Update 29-May-2018: Cel tego artykułu jest potrójny (1) Pokazać, że zawsze będziemy potrzebować modelu danych (albo zrobionego przez ludzi, albo przez maszyny) (2) Pokazać, że modelowanie fizyczne nie jest tym samym, co modelowanie logiczne. W rzeczywistości jest ono bardzo różne i zależy od technologii, na której jest oparte. Potrzebujemy jednak obu. Zilustrowałem ten punkt za pomocą Hadoop w warstwie fizycznej (3) Pokazałem wpływ koncepcji niezmienności na modelowanie danych.
- Czy modelowanie wymiarowe jest martwe?
- Dlaczego musimy modelować nasze dane?
- Dlaczego potrzebujemy modeli wymiarowych?
- Modelowanie danych a modelowanie wymiarowe
- Dlaczego więc niektórzy twierdzą, że modelowanie wymiarowe jest martwe?
- Magazyn danych jest martwyKonfuzja
- The Schema on Read Misunderstanding
- Powtórka z denormalizacji. Fizyczne aspekty modelu.
- Podjęcie de-normalizacji do jej pełnego zakończenia
- Rozkład danych na rozproszonej relacyjnej bazie danych (MPP)
- Dystrybucja danych na Hadoop
- Dimensional Models on Hadoop
- Hadoop i powoli zmieniające się wymiary
- Ewolucja przechowywania w Hadoop
- Werdykt. Czy modele wymiarowe i schematy gwiaździste są przestarzałe?
- Complementary Reading on Dimensional Modelling in the Era of Big Data
Czy modelowanie wymiarowe jest martwe?
Zanim udzielę odpowiedzi na to pytanie, zróbmy krok wstecz i najpierw spójrzmy, co rozumiemy przez wymiarowe modelowanie danych.
Dlaczego musimy modelować nasze dane?
Wbrew powszechnemu nieporozumieniu, jedynym celem modeli danych nie jest służenie jako diagram ER do projektowania fizycznej bazy danych. Modele danych reprezentują złożoność procesów biznesowych w przedsiębiorstwie. Dokumentują one ważne reguły i koncepcje biznesowe oraz pomagają w standaryzacji kluczowej terminologii przedsiębiorstwa. Zapewniają przejrzystość i pomagają odkryć nieostre myślenie i niejednoznaczności dotyczące procesów biznesowych. Ponadto, modele danych można wykorzystać do komunikacji z innymi interesariuszami. Nie zbudowalibyśmy domu czy mostu bez planu. Dlaczego więc miałbyś budować aplikację danych, taką jak hurtownia danych, bez planu?
Dlaczego potrzebujemy modeli wymiarowych?
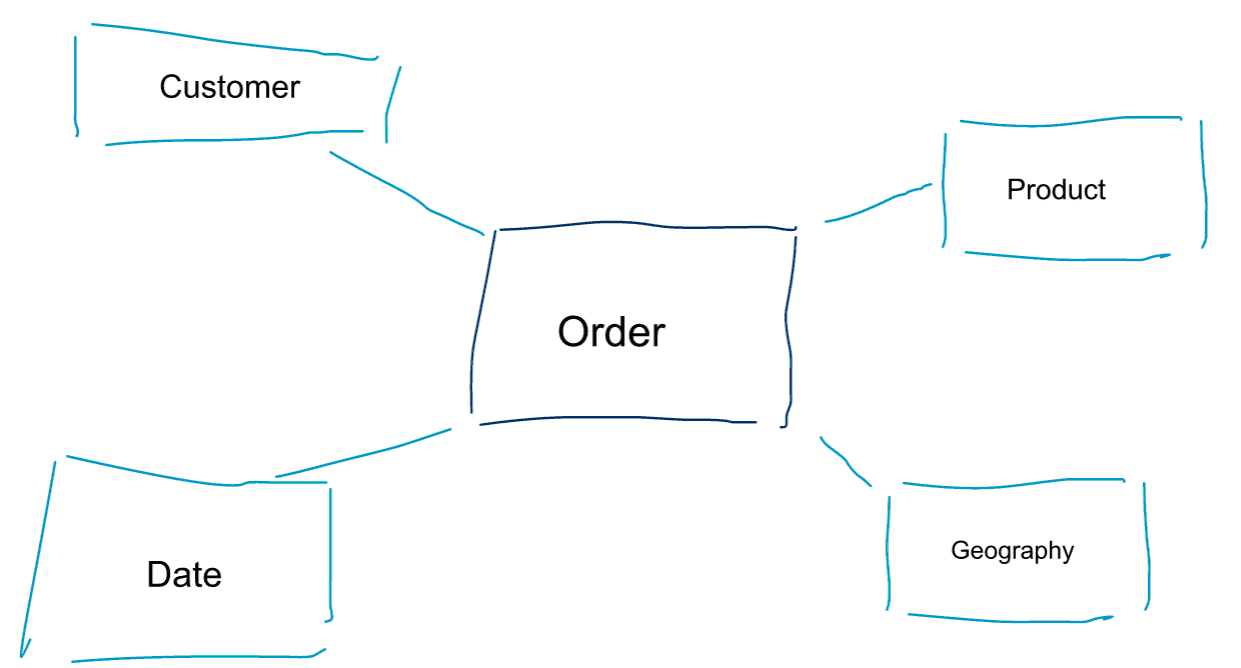
