obliczania wyżej wymienionych danych kategorycznych jest indeks niespójności (IOI). W powyższym przykładzie, ponieważ istnieją dwa pomiary (log i self-reported data) i pięć opcji w odpowiedzi, tworzona jest tabela 4 X 4. Pierwszym krokiem do obliczenia IOI jest podzielenie tabeli RXC na kilka podtablic 2X2. Na przykład, ostatnia opcja „nigdy” jest traktowana jako jedna kategoria, a wszystkie pozostałe są łączone w inną kategorię jako „nie nigdy”, jak pokazano w poniższej tabeli.
Dane własnereported data Log Nigdy Nie nigdy Ogółem Nigdy a .
b a+b Nigdy c d c+d Total a+c b+d n=Sum(a-d) Procentowy udział IOI oblicza się według następującego wzoru:
IOI% = 100*(b+c)/ gdzie p = (a+c)/n
Po obliczeniu IOI dla każdej tabeli cząstkowej 2X2, średnia wszystkich indeksów jest używana jako wskaźnik niespójności środka. Kryterium pozwalające ocenić, czy dane są spójne, jest następujące:
- IOI poniżej 20 oznacza niską wariancję
- IOI między 20 a 50 oznacza umiarkowaną wariancję
- IOI powyżej 50 oznacza wysoką wariancję
Wieloletnia wiarygodność danych jest wyrażona następującym równaniem: r = 1 – IOI
Współczynnik korelacji wewnątrzklasowej
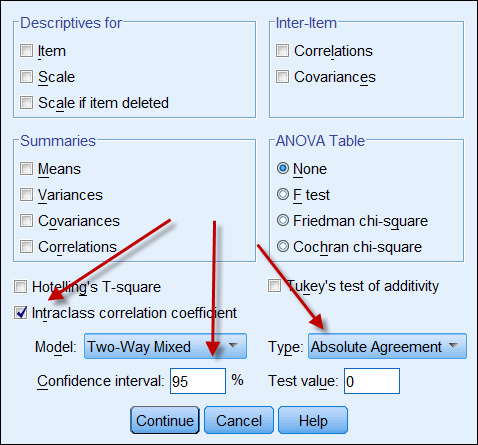
Jeśli oba źródła danych dają dane ciągłe, to można obliczyć współczynnik korelacji wewnątrzklasowej, aby wskazać wiarygodność danych. Poniżej znajduje się zrzut ekranu z opcjami ICC w SPSS. W typie znajdują się dwie opcje: „spójność” i „zgodność bezwzględna”. Jeśli wybrana jest „zgodność”, to nawet jeśli jeden zestaw liczb jest spójny wysoko (np. 9, 8, 9, 8, 7…), a drugi jest spójny nisko (np. 4,3, 4, 3, 2…), ich silna korelacja błędnie sugeruje, że dane są zgodne ze sobą. W związku z tym zaleca się wybór opcji „absolute agreement”.
Repeated measures
Pomiar wiarygodności między danymi może być również konceptualizowany i proceduralizowany jako repeated measuresANOVA. W ANOVA powtarzanych środków, pomiary są podawane do tych samych obiektów kilka razy, takie jak pretest, midterm i posttest. W tym kontekście, osoby badane są również wielokrotnie mierzone za pomocą dziennika użytkownika sieci, dziennika i ankiety własnej. Poniżej znajduje się kod SAS dla ANOVA z powtarzanymi działaniami:
data one; input user $ web_log log_book self_report;
cards;
1 215 260 200
2 178 200 150
3 100 111 120
4 135 172 100
5 139 150 140
6 198 200 230
7 135 150 180
8 120 110 100
9 289 276 300
proc glm;
classes user;
model web_log log_book self_report = user;
repeated time 3;
run;
W powyższym programie, liczba odwiedzonych stron internetowych przez dziewięciu ochotników jest rejestrowana w dzienniku dostępu użytkownika, osobistym dzienniku i ankiecie własnej. Użytkownicy są traktowani jako czynnik między-podmiotowy, podczas gdy trzy środki są traktowane jako czynnik między-środowiskowy. Poniżej przedstawiono skondensowane dane wyjściowe:
Źródło zmienności DF Średnia kwadratowa Pomiędzy-przedmiot (użytkownik) 8 10442.50 Between-measure (time) 2 488.93 Residual 16 454.80 Na podstawie powyższych informacji można obliczyć współczynnik wiarygodności, korzystając z tego wzoru (Fisher, 1946; Horst, 1949):
r = MSbetween-measure – MSresidual —————————————————-.———- MSbetween-measure + (dfbetween-people X MSresidual) Wprowadźmy tę liczbę do wzoru:
r = 488.93 – 454,80 ————————————— 488,93 + ( 8 X 454,80) Wieloletnia wiarygodność wynosi około .0008, czyli jest bardzo niska. Dlatego możemy iść do domu i zapomnieć o tych danych. Na szczęście jest to tylko hipotetyczny zestaw danych. Ale co, jeśli jest to prawdziwy zestaw danych? Musisz być wystarczająco twardy, aby zrezygnować ze słabych danych, zamiast publikować wyniki, które są całkowicie niewiarygodne.
