- Wprowadzenie
- Cel
- A. Metody filtrów
- Test Chi kwadrat
- Fisher’s Score
- Współczynnik korelacji
- Próg wariancji
- Mean Absolute Difference (MAD)
- Współczynnik dyspersji
- B. Metody opakowujące:
- Forward Feature Selection
- Backward Feature Elimination
- Wyczerpująca selekcja cech
- Recursywna eliminacja cech
- C. Metody wbudowane:
- LASSO Regularization (L1)
- Las losowy Znaczenie
- Wniosek
Wprowadzenie
Budując model uczenia maszynowego w prawdziwym życiu, prawie rzadko zdarza się, że wszystkie zmienne w zbiorze danych są użyteczne do budowy modelu. Dodawanie nadmiarowych zmiennych zmniejsza zdolność generalizacji modelu i może również zmniejszyć ogólną dokładność klasyfikatora. Ponadto dodawanie coraz większej ilości zmiennych do modelu zwiększa jego ogólną złożoność.
Jak wynika z prawa parsymonii 'Brzytwy Occama’, najlepszym wyjaśnieniem problemu jest to, które obejmuje najmniejszą ilość możliwych założeń. Dlatego też selekcja cech staje się nieodzowną częścią budowania modeli uczenia maszynowego.
Cel
Celem selekcji cech w uczeniu maszynowym jest znalezienie najlepszego zestawu cech, który pozwala na zbudowanie użytecznych modeli badanych zjawisk.
Techniki selekcji cech w uczeniu maszynowym mogą być szeroko sklasyfikowane w następujących kategoriach:
Techniki nadzorowane: Techniki te mogą być stosowane dla danych oznaczonych i są wykorzystywane do identyfikacji odpowiednich cech w celu zwiększenia efektywności modeli nadzorowanych, takich jak klasyfikacja i regresja.
Techniki nienadzorowane: Techniki te mogą być stosowane dla danych nieoznakowanych.
Z taksonomicznego punktu widzenia techniki te są klasyfikowane jako:
A. Metody filtrujące
B. Metody opakowujące
C. Metody osadzone
D. Metody hybrydowe
W tym artykule omówimy kilka popularnych technik selekcji cech w uczeniu maszynowym.
A. Metody filtrów
Metody filtrów wyłapują wewnętrzne właściwości cech mierzone za pomocą statystyki jednoczynnikowej zamiast wydajności walidacji krzyżowej. Metody te są szybsze i mniej kosztowne obliczeniowo niż metody typu wrapper. Kiedy mamy do czynienia z danymi wielowymiarowymi, tańsze obliczeniowo jest użycie metod filtrujących.
Przedyskutujmy niektóre z tych technik:
Zysk informacji
Zysk informacji oblicza redukcję entropii z transformacji zbioru danych. Może być użyty do selekcji cech poprzez ocenę zysku informacyjnego każdej zmiennej w kontekście zmiennej docelowej.
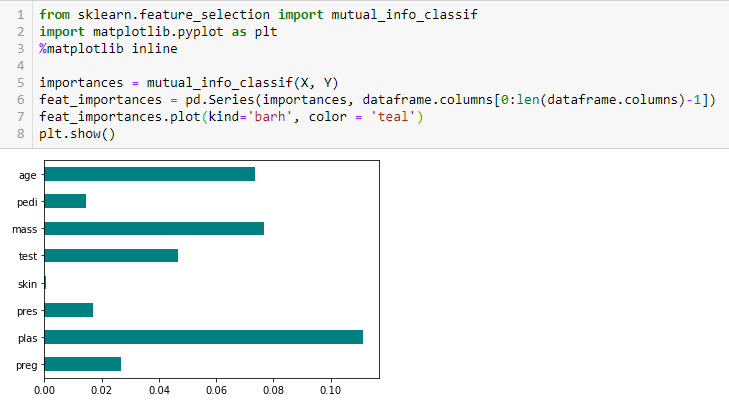
Test Chi kwadrat
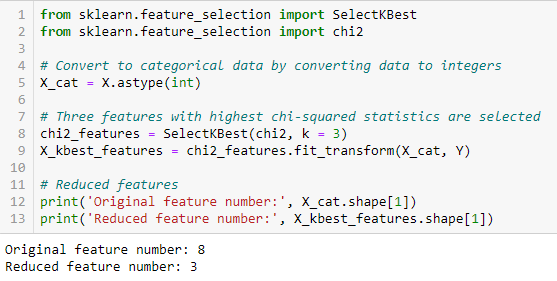
Test Chi kwadrat jest używany dla cech kategorycznych w zbiorze danych. Obliczamy Chi-kwadrat pomiędzy każdą cechą a celem i wybieramy pożądaną liczbę cech z najlepszymi wynikami Chi-kwadrat. Aby poprawnie zastosować chi-squared do testowania zależności pomiędzy różnymi cechami w zbiorze danych a zmienną docelową, muszą być spełnione następujące warunki: zmienne muszą być kategoryczne, próbkowane niezależnie, a wartości powinny mieć oczekiwaną częstość większą niż 5.