Modelowanie wymiarowe to specjalne podejście do modelowania danych. Używamy również słów data mart lub star schema jako synonimów modelu wymiarowego. Schematy gwiaździste są zoptymalizowane do analizy danych. Przyjrzyj się poniższemu modelowi wymiarowemu. Jest on dość intuicyjny do zrozumienia. Natychmiast widzimy, jak możemy pokroić nasze dane dotyczące zamówień według klienta, produktu lub daty i zmierzyć wydajność procesu biznesowego zamówień poprzez agregację i porównanie metryk.
Jedną z podstawowych idei modelowania wymiarowego jest określenie najniższego poziomu szczegółowości w transakcyjnym procesie biznesowym. Kiedy kroimy i drążymy dane, jest to poziom listków, z którego nie możemy drążyć dalej. Innymi słowy, najniższym poziomem szczegółowości w schemacie gwiaździstym jest połączenie faktów ze wszystkimi tabelami wymiarów bez żadnych agregacji.
Modelowanie danych a modelowanie wymiarowe
W standardowym modelowaniu danych dążymy do wyeliminowania powtórzeń i nadmiarowości danych. Kiedy następuje zmiana w danych, musimy zmienić je tylko w jednym miejscu. Pomaga to również w jakości danych. Wartości nie wymykają się z synchronizacji w wielu miejscach. Przyjrzyj się poniższemu modelowi. Zawiera on różne tabele, które reprezentują pojęcia geograficzne. W modelu znormalizowanym mamy osobną tabelę dla każdej jednostki. W modelu wymiarowym mamy tylko jedną tabelę: geografia. W tej tabeli miasta zostaną powtórzone wiele razy. Raz dla każdego miasta. Jeśli kraj zmieni nazwę, musimy aktualizować kraj w wielu miejscach
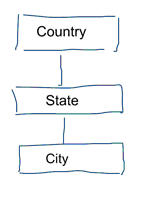
Uwaga: Standardowe modelowanie danych jest również określane jako modelowanie 3NF.
Standardowe podejście do modelowania danych nie jest odpowiednie dla obciążeń Business Intelligence. Duża ilość tabel skutkuje dużą ilością złączeń. Połączenia spowalniają pracę. W analityce danych unikamy ich tam, gdzie to możliwe. W modelach wymiarowych od-normalizujemy wiele powiązanych tabel w jedną tabelę, np. różne tabele w naszym poprzednim przykładzie mogą być wstępnie połączone w jedną tabelę: geografia.
Dlaczego więc niektórzy twierdzą, że modelowanie wymiarowe jest martwe?
Sądzę, że zgodzisz się, że modelowanie danych w ogóle, a modelowanie wymiarowe w szczególności, jest dość użytecznym ćwiczeniem. Dlaczego więc niektórzy twierdzą, że modelowanie wymiarowe jest nieprzydatne w erze big data i Hadoop?
Jak można sobie wyobrazić, są ku temu różne powody.