Analiza korelacyjna i regresyjna
Analiza korelacyjna, która wykorzystuje współczynnik momentu produktu Pearsona, jest bardzo prosta i szczególnie przydatna, gdy skale dwóch pomiarów nie są takie same. Na przykład, dziennik serwera WWW może śledzić liczbę wejść na strony, podczas gdy dane własne są skalowane w skali Likerta (np. Jak często przeglądasz Internet? 5=bardzo często,4=często, 3=kiedyś, 2=rzadko, 5=nigdy). W tym przypadku, wyniki raportowane przez samego siebie mogą być użyte jako predyktor do regresji względem dostępu do strony.
Referencja
- Aschengrau, A., & Seage III, G. (2008). Essentials of epidemiology in public health. Boston, MA: Jones and Bartlett Publishers.
- Blalock, H. M. (1974). (Ed.) Pomiar w naukach społecznych: Teorie i strategie. Chicago, Illinois: Aldine Publishing Company.
- Caskie, G. I. L., Sutton, M. C., & Eckhardt, A. G.(2014). Accuracy of self-reported college GPA: Gender-moderateddifferences by achievement level and academic self-efficacy. Journal of College Student Development, 55, 385-390. 10.1353/csd.2014.0038
- Chan, D. (2009). Więc po co mnie pytać? Czy dane z raportów własnych są naprawdę takie złe? In Charles E. Lance and Robert J. Vandenberg (Eds.), Statistical and methodological myths and urban legends: Doctrine, verity and fable in the organizational and social sciences (pp309-335). New York, NY: Routledge.
- Cook, T. D., & Campbell, D. T. (1979). Quasi-eksperymenty: Zagadnienia projektowania i analizy. Boston, MA: Houghton Mifflin Company.
- Csikszentmihalyi, M., & Larson, R. (1987). Validity and reliability of the experience-sampling method. Journal of Nervous and Mental Disease, 175, 526-536. https://doi.org/10.1097/00005053-198709000-00004
- Deese, J. (1972). Psychologia jako nauka i sztuka. New York, NY: Harcourt Brace Jovanovich, Inc.
- DeFranza, D., Lindow, M., Harrison, K., Mishra, A., &Mishra, H. (2020, August 10). Religia i reakcja na wytyczne COVID-19mitigation. American Psychologist. Advance online publication. http://dx.doi.org/10.1037/amp0000717.
- Fetters, W., Stowe, P., & Owings, J. (1984). High School and Beyond. A national longitudinal study for the 1980s, quality of responses of high school students to questionnaire items. (NCES 84-216).Washington, D. C.: U.S. Department of Education. Office of EducationalResearch and Improvement. National center for Education Statistics.
- Finnigan, K. M., & Vazire, S. (2018). The incrementalvalidity of average state self-reports over global self-reports ofpersonality. Journal of Personality and Social Psychology, 115, 321-337. https://doi.org/10.1037/pspp0000136
- Fisher, R. J. (1946). Statistical methods for research workers (10th ed.). Edinburgh, UK: Oliver and Boyd.
- Hadaway, C. K., & Marlar, P. L. (2005). Ilu Amerykanów uczestniczy w nabożeństwach każdego tygodnia? An alternative approach tomeasurement? Journal for the Scientific Study of Religion, 44, 307-322. DOI: 10.1111/j.1468-5906.2005.00288.x
- Hart, W.; & Tomazic, T. (1999 August). Comparison ofpercentile distributions for anthropometric measures between three datasets. Referat przedstawiony na Annual Joint Statistical Meeting, Baltimore, MD.
- Horst, P. (1949). A Generalized expression for the reliability of measures. Psychometrika, 14, 21-31.
- Khoury, M., James, L., & Erikson, J. (1994). On the use of affected controls to address recall bias in case-control studiesof birth defects. Teratology, 49, 273-281.
- Loftus, E. (2016, kwiecień). The fiction of memory. Referat przedstawiony na zjeździe Zachodniego Towarzystwa Psychologicznego. Long Beach, CA.
- Lowry, R. (2016). Kappa jako miara zgodności w sortowaniu kategorialnym. Retrieved from http://vassarstats.net/kappa.html
- Organizacja Współpracy Gospodarczej i Rozwoju. (2017). Kwestionariusz dobrostanu dla potrzeb badania PISA 2018. Paris: Autor. Retrieved from https://www.oecd.org/pisa/data/2018database/CY7_201710_QST_MS_WBQ_NoNotes_final.pdf
- Schacter, D. L. (1999). Siedem grzechów pamięci: Insights from psychology and cognitive neuroscience. Psychologia Amerykańska, 54, 182-203.
- Salvucci, S.; Walter, E., Conley, V; Fink, S; & Saba, M. (1997). Badania błędów pomiaru w Narodowym Centrum Statystyki Edukacji. Washington D. C.: U. S. Department of Education.
- Stephens-Davidowitz, S. (2017). Wszyscy kłamią: Big data, new data i co internet może nam powiedzieć o tym, kim naprawdę jesteśmy. New York, NY: Dey Street Books.
Przejdź do menu głównego
.
. Nawigacja
Inne kursy
Szukacz

Kontakt ze mną