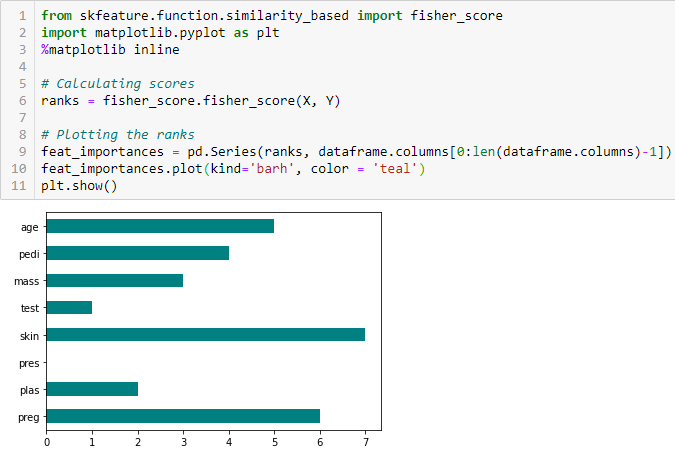
Fisher’s Score
Fisher score jest jedną z najczęściej stosowanych metod nadzorowanej selekcji cech. Algorytm, którego użyjemy, zwraca rangi zmiennych na podstawie wyniku Fishera w porządku malejącym. Możemy następnie wybrać zmienne zgodnie z przypadkiem.
Współczynnik korelacji
Korelacja jest miarą liniowego związku 2 lub więcej zmiennych. Poprzez korelację, możemy przewidzieć jedną zmienną na podstawie drugiej. Logika stojąca za użyciem korelacji do wyboru cech jest taka, że dobre zmienne są wysoko skorelowane z celem. Ponadto, zmienne powinny być skorelowane z celem, ale powinny być nieskorelowane między sobą.
Jeśli dwie zmienne są skorelowane, możemy przewidzieć jedną z nich na podstawie drugiej. Dlatego, jeśli dwie cechy są skorelowane, model tak naprawdę potrzebuje tylko jednej z nich, ponieważ druga nie dodaje dodatkowej informacji. Użyjemy tutaj korelacji Pearsona.
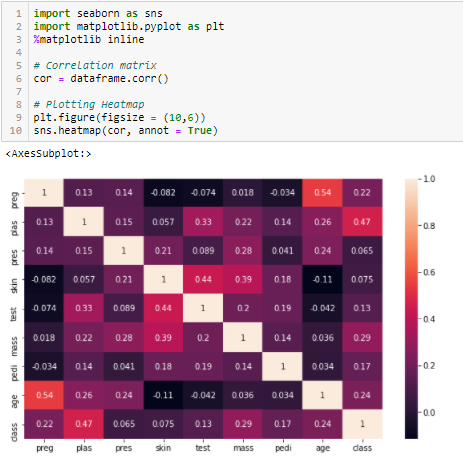
Musimy ustalić wartość bezwzględną, powiedzmy 0,5 jako próg wyboru zmiennych. Jeśli stwierdzimy, że zmienne predykcyjne są skorelowane między sobą, możemy zrezygnować ze zmiennej, która ma niższą wartość współczynnika korelacji ze zmienną docelową. Możemy również obliczyć współczynniki korelacji wielokrotnej, aby sprawdzić, czy więcej niż dwie zmienne są ze sobą skorelowane. Zjawisko to znane jest jako wieloliniowość.