Magazyn danych jest martwyKonfuzja
Po pierwsze, niektórzy mylą modelowanie wymiarowe z hurtownią danych. Twierdzą oni, że hurtownie danych są martwe i w związku z tym modelowanie wymiarowe również może zostać odesłane na śmietnik historii. Jest to logicznie spójny argument. Jednak koncepcja hurtowni danych nie jest bynajmniej przestarzała. Zawsze potrzebujemy zintegrowanych i wiarygodnych danych do wypełnienia naszych pulpitów BI. Jeśli chcą Państwo dowiedzieć się więcej na ten temat, polecam nasze szkolenie Big Data for Data Warehouse Professionals. W szkoleniu zagłębiam się w szczegóły i wyjaśniam, że hurtownia danych jest istotna jak nigdy dotąd. Pokażę również, w jaki sposób pojawiające się narzędzia i technologie big data są przydatne w hurtowniach danych.

The Schema on Read Misunderstanding
Drugi argument, który często słyszę, brzmi następująco. 'Stosujemy podejście schematu przy odczycie i nie musimy już modelować naszych danych’. Moim zdaniem koncepcja schematu na odczycie jest jednym z największych nieporozumień w analityce danych. Zgadzam się, że warto początkowo przechowywać surowe dane w zrzutach danych, które są lekkie na schemat. Jednak ten argument nie powinien być używany jako wymówka, aby całkowicie nie modelować danych. Podejście do schematu przy odczycie jest po prostu kopaniem w dół puszki i odpowiedzialnością dla dalszych procesów. Ktoś wciąż musi ugryźć kulę definiowania typów danych. Każdy proces, który uzyskuje dostęp do zrzutu danych bez schematu, musi samodzielnie dowiedzieć się, co się dzieje. Ten rodzaj pracy sumuje się, jest całkowicie zbędny i można go łatwo uniknąć, definiując typy danych i odpowiedni schemat.
Powtórka z denormalizacji. Fizyczne aspekty modelu.
Czy faktycznie istnieją jakieś ważne argumenty za uznaniem modeli wymiarowych za przestarzałe? Istnieją rzeczywiście lepsze argumenty niż te dwa, które wymieniłem powyżej. Wymagają one pewnego zrozumienia fizycznego modelowania danych i sposobu, w jaki działa Hadoop. Bear with me.
Wcześniej krótko wspomniałem o jednym z powodów, dla których modelujemy nasze dane wymiarowo. Jest to związane z tym, w jaki sposób dane są przechowywane fizycznie w naszym magazynie danych. W standardowym modelowaniu danych każda jednostka świata rzeczywistego dostaje swoją własną tabelę. Robimy to, aby uniknąć redundancji danych i ryzyka problemów z jakością danych wkradających się do naszych danych. Im więcej tabel mamy, tym więcej złączeń potrzebujemy. To jest właśnie wada. Połączenia tabel są drogie, szczególnie gdy łączymy dużą liczbę rekordów z naszych zbiorów danych. Kiedy modelujemy dane wymiarowo, konsolidujemy wiele tabel w jedną. Mówimy, że wstępnie łączymy lub de-normalizujemy dane. Mamy teraz mniej tabel, mniej złączeń, a w rezultacie niższe opóźnienia i lepszą wydajność zapytań.
Weź udział w dyskusji na temat tego postu na LinkedIn
Podjęcie de-normalizacji do jej pełnego zakończenia
Dlaczego nie podjąć de-normalizacji do jej pełnego zakończenia? Pozbyć się wszystkich złączeń i mieć tylko jedną, pojedynczą tabelę faktów? W rzeczywistości wyeliminowałoby to całkowicie potrzebę jakichkolwiek złączeń. Jednakże, jak można sobie wyobrazić, ma to pewne efekty uboczne. Po pierwsze, zwiększa ilość wymaganej pamięci masowej. Musimy teraz przechowywać wiele nadmiarowych danych. Wraz z pojawieniem się kolumnowych formatów pamięci masowej do analizy danych jest to obecnie mniejszy problem. Większym problemem de-normalizacji jest fakt, że za każdym razem, gdy zmienia się wartość jednego z atrybutów, musimy zaktualizować wartość w wielu miejscach – być może tysiące lub miliony aktualizacji. Jednym ze sposobów na obejście tego problemu jest pełne przeładowanie naszych modeli w nocy. Często będzie to o wiele szybsze i łatwiejsze niż zastosowanie dużej liczby aktualizacji. Kolumnowe bazy danych zazwyczaj przyjmują następujące podejście. Najpierw przechowują aktualizacje danych w pamięci, a następnie asynchronicznie zapisują je na dysku.
Rozkład danych na rozproszonej relacyjnej bazie danych (MPP)
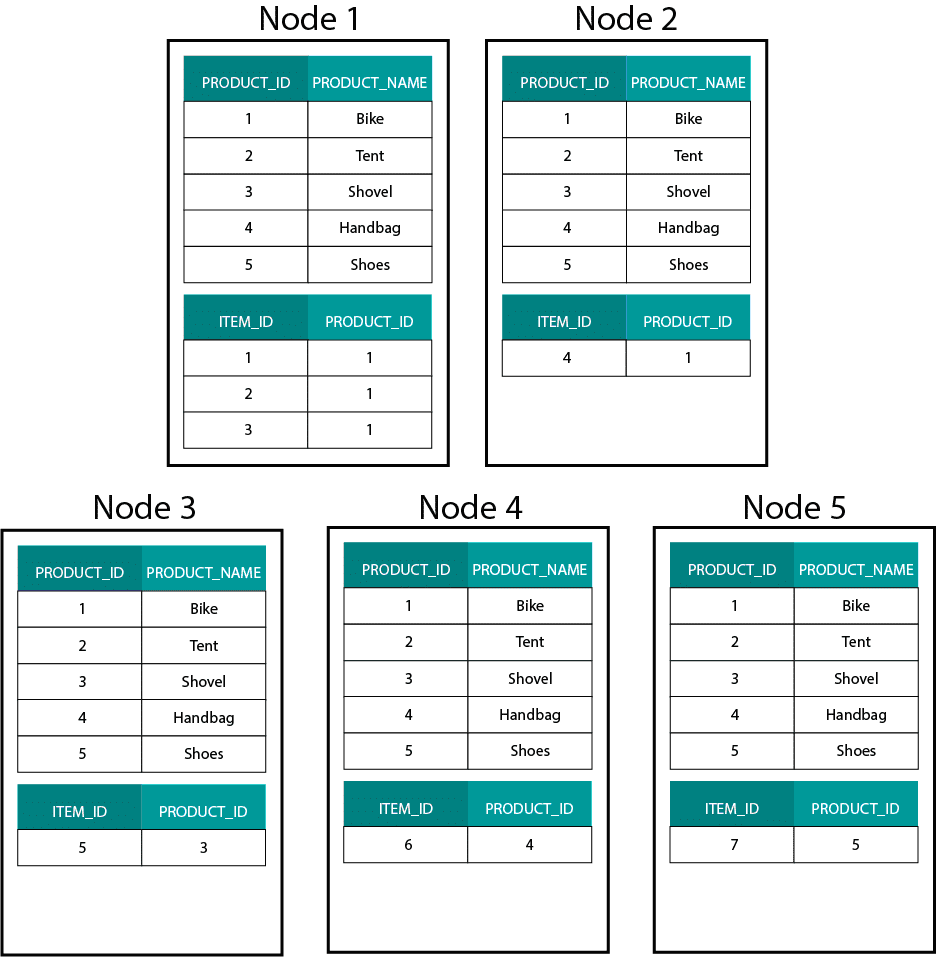
Przy tworzeniu modeli wymiarowych na Hadoop, np. Hive, SparkSQL itp. musimy lepiej zrozumieć jedną podstawową cechę tej technologii, która odróżnia ją od rozproszonej relacyjnej bazy danych (MPP), takiej jak Teradata itp. Podczas dystrybucji danych pomiędzy węzłami w MPP mamy kontrolę nad rozmieszczeniem rekordów. Bazując na naszej strategii partycjonowania, np. hash, lista, zakres itp. możemy współlokować klucze poszczególnych rekordów w różnych zakładkach na tym samym węźle. Mając zagwarantowaną współlokalność danych, nasze złączenia są superszybkie, ponieważ nie musimy przesyłać żadnych danych przez sieć. Spójrz na poniższy przykład. Rekordy z tym samym ORDER_ID z tabel ORDER i ORDER_ITEM trafiają do tego samego węzła.