Próg wariancji
Próg wariancji jest prostym, bazowym podejściem do selekcji cech. Usuwa wszystkie cechy, których wariancja nie spełnia pewnego progu. Domyślnie usuwa wszystkie cechy o zerowej wariancji, czyli takie, które mają taką samą wartość we wszystkich próbkach. Zakładamy, że cechy o wyższej wariancji mogą zawierać więcej użytecznych informacji, ale należy pamiętać, że nie bierzemy pod uwagę zależności pomiędzy zmiennymi cech lub zmiennymi cech i zmiennymi celu, co jest jedną z wad metod filtracyjnych.

The get_support zwraca wektor Boolean, gdzie True oznacza, że zmienna nie ma zerowej wariancji.
Mean Absolute Difference (MAD)
’Średnia różnica bezwzględna (MAD) oblicza bezwzględną różnicę od wartości średniej. Główną różnicą między wariancją i MAD jest brak kwadratu w tej ostatniej. MAD, podobnie jak wariancja, jest również wariantem skali. Oznacza to, że wyższa MAD, wyższa moc dyskryminacyjna.
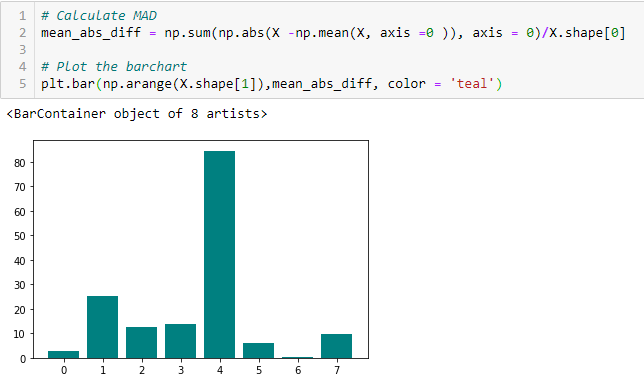
Współczynnik dyspersji
’Inna miara dyspersji stosuje średnią arytmetyczną (AM) i średnią geometryczną (GM). Dla danej (pozytywnej) cechy Xi na n wzorach, AM i GM są dane przez
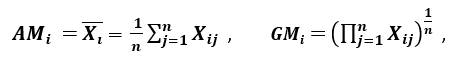
odpowiednio; ponieważ AMi ≥ GMi, z równością zachodzącą wtedy i tylko wtedy, gdy Xi1 = Xi2 = …. = Xin, wtedy stosunek
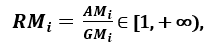
może być użyty jako miara rozproszenia. Wyższa dyspersja oznacza wyższą wartość Ri, a więc cechę bardziej istotną. I odwrotnie, gdy wszystkie próbki cech mają (w przybliżeniu) tę samą wartość, Ri jest bliskie 1, wskazując na cechę o niskiej istotności.

 ’
’
B. Metody opakowujące:
Wrappery wymagają jakiejś metody przeszukiwania przestrzeni wszystkich możliwych podzbiorów cech, oceny ich jakości poprzez uczenie i ocenę klasyfikatora z tym podzbiorem cech. Proces selekcji cech jest oparty na konkretnym algorytmie uczenia maszynowego, który próbujemy dopasować do danego zbioru danych. Stosuje się podejście zachłannego wyszukiwania, oceniając wszystkie możliwe kombinacje cech względem kryterium oceny. Metody opakowujące zwykle skutkują lepszą dokładnością predykcyjną niż metody filtrujące.