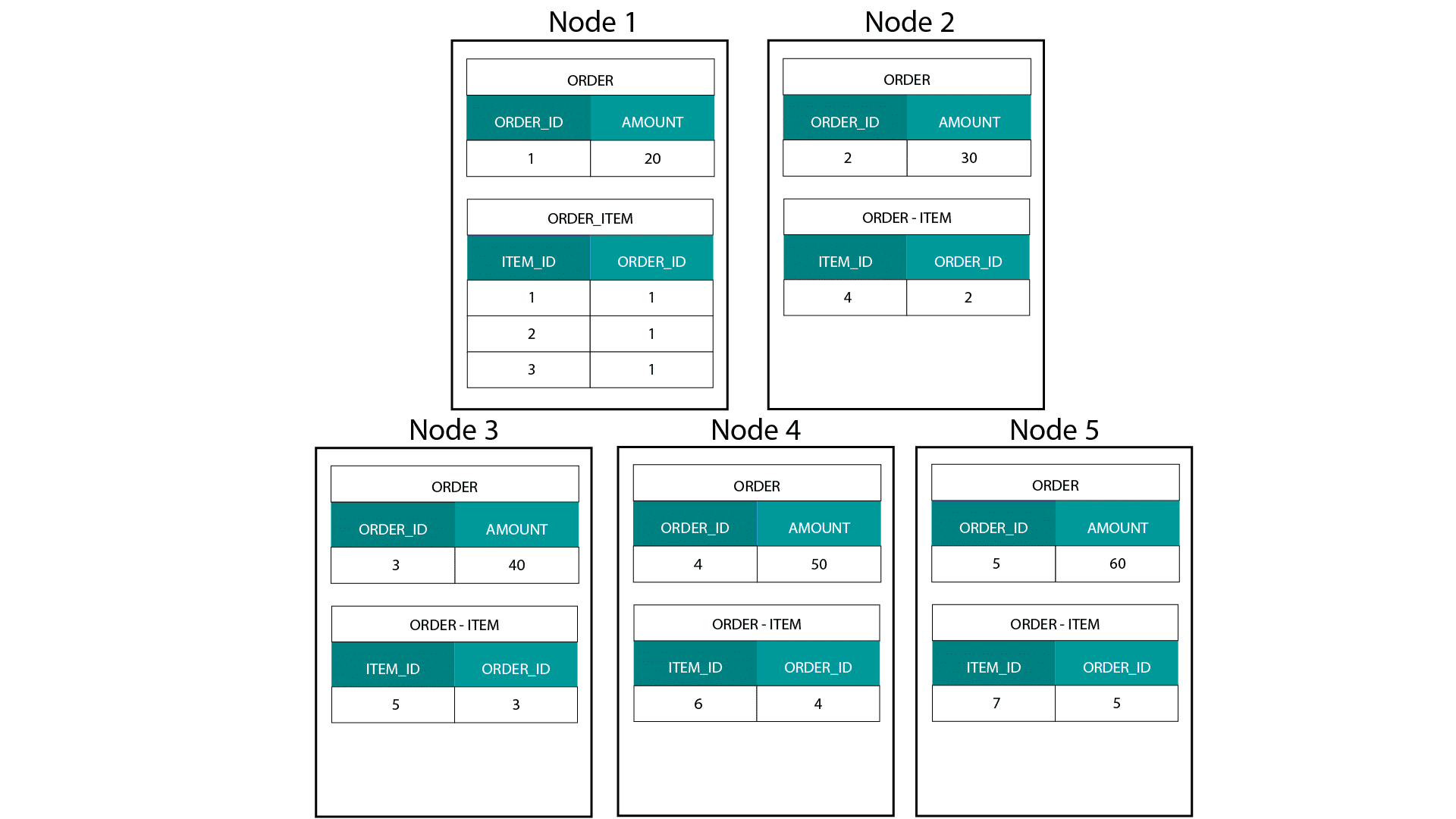
Klucze dla order_id z tabeli order i order_item są współlokowane na tych samych węzłach.
Dystrybucja danych na Hadoop
To bardzo różni się od systemów opartych na Hadoop. Tam dzielimy nasze dane na duże kawałki i dystrybuujemy je i replikujemy w naszych węzłach na rozproszonym systemie plików HDFS (Hadoop Distributed File System). Przy takiej strategii dystrybucji danych nie możemy zagwarantować współlokalności danych. Przyjrzyj się poniższemu przykładowi. Rekordy dla klucza ORDER_ID kończą się na różnych węzłach.
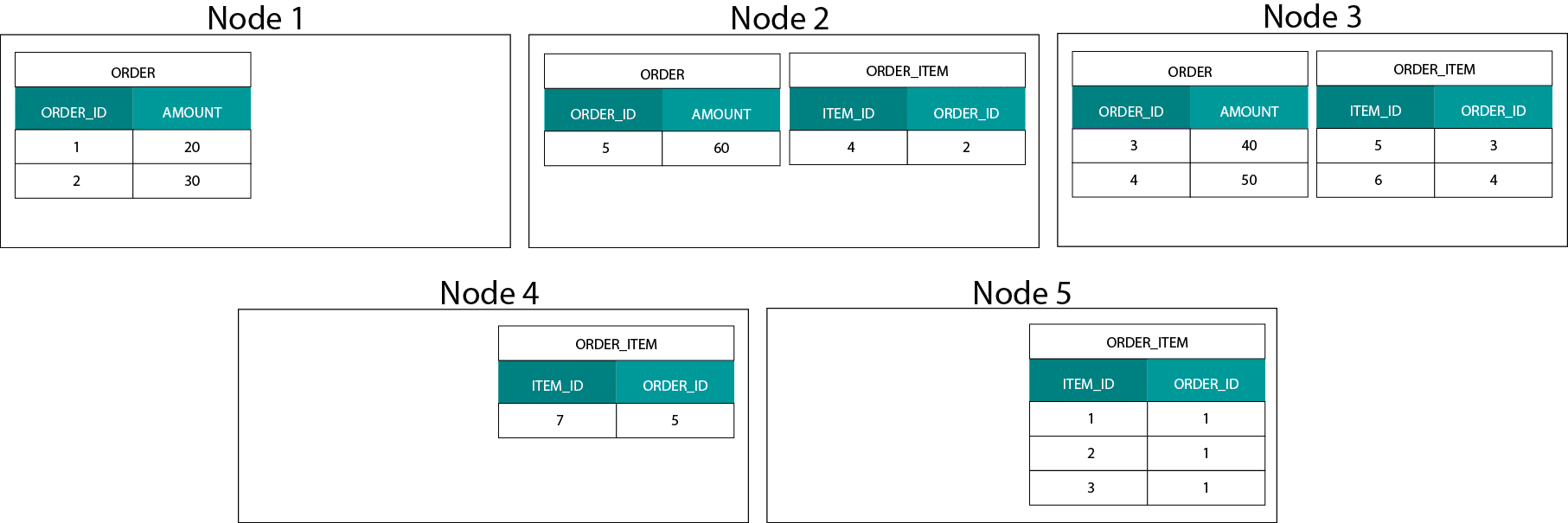
Aby wykonać złączenie, musimy przesłać dane przez sieć, co wpływa na wydajność.
Jedną ze strategii radzenia sobie z tym problemem jest replikacja jednej z tabel złączenia przez wszystkie węzły w klastrze. Nazywa się to broadcast join i używamy tej samej strategii na MPP. Jak można sobie wyobrazić, działa to tylko dla małych tabel typu lookup lub tabel wymiarów.
Co więc robimy, gdy mamy dużą tabelę faktów i dużą tabelę wymiarów, np. klient lub produkt? Albo gdy mamy dwie duże tabele faktów.