Przedyskutujmy niektóre z tych technik:
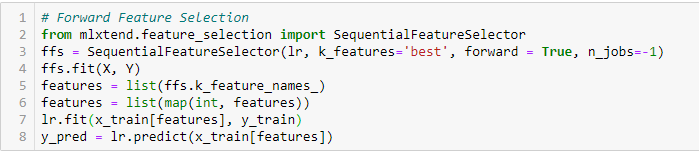
Forward Feature Selection
Jest to metoda iteracyjna, w której zaczynamy od najlepiej działającej zmiennej względem celu. Następnie wybieramy inną zmienną, która daje najlepsze wyniki w połączeniu z pierwszą wybraną zmienną. Ten proces jest kontynuowany aż do osiągnięcia zadanego kryterium.
Backward Feature Elimination
Ta metoda działa dokładnie odwrotnie do metody Forward Feature Selection. Tutaj zaczynamy od wszystkich dostępnych cech i budujemy model. Następnie z modelu wybieramy zmienną, która daje najlepszą wartość miary oceny. Proces ten jest kontynuowany do momentu osiągnięcia zadanego kryterium.
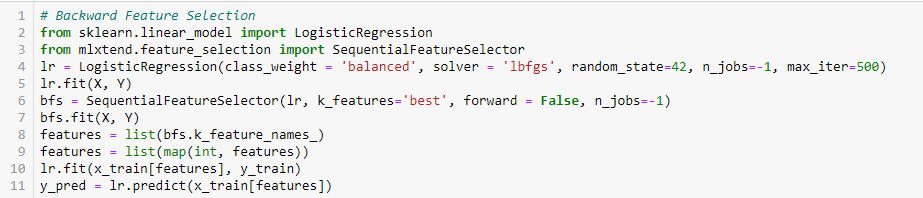
Ta metoda wraz z omówioną powyżej jest również znana jako metoda sekwencyjnej selekcji cech.
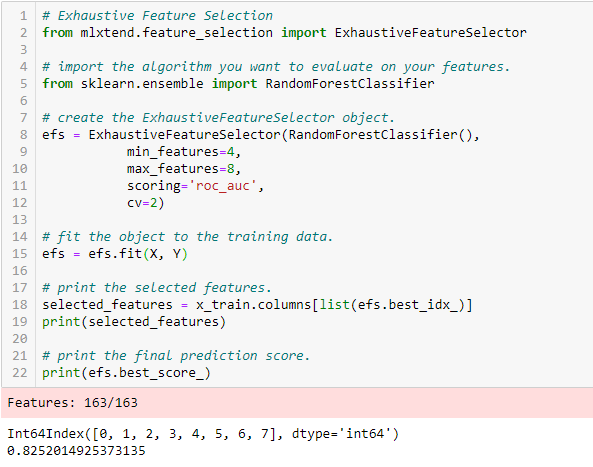
Wyczerpująca selekcja cech
Jest to najbardziej solidna metoda selekcji cech omówiona do tej pory. Jest to ocena brute-force każdego podzbioru cech. Oznacza to, że próbuje każdej możliwej kombinacji zmiennych i zwraca najlepiej działający podzbiór.
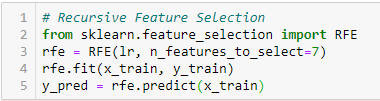
Recursywna eliminacja cech
„Biorąc pod uwagę zewnętrzny estymator, który przypisuje wagi cechom (np. współczynnikom modelu liniowego), celem rekursywnej eliminacji cech (RFE) jest wybór cech poprzez rekursywne rozważanie coraz mniejszych zbiorów cech. Po pierwsze, estymator jest trenowany na początkowym zbiorze cech, a ważność każdej cechy jest uzyskiwana poprzez atrybut coef_ lub atrybut feature_importances_.
Następnie, najmniej ważne cechy są przycinane z bieżącego zbioru cech. Ta procedura jest rekurencyjnie powtarzana na przyciętym zbiorze, aż w końcu zostanie osiągnięta pożądana liczba cech do wyboru.’
C. Metody wbudowane:
Metody te obejmują korzyści obu metod wrapper i filter, poprzez włączenie interakcji cech, ale także utrzymanie rozsądnego kosztu obliczeniowego. Metody wbudowane są iteracyjne w tym sensie, że zajmują się każdą iteracją procesu szkolenia modelu i starannie wyodrębniają te cechy, które wnoszą najwięcej do szkolenia dla danej iteracji.
Przedyskutujmy niektóre z tych technik kliknij tutaj:
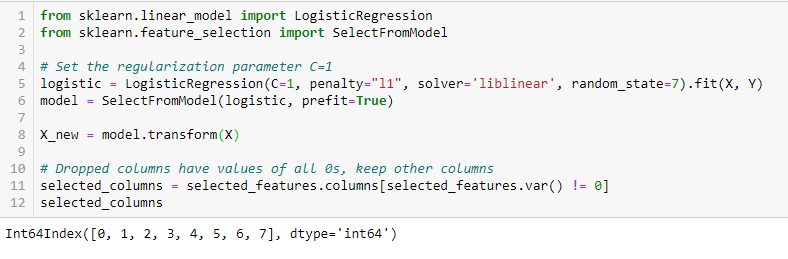
LASSO Regularization (L1)
Regularyzacja polega na dodaniu kary do różnych parametrów modelu uczenia maszynowego w celu zmniejszenia swobody modelu, tj. uniknięcia nadmiernego dopasowania. W modelu liniowym, kara jest nakładana na współczynniki, które mnożą każdy z predyktorów. Spośród różnych rodzajów regularyzacji, Lasso lub L1 ma tę właściwość, że jest w stanie zmniejszyć niektóre współczynniki do zera. Dlatego ta cecha może być usunięta z modelu.
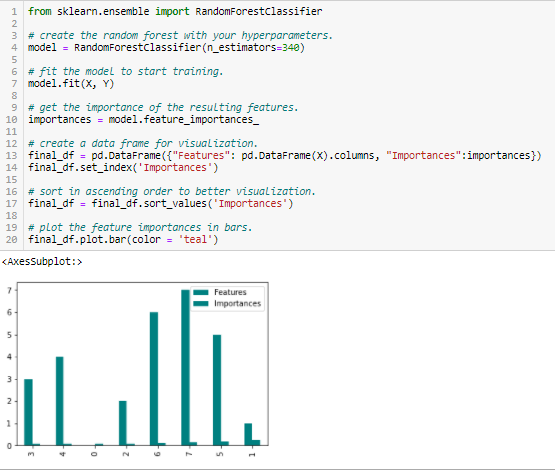
Las losowy Znaczenie
Las losowy jest rodzajem algorytmu Bagging, który agreguje określoną liczbę drzew decyzyjnych. Strategie oparte na drzewach używane przez lasy losowe naturalnie klasyfikują się według tego, jak dobrze poprawiają czystość węzła, lub innymi słowy spadek nieczystości (nieczystość Giniego) w stosunku do wszystkich drzew. Węzły z największym spadkiem nieczystości znajdują się na początku drzew, podczas gdy węzły z najmniejszym spadkiem nieczystości znajdują się na końcu drzew. W ten sposób, przycinając drzewa poniżej danego węzła, możemy stworzyć podzbiór najważniejszych cech.
Wniosek
Przedyskutowaliśmy kilka technik selekcji cech. Mamy na celu pozostawienie technik ekstrakcji cech, takich jak Principal Component Analysis, Singular Value Decomposition, Linear Discriminant Analysis, itp. Metody te pomagają zredukować wymiarowość danych lub zmniejszyć liczbę zmiennych przy zachowaniu wariancji danych.
Apart from the methods discussed above, there are many other methods of feature selection. Istnieją również metody hybrydowe, które wykorzystują zarówno techniki filtrowania jak i zawijania. Jeśli chcesz dowiedzieć się więcej o technikach selekcji cech, moim zdaniem świetnym i wyczerpującym materiałem do czytania jest 'Feature Selection for Data and Pattern Recognition’ autorstwa Urszuli Stańczyk i Lakhmi C. Jain.