Dimensional Models on Hadoop
Aby obejść ten problem z wydajnością, możemy zdenormalizować duże tabele wymiarów do naszej tabeli faktów, aby zagwarantować, że dane są współlokowane. W przypadku łączenia dwóch dużych tabel faktów możemy zagnieździć tabelę o mniejszej ziarnistości wewnątrz tabeli o większej ziarnistości, np. dużą tabelę ORDER_ITEM zagnieździć wewnątrz tabeli ORDER. Nowoczesne silniki zapytań, takie jak Impala lub Drill, pozwalają nam spłaszczyć te dane

Ta strategia zagnieżdżania danych jest również przydatna do bolesnych koncepcji Kimballa, takich jak tabele pomostowe do reprezentowania relacji M:N w modelu wymiarowym.
Hadoop i powoli zmieniające się wymiary
Przechowywanie danych w systemie plików Hadoop jest niezmienne. Innymi słowy, można tylko wstawiać i dołączać rekordy. Nie można modyfikować danych. Jeśli pochodzisz z relacyjnej hurtowni danych, może się to początkowo wydawać dziwne. Jednak pod maską bazy danych działają w podobny sposób. Przechowują one wszystkie zmiany w danych w niezmiennym dzienniku wyprzedzenia zapisu (znanym w Oracle jako dziennik redo), zanim proces asynchronicznie zaktualizuje dane w plikach danych.
Jaki wpływ ma niezmienność na nasze modele wymiarowe? Być może pamiętasz koncepcję wolno zmieniających się wymiarów (SCD) ze swojego kursu modelowania wymiarowego. SCD opcjonalnie zachowują historię zmian atrybutów. Pozwalają nam na raportowanie metryk w odniesieniu do wartości atrybutu w danym punkcie w czasie. Nie jest to jednak zachowanie domyślne. Domyślnie aktualizujemy tabele wymiarów z najnowszymi wartościami. Jakie są więc nasze opcje na Hadoop? Pamiętaj! Nie możemy aktualizować danych. Możemy po prostu uczynić SCD domyślnym zachowaniem i audytować wszelkie zmiany. Jeśli chcemy uruchamiać raporty na podstawie aktualnych wartości, możemy stworzyć widok na SCD, który będzie pobierał tylko najnowsze wartości. Można to łatwo zrobić za pomocą funkcji okienkowych. Alternatywnie, możemy uruchomić tak zwaną usługę kompakcji, która fizycznie tworzy oddzielną wersję tabeli wymiarów z tylko najnowszymi wartościami.
Ewolucja przechowywania w Hadoop
Te ograniczenia Hadoop nie pozostały niezauważone przez producentów platform Hadoop. W Hive mamy teraz transakcje ACID i aktualizowalne tabele. W oparciu o liczbę otwartych poważnych problemów i moje własne doświadczenie, ta funkcja nie wydaje się być jeszcze gotowa do produkcji. Cloudera przyjęła inne podejście. Z Kudu stworzyli nowy format updatable storage, który nie siedzi na HDFS, ale na lokalnym systemie plików OS. Pozbywa się on całkowicie ograniczeń Hadoop i jest podobny do tradycyjnej warstwy pamięci masowej w kolumnowym MPP. Ogólnie rzecz biorąc, prawdopodobnie lepiej jest uruchamiać wszelkie przypadki użycia BI i dashboardów na MPP, np. Impala + Kudu, niż na Hadoop. Niemniej jednak, MPP mają swoje własne ograniczenia, jeśli chodzi o odporność, współbieżność i skalowalność. Jeśli napotkasz te ograniczenia, Hadoop i jego bliski kuzyn Spark są dobrymi opcjami dla obciążeń BI. Wszystkie te ograniczenia omawiamy w naszym kursie szkoleniowym Big Data for Data Warehouse Professionals i zalecamy, kiedy używać RDBMS, a kiedy SQL na Hadoop/Spark.
Werdykt. Czy modele wymiarowe i schematy gwiaździste są przestarzałe?
Wszyscy wiemy, że Ralph Kimball przeszedł na emeryturę. Ale jego główne idee i koncepcje są wciąż aktualne i żyją dalej. Musimy je dostosować do nowych technologii i typów pamięci masowej, ale nadal stanowią wartość dodaną.
Teach me Big Data to Advance my Career
Complementary Reading on Dimensional Modelling in the Era of Big Data
Tom Breur: The Past and Future of Dimensional Modeling
Edosa Odaro: 5 Radical Tips for Speedy Big Data Integration – The Anti Data Warehouse Pattern